Keras-modellen op schaal trainen met Azure Machine Learning
VAN TOEPASSING OP: Python SDK azure-ai-ml v2 (actueel)
Python SDK azure-ai-ml v2 (actueel)
In dit artikel leert u hoe u uw Keras-trainingsscripts uitvoert met behulp van de Azure Machine Learning Python SDK v2.
De voorbeeldcode in dit artikel maakt gebruik van Azure Machine Learning voor het trainen, registreren en implementeren van een Keras-model dat is gebouwd met behulp van de TensorFlow-back-end. Het model, een deep neural network (DNN) dat is gebouwd met de Keras Python-bibliotheek die wordt uitgevoerd boven op TensorFlow, classificeert handgeschreven cijfers van de populaire MNIST-gegevensset.
Keras is een neurale netwerk-API op hoog niveau die kan worden uitgevoerd op andere populaire DNN-frameworks om de ontwikkeling te vereenvoudigen. Met Azure Machine Learning kunt u snel trainingstaken uitschalen met behulp van elastische cloud-rekenresources. U kunt ook uw trainingsuitvoeringen, versiemodellen, modellen implementeren en nog veel meer bijhouden.
Of u nu een Keras-model ontwikkelt vanaf de basis of een bestaand model in de cloud brengt, Azure Machine Learning kan u helpen bij het bouwen van modellen die gereed zijn voor productie.
Notitie
Als u de Keras-API tf.keras gebruikt die is ingebouwd in TensorFlow en niet het zelfstandige Keras-pakket, raadpleegt u in plaats daarvan TensorFlow-modellen trainen.
Vereisten
Als u wilt profiteren van dit artikel, moet u het volgende doen:
- Toegang tot een Azure-abonnement. Als u er nog geen hebt, maakt u een gratis account.
- Voer de code in dit artikel uit met behulp van een Azure Machine Learning-rekenproces of uw eigen Jupyter-notebook.
- Azure Machine Learning-rekenproces: er zijn geen downloads of installatie nodig
- Voltooi Resources maken om aan de slag te gaan met het maken van een toegewezen notebookserver die vooraf is geladen met de SDK en de voorbeeldopslagplaats.
- Zoek in de map Deep Learning-voorbeelden op de notebookserver een voltooid en uitgebreid notebook door naar deze map te navigeren: python-taken > > > > met één stap > tensorflow > train-hyperparameter-tune-deploy-with-keras.
- Uw Jupyter Notebook-server
- Azure Machine Learning-rekenproces: er zijn geen downloads of installatie nodig
- Download de trainingsscripts keras_mnist.py en utils.py.
U kunt ook een voltooide Jupyter Notebook-versie van deze handleiding vinden op de pagina met GitHub-voorbeelden.
Voordat u de code in dit artikel kunt uitvoeren om een GPU-cluster te maken, moet u een quotumverhoging aanvragen voor uw werkruimte.
De taak instellen
In deze sectie wordt de taak voor training ingesteld door de vereiste Python-pakketten te laden, verbinding te maken met een werkruimte, een rekenresource te maken om een opdrachttaak uit te voeren en een omgeving te maken om de taak uit te voeren.
Verbinding maken met de werkruimte
Eerst moet u verbinding maken met uw Azure Machine Learning-werkruimte. De Azure Machine Learning-werkruimte is de resource op het hoogste niveau voor de service. Het biedt u een centrale locatie om te werken met alle artefacten die u maakt wanneer u Azure Machine Learning gebruikt.
We gebruiken DefaultAzureCredential om toegang te krijgen tot de werkruimte. Deze referentie moet geschikt zijn voor het verwerken van de meeste Azure SDK-verificatiescenario's.
Als DefaultAzureCredential dit niet werkt, raadpleegt azure-identity reference documentation u of Set up authentication voor meer beschikbare referenties.
# Handle to the workspace
from azure.ai.ml import MLClient
# Authentication package
from azure.identity import DefaultAzureCredential
credential = DefaultAzureCredential()Als u liever een browser gebruikt om u aan te melden en te verifiëren, moet u de opmerkingen bij de volgende code verwijderen en in plaats daarvan gebruiken.
