Spark-taken verzenden in Azure Machine Learning
VAN TOEPASSING OP: Azure CLI ml extension v2 (current)Python SDK azure-ai-ml v2 (current)
Azure CLI ml extension v2 (current)Python SDK azure-ai-ml v2 (current)
Azure Machine Learning biedt ondersteuning voor het verzenden van zelfstandige machine learning-taken en het maken van machine learning-pijplijnen waarbij meerdere machine learning-werkstroomstappen zijn betrokken. Azure Machine Learning verwerkt zowel het maken van zelfstandige Spark-taken als het maken van herbruikbare Spark-onderdelen die azure Machine Learning-pijplijnen kunnen gebruiken. In dit artikel leert u hoe u Spark-taken verzendt met behulp van:
- gebruikersinterface voor Azure Machine Learning-studio
- Azure Machine Learning CLI
- Azure Machine Learning-SDK
Zie deze resource voor meer informatie over Apache Spark in Azure Machine Learning-concepten.
Vereisten
VAN TOEPASSING OP: Azure CLI ml-extensie v2 (huidige)
- Een Azure-abonnement; Als u geen Azure-abonnement hebt, maakt u een gratis account voordat u begint.
- Een Azure Machine Learning-werkruimte. Zie Werkruimtebronnen maken.
- Maak een Azure Machine Learning-rekenproces.
- Installeer Azure Machine Learning CLI.
- (Optioneel): Een gekoppelde Synapse Spark-pool in de Azure Machine Learning-werkruimte.
Notitie
- Zie Resourcetoegang garanderen voor Spark-taken voor meer informatie over resourcetoegang tijdens het gebruik van serverloze Spark-rekenkracht van Azure Machine Learning en gekoppelde Synapse Spark-pool.
- Azure Machine Learning biedt een gedeelde quotumgroep waaruit alle gebruikers toegang hebben tot het rekenquotum om gedurende een beperkte tijd tests uit te voeren. Wanneer u de serverloze Spark-berekening gebruikt, kunt u met Azure Machine Learning gedurende korte tijd toegang krijgen tot dit gedeelde quotum.
Door de gebruiker toegewezen beheerde identiteit koppelen met CLI v2
- Maak een YAML-bestand dat de door de gebruiker toegewezen beheerde identiteit definieert die moet worden gekoppeld aan de werkruimte:
identity: type: system_assigned,user_assigned tenant_id: <TENANT_ID> user_assigned_identities: '/subscriptions/<SUBSCRIPTION_ID/resourceGroups/<RESOURCE_GROUP>/providers/Microsoft.ManagedIdentity/userAssignedIdentities/<AML_USER_MANAGED_ID>': {} - Gebruik met de
--fileparameter het YAML-bestand in deaz ml workspace updateopdracht om de door de gebruiker toegewezen beheerde identiteit toe te voegen:az ml workspace update --subscription <SUBSCRIPTION_ID> --resource-group <RESOURCE_GROUP> --name <AML_WORKSPACE_NAME> --file <YAML_FILE_NAME>.yaml
Door de gebruiker toegewezen beheerde identiteit koppelen met ARMClient
- Installeren
ARMClient, een eenvoudig opdrachtregelprogramma dat de Azure Resource Manager-API aanroept. - Maak een JSON-bestand dat de door de gebruiker toegewezen beheerde identiteit definieert die moet worden gekoppeld aan de werkruimte:
{ "properties":{ }, "location": "<AZURE_REGION>", "identity":{ "type":"SystemAssigned,UserAssigned", "userAssignedIdentities":{ "/subscriptions/<SUBSCRIPTION_ID/resourceGroups/<RESOURCE_GROUP>/providers/Microsoft.ManagedIdentity/userAssignedIdentities/<AML_USER_MANAGED_ID>": { } } } } - Als u de door de gebruiker toegewezen beheerde identiteit aan de werkruimte wilt koppelen, voert u de volgende opdracht uit in de PowerShell-prompt of de opdrachtprompt.
armclient PATCH https://management.azure.com/subscriptions/<SUBSCRIPTION_ID>/resourceGroups/<RESOURCE_GROUP>/providers/Microsoft.MachineLearningServices/workspaces/<AML_WORKSPACE_NAME>?api-version=2022-05-01 '@<JSON_FILE_NAME>.json'
Notitie
- Als u wilt zorgen voor een geslaagde uitvoering van de Spark-taak, wijst u de rollen Inzender en Inzender voor opslagblobgegevens toe aan het Azure-opslagaccount dat wordt gebruikt voor gegevensinvoer en -uitvoer, aan de identiteit die door de Spark-taak wordt gebruikt
- Openbare netwerktoegang moet zijn ingeschakeld in de Azure Synapse-werkruimte om ervoor te zorgen dat de Spark-taak wordt uitgevoerd met behulp van een gekoppelde Synapse Spark-pool.
