Toegang tot gegevens in een taak
VAN TOEPASSING OP: Azure CLI ml extension v2 (current)Python SDK azure-ai-ml v2 (current)
Azure CLI ml extension v2 (current)Python SDK azure-ai-ml v2 (current)
In dit artikel leert u het volgende:
- Gegevens lezen uit Azure Storage in een Azure Machine Learning-taak.
- Gegevens schrijven van uw Azure Machine Learning-taak naar Azure Storage.
- Het verschil tussen koppelings - en downloadmodi .
- Gebruikersidentiteit en beheerde identiteit gebruiken voor toegang tot gegevens.
- Koppelinstellingen die beschikbaar zijn in een taak.
- Optimale koppelinstellingen voor veelvoorkomende scenario's.
- Toegang krijgen tot V1-gegevensassets.
Vereisten
Een Azure-abonnement. Als u nog geen abonnement op Azure hebt, maak dan een gratis account aan voordat u begint. Probeer de gratis of betaalde versie van Azure Machine Learning.
Een Azure Machine Learning-werkruimte
Snelstart
Voordat u de gedetailleerde opties verkent die voor u beschikbaar zijn wanneer u gegevens opent, beschrijven we eerst de relevante codefragmenten voor gegevenstoegang.
Gegevens lezen uit Azure Storage in een Azure Machine Learning-taak
In dit voorbeeld verzendt u een Azure Machine Learning-taak die toegang heeft tot gegevens uit een openbaar Blob Storage-account. U kunt het fragment echter aanpassen om toegang te krijgen tot uw eigen gegevens in een privé-Azure Storage-account. Werk het pad bij zoals hier wordt beschreven. Azure Machine Learning verwerkt naadloos verificatie voor cloudopslag, met Microsoft Entra Passthrough. Wanneer u een taak verzendt, kunt u het volgende kiezen:
- Gebruikersidentiteit: Passthrough uw Microsoft Entra-identiteit voor toegang tot de gegevens
- Beheerde identiteit: gebruik de beheerde identiteit van het rekendoel om toegang te krijgen tot gegevens
- Geen: Geef geen identiteit op voor toegang tot de gegevens. Geen gebruiken bij het gebruik van gegevensarchieven op basis van referenties (sleutel-/SAS-token) of bij het openen van openbare gegevens
Tip
Als u sleutels of SAS-tokens gebruikt om te verifiëren, raden we u aan een Azure Machine Learning-gegevensarchief te maken, omdat de runtime automatisch verbinding maakt met opslag zonder blootstelling van de sleutel/token.
from azure.ai.ml import command, Input, MLClient, UserIdentityConfiguration, ManagedIdentityConfiguration
from azure.ai.ml.entities import Data
from azure.ai.ml.constants import AssetTypes, InputOutputModes
from azure.identity import DefaultAzureCredential
# Set your subscription, resource group and workspace name:
subscription_id = "<SUBSCRIPTION_ID>"
resource_group = "<RESOURCE_GROUP>"
workspace = "<AML_WORKSPACE_NAME>"
# connect to the AzureML workspace
ml_client = MLClient(
DefaultAzureCredential(), subscription_id, resource_group, workspace
)
# ==============================================================
# Set the URI path for the data.
# Supported `path` formats for input include:
# local: `./<path>
# Blob: wasbs://<container_name>@<account_name>.blob.core.windows.net/<path>
# ADLS: abfss://<file_system>@<account_name>.dfs.core.windows.net/<path>
# Datastore: azureml://datastores/<data_store_name>/paths/<path>
# Data Asset: azureml:<my_data>:<version>
# Supported `path` format for output is:
# Datastore: azureml://datastores/<data_store_name>/paths/<path>
# We set the input path to a file on a public blob container
# ==============================================================
path = "wasbs://data@azuremlexampledata.blob.core.windows.net/titanic.csv"
# ==============================================================
# What type of data does the path point to? Options include:
# data_type = AssetTypes.URI_FILE # a specific file
# data_type = AssetTypes.URI_FOLDER # a folder
# data_type = AssetTypes.MLTABLE # an mltable
# The path we set above is a specific file
# ==============================================================
data_type = AssetTypes.URI_FILE
# ==============================================================
# Set the mode. The popular modes include:
# mode = InputOutputModes.RO_MOUNT # Read-only mount on the compute target
# mode = InputOutputModes.DOWNLOAD # Download the data to the compute target
# ==============================================================
mode = InputOutputModes.RO_MOUNT
# ==============================================================
# You can set the identity you want to use in a job to access the data. Options include:
# identity = UserIdentityConfiguration() # Use the user's identity
# identity = ManagedIdentityConfiguration() # Use the compute target managed identity
# ==============================================================
# This example accesses public data, so we don't need an identity.
# You also set identity to None if you use a credential-based datastore
identity = None
# Set the input for the job:
inputs = {
"input_data": Input(type=data_type, path=path, mode=mode)
}
# This command job uses the head Linux command to print the first 10 lines of the file
job = command(
command="head ${{inputs.input_data}}",
inputs=inputs,
environment="azureml://registries/azureml/environments/sklearn-1.1/versions/4",
compute="cpu-cluster",
identity=identity,
)
# Submit the command
ml_client.jobs.create_or_update(job)
Gegevens schrijven van uw Azure Machine Learning-taak naar Azure Storage
In dit voorbeeld verzendt u een Azure Machine Learning-taak waarmee gegevens naar uw standaard Azure Machine Learning-gegevensarchief worden geschreven. U kunt desgewenst de name waarde van uw gegevensasset instellen om een gegevensasset te maken in de uitvoer.
from azure.ai.ml import command, Input, Output, MLClient
from azure.ai.ml.constants import AssetTypes, InputOutputModes
from azure.identity import DefaultAzureCredential
# Set your subscription, resource group and workspace name:
subscription_id = "<SUBSCRIPTION_ID>"
resource_group = "<RESOURCE_GROUP>"
workspace = "<AML_WORKSPACE_NAME>"
# connect to the AzureML workspace
ml_client = MLClient(
DefaultAzureCredential(), subscription_id, resource_group, workspace
)
# ==============================================================
# Set the URI path for the data.
# Supported `path` formats for input include:
# local: `./<path>
# Blob: wasbs://<container_name>@<account_name>.blob.core.windows.net/<path>
# ADLS: abfss://<file_system>@<account_name>.dfs.core.windows.net/<path>
# Datastore: azureml://datastores/<data_store_name>/paths/<path>
# Data Asset: azureml:<my_data>:<version>
# Supported `path` format for output is:
# Datastore: azureml://datastores/<data_store_name>/paths/<path>
# As an example, we set the input path to a file on a public blob container
# As an example, we set the output path to a folder in the default datastore
# ==============================================================
input_path = "wasbs://data@azuremlexampledata.blob.core.windows.net/titanic.csv"
output_path = "azureml://datastores/workspaceblobstore/paths/quickstart-output/titanic.csv"