# Handle to the workspace
# from azure.ai.ml import MLClient
# Authentication package
# from azure.identity import InteractiveBrowserCredential
# credential = InteractiveBrowserCredential()
Haal vervolgens een ingang op voor de werkruimte door uw abonnements-id, resourcegroepnaam en werkruimtenaam op te geven. Ga als volgt te werk om deze parameters te vinden:
- Zoek de naam van uw werkruimte in de rechterbovenhoek van de werkbalk Azure Machine Learning-studio.
- Selecteer de naam van uw werkruimte om uw resourcegroep en abonnements-id weer te geven.
- Kopieer de waarden voor resourcegroep en abonnements-id naar de code.
# Get a handle to the workspace
ml_client = MLClient(
credential=credential,
subscription_id="<SUBSCRIPTION_ID>",
resource_group_name="<RESOURCE_GROUP>",
workspace_name="<AML_WORKSPACE_NAME>",
)Het resultaat van het uitvoeren van dit script is een werkruimtehandgreep die u gebruikt voor het beheren van andere resources en taken.
Notitie
- Als
MLClientde client wordt gemaakt, wordt er geen verbinding gemaakt met de werkruimte. De initialisatie van de client is lui en wacht op de eerste keer dat de client een oproep moet doen. In dit artikel gebeurt dit tijdens het maken van de berekening.
Een rekenresource maken om de taak uit te voeren
Azure Machine Learning heeft een rekenresource nodig om een taak uit te voeren. Deze resource kan machines met één of meerdere knooppunten zijn met Linux- of Windows-besturingssysteem, of een specifieke rekeninfrastructuur zoals Spark.
In het volgende voorbeeldscript richten we een Linux compute clusterin. U ziet de Azure Machine Learning pricing pagina voor de volledige lijst met VM-grootten en -prijzen. Omdat we voor dit voorbeeld een GPU-cluster nodig hebben, kiezen we een STANDARD_NC6 model en maken we een Azure Machine Learning-rekenproces.
from azure.ai.ml.entities import AmlCompute
gpu_compute_target = "gpu-cluster"
try:
# let's see if the compute target already exists
gpu_cluster = ml_client.compute.get(gpu_compute_target)
print(
f"You already have a cluster named {gpu_compute_target}, we'll reuse it as is."
)
except Exception:
print("Creating a new gpu compute target...")
# Let's create the Azure ML compute object with the intended parameters
gpu_cluster = AmlCompute(
# Name assigned to the compute cluster
name="gpu-cluster",
# Azure ML Compute is the on-demand VM service
type="amlcompute",
# VM Family
size="STANDARD_NC6s_v3",
# Minimum running nodes when there is no job running
min_instances=0,
# Nodes in cluster
max_instances=4,
# How many seconds will the node running after the job termination
idle_time_before_scale_down=180,
# Dedicated or LowPriority. The latter is cheaper but there is a chance of job termination
tier="Dedicated",
)
# Now, we pass the object to MLClient's create_or_update method
gpu_cluster = ml_client.begin_create_or_update(gpu_cluster).result()
print(
f"AMLCompute with name {gpu_cluster.name} is created, the compute size is {gpu_cluster.size}"
)Een taakomgeving maken
Als u een Azure Machine Learning-taak wilt uitvoeren, hebt u een omgeving nodig. Een Azure Machine Learning-omgeving bevat de afhankelijkheden (zoals softwareruntime en bibliotheken) die nodig zijn om uw machine learning-trainingsscript uit te voeren op uw rekenresource. Deze omgeving is vergelijkbaar met een Python-omgeving op uw lokale computer.
Met Azure Machine Learning kunt u een gecureerde (of kant-en-klare) omgeving gebruiken of een aangepaste omgeving maken met behulp van een Docker-installatiekopieën of een Conda-configuratie. In dit artikel maakt u een aangepaste Conda-omgeving voor uw taken met behulp van een Conda YAML-bestand.
Een aangepaste omgeving maken
Als u uw aangepaste omgeving wilt maken, definieert u uw Conda-afhankelijkheden in een YAML-bestand. Maak eerst een map voor het opslaan van het bestand. In dit voorbeeld hebben we de map dependencieseen naam.
import os
dependencies_dir = "./dependencies"
os.makedirs(dependencies_dir, exist_ok=True)Maak vervolgens het bestand in de map met afhankelijkheden. In dit voorbeeld hebben we het bestand conda.ymleen naam.