- Als een gekoppelde Synapse Spark-pool verwijst naar een Synapse Spark-pool, moet in een Azure Synapse-werkruimte waaraan een beheerd virtueel netwerk is gekoppeld, een beheerd privé-eindpunt voor het opslagaccount worden geconfigureerd om toegang tot gegevens te garanderen.
- Serverloze Spark-rekenkracht ondersteunt door Azure Machine Learning beheerd virtueel netwerk. Als een beheerd netwerk is ingericht voor de serverloze Spark-berekening, moeten de bijbehorende privé-eindpunten voor het opslagaccount ook worden ingericht om toegang tot gegevens te garanderen.
Een zelfstandige Spark-taak verzenden
Nadat u de benodigde wijzigingen voor python-scriptparameterisatie hebt aangebracht, kan een Python-script dat is ontwikkeld door interactieve gegevens wrangling , worden gebruikt om een batchtaak te verzenden om een groter aantal gegevens te verwerken. Een eenvoudige batchtaak kan worden verzonden als een zelfstandige Spark-taak.
Een Spark-taak vereist een Python-script dat argumenten accepteert, die kan worden ontwikkeld met wijziging van de Python-code die is ontwikkeld op basis van interactieve gegevens-wrangling. Hier ziet u een voorbeeld van een Python-script.
# titanic.py
import argparse
from operator import add
import pyspark.pandas as pd
from pyspark.ml.feature import Imputer
parser = argparse.ArgumentParser()
parser.add_argument("--titanic_data")
parser.add_argument("--wrangled_data")
args = parser.parse_args()
print(args.wrangled_data)
print(args.titanic_data)
df = pd.read_csv(args.titanic_data, index_col="PassengerId")
imputer = Imputer(inputCols=["Age"], outputCol="Age").setStrategy(
"mean"
) # Replace missing values in Age column with the mean value
df.fillna(
value={"Cabin": "None"}, inplace=True
) # Fill Cabin column with value "None" if missing
df.dropna(inplace=True) # Drop the rows which still have any missing value
df.to_csv(args.wrangled_data, index_col="PassengerId")
Notitie
In dit Python-codevoorbeeld wordt gebruikgemaakt van pyspark.pandas. Alleen de Spark Runtime-versie 3.2 of hoger ondersteunt dit.
Het bovenstaande script heeft twee argumenten --titanic_data en --wrangled_data, die respectievelijk het pad van invoergegevens en uitvoermap doorgeven.
VAN TOEPASSING OP: Azure CLI ml-extensie v2 (huidige)
Als u een taak wilt maken, kan een zelfstandige Spark-taak worden gedefinieerd als een YAML-specificatiebestand, dat kan worden gebruikt in de az ml job create opdracht, met de --file parameter. Definieer deze eigenschappen in het YAML-bestand:
YAML-eigenschappen in de Spark-taakspecificatie
type- ingesteld opspark.code- definieert de locatie van de map die broncode en scripts voor deze taak bevat.entry- definieert het toegangspunt voor de taak. Dit moet betrekking hebben op een van deze eigenschappen:file- definieert de naam van het Python-script dat fungeert als invoerpunt voor de taak.