# ==============================================================
# What type of data are you pointing to?
# AssetTypes.URI_FILE (a specific file)
# AssetTypes.URI_FOLDER (a folder)
# AssetTypes.MLTABLE (a table)
# The path we set above is a specific file
# ==============================================================
data_type = AssetTypes.URI_FILE
# ==============================================================
# Set the input mode. The most commonly-used modes:
# InputOutputModes.RO_MOUNT
# InputOutputModes.DOWNLOAD
# Set the mode to Read Only (RO) to mount the data
# ==============================================================
input_mode = InputOutputModes.RO_MOUNT
# ==============================================================
# Set the output mode. The most commonly-used modes:
# InputOutputModes.RW_MOUNT
# InputOutputModes.UPLOAD
# Set the mode to Read Write (RW) to mount the data
# ==============================================================
output_mode = InputOutputModes.RW_MOUNT
# Set the input and output for the job:
inputs = {
"input_data": Input(type=data_type, path=input_path, mode=input_mode)
}
outputs = {
"output_data": Output(type=data_type,
path=output_path,
mode=output_mode,
# optional: if you want to create a data asset from the output,
# then uncomment `name` (`name` can be set without setting `version`, and in this way, we will set `version` automatically for you)
# name = "<name_of_data_asset>", # use `name` and `version` to create a data asset from the output
# version = "<version>",
)
}
# This command job copies the data to your default Datastore
job = command(
command="cp ${{inputs.input_data}} ${{outputs.output_data}}",
inputs=inputs,
outputs=outputs,
environment="azureml://registries/azureml/environments/sklearn-1.1/versions/4",
compute="cpu-cluster",
)
# Submit the command
ml_client.jobs.create_or_update(job)
De Azure Machine Learning-gegevensruntime
Wanneer u een taak verzendt, bepaalt de Azure Machine Learning-gegevensruntime de gegevensbelasting, van de opslaglocatie naar het rekendoel. De Azure Machine Learning-gegevensruntime is geoptimaliseerd voor snelheid en efficiëntie voor machine learning-taken. De belangrijkste voordelen zijn:
- Gegevens worden geladen in de Rust-taal, een taal die bekend staat om hoge snelheid en hoge geheugenefficiëntie. Voor gelijktijdige gegevensdownloads voorkomt Rust problemen met Python Global Interpreter Lock (GIL)
- Lichtgewicht; Rust heeft geen afhankelijkheden van andere technologieën, bijvoorbeeld JVM. Als gevolg hiervan wordt de runtime snel geïnstalleerd en worden er geen extra resources (CPU, geheugen) op het rekendoel verbruikt
- Gegevens laden met meerdere processen (parallel)
- Maakt gegevens vooraf als achtergrondtaak op de CPU('s) om een beter gebruik van de GPU('s) mogelijk te maken bij het uitvoeren van deep learning
- Naadloze verificatieafhandeling voor cloudopslag
- Biedt opties voor het koppelen van gegevens (stream) of het downloaden van alle gegevens. Ga voor meer informatie naar de secties Koppelen (streamen) en Downloaden .
- Naadloze integratie met fsspec - een geïntegreerde Python-interface voor lokale, externe en ingesloten bestandssystemen en byteopslag.
Tip
U wordt aangeraden gebruik te maken van de Azure Machine Learning-gegevensruntime, in plaats van uw eigen koppelings-/downloadmogelijkheid te maken in uw trainingscode (clientcode). We hebben beperkingen waargenomen voor opslagdoorvoer wanneer de clientcode Python gebruikt om gegevens te downloaden uit de opslag, vanwege problemen met Global Interpreter Lock (GIL).
Paden
Wanneer u een gegevensinvoer/uitvoer aan een taak opgeeft, moet u een path parameter opgeven die verwijst naar de gegevenslocatie. In deze tabel ziet u de verschillende gegevenslocaties die door Azure Machine Learning worden ondersteund en worden ook parametervoorbeelden weergegeven path :
| Locatie | Voorbeelden | Invoer | Uitvoer |
|---|---|---|---|
| Een pad op uw lokale computer | ./home/username/data/my_data |
J | N |
| Een pad op een openbare HTTP(s)-server | https://raw.githubusercontent.com/pandas-dev/pandas/main/doc/data/titanic.csv |
J | N |
| Een pad in Azure Storage | wasbs://<container_name>@<account_name>.blob.core.windows.net/<path>abfss://<file_system>@<account_name>.dfs.core.windows.net/<path> |
Y, alleen voor verificatie op basis van identiteiten. | N |
| Een pad in een Azure Machine Learning-gegevensarchief | azureml://datastores/<data_store_name>/paths/<path> |
J | J |
| Een pad naar een gegevensasset | azureml:<my_data>:<version> |
J | N, maar u kunt een gegevensasset gebruiken name en version maken op basis van uitvoer |
Modi
Wanneer u een taak uitvoert met gegevensinvoer/-uitvoer, kunt u kiezen uit de volgende modusopties :
ro_mount: Koppel de opslaglocatie, als alleen-lezen op het rekendoel van de lokale schijf (SSD).rw_mount: Koppel de opslaglocatie als lees-schrijfbewerking op het rekendoel van de lokale schijf (SSD).download: Download de gegevens van de opslaglocatie naar het rekendoel van de lokale schijf (SSD).upload: Upload gegevens van het rekendoel naar de opslaglocatie.eval_mount/eval_download: Deze modi zijn uniek voor MLTable. In sommige scenario's kan een MLTable bestanden opleveren die zich mogelijk in een ander opslagaccount bevinden dan het opslagaccount dat als host fungeert voor het MLTable-bestand. Of een MLTable kan de gegevens die zich in de opslagresource bevinden, subsets maken of verplaatsen. Deze weergave van de subset/shuffle wordt alleen zichtbaar als de Azure Machine Learning-gegevensruntime het MLTable-bestand daadwerkelijk evalueert. In dit diagram ziet u bijvoorbeeld hoe een MLTable die wordt gebruikt meteval_mountofeval_downloadafbeeldingen kan maken uit twee verschillende opslagcontainers, en een aantekeningenbestand in een ander opslagaccount en vervolgens koppelt/downloadt aan het bestandssysteem van het externe rekendoel.
De
camera1map,camera2map enannotations.csvbestand zijn vervolgens toegankelijk op het bestandssysteem van het rekendoel in de mapstructuur:/INPUT_DATA ├── account-a │ ├── container1 │ │ └── camera1 │ │ ├── image1.jpg │ │ └── image2.jpg │ └── container2 │ └── camera2 │ ├── image1.jpg │ └── image2.jpg └── account-b └── container1 └── annotations.csvdirect: Mogelijk wilt u gegevens rechtstreeks vanuit een URI lezen via andere API's in plaats van de Azure Machine Learning-gegevensruntime te doorlopen. U wilt bijvoorbeeld toegang krijgen tot gegevens in een s3-bucket (met een url voor virtuele host of padstijlhttps) met behulp van de boto s3-client. U kunt de URI van de invoer verkrijgen als een tekenreeks met dedirectmodus. U ziet het gebruik van de directe modus in Spark-taken, omdat despark.read_*()methoden weten hoe de URI's moeten worden verwerkt. Voor niet-Spark-taken is het uw verantwoordelijkheid om toegangsreferenties te beheren. U moet bijvoorbeeld expliciet gebruikmaken van reken-MSI of anderszins brokertoegang.

In deze tabel ziet u de mogelijke modi voor verschillende combinaties van typen/modus/invoer/uitvoer:
| Type | Invoer/uitvoer | upload |
download |
ro_mount |
rw_mount |
direct |
eval_download |
eval_mount |
|---|---|---|---|---|---|---|---|---|
uri_folder |
Invoer | ✓ | ✓ | ✓ | ||||
uri_file |
Invoer | ✓ | ✓ | ✓ | ||||
mltable |
Invoer | ✓ | ✓ | ✓ | ✓ | ✓ | ||
uri_folder |
Uitvoer | ✓ | ✓ | |||||
uri_file |
Uitvoer | ✓ | ✓ | |||||
mltable |
Uitvoer | ✓ | ✓ | ✓ |
Downloaden
In de downloadmodus worden alle invoergegevens gekopieerd naar de lokale schijf (SSD) van het rekendoel. De Azure Machine Learning-gegevensruntime start het script voor gebruikerstraining, zodra alle gegevens zijn gekopieerd. Wanneer het gebruikersscript wordt gestart, worden gegevens van de lokale schijf gelezen, net als andere bestanden. Wanneer de taak is voltooid, worden de gegevens verwijderd uit de schijf van het rekendoel.