%%writefile {dependencies_dir}/conda.yaml
name: keras-env
channels:
- conda-forge
dependencies:
- python=3.8
- pip=21.2.4
- pip:
- protobuf~=3.20
- numpy==1.22
- tensorflow-gpu==2.2.0
- keras<=2.3.1
- matplotlib
- azureml-mlflow==1.42.0De specificatie bevat enkele gebruikelijke pakketten (zoals numpy en pip) die u in uw taak gaat gebruiken.
Gebruik vervolgens het YAML-bestand om deze aangepaste omgeving in uw werkruimte te maken en te registreren. De omgeving wordt tijdens runtime verpakt in een Docker-container.
from azure.ai.ml.entities import Environment
custom_env_name = "keras-env"
job_env = Environment(
name=custom_env_name,
description="Custom environment for keras image classification",
conda_file=os.path.join(dependencies_dir, "conda.yaml"),
image="mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu20.04:latest",
)
job_env = ml_client.environments.create_or_update(job_env)
print(
f"Environment with name {job_env.name} is registered to workspace, the environment version is {job_env.version}"
)Zie Software-omgevingen maken en gebruiken in Azure Machine Learning voor meer informatie over het maken en gebruiken van omgevingen.
Uw trainingstaak configureren en verzenden
In deze sectie beginnen we met het introduceren van de gegevens voor training. Vervolgens bespreken we hoe u een trainingstaak uitvoert met behulp van een trainingsscript dat we hebben opgegeven. U leert hoe u de trainingstaak bouwt door de opdracht voor het uitvoeren van het trainingsscript te configureren. Vervolgens dient u de trainingstaak in om uit te voeren in Azure Machine Learning.
De trainingsgegevens verkrijgen
U gebruikt gegevens uit de database Modified National Institute of Standards and Technology (MNIST) met handgeschreven cijfers. Deze gegevens zijn afkomstig van de website van Yan LeCun en opgeslagen in een Azure-opslagaccount.
web_path = "wasbs://datasets@azuremlexamples.blob.core.windows.net/mnist/"Ga naar de website van Yan LeCun voor meer informatie over de MNIST-gegevensset.
Het trainingsscript voorbereiden
In dit artikel hebben we het trainingsscript keras_mnist.py opgegeven. In de praktijk moet u elk aangepast trainingsscript kunnen gebruiken en uitvoeren met Azure Machine Learning zonder dat u uw code hoeft te wijzigen.
Het opgegeven trainingsscript doet het volgende:
- verwerkt de voorverwerking van gegevens, het splitsen van de gegevens in test- en traingegevens;
- traint een model met behulp van de gegevens; en
- retourneert het uitvoermodel.
Tijdens de pijplijnuitvoering gebruikt u MLFlow om de parameters en metrische gegevens te registreren. Zie ML-experimenten en -modellen bijhouden met MLflow voor meer informatie over het inschakelen van MLFlow-tracering.
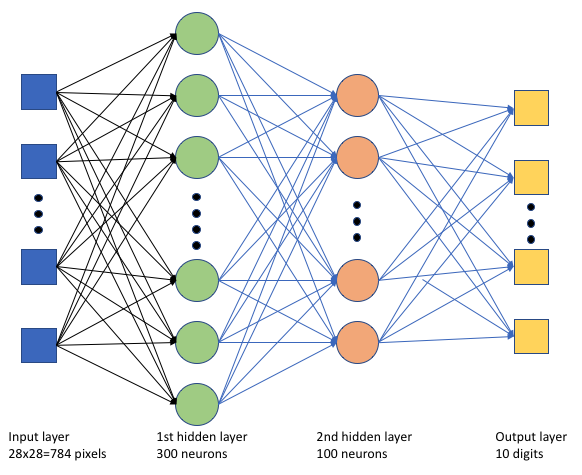
In het trainingsscript keras_mnist.pymaken we een eenvoudig deep neural network (DNN). Deze DNN heeft:
- Een invoerlaag met 28 * 28 = 784 neuronen. Elke neuron vertegenwoordigt een afbeeldings pixel.