py_files- definieert een lijst met.zip,.eggof.pybestanden, die in dePYTHONPATH, voor een succesvolle uitvoering van de taak moeten worden geplaatst. Deze eigenschap is optioneel.jars- definieert een lijst met.jarbestanden die moeten worden opgenomen in het Spark-stuurprogramma en de uitvoerderCLASSPATHvoor een geslaagde uitvoering van de taak. Deze eigenschap is optioneel.files- definieert een lijst met bestanden die moeten worden gekopieerd naar de werkmap van elke uitvoerder, voor een geslaagde taakuitvoering. Deze eigenschap is optioneel.archives- definieert een lijst met archieven die moeten worden geëxtraheerd in de werkmap van elke uitvoerder, voor een geslaagde taakuitvoering. Deze eigenschap is optioneel.conf- definieert deze Spark-stuurprogramma- en uitvoerderseigenschappen:spark.driver.cores: het aantal kernen voor het Spark-stuurprogramma.spark.driver.memory: toegewezen geheugen voor het Spark-stuurprogramma, in gigabytes (GB).spark.executor.cores: het aantal kernen voor de Spark-uitvoerfunctie.spark.executor.memory: de geheugentoewijzing voor de Spark-uitvoerfunctie, in gigabytes (GB).spark.dynamicAllocation.enabled- of uitvoerders dynamisch moeten worden toegewezen, als eenTrueofFalsewaarde.- Als dynamische toewijzing van uitvoerders is ingeschakeld, definieert u deze eigenschappen:
spark.dynamicAllocation.minExecutors- het minimale aantal Spark-uitvoerders voor dynamische toewijzing.spark.dynamicAllocation.maxExecutors- het maximum aantal Spark-uitvoerders voor dynamische toewijzing.
- Als dynamische toewijzing van uitvoerders is uitgeschakeld, definieert u deze eigenschap:
spark.executor.instances- het aantal Spark-uitvoerders.
environment- een Azure Machine Learning-omgeving om de taak uit te voeren.args- de opdrachtregelargumenten die moeten worden doorgegeven aan het Python-script voor het taakinvoerpunt. Zie het YAML-specificatiebestand dat hier is opgegeven voor een voorbeeld.resources- met deze eigenschap worden de resources gedefinieerd die moeten worden gebruikt door een serverloze Spark-rekenkracht van Azure Machine Learning. Hierbij worden de volgende eigenschappen gebruikt:instance_type- het type rekeninstantie dat moet worden gebruikt voor Spark-pool. De volgende exemplaartypen worden momenteel ondersteund:standard_e4s_v3standard_e8s_v3standard_e16s_v3standard_e32s_v3standard_e64s_v3
runtime_version- definieert de Spark Runtime-versie. De volgende Spark-runtimeversies worden momenteel ondersteund:3.23.3Belangrijk
Azure Synapse Runtime voor Apache Spark: aankondigingen
- Azure Synapse Runtime voor Apache Spark 3.2:
- EOLA Aankondigingsdatum: 8 juli 2023
- Einddatum van ondersteuning: 8 juli 2024. Na deze datum wordt de runtime uitgeschakeld.
- Voor continue ondersteuning en optimale prestaties adviseren we om te migreren naar Apache Spark 3.3.
- Azure Synapse Runtime voor Apache Spark 3.2:
Dit is een voorbeeld:
resources: instance_type: standard_e8s_v3 runtime_version: "3.3"compute- deze eigenschap definieert de naam van een gekoppelde Synapse Spark-pool, zoals wordt weergegeven in dit voorbeeld:compute: mysparkpoolinputs- met deze eigenschap worden invoer voor de Spark-taak gedefinieerd. Invoer voor een Spark-taak kan een letterlijke waarde zijn of gegevens die zijn opgeslagen in een bestand of map.- Een letterlijke waarde kan een getal, een Booleaanse waarde of een tekenreeks zijn. Hier ziet u enkele voorbeelden:
inputs: sampling_rate: 0.02 # a number hello_number: 42 # an integer hello_string: "Hello world" # a string hello_boolean: True # a boolean value - Gegevens die zijn opgeslagen in een bestand of map, moeten worden gedefinieerd met behulp van deze eigenschappen:
type- stel deze eigenschap in opuri_file, ofuri_folder, voor invoergegevens in een bestand of een map.path- de URI van de invoergegevens, zoalsazureml://,abfss://ofwasbs://.mode- stel deze eigenschap in opdirect. In dit voorbeeld ziet u de definitie van een taakinvoer, die kan worden aangeduid als$${inputs.titanic_data}}:inputs: titanic_data: type: uri_file path: azureml://datastores/workspaceblobstore/paths/data/titanic.csv mode: direct
- Een letterlijke waarde kan een getal, een Booleaanse waarde of een tekenreeks zijn. Hier ziet u enkele voorbeelden:
outputs- met deze eigenschap worden de uitvoer van de Spark-taak gedefinieerd. Uitvoer voor een Spark-taak kan worden geschreven naar een bestand of een maplocatie, die is gedefinieerd met behulp van de volgende drie eigenschappen:type- deze eigenschap kan worden ingesteld opuri_fileofuri_foldervoor het schrijven van uitvoergegevens naar een bestand of een map.path- deze eigenschap definieert de URI van de uitvoerlocatie, zoalsazureml://,abfss://ofwasbs://.mode- stel deze eigenschap in opdirect. In dit voorbeeld ziet u de definitie van een taakuitvoer, die kan worden aangeduid als${{outputs.wrangled_data}}:outputs: wrangled_data: type: uri_folder path: azureml://datastores/workspaceblobstore/paths/data/wrangled/ mode: direct
identity- deze optionele eigenschap definieert de identiteit die wordt gebruikt om deze taak te verzenden. Het kan bestaanuser_identityuit waarden enmanagedwaarden. Als de YAML-specificatie geen identiteit definieert, gebruikt de Spark-taak de standaardidentiteit.