| Voordelen | Nadelen |
|---|---|
| Wanneer de training wordt gestart, zijn alle gegevens beschikbaar op de lokale schijf (SSD) van het rekendoel voor het trainingsscript. Er is geen Interactie tussen Azure-opslag en netwerk vereist. | De gegevensset moet volledig op een rekendoelschijf passen. |
| Nadat het gebruikersscript is gestart, zijn er geen afhankelijkheden van de betrouwbaarheid van opslag/netwerk. | De volledige gegevensset wordt gedownload (als training willekeurig slechts een klein deel van een gegevens moet selecteren, wordt veel van de download vervolgens verspild). |
| Azure Machine Learning-gegevensruntime kan de download parallelliseren (aanzienlijk verschil in veel kleine bestanden) en maximale netwerk-/opslagdoorvoer. | De taak wacht totdat alle gegevens naar de lokale schijf van het rekendoel worden gedownload. Voor een ingediende deep learning-taak worden de GPU's inactief totdat de gegevens gereed zijn. |
| Er is geen onvermijdelijke overhead toegevoegd door de FUSE-laag (roundtrip: aanroep gebruikersruimte in gebruikersscript → kernel → gebruikersruimte fuse daemon → kernel → antwoord op gebruikersscript in gebruikersruimte) | Opslagwijzigingen worden niet doorgevoerd in de gegevens nadat het downloaden is voltooid. |
Wanneer moet u downloaden gebruiken
- De gegevens zijn klein genoeg om op de schijf van het rekendoel te passen zonder tussenkomst van andere training
- De training maakt gebruik van de meeste of alle gegevenssets
- De training leest bestanden uit een gegevensset meer dan één keer
- De training moet naar willekeurige posities van een groot bestand springen
- Het is ok om te wachten totdat alle gegevens worden gedownload voordat de training wordt gestart
Beschikbare downloadinstellingen
U kunt de downloadinstellingen afstemmen met deze omgevingsvariabelen in uw taak:
| Naam van omgevingsvariabele | Type | Standaardwaarde | Beschrijving |
|---|---|---|---|
RSLEX_DOWNLOADER_THREADS |
u64 | NUMBER_OF_CPU_CORES * 4 |
Het aantal gelijktijdige threads downloaden kan worden gebruikt |
AZUREML_DATASET_HTTP_RETRY_COUNT |
u64 | 7 | Aantal nieuwe pogingen van afzonderlijke opslag/ http aanvraag om te herstellen van tijdelijke fouten. |
In uw taak kunt u de bovenstaande standaardinstellingen wijzigen door de omgevingsvariabelen in te stellen, bijvoorbeeld:
Ter beknoptheid laten we alleen zien hoe u de omgevingsvariabelen in de taak definieert.
from azure.ai.ml import command
env_var = {
"RSLEX_DOWNLOADER_THREADS": 64,
"AZUREML_DATASET_HTTP_RETRY_COUNT": 10
}
job = command(
environment_variables=env_var
)
Metrische prestatiegegevens downloaden
De VM-grootte van uw rekendoel heeft een effect op de downloadtijd van uw gegevens. Specifiek:
- Het aantal kernen. Hoe meer kernen beschikbaar zijn, hoe meer gelijktijdigheid en dus snellere downloadsnelheid.
- De verwachte netwerkbandbreedte. Elke VM in Azure heeft een maximale doorvoer van de NIC (Network Interface Card).
Notitie
Voor A100 GPU-VM's kan de Azure Machine Learning-gegevensruntime de NIC (netwerkinterfacekaart) verzadigen bij het downloaden van gegevens naar het rekendoel (~24 Gbit/s): de theoretische maximale doorvoer mogelijk.
In deze tabel ziet u de downloadprestaties die de Azure Machine Learning-gegevensruntime kan verwerken voor een bestand van 100 GB op een Standard_D15_v2 VIRTUELE machine (20cores, 25 Gbit/s Netwerkdoorvoer):
| Gegevensstructuur | Alleen downloaden (secs) | MD5 (secs) downloaden en berekenen | Doorvoer bereikt (Gbit/s) |
|---|---|---|---|
| 10 x 10 GB Bestanden | 55.74 | 260.97 | 14,35 Gbit/s |
| 100 x 1 GB bestanden | 58.09 | 259.47 | 13.77 Gbit/s |
| 1 x 100 GB-bestand | 96.13 | 300.61 | 8.32 Gbit/s |
We kunnen zien dat een groter bestand, opgesplitst in kleinere bestanden, de downloadprestaties kan verbeteren vanwege parallelle uitvoering. U wordt aangeraden bestanden te klein te maken (minder dan 4 MB), omdat de benodigde tijd voor verzendingen van opslagaanvragen toeneemt ten opzichte van de tijd die nodig is om de nettolading te downloaden. Lees veel kleine bestanden voor meer informatie.
Koppelen (streaming)
In de koppelmodus maakt de Azure Machine Learning-gegevensfunctie gebruik van de FUNCTIE FUSE (bestandssysteem in gebruikersruimte) om een geëmuleerd bestandssysteem te maken. In plaats van alle gegevens te downloaden naar de lokale schijf (SSD) van het rekendoel, kan de runtime in realtime reageren op de scriptacties van de gebruiker. Bijvoorbeeld 'open file', 'read 2-KB chunk from position X', 'list directory content'.
| Voordelen | Nadelen |
|---|---|
| Gegevens die de lokale schijfcapaciteit van het rekendoel overschrijden, kunnen worden gebruikt (niet beperkt door rekenhardware) | Extra overhead van de Linux FUSE-module. |
| Geen vertraging aan het begin van de training (in tegenstelling tot de downloadmodus). | Afhankelijk van het codegedrag van de gebruiker (als de trainingscode die opeenvolgend kleine bestanden in één threadkoppeling leest, ook gegevens uit de opslag aanvraagt, is het mogelijk dat de doorvoer van het netwerk of de opslag niet wordt gemaximaliseerd). |
| Meer beschikbare instellingen om af te stemmen op een gebruiksscenario. | Geen windows-ondersteuning. |
| Alleen gegevens die nodig zijn voor training, worden gelezen uit de opslag. |
Wanneer gebruikt u Koppelen
- De gegevens zijn groot en passen niet op de lokale schijf van het rekendoel.
- Elk afzonderlijk rekenknooppunt in een cluster hoeft de volledige gegevensset niet te lezen (willekeurige bestanden of rijen in csv-bestandsselectie, enzovoort).
- Vertragingen die wachten tot alle gegevens worden gedownload voordat de training wordt gestart, kunnen een probleem worden (niet-actieve GPU-tijd).