- Twee verborgen lagen. De eerste verborgen laag heeft 300 neuronen en de tweede verborgen laag heeft 100 neuronen.
- Een uitvoerlaag met 10 neuronen. Elke neuron vertegenwoordigt een doellabel van 0 tot 9.
De trainingstaak bouwen
Nu u alle assets hebt die nodig zijn om uw taak uit te voeren, is het tijd om deze te bouwen met behulp van de Azure Machine Learning Python SDK v2. In dit voorbeeld maken we een command.
Een Azure Machine Learning command is een resource waarmee alle details worden opgegeven die nodig zijn om uw trainingscode in de cloud uit te voeren. Deze details omvatten de invoer en uitvoer, het type hardware dat moet worden gebruikt, de software die moet worden geïnstalleerd en hoe u uw code uitvoert. De command bevat informatie voor het uitvoeren van één opdracht.
De opdracht configureren
U gebruikt het algemene doel command om het trainingsscript uit te voeren en de gewenste taken uit te voeren. Maak een Command object om de configuratiegegevens van uw trainingstaak op te geven.
from azure.ai.ml import command
from azure.ai.ml import UserIdentityConfiguration
from azure.ai.ml import Input
web_path = "wasbs://datasets@azuremlexamples.blob.core.windows.net/mnist/"
job = command(
inputs=dict(
data_folder=Input(type="uri_folder", path=web_path),
batch_size=50,
first_layer_neurons=300,
second_layer_neurons=100,
learning_rate=0.001,
),
compute=gpu_compute_target,
environment=f"{job_env.name}:{job_env.version}",
code="./src/",
command="python keras_mnist.py --data-folder ${{inputs.data_folder}} --batch-size ${{inputs.batch_size}} --first-layer-neurons ${{inputs.first_layer_neurons}} --second-layer-neurons ${{inputs.second_layer_neurons}} --learning-rate ${{inputs.learning_rate}}",
experiment_name="keras-dnn-image-classify",
display_name="keras-classify-mnist-digit-images-with-dnn",
)De invoer voor deze opdracht omvat de gegevenslocatie, batchgrootte, het aantal neuronen in de eerste en tweede laag en het leerpercentage. U ziet dat we het webpad rechtstreeks als invoer hebben doorgegeven.
Voor de parameterwaarden:
- geef het rekencluster
gpu_compute_target = "gpu-cluster"op dat u hebt gemaakt voor het uitvoeren van deze opdracht; - geef de aangepaste omgeving
keras-envop die u hebt gemaakt voor het uitvoeren van de Azure Machine Learning-taak; - configureert u de opdrachtregelactie zelf, in dit geval is de opdracht
python keras_mnist.py. U kunt de invoer en uitvoer in de opdracht openen via de${{ ... }}notatie; en - metagegevens zoals de weergavenaam en experimentnaam configureren; waarbij een experiment een container is voor alle iteraties die op een bepaald project worden uitgevoerd. Alle taken die onder dezelfde experimentnaam worden ingediend, worden naast elkaar weergegeven in Azure Machine Learning-studio.
- geef het rekencluster
In dit voorbeeld gebruikt u de
UserIdentityopdracht om de opdracht uit te voeren. Als u een gebruikersidentiteit gebruikt, betekent dit dat de opdracht uw identiteit gebruikt om de taak uit te voeren en toegang te krijgen tot de gegevens uit de blob.
De taak verzenden
Het is nu tijd om de taak in te dienen om te worden uitgevoerd in Azure Machine Learning. Deze keer gebruikt create_or_update u deze ml_client.jobskeer.
ml_client.jobs.create_or_update(job)Zodra de taak is voltooid, registreert de taak een model in uw werkruimte (als gevolg van training) en voert u een koppeling uit om de taak in Azure Machine Learning-studio weer te geven.
Waarschuwing
Azure Machine Learning voert trainingsscripts uit door de volledige bronmap te kopiëren. Als u gevoelige gegevens hebt die u niet wilt uploaden, gebruikt u een .ignore-bestand of neemt u het niet op in de bronmap.