Zelfstandige Spark-taak
In dit voorbeeld van de YAML-specificatie ziet u een zelfstandige Spark-taak. Er wordt gebruikgemaakt van een serverloze Spark-rekenkracht van Azure Machine Learning:
$schema: http://azureml/sdk-2-0/SparkJob.json
type: spark
code: ./
entry:
file: titanic.py
conf:
spark.driver.cores: 1
spark.driver.memory: 2g
spark.executor.cores: 2
spark.executor.memory: 2g
spark.executor.instances: 2
inputs:
titanic_data:
type: uri_file
path: azureml://datastores/workspaceblobstore/paths/data/titanic.csv
mode: direct
outputs:
wrangled_data:
type: uri_folder
path: azureml://datastores/workspaceblobstore/paths/data/wrangled/
mode: direct
args: >-
--titanic_data ${{inputs.titanic_data}}
--wrangled_data ${{outputs.wrangled_data}}
identity:
type: user_identity
resources:
instance_type: standard_e4s_v3
runtime_version: "3.3"
Notitie
Als u een gekoppelde Synapse Spark-pool wilt gebruiken, definieert u de compute eigenschap in het yamL-voorbeeldspecificatiebestand dat eerder wordt weergegeven, in plaats van de resources eigenschap.
De YAML-bestanden die eerder worden weergegeven, kunnen worden gebruikt in de az ml job create opdracht, met de --file parameter, om een zelfstandige Spark-taak te maken, zoals wordt weergegeven:
az ml job create --file <YAML_SPECIFICATION_FILE_NAME>.yaml --subscription <SUBSCRIPTION_ID> --resource-group <RESOURCE_GROUP> --workspace-name <AML_WORKSPACE_NAME>
U kunt de bovenstaande opdracht uitvoeren vanuit:
- terminal van een Azure Machine Learning-rekenproces.
- terminal van Visual Studio Code die is verbonden met een Azure Machine Learning-rekenproces.
- uw lokale computer waarop Azure Machine Learning CLI is geïnstalleerd.