Beschikbare koppelingsinstellingen
U kunt de koppelingsinstellingen afstemmen met deze omgevingsvariabelen in uw taak:
| Naam van env-variabele | Type | Default value | Beschrijving |
|---|---|---|---|
DATASET_MOUNT_ATTRIBUTE_CACHE_TTL |
u64 | Niet ingesteld (cache verloopt nooit) | Tijd, in milliseconden, die nodig is om de oproep in de getattr cache te houden en om volgende aanvragen van deze gegevens uit de opslag te voorkomen. |
DATASET_RESERVED_FREE_DISK_SPACE |
u64 | 150 MB | Bedoeld voor een systeemconfiguratie om de berekening in orde te houden. Ongeacht de waarden die de andere instellingen hebben, maakt Azure Machine Learning-gegevensruntime geen gebruik van de laatste RESERVED_FREE_DISK_SPACE bytes schijfruimte. |
DATASET_MOUNT_CACHE_SIZE |
usize | Onbeperkt | Hiermee bepaalt u hoeveel schijfruimte kan worden gekoppeld. Met een positieve waarde wordt de absolute waarde in bytes ingesteld. Negatieve waarde bepaalt hoeveel schijfruimte vrij moet blijven. Deze tabel biedt meer opties voor schijfcache. Ondersteunt KB, MB en GB modifiers voor het gemak. |
DATASET_MOUNT_FILE_CACHE_PRUNE_THRESHOLD |
f64 | 1.0 | Volumekoppeling start cachesnoeien wanneer de cache wordt opgevuld tot AVAILABLE_CACHE_SIZE * DATASET_MOUNT_FILE_CACHE_PRUNE_THRESHOLD. Moet tussen 0 en 1 zijn. Als u deze < instelling 1 instelt, wordt het verwijderen van de achtergrondcache eerder geactiveerd. AVAILABLE_CACHE_SIZE is geen omgevingsvariabele die u rechtstreeks kunt wijzigen of weergeven. In deze context verwijst het naar het 'aantal bytes dat het systeem berekent als beschikbaar voor caching'. Deze waarde is afhankelijk van factoren zoals schijfgrootte, de hoeveelheid schijfruimte die nodig is voor de systeemstatus en configuraties die zijn ingesteld in omgevingsvariabelen (zoals DATASET_RESERVED_FREE_DISK_SPACE en DATASET_MOUNT_CACHE_SIZE). |
DATASET_MOUNT_FILE_CACHE_PRUNE_TARGET |
f64 | 0,7 | Het verwijderen van cache probeert ten minste (1-DATASET_MOUNT_FILE_CACHE_PRUNE_TARGET) van een cacheruimte vrij te maken. |
DATASET_MOUNT_READ_BLOCK_SIZE |
usize | 2 MB | Grootte van leesblok streamen. Wanneer het bestand groot genoeg is, vraagt u ten minste DATASET_MOUNT_READ_BLOCK_SIZE gegevens op uit de opslag en cache, zelfs wanneer de fuse aangevraagde leesbewerking minder was. |
DATASET_MOUNT_READ_BUFFER_BLOCK_COUNT |
usize | 32 | Aantal blokken dat vooraf moet worden gezet (leesblok k activeert achtergrondvoorfetching van blokken k+1, ..., k.+DATASET_MOUNT_READ_BUFFER_BLOCK_COUNT) |
DATASET_MOUNT_READ_THREADS |
usize | NUMBER_OF_CORES * 4 |
Aantal achtergrondvoorvoegingsthreads. |
DATASET_MOUNT_BLOCK_BASED_CACHE_ENABLED |
bool | false | Schakel caching op basis van blokken in. |
DATASET_MOUNT_MEMORY_CACHE_SIZE |
usize | 128 MB | Alleen van toepassing op opslaan in cache op basis van blokken. De grootte van cacheopslag op basis van RAM-geheugenblokken kan worden gebruikt. Een waarde van 0 schakelt geheugencache volledig uit. |
DATASET_MOUNT_BLOCK_FILE_CACHE_ENABLED |
bool | true | Alleen van toepassing op opslaan in cache op basis van blokken. Als deze is ingesteld op waar, gebruikt blokgebaseerde caching lokale harde schijf om blokken in de cache op te slaan. |
DATASET_MOUNT_BLOCK_FILE_CACHE_MAX_QUEUE_SIZE |
usize | 512 MB | Alleen van toepassing op opslaan in cache op basis van blokken. Op blok gebaseerde caching schrijft in cache opgeslagen blok naar een lokale schijf op een achtergrond. Met deze instelling bepaalt u hoeveel geheugenkoppeling kan worden gebruikt om blokken op te slaan die wachten op leegmaken naar de lokale schijfcache. |
DATASET_MOUNT_BLOCK_FILE_CACHE_WRITE_THREADS |
usize | NUMBER_OF_CORES * 2 |
Alleen van toepassing op opslaan in cache op basis van blokken. Het aantal achtergrondthreads op blokgebaseerde caching gebruikt om gedownloade blokken naar de lokale schijf van het rekendoel te schrijven. |
DATASET_UNMOUNT_TIMEOUT_SECONDS |
u64 | 30 | De tijd in seconden voor unmount het voltooien van alle bewerkingen die in behandeling zijn (bijvoorbeeld door aanroepen leegmaken) voordat de koppelingsberichtlus geforceerd wordt beëindigd. |
In uw taak kunt u de bovenstaande standaardinstellingen wijzigen door de omgevingsvariabelen in te stellen, bijvoorbeeld:
from azure.ai.ml import command
env_var = {
"DATASET_MOUNT_BLOCK_FILE_CACHE_ENABLED": True
}
job = command(
environment_variables=env_var
)
Open modus op basis van blokkeren
Met de op blok gebaseerde open modus wordt elk bestand gesplitst in blokken van een vooraf gedefinieerde grootte (met uitzondering van het laatste blok). Een leesaanvraag van een opgegeven positie vraagt een bijbehorend blok uit de opslag aan en retourneert de aangevraagde gegevens onmiddellijk. Een leesbewerking activeert ook het vooraf halen van N volgende blokken op de achtergrond met behulp van meerdere threads (geoptimaliseerd voor sequentiële leesbewerking). Gedownloade blokken worden in de cache opgeslagen in de cache van twee lagen (RAM en lokale schijf).
| Voordelen | Nadelen |
|---|---|
| Snelle levering van gegevens aan het trainingsscript (minder blokkering voor segmenten die nog niet zijn aangevraagd). | Willekeurige leesbewerkingen kunnen vooruitgefetcheerde blokken verspillen. |
| Meer werk offloads naar achtergrondthreads (prefetching/ caching). De training kan vervolgens worden voortgezet. | Er is overhead toegevoegd om tussen caches te navigeren, vergeleken met directe leesbewerkingen uit een bestand op een lokale schijfcache (bijvoorbeeld in de modus voor volledige bestandscache). |
| Alleen aangevraagde gegevens (plus prefetching) worden gelezen uit de opslag. | |
| Voor kleine gegevens wordt een snelle RAM-cache gebruikt. |
Wanneer gebruikt u de open modus op basis van blokken
Aanbevolen voor de meeste scenario's , behalve wanneer u snelle leesbewerkingen van willekeurige bestandslocaties nodig hebt. In dergelijke gevallen gebruikt u de open modus Hele bestandscache.
Hele bestandscache geopende modus
Wanneer een bestand onder een koppelingsmap wordt geopend (bijvoorbeeld f = open(path, args)) in de hele bestandsmodus, wordt de aanroep geblokkeerd totdat het hele bestand wordt gedownload naar een cachemap voor het rekendoel op de schijf. Alle volgende leesoproepen worden omgeleid naar het in de cache opgeslagen bestand, dus er is geen opslaginteractie nodig. Als de cache onvoldoende beschikbare ruimte heeft om het huidige bestand aan te passen, probeert de koppeling te verwijderen door het minst recent gebruikte bestand uit de cache te verwijderen. In gevallen waarin het bestand niet op schijf past (met betrekking tot cache-instellingen), valt de gegevensruntime terug naar de streamingmodus.
| Voordelen | Nadelen |
|---|---|
| Geen betrouwbaarheid van opslag/ doorvoerafhankelijkheden nadat het bestand is geopend. | De aanroep wordt geblokkeerd totdat het hele bestand is gedownload. |
| Snelle willekeurige leesbewerkingen (segmenten lezen vanaf willekeurige plaatsen van het bestand). | Het hele bestand wordt gelezen uit de opslag, zelfs als sommige delen van het bestand mogelijk niet nodig zijn. |
Wanneer te gebruiken
Wanneer willekeurige leesbewerkingen nodig zijn voor relatief grote bestanden die groter zijn dan 128 MB.
Gebruik
Stel de omgevingsvariabele DATASET_MOUNT_BLOCK_BASED_CACHE_ENABLED false in op uw taak:
from azure.ai.ml import command
env_var = {
"DATASET_MOUNT_BLOCK_BASED_CACHE_ENABLED": False
}
job = command(
environment_variables=env_var
)
Koppelen: Bestanden weergeven
Wanneer u met miljoenen bestanden werkt, vermijdt u bijvoorbeeld een recursieve vermelding ls -R /mnt/dataset/folder/ . Een recursieve vermelding activeert veel aanroepen om de mapinhoud van de bovenliggende map weer te geven. Het vereist vervolgens een afzonderlijke recursieve aanroep voor elke map binnen, op alle onderliggende niveaus. In Azure Storage kunnen doorgaans slechts 5000 elementen worden geretourneerd per aanvraag voor één lijst. Als gevolg hiervan is een recursieve lijst van 1M-mappen met 10 bestanden vereist elk 1,000,000 / 5000 + 1,000,000 = 1,000,200 aanvragen voor opslag. Ter vergelijking: 1.000 mappen met 10.000 bestanden hebben slechts 1001 aanvragen nodig voor opslag voor een recursieve vermelding.