Wat gebeurt er tijdens het uitvoeren van de taak
Terwijl de taak wordt uitgevoerd, doorloopt deze de volgende fasen:
Voorbereiden: Er wordt een Docker-installatiekopieën gemaakt op basis van de gedefinieerde omgeving. De installatiekopieën worden geüpload naar het containerregister van de werkruimte en in de cache opgeslagen voor latere uitvoeringen. Logboeken worden ook gestreamd naar de taakgeschiedenis en kunnen worden bekeken om de voortgang te controleren. Als er een gecureerde omgeving is opgegeven, wordt de back-up van de gecureerde omgeving in de cache gebruikt.
Schalen: Het cluster probeert omhoog te schalen als er meer knooppunten nodig zijn om de uitvoering uit te voeren dan momenteel beschikbaar is.
Wordt uitgevoerd: Alle scripts in de scriptmap src worden geüpload naar het rekendoel, gegevensarchieven worden gekoppeld of gekopieerd en het script wordt uitgevoerd. Uitvoer van stdout en de map ./logs worden naar de taakgeschiedenis gestreamd en kunnen worden gebruikt om de taak te bewaken.
Modelhyperparameters afstemmen
U hebt het model getraind met één set parameters. Laten we nu kijken of u de nauwkeurigheid van uw model verder kunt verbeteren. U kunt de hyperparameters van uw model afstemmen en optimaliseren met behulp van de mogelijkheden van sweep Azure Machine Learning.
Als u de hyperparameters van het model wilt afstemmen, definieert u de parameterruimte waarin tijdens de training moet worden gezocht. U doet dit door enkele van de parameters (batch_size, first_layer_neurons, second_layer_neuronsen learning_rate) die aan de trainingstaak zijn doorgegeven, te vervangen door speciale invoer uit het azure.ml.sweep pakket.
from azure.ai.ml.sweep import Choice, LogUniform
# we will reuse the command_job created before. we call it as a function so that we can apply inputs
# we do not apply the 'iris_csv' input again -- we will just use what was already defined earlier
job_for_sweep = job(
batch_size=Choice(values=[25, 50, 100]),
first_layer_neurons=Choice(values=[10, 50, 200, 300, 500]),
second_layer_neurons=Choice(values=[10, 50, 200, 500]),
learning_rate=LogUniform(min_value=-6, max_value=-1),
)Vervolgens configureert u opruimen voor de opdrachttaak met behulp van enkele opruimende parameters, zoals de primaire metrische waarde die u wilt bekijken en het steekproefalgoritmen dat moet worden gebruikt.
In de volgende code gebruiken we willekeurige steekproeven om verschillende configuratiesets van hyperparameters uit te proberen in een poging om onze primaire metrische gegevens te maximaliseren. validation_acc
We definiëren ook een beleid voor vroegtijdige beëindiging , de BanditPolicy. Dit beleid werkt door elke twee iteraties de taak te controleren. Als de primaire metrische waarde validation_accbuiten het bovenste tien procent bereik valt, beëindigt Azure Machine Learning de taak. Hierdoor wordt het model opgeslagen van het blijven verkennen van hyperparameters die geen belofte tonen om de doelmetriek te bereiken.
from azure.ai.ml.sweep import BanditPolicy
sweep_job = job_for_sweep.sweep(
compute=gpu_compute_target,
sampling_algorithm="random",
primary_metric="Accuracy",
goal="Maximize",
max_total_trials=20,
max_concurrent_trials=4,
early_termination_policy=BanditPolicy(slack_factor=0.1, evaluation_interval=2),
)U kunt deze taak nu indienen zoals voorheen. Deze keer voert u een sweep-taak uit die over uw trainingstaak veegt.
returned_sweep_job = ml_client.create_or_update(sweep_job)
# stream the output and wait until the job is finished
ml_client.jobs.stream(returned_sweep_job.name)
# refresh the latest status of the job after streaming
returned_sweep_job = ml_client.jobs.get(name=returned_sweep_job.name)U kunt de taak controleren met behulp van de gebruikersinterfacekoppeling van studio die wordt weergegeven tijdens de taakuitvoering.