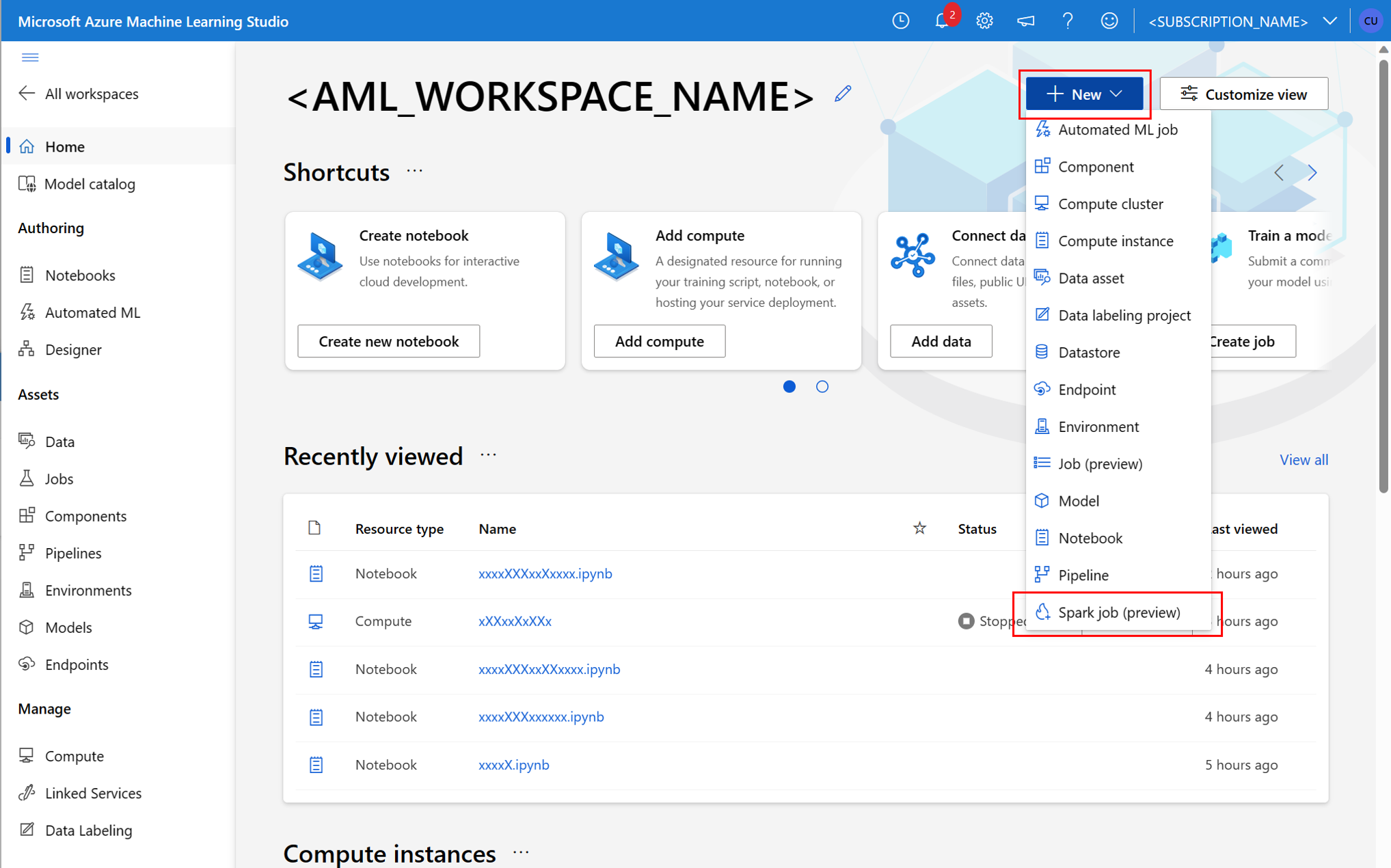
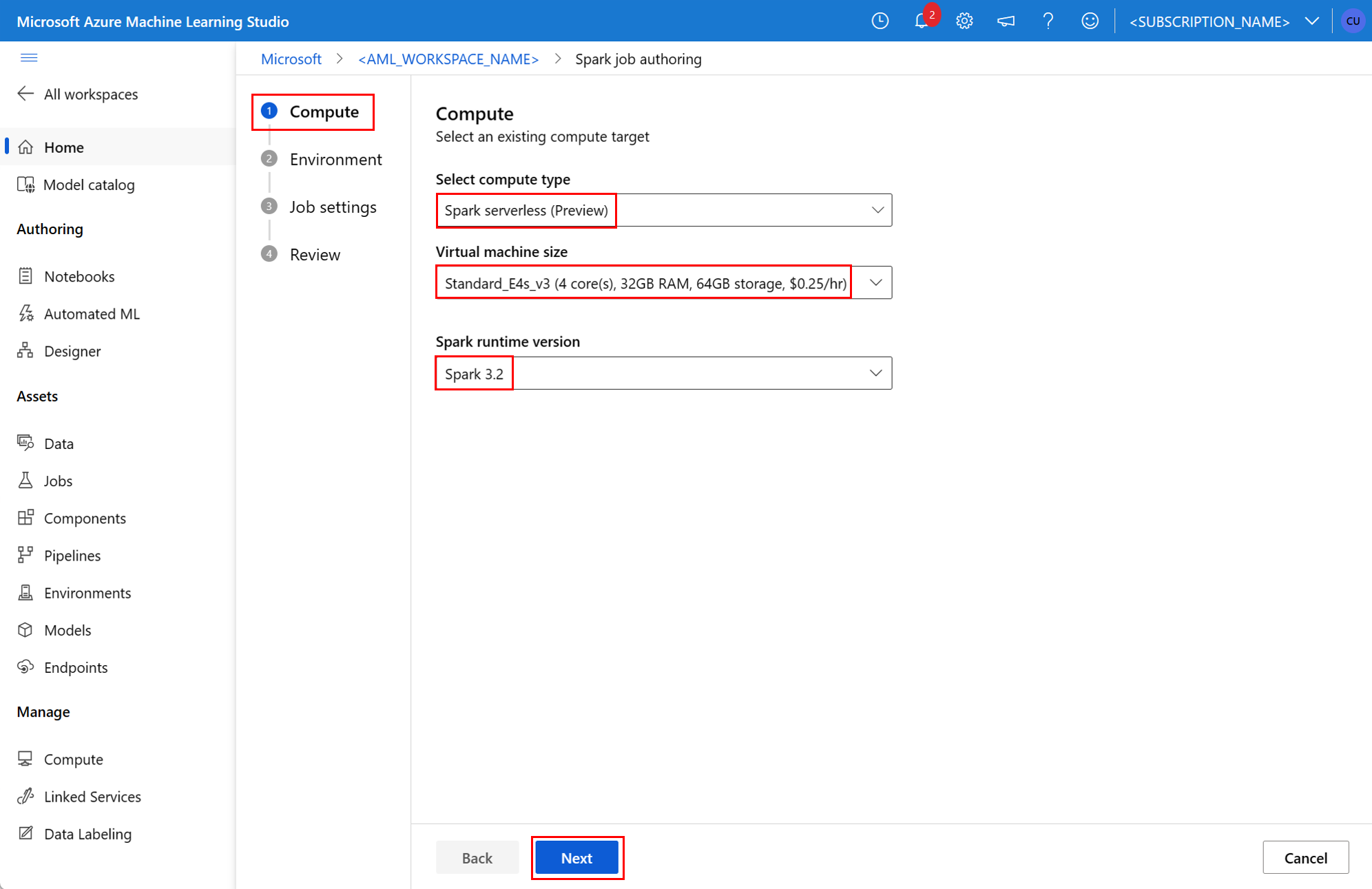
Spark-onderdeel in een pijplijntaak
Een Spark-onderdeel biedt de flexibiliteit om hetzelfde onderdeel in meerdere Azure Machine Learning-pijplijnen te gebruiken als een pijplijnstap.
VAN TOEPASSING OP: Azure CLI ml-extensie v2 (huidige)
De YAML-syntaxis voor een Spark-onderdeel lijkt op de YAML-syntaxis voor spark-taakspecificatie op de meeste manieren. Deze eigenschappen worden anders gedefinieerd in de YAML-specificatie van het Spark-onderdeel:
name- de naam van het Spark-onderdeel.version- de versie van het Spark-onderdeel.display_name- de naam van het Spark-onderdeel dat moet worden weergegeven in de gebruikersinterface en elders.description- de beschrijving van het Spark-onderdeel.inputs- deze eigenschap is vergelijkbaar metinputsde eigenschap die wordt beschreven in de YAML-syntaxis voor spark-taakspecificatie, behalve dat depatheigenschap niet wordt gedefinieerd. Dit codefragment toont een voorbeeld van de spark-onderdeeleigenschapinputs:inputs: titanic_data: type: uri_file mode: directoutputs- deze eigenschap is vergelijkbaar met de eigenschap die wordt beschreven in deoutputsYAML-syntaxis voor spark-taakspecificatie, behalve dat deze depatheigenschap niet definieert. Dit codefragment toont een voorbeeld van de spark-onderdeeleigenschapoutputs:outputs: wrangled_data: type: uri_folder mode: direct
Notitie
Een Spark-onderdeel definieert identitycompute of resources eigenschappen niet. Het YAML-specificatiebestand van de pijplijn definieert deze eigenschappen.