Azure Machine Learning-koppeling verwerkt vermeldingen op een luie manier. Als u daarom veel kleine bestanden wilt weergeven, is het beter om een iteratieve clientbibliotheekaanroep (bijvoorbeeld os.scandir() in Python) te gebruiken in plaats van een clientbibliotheekaanroep die de volledige lijst retourneert (bijvoorbeeld os.listdir() in Python). Een iteratieve clientbibliotheekaanroep retourneert een generator, wat betekent dat deze niet hoeft te wachten totdat de hele lijst wordt geladen. Het kan dan sneller gaan.
Deze tabel vergelijkt de benodigde tijd voor python os.scandir() en os.listdir() functies om een map weer te geven die ~4M-bestanden in een platte structuur bevat:
| Metrische gegevens | os.scandir() |
os.listdir() |
|---|---|---|
| Tijd om het eerste item op te halen (secs) | 0.67 | 553.79 |
| Tijd voor het ophalen van eerste 50.000 vermeldingen (secs) | 9.56 | 562.73 |
| Tijd om alle vermeldingen (secs) op te halen | 558.35 | 582.14 |
Optimale koppelinstellingen voor algemene scenario's
Voor bepaalde veelvoorkomende scenario's laten we de optimale koppelingsinstellingen zien die u moet instellen in uw Azure Machine Learning-taak.
Grote bestanden sequentieel één keer lezen (regels in CSV-bestand verwerken)
Neem deze koppelingsinstellingen op in de environment_variables sectie van uw Azure Machine Learning-taak:
Notitie
Als u serverloze berekeningen wilt gebruiken, verwijdert compute="cpu-cluster", u deze code.
from azure.ai.ml import command
env_var = {
"DATASET_MOUNT_BLOCK_BASED_CACHE_ENABLED": True, # Enable block-based caching
"DATASET_MOUNT_BLOCK_FILE_CACHE_ENABLED": False, # Disable caching on disk
"DATASET_MOUNT_MEMORY_CACHE_SIZE": 0, # Disabling in-memory caching
# Increase the number of blocks used for prefetch. This leads to use of more RAM (2 MB * #value set).
# Can adjust up and down for fine-tuning, depending on the actual data processing pattern.
# An optimal setting based on our test ~= the number of prefetching threads (#CPU_CORES * 4 by default)
"DATASET_MOUNT_READ_BUFFER_BLOCK_COUNT": 80,
}
job = command(
environment_variables=env_var
)
Grote bestanden één keer lezen vanuit meerdere threads (gepartitioneerd CSV-bestand verwerken in meerdere threads)
Neem deze koppelingsinstellingen op in de environment_variables sectie van uw Azure Machine Learning-taak:
from azure.ai.ml import command
env_var = {
"DATASET_MOUNT_BLOCK_BASED_CACHE_ENABLED": True, # Enable block-based caching
"DATASET_MOUNT_BLOCK_FILE_CACHE_ENABLED": False, # Disable caching on disk
"DATASET_MOUNT_MEMORY_CACHE_SIZE": 0, # Disabling in-memory caching
}
job = command(
environment_variables=env_var
)
Miljoenen kleine bestanden (afbeeldingen) uit meerdere threads één keer lezen (enkele epoch-training op afbeeldingen)
Neem deze koppelingsinstellingen op in de environment_variables sectie van uw Azure Machine Learning-taak:
from azure.ai.ml import command
env_var = {
"DATASET_MOUNT_BLOCK_BASED_CACHE_ENABLED": True, # Enable block-based caching
"DATASET_MOUNT_BLOCK_FILE_CACHE_ENABLED": False, # Disable caching on disk
"DATASET_MOUNT_MEMORY_CACHE_SIZE": 0, # Disabling in-memory caching
}
job = command(
environment_variables=env_var
)
Miljoenen kleine bestanden (afbeeldingen) uit meerdere threads meerdere keren lezen (training voor meerdere tijdvakken op afbeeldingen)
Neem deze koppelingsinstellingen op in de environment_variables sectie van uw Azure Machine Learning-taak:
from azure.ai.ml import command
env_var = {
"DATASET_MOUNT_BLOCK_BASED_CACHE_ENABLED": True, # Enable block-based caching
}
job = command(
environment_variables=env_var
)
Het lezen van een groot bestand met willekeurige zoekopdrachten (zoals het verwerken van de bestandsdatabase uit de gekoppelde map)
Neem deze koppelingsinstellingen op in de environment_variables sectie van uw Azure Machine Learning-taak:
from azure.ai.ml import command
env_var = {
"DATASET_MOUNT_BLOCK_BASED_CACHE_ENABLED": False, # Disable block-based caching
}
job = command(
environment_variables=env_var
)
Problemen met het laden van gegevens vaststellen en oplossen
Wanneer een Azure Machine Learning-taak wordt uitgevoerd met gegevens, bepaalt de mode invoer hoe bytes worden gelezen uit de opslag en in de cache op de lokale SSD-schijf van het rekendoel. Voor de downloadmodus worden alle gegevenscaches op schijf opgeslagen voordat de gebruikerscode de uitvoering start. Daarom, factoren zoals
- aantal parallelle threads
- het aantal bestanden
- bestandsgrootte
hebben een effect op de maximale downloadsnelheden. Voor koppelen moet de gebruikerscode bestanden openen voordat de gegevens in de cache worden opgeslagen. Verschillende koppelingsinstellingen resulteren in verschillende lees- en cachegedrag. Verschillende factoren hebben een effect op de snelheid waarmee gegevens uit de opslag worden geladen:
- Locatie van gegevens om te berekenen: uw opslag- en rekendoellocaties moeten hetzelfde zijn. Als uw opslag- en rekendoel zich in verschillende regio's bevinden, verslechtert de prestaties omdat gegevens moeten worden overgedragen tussen regio's. Ga naar Colocate-gegevens met rekenkracht voor meer informatie over hoe u ervoor kunt zorgen dat uw gegevenskomma's met berekeningen worden gekomma's.
- De grootte van het rekendoel: kleine berekeningen hebben lagere kernaantallen (minder parallelle uitvoering) en een kleinere verwachte netwerkbandbreedte in vergelijking met grotere rekenkracht. Beide factoren zijn van invloed op de prestaties van het laden van gegevens.
- Als u bijvoorbeeld een kleine VM-grootte gebruikt, zoals
Standard_D2_v2(2 kernen, 1500 Mbps NIC) en u probeert 50.000 MB (50 GB) aan gegevens te laden, is de best haalbare laadtijd ongeveer 270 sec (ervan uitgaande dat u de NIC op 187,5 MB/s doorvoer hebt overbelast). Een (16 kernen, 12.000 Mbps) laadt daarentegenStandard_D5_v2dezelfde gegevens in ~33 sec (ervan uitgaande dat u de NIC op 1500 MB/s doorvoer verzadigt).
- Als u bijvoorbeeld een kleine VM-grootte gebruikt, zoals
- Opslaglaag: Voor de meeste scenario's, waaronder Large Language Models (LLM) - Standard Storage biedt het beste kosten-/prestatieprofiel. Als u echter veel kleine bestanden hebt, biedt Premium Storage een beter kosten-/prestatieprofiel. Lees Azure Storage-opties voor meer informatie.
- Opslagbelasting: Als het opslagaccount zwaar wordt belast, bijvoorbeeld veel GPU-knooppunten in een cluster waarin gegevens worden aangevraagd, loopt u het risico dat de uitgaande opslagcapaciteit wordt bereikt. Lees opslagbelasting voor meer informatie. Als u veel kleine bestanden hebt die parallel toegang nodig hebben, kunt u de aanvraaglimieten voor opslag bereiken. Lees actuele informatie over de limieten voor zowel uitgaande capaciteit als opslagaanvragen in schaaldoelen voor standaardopslagaccounts.
- Patroon voor gegevenstoegang in gebruikerscode: wanneer u de koppelingsmodus gebruikt, worden gegevens opgehaald op basis van de acties voor openen/lezen in uw code. Wanneer u bijvoorbeeld willekeurige secties van een groot bestand leest, kunnen de standaardinstellingen voor het vooraf afzetten van gegevens van koppelingen leiden tot downloads van blokken die niet worden gelezen. Mogelijk moet u enkele instellingen afstemmen om de maximale doorvoer te bereiken. Lees optimale koppelinstellingen voor algemene scenario's voor meer informatie.
Logboeken gebruiken om problemen vast te stellen
Voor toegang tot de logboeken van de gegevensruntime vanuit uw taak:
- Selecteer het tabblad Uitvoer en logboeken op de taakpagina.
- Selecteer de map system_logs , gevolgd door data_capability map.
- U ziet nu twee logboekbestanden:
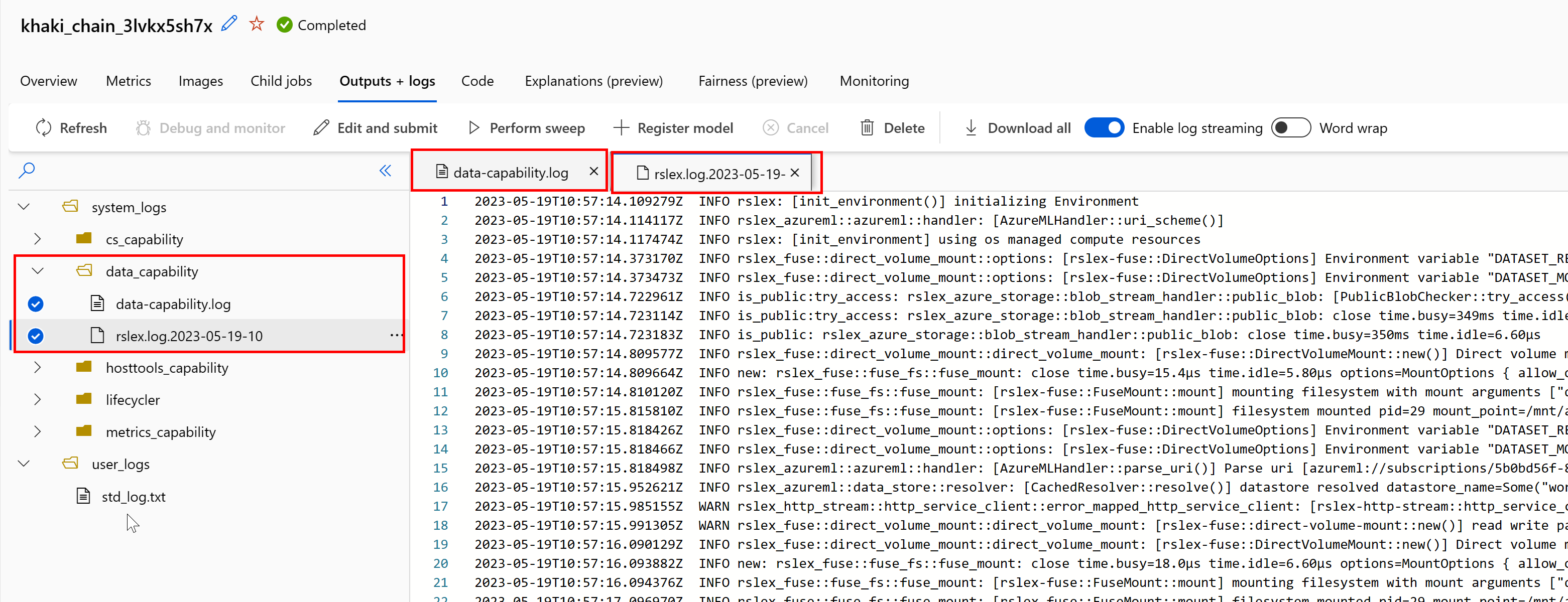

Het logboekbestand data-capability.log toont de algemene informatie over de tijd die is besteed aan belangrijke taken voor het laden van gegevens. Wanneer u bijvoorbeeld gegevens downloadt, registreert de runtime de begin- en eindtijden van de downloadactiviteit:
INFO 2023-05-18 17:14:47,790 sdk_logger.py:44 [28] - ActivityStarted, download
INFO 2023-05-18 17:14:50,295 sdk_logger.py:44 [28] - ActivityCompleted: Activity=download, HowEnded=Success, Duration=2504.39 [ms]
Als de downloaddoorvoer een fractie is van de verwachte netwerkbandbreedte voor de VM-grootte, kunt u het logboekbestand controleren rslex.log.<TIJDSTEMPEL>. Dit bestand bevat alle fijnmazige logboekregistratie van de rust-gebaseerde runtime; Bijvoorbeeld parallellisatie:
2023-05-18T14:08:25.388670Z INFO copy_uri:copy_uri:copy_dataset:write_streams_to_files:collect:reduce:reduce_and_combine:reduce:get_iter: rslex::prefetching: close time.busy=23.2µs time.idle=1.90µs sessionId=012ea46a-341c-4258-8aba-90bde4fdfb51 source=Dataset[Partitions: 1, Sources: 1] file_name_column=None break_on_first_error=true skip_existing_files=false parallelization_degree=4 self=Dataset[Partitions: 1, Sources: 1] parallelization_degree=4 self=Dataset[Partitions: 1, Sources: 1] parallelization_degree=4 self=Dataset[Partitions: 1, Sources: 1] parallelization_degree=4 i=0 index=0
2023-05-18T14:08:25.388731Z INFO copy_uri:copy_uri:copy_dataset:write_streams_to_files:collect:reduce:reduce_and_combine:reduce: rslex::dataset_crossbeam: close time.busy=90.9µs time.idle=9.10µs sessionId=012ea46a-341c-4258-8aba-90bde4fdfb51 source=Dataset[Partitions: 1, Sources: 1] file_name_column=None break_on_first_error=true skip_existing_files=false parallelization_degree=4 self=Dataset[Partitions: 1, Sources: 1] parallelization_degree=4 self=Dataset[Partitions: 1, Sources: 1] parallelization_degree=4 self=Dataset[Partitions: 1, Sources: 1] parallelization_degree=4 i=0
2023-05-18T14:08:25.388762Z INFO copy_uri:copy_uri:copy_dataset:write_streams_to_files:collect:reduce:reduce_and_combine:combine: rslex::dataset_crossbeam: close time.busy=1.22ms time.idle=9.50µs sessionId=012ea46a-341c-4258-8aba-90bde4fdfb51 source=Dataset[Partitions: 1, Sources: 1] file_name_column=None break_on_first_error=true skip_existing_files=false parallelization_degree=4 self=Dataset[Partitions: 1, Sources: 1] parallelization_degree=4 self=Dataset[Partitions: 1, Sources: 1] parallelization_degree=4 self=Dataset[Partitions: 1, Sources: 1] parallelization_degree=4
Het rslex.log-bestand bevat details over het kopiëren van bestanden, ongeacht of u de koppelings- of downloadmodi hebt gekozen. Ook worden de gebruikte instellingen (omgevingsvariabelen) beschreven. Als u wilt beginnen met foutopsporing, controleert u of u de instellingen voor optimale koppeling instelt voor veelvoorkomende scenario's.
Azure Storage bewaken
In Azure Portal kunt u uw opslagaccount en vervolgens metrische gegevens selecteren om de metrische opslaggegevens te bekijken:

Vervolgens tekent u successE2ELatency met SuccessServerLatency. Als de metrische gegevens hoge SuccessE2ELatency en weinig SuccessServerLatency bevatten, hebt u beperkte beschikbare threads of hebt u weinig resources, zoals CPU, geheugen of netwerkbandbreedte, moet u het volgende doen:
- Gebruik de bewakingsweergave in de Azure Machine Learning-studio om het CPU- en geheugengebruik van uw taak te controleren. Als u weinig CPU en geheugen hebt, kunt u overwegen om de VM-grootte van het rekendoel te vergroten.
- Overweeg om te verhogen
RSLEX_DOWNLOADER_THREADSals u downloadt en u de CPU en het geheugen niet gebruikt. Als u koppeling gebruikt, moet u verhogenDATASET_MOUNT_READ_BUFFER_BLOCK_COUNTom meer prefetching uit te voeren en te verhogenDATASET_MOUNT_READ_THREADSvoor meer leesthreads.
Als de metrische gegevens lage SuccessE2ELatency en lage SuccessServerLatency tonen, maar de client een hoge latentie ondervindt, hebt u een vertraging in de opslagaanvraag die de service bereikt. Controleer het volgende:
- Of het aantal threads dat wordt gebruikt voor koppelen/downloaden (
DATASET_MOUNT_READ_THREADS/RSLEX_DOWNLOADER_THREADS) te laag is ingesteld ten opzichte van het aantal kernen dat beschikbaar is op het rekendoel. Als de instelling te laag is, verhoogt u het aantal threads. - Of het aantal nieuwe pogingen voor het downloaden (
AZUREML_DATASET_HTTP_RETRY_COUNT) te hoog is ingesteld. Zo ja, verlaagt u het aantal nieuwe pogingen.
Schijfgebruik bewaken tijdens een taak
Vanuit de Azure Machine Learning-studio kunt u ook de IO en het gebruik van de rekendoelschijf controleren tijdens de uitvoering van uw taak. Navigeer naar uw taak en selecteer het tabblad Bewaking . Dit tabblad biedt inzicht in de resources van uw taak, op rollende basis van 30 dagen. Voorbeeld:

Notitie
Taakbewaking ondersteunt alleen rekenresources die door Azure Machine Learning worden beheerd. Taken met een runtime van minder dan 5 minuten hebben niet voldoende gegevens om deze weergave te vullen.
Azure Machine Learning-gegevensruntime gebruikt niet de laatste RESERVED_FREE_DISK_SPACE bytes schijfruimte om de berekening in orde te houden (de standaardwaarde is 150MB). Als uw schijf vol is, schrijft uw code bestanden naar schijf zonder de bestanden als uitvoer te declareren. Controleer daarom uw code om ervoor te zorgen dat gegevens niet per ongeluk naar de tijdelijke schijf worden geschreven. Als u bestanden naar een tijdelijke schijf moet schrijven en deze resource vol raakt, kunt u het volgende overwegen:
- De VM-grootte verhogen naar een vm met een grotere tijdelijke schijf
- Een TTL instellen op de gegevens in de cache (
DATASET_MOUNT_ATTRIBUTE_CACHE_TTL), om uw gegevens van schijf te verwijderen
Colocate data with compute
Let op
Als uw opslag en rekenkracht zich in verschillende regio's bevinden, verslechtert uw prestaties omdat gegevens moeten worden overgedragen tussen regio's. Dit verhoogt de kosten. Zorg ervoor dat uw opslagaccount en rekenresources zich in dezelfde regio bevinden.
Als uw gegevens en Azure Machine Learning-werkruimte zijn opgeslagen in verschillende regio's, raden we u aan de gegevens te kopiëren naar een opslagaccount in dezelfde regio met het hulpprogramma azcopy . AzCopy maakt gebruik van server-naar-server-API's, zodat gegevens rechtstreeks tussen opslagservers worden gekopieerd. Deze kopieerbewerkingen maken geen gebruik van de netwerkbandbreedte van uw computer. U kunt de doorvoer van deze bewerkingen verhogen met de AZCOPY_CONCURRENCY_VALUE omgevingsvariabele. Zie Gelijktijdigheid verhogen voor meer informatie.
Opslagbelasting
Een enkel opslagaccount kan worden beperkt wanneer het wordt belast met hoge belasting, wanneer:
- Uw taak maakt gebruik van veel GPU-knooppunten
- Uw opslagaccount heeft veel gelijktijdige gebruikers/apps die toegang hebben tot de gegevens terwijl u uw taak uitvoert
In deze sectie ziet u de berekeningen om te bepalen of beperking een probleem kan worden voor uw workload en hoe u verminderingen van bandbreedtebeperking kunt benaderen.
Bandbreedtelimieten berekenen
Een Azure Storage-account heeft een standaardlimiet voor uitgaand verkeer van 120 Gbit/s. Azure-VM's hebben verschillende netwerkbandbreedten, die van invloed zijn op het theoretische aantal rekenknooppunten dat nodig is om de maximale standaardcapaciteit voor uitgaand verkeer van opslag te bereiken:
Tekengrootte
GPU-kaart
vCPU
Geheugen: GiB
Tijdelijke opslag (SSD) GiB
Aantal GPU-kaarten
GPU-geheugen: GiB
Verwachte netwerkbandbreedte (Gbit/s)
Standaardwaarde voor uitgaand opslagaccount (Gbit/s)*
Aantal knooppunten om de standaardcapaciteit voor uitgaand verkeer te bereiken
Standard_ND96asr_v4
A100
96
900
6000
8
40
24
120
5
Standard_ND96amsr_A100_v4
A100
96
1900
6400
8
80
24
120
5
Standard_NC6s_v3
V100
6
112
736
1
16
24
120
5
Standard_NC12s_v3
V100
12
224
1474
2
32
24
120
5
Standard_NC24s_v3
V100
24
448
2948
4
64
24
120
5
Standard_NC24rs_v3
V100
24
448
2948
4
64
24
120
5
Standard_NC4as_T4_v3
T4
4
28
180
1
16
8
120
15
Standard_NC8as_T4_v3
T4
8
56
360
1
16
8
120
15
Standard_NC16as_T4_v3
T4
16
110
360
1
16
8
120
15
Standard_NC64as_T4_v3
T4
64
440
2880
4
64
32
120
3
Beide A100/V100-SKU's hebben een maximale netwerkbandbreedte per knooppunt van 24 Gbit/s. Als elk knooppunt dat gegevens van één account leest, dicht bij het theoretische maximum van 24 Gbit/s kan lezen, treedt de capaciteit voor uitgaand verkeer op met vijf knooppunten. Het gebruik van zes of meer rekenknooppunten zou de gegevensdoorvoer voor alle knooppunten verminderen.
Belangrijk
Als uw workload meer dan 6 knooppunten van A100/V100 nodig heeft, of als u denkt dat u de standaardcapaciteit voor uitgaande opslag (120Gbit/s) overschrijdt, neemt u contact op met de ondersteuning (via Azure Portal) en vraagt u een limiet voor uitgaande opslag aan.
Schalen tussen meerdere opslagaccounts
Mogelijk overschrijdt u de maximale capaciteit voor uitgaande opslag en/of bereikt u de limieten voor de aanvraagsnelheid. Als deze problemen optreden, raden we u aan eerst contact op te nemen met de ondersteuning om deze limieten voor het opslagaccount te verhogen.
Als u de maximale uitgaande capaciteit of aanvraagsnelheidslimiet niet kunt verhogen, kunt u overwegen om de gegevens over meerdere opslagaccounts te repliceren. Kopieer de gegevens naar meerdere accounts met Azure Data Factory, Azure Storage Explorer of azcopy, en koppel alle accounts in uw trainingstaak. Alleen de gegevens die op een koppeling worden geopend, worden gedownload. Daarom kan uw trainingscode de RANK omgevingsvariabele lezen om te kiezen van welke van de meerdere invoerkoppelingen waaruit moet worden gelezen. Uw taakdefinitie geeft een lijst met opslagaccounts door:
$schema: https://azuremlschemas.azureedge.net/latest/commandJob.schema.json
code: src
command: >-
python train.py
--epochs ${{inputs.epochs}}
--learning-rate ${{inputs.learning_rate}}
--data ${{inputs.cifar_storage1}}, ${{inputs.cifar_storage2}}
inputs:
epochs: 1
learning_rate: 0.2
cifar_storage1:
type: uri_folder
path: azureml://datastores/storage1/paths/cifar
cifar_storage2:
type: uri_folder
path: azureml://datastores/storage2/paths/cifar
environment: azureml:AzureML-pytorch-1.9-ubuntu18.04-py37-cuda11-gpu@latest
compute: azureml:gpu-cluster
distribution:
type: pytorch
process_count_per_instance: 1
resources:
instance_count: 2
display_name: pytorch-cifar-distributed-example
experiment_name: pytorch-cifar-distributed-example
description: Train a basic convolutional neural network (CNN) with PyTorch on the CIFAR-10 dataset, distributed via PyTorch.
Uw Python-trainingscode kan vervolgens worden gebruikt RANK om het opslagaccount specifiek voor dat knooppunt op te halen:
import argparse
import os
parser = argparse.ArgumentParser()
parser.add_argument('--data', nargs='+')
args = parser.parse_args()
world_size = int(os.environ["WORLD_SIZE"])
rank = int(os.environ["RANK"])
local_rank = int(os.environ["LOCAL_RANK"])
data_path_for_this_rank = args.data[rank]
Veel problemen met kleine bestanden
Het lezen van bestanden uit de opslag omvat het indienen van aanvragen voor elk bestand. Het aantal aanvragen per bestand varieert, afhankelijk van de bestandsgrootten en de instellingen van de software die het bestand leest.
Bestanden worden meestal gelezen in blokken van 1-4 MB in grootte. Bestanden die kleiner zijn dan een blok worden gelezen met één aanvraag (GET file.jpg 0-4 MB) en bestanden die groter zijn dan een blok, hebben één aanvraag per blok (GET file.jpg 0-4 MB, GET file.jpg 4-8 MB). In deze tabel ziet u dat bestanden die kleiner zijn dan een blok van 4 MB resulteren in meer opslagaanvragen in vergelijking met grotere bestanden:
#Bestanden
Bestandsgrootte
Totale gegevensgrootte
Blokgrootte
# Opslagaanvragen
2,000,000
500 KB
1 TB
4 MB
2,000,000
1.000
1 GB
1 TB
4 MB
256,000
Voor kleine bestanden omvat het latentie-interval meestal het verwerken van de aanvragen voor opslag, in plaats van gegevensoverdracht. Daarom bieden we deze aanbevelingen om de bestandsgrootte te vergroten:
- Voor ongestructureerde gegevens (afbeeldingen, tekst, video, enzovoort), archiveren (zip/tar) kleine bestanden, om ze op te slaan als een groter bestand dat in meerdere segmenten kan worden gelezen. Deze grotere gearchiveerde bestanden kunnen worden geopend in de rekenresource en PyTorch Archive DataPipes kunnen de kleinere bestanden extraheren.
- Bekijk uw ETL-proces voor gestructureerde gegevens (CSV, parquet, enzovoort) om ervoor te zorgen dat bestanden worden samenvermeld om de grootte te vergroten. Spark heeft
repartition() en coalesce() methoden om de bestandsgrootten te vergroten.
Als u uw bestandsgrootten niet kunt vergroten, verkent u uw Azure Storage-opties.
Opties voor Azure Storage
Azure Storage biedt twee lagen: Standard en Premium:
Storage
Scenario
Azure Blob - Standard (HDD)
Uw gegevens zijn gestructureerd in grotere blobs: afbeeldingen, video, enzovoort.
Azure Blob - Premium (SSD)
Hoge transactiesnelheden, kleinere objecten of consistent lage opslaglatentievereisten
Tip
Voor 'veel' kleine bestanden (KB-grootte) raden we u aan premium (SSD) te gebruiken omdat de opslagkosten lager zijn dan de kosten van het uitvoeren van GPU-rekenkracht.
Gegevensassets van V1 lezen
In deze sectie wordt uitgelegd hoe u V1 FileDataset - en TabularDataset gegevensentiteiten in een V2-taak leest.
Lees een FileDataset
Geef in het Input object het object op type als AssetTypes.MLTABLE en mode als InputOutputModes.EVAL_MOUNT:
Notitie
Als u serverloze berekeningen wilt gebruiken, verwijdert compute="cpu-cluster", u deze code.
Ga naar Verbinding maken met een werkruimte voor meer informatie over het MLClient-object, de initialisatieopties voor MLClient-objecten en het maken van verbinding met een werkruimte.
from azure.ai.ml import command
from azure.ai.ml.entities import Data
from azure.ai.ml import Input
from azure.ai.ml.constants import AssetTypes, InputOutputModes
from azure.ai.ml import MLClient
ml_client = MLClient.from_config(credential=DefaultAzureCredential())
filedataset_asset = ml_client.data.get(name="<filedataset_name>", version="<version>")
my_job_inputs = {
"input_data": Input(
type=AssetTypes.MLTABLE,
path=filedataset_asset.id,
mode=InputOutputModes.EVAL_MOUNT
)
}
job = command(
code="./src", # Local path where the code is stored
command="ls ${{inputs.input_data}}",
inputs=my_job_inputs,
environment="<environment_name>:<version>",
compute="cpu-cluster",
)
# Submit the command
returned_job = ml_client.jobs.create_or_update(job)
# Get a URL for the job status
returned_job.services["Studio"].endpoint
Lees een TabularDataset
Geef in het Input object de type waarde op als AssetTypes.MLTABLEen mode als InputOutputModes.DIRECT:
Notitie
Als u serverloze berekeningen wilt gebruiken, verwijdert compute="cpu-cluster", u deze code.
from azure.ai.ml import command
from azure.ai.ml.entities import Data
from azure.ai.ml import Input
from azure.ai.ml.constants import AssetTypes, InputOutputModes
from azure.ai.ml import MLClient
ml_client = MLClient.from_config(credential=DefaultAzureCredential())
filedataset_asset = ml_client.data.get(name="<tabulardataset_name>", version="<version>")
my_job_inputs = {
"input_data": Input(
type=AssetTypes.MLTABLE,
path=filedataset_asset.id,
mode=InputOutputModes.DIRECT
)
}
job = command(
code="./src", # Local path where the code is stored
command="python train.py --inputs ${{inputs.input_data}}",
inputs=my_job_inputs,
environment="<environment_name>:<version>",
compute="cpu-cluster",
)
# Submit the command
returned_job = ml_client.jobs.create_or_update(job)
# Get a URL for the status of the job
returned_job.services["Studio"].endpoint
Volgende stappen
Let op
Als uw opslag en rekenkracht zich in verschillende regio's bevinden, verslechtert uw prestaties omdat gegevens moeten worden overgedragen tussen regio's. Dit verhoogt de kosten. Zorg ervoor dat uw opslagaccount en rekenresources zich in dezelfde regio bevinden.
Als uw gegevens en Azure Machine Learning-werkruimte zijn opgeslagen in verschillende regio's, raden we u aan de gegevens te kopiëren naar een opslagaccount in dezelfde regio met het hulpprogramma azcopy . AzCopy maakt gebruik van server-naar-server-API's, zodat gegevens rechtstreeks tussen opslagservers worden gekopieerd. Deze kopieerbewerkingen maken geen gebruik van de netwerkbandbreedte van uw computer. U kunt de doorvoer van deze bewerkingen verhogen met de AZCOPY_CONCURRENCY_VALUE omgevingsvariabele. Zie Gelijktijdigheid verhogen voor meer informatie.
Opslagbelasting
Een enkel opslagaccount kan worden beperkt wanneer het wordt belast met hoge belasting, wanneer:
- Uw taak maakt gebruik van veel GPU-knooppunten
- Uw opslagaccount heeft veel gelijktijdige gebruikers/apps die toegang hebben tot de gegevens terwijl u uw taak uitvoert
In deze sectie ziet u de berekeningen om te bepalen of beperking een probleem kan worden voor uw workload en hoe u verminderingen van bandbreedtebeperking kunt benaderen.
Bandbreedtelimieten berekenen
Een Azure Storage-account heeft een standaardlimiet voor uitgaand verkeer van 120 Gbit/s. Azure-VM's hebben verschillende netwerkbandbreedten, die van invloed zijn op het theoretische aantal rekenknooppunten dat nodig is om de maximale standaardcapaciteit voor uitgaand verkeer van opslag te bereiken:
| Tekengrootte | GPU-kaart | vCPU | Geheugen: GiB | Tijdelijke opslag (SSD) GiB | Aantal GPU-kaarten | GPU-geheugen: GiB | Verwachte netwerkbandbreedte (Gbit/s) | Standaardwaarde voor uitgaand opslagaccount (Gbit/s)* | Aantal knooppunten om de standaardcapaciteit