Het beste model zoeken en registreren
Zodra alle uitvoeringen zijn voltooid, kunt u de uitvoering vinden die het model heeft geproduceerd met de hoogste nauwkeurigheid.
from azure.ai.ml.entities import Model
if returned_sweep_job.status == "Completed":
# First let us get the run which gave us the best result
best_run = returned_sweep_job.properties["best_child_run_id"]
# lets get the model from this run
model = Model(
# the script stores the model as "keras_dnn_mnist_model"
path="azureml://jobs/{}/outputs/artifacts/paths/keras_dnn_mnist_model/".format(
best_run
),
name="run-model-example",
description="Model created from run.",
type="mlflow_model",
)
else:
print(
"Sweep job status: {}. Please wait until it completes".format(
returned_sweep_job.status
)
)U kunt dit model vervolgens registreren.
registered_model = ml_client.models.create_or_update(model=model)Het model implementeren als een online-eindpunt
Nadat u uw model hebt geregistreerd, kunt u het implementeren als een online-eindpunt, dat wil gezegd, als een webservice in de Azure-cloud.
Voor het implementeren van een machine learning-service hebt u doorgaans het volgende nodig:
- De modelassets die u wilt implementeren. Deze assets omvatten het bestand en de metagegevens van het model die u al hebt geregistreerd in uw trainingstaak.
- Sommige code die moet worden uitgevoerd als een service. De code voert het model uit op een bepaalde invoeraanvraag (een invoerscript). Dit invoerscript ontvangt gegevens die zijn verzonden naar een geïmplementeerde webservice en geeft deze door aan het model. Nadat het model de gegevens heeft verwerkt, retourneert het script het antwoord van het model op de client. Het script is specifiek voor uw model en moet de gegevens begrijpen die het model verwacht en retourneert. Wanneer u een MLFlow-model gebruikt, maakt Azure Machine Learning dit script automatisch voor u.
Zie Een machine learning-model implementeren en beoordelen met een beheerd online-eindpunt met behulp van Python SDK v2 voor meer informatie over implementatie.
Een nieuw online-eindpunt maken
Als eerste stap voor het implementeren van uw model moet u uw online-eindpunt maken. De eindpuntnaam moet uniek zijn in de hele Azure-regio. Voor dit artikel maakt u een unieke naam met behulp van een UUID (Universally Unique Identifier).
import uuid
# Creating a unique name for the endpoint
online_endpoint_name = "keras-dnn-endpoint-" + str(uuid.uuid4())[:8]from azure.ai.ml.entities import (
ManagedOnlineEndpoint,
ManagedOnlineDeployment,
Model,
Environment,
)
# create an online endpoint
endpoint = ManagedOnlineEndpoint(
name=online_endpoint_name,
description="Classify handwritten digits using a deep neural network (DNN) using Keras",
auth_mode="key",
)
endpoint = ml_client.begin_create_or_update(endpoint).result()
print(f"Endpint {endpoint.name} provisioning state: {endpoint.provisioning_state}")Nadat u het eindpunt hebt gemaakt, kunt u het als volgt ophalen:
endpoint = ml_client.online_endpoints.get(name=online_endpoint_name)
print(
f'Endpint "{endpoint.name}" with provisioning state "{endpoint.provisioning_state}" is retrieved'
)Het model implementeren op het eindpunt
Nadat u het eindpunt hebt gemaakt, kunt u het model implementeren met het invoerscript. Een eindpunt kan meerdere implementaties hebben. Met behulp van regels kan het eindpunt vervolgens verkeer naar deze implementaties leiden.
In de volgende code maakt u één implementatie die 100% van het binnenkomende verkeer verwerkt. We hebben een willekeurige kleurnaam (tff-blauw) opgegeven voor de implementatie. U kunt ook een andere naam gebruiken, zoals tff-groen of tff-rood voor de implementatie. De code voor het implementeren van het model op het eindpunt doet het volgende:
- implementeert de beste versie van het model dat u eerder hebt geregistreerd;
- beoordeelt het model met behulp van het
score.pybestand; en - gebruikt de aangepaste omgeving (die u eerder hebt gemaakt) om deductie uit te voeren.
from azure.ai.ml.entities import ManagedOnlineDeployment, CodeConfiguration
model = registered_model
# create an online deployment.
blue_deployment = ManagedOnlineDeployment(
name="keras-blue-deployment",
endpoint_name=online_endpoint_name,
model=model,
# code_configuration=CodeConfiguration(code="./src", scoring_script="score.py"),
instance_type="Standard_DS3_v2",
instance_count=1,
)
blue_deployment = ml_client.begin_create_or_update(blue_deployment).result()Notitie
Verwacht dat het even duurt voordat deze implementatie is voltooid.
Het geïmplementeerde model testen
Nu u het model hebt geïmplementeerd op het eindpunt, kunt u de uitvoer van het geïmplementeerde model voorspellen met behulp van de invoke methode op het eindpunt.
Als u het eindpunt wilt testen, hebt u enkele testgegevens nodig. Laten we de testgegevens die we in ons trainingsscript hebben gebruikt, lokaal downloaden.
import urllib.request
data_folder = os.path.join(os.getcwd(), "data")
os.makedirs(data_folder, exist_ok=True)
urllib.request.urlretrieve(
"https://azureopendatastorage.blob.core.windows.net/mnist/t10k-images-idx3-ubyte.gz",
filename=os.path.join(data_folder, "t10k-images-idx3-ubyte.gz"),
)
urllib.request.urlretrieve(
"https://azureopendatastorage.blob.core.windows.net/mnist/t10k-labels-idx1-ubyte.gz",
filename=os.path.join(data_folder, "t10k-labels-idx1-ubyte.gz"),
)Laad deze in een testgegevensset.
from src.utils import load_data
X_test = load_data(os.path.join(data_folder, "t10k-images-idx3-ubyte.gz"), False)
y_test = load_data(
os.path.join(data_folder, "t10k-labels-idx1-ubyte.gz"), True
).reshape(-1)Kies 30 willekeurige steekproeven uit de testset en schrijf ze naar een JSON-bestand.
import json
import numpy as np
# find 30 random samples from test set
n = 30
sample_indices = np.random.permutation(X_test.shape[0])[0:n]
test_samples = json.dumps({"input_data": X_test[sample_indices].tolist()})
# test_samples = bytes(test_samples, encoding='utf8')
with open("request.json", "w") as outfile:
outfile.write(test_samples)Vervolgens kunt u het eindpunt aanroepen, de geretourneerde voorspellingen afdrukken en deze samen met de invoerafbeeldingen tekenen. Gebruik rode tekstkleur en omgekeerde afbeelding (wit op zwart) om de verkeerd geclassificeerde voorbeelden te markeren.
import matplotlib.pyplot as plt
# predict using the deployed model
result = ml_client.online_endpoints.invoke(
endpoint_name=online_endpoint_name,
request_file="./request.json",
deployment_name="keras-blue-deployment",
)
# compare actual value vs. the predicted values:
i = 0
plt.figure(figsize=(20, 1))
for s in sample_indices:
plt.subplot(1, n, i + 1)
plt.axhline("")
plt.axvline("")
# use different color for misclassified sample
font_color = "red" if y_test[s] != result[i] else "black"
clr_map = plt.cm.gray if y_test[s] != result[i] else plt.cm.Greys
plt.text(x=10, y=-10, s=result[i], fontsize=18, color=font_color)
plt.imshow(X_test[s].reshape(28, 28), cmap=clr_map)
i = i + 1
plt.show()Notitie
Omdat de nauwkeurigheid van het model hoog is, moet u de cel mogelijk een paar keer uitvoeren voordat u een verkeerd geclassificeerd voorbeeld ziet.
Resources opschonen
Als u het eindpunt niet gebruikt, verwijdert u het om te stoppen met het gebruik van de resource. Zorg ervoor dat er geen andere implementaties het eindpunt gebruiken voordat u het verwijdert.
ml_client.online_endpoints.begin_delete(name=online_endpoint_name)Notitie
Verwacht dat het even duurt voordat deze opschoonactie is voltooid.
Volgende stappen
In dit artikel hebt u een Keras-model getraind en geregistreerd. U hebt het model ook geïmplementeerd op een online-eindpunt. Zie deze andere artikelen voor meer informatie over Azure Machine Learning.