Dit YAML-specificatiebestand bevat een voorbeeld van een Spark-onderdeel:
$schema: http://azureml/sdk-2-0/SparkComponent.json
name: titanic_spark_component
type: spark
version: 1
display_name: Titanic-Spark-Component
description: Spark component for Titanic data
code: ./src
entry:
file: titanic.py
inputs:
titanic_data:
type: uri_file
mode: direct
outputs:
wrangled_data:
type: uri_folder
mode: direct
args: >-
--titanic_data ${{inputs.titanic_data}}
--wrangled_data ${{outputs.wrangled_data}}
conf:
spark.driver.cores: 1
spark.driver.memory: 2g
spark.executor.cores: 2
spark.executor.memory: 2g
spark.dynamicAllocation.enabled: True
spark.dynamicAllocation.minExecutors: 1
spark.dynamicAllocation.maxExecutors: 4
Het Spark-onderdeel dat is gedefinieerd in het bovenstaande YAML-specificatiebestand, kan worden gebruikt in een Azure Machine Learning-pijplijntaak. Zie het YAML-schema voor pijplijntaken voor meer informatie over de YAML-syntaxis waarmee een pijplijntaak wordt gedefinieerd. In dit voorbeeld ziet u een YAML-specificatiebestand voor een pijplijntaak, met een Spark-onderdeel en een serverloze Spark-rekenkracht van Azure Machine Learning:
$schema: http://azureml/sdk-2-0/PipelineJob.json
type: pipeline
display_name: Titanic-Spark-CLI-Pipeline
description: Spark component for Titanic data in Pipeline
jobs:
spark_job:
type: spark
component: ./spark-job-component.yaml
inputs:
titanic_data:
type: uri_file
path: azureml://datastores/workspaceblobstore/paths/data/titanic.csv
mode: direct
outputs:
wrangled_data:
type: uri_folder
path: azureml://datastores/workspaceblobstore/paths/data/wrangled/
mode: direct
identity:
type: managed
resources:
instance_type: standard_e8s_v3
runtime_version: "3.3"
Notitie
Als u een gekoppelde Synapse Spark-pool wilt gebruiken, definieert u de compute eigenschap in het voorbeeldbestand van de YAML-specificatie dat hierboven wordt weergegeven, in plaats van resources de eigenschap.
Het bovenstaande YAML-specificatiebestand kan worden gebruikt in de az ml job create opdracht, met behulp van de --file parameter, om een pijplijntaak te maken zoals wordt weergegeven:
az ml job create --file <YAML_SPECIFICATION_FILE_NAME>.yaml --subscription <SUBSCRIPTION_ID> --resource-group <RESOURCE_GROUP> --workspace-name <AML_WORKSPACE_NAME>
U kunt de bovenstaande opdracht uitvoeren vanuit:
- terminal van een Azure Machine Learning-rekenproces.
- terminal van Visual Studio Code die is verbonden met een Azure Machine Learning-rekenproces.
- uw lokale computer waarop Azure Machine Learning CLI is geïnstalleerd.
Problemen met Spark-taken oplossen
Als u problemen met een Spark-taak wilt oplossen, hebt u toegang tot de logboeken die zijn gegenereerd voor die taak in Azure Machine Learning-studio. De logboeken voor een Spark-taak weergeven:
- Ga in het linkerdeelvenster naar Taken in de gebruikersinterface van Azure Machine Learning-studio
- Het tabblad Alle taken selecteren
- Selecteer de weergavenaamwaarde voor de taak
- Selecteer op de pagina Met taakgegevens het tabblad Uitvoer en logboeken
- Vouw in de Verkenner de map logboeken uit en vouw vervolgens de azureml-map uit
- Toegang tot de Spark-taaklogboeken in de mappen stuurprogramma- en bibliotheekbeheer
Notitie
Als u problemen met Spark-taken wilt oplossen die zijn gemaakt tijdens interactieve gegevens in een notebooksessie, selecteert u Taakdetails in de rechterbovenhoek van de gebruikersinterface van het notebook. Een Spark-taak van een interactieve notebooksessie wordt gemaakt onder de naam notebook-runs van het experiment.
Volgende stappen
Feedback
Binnenkort beschikbaar: In de loop van 2024 zullen we GitHub-problemen geleidelijk uitfaseren als het feedbackmechanisme voor inhoud en deze vervangen door een nieuw feedbacksysteem. Zie voor meer informatie: https://aka.ms/ContentUserFeedback.
Feedback verzenden en weergeven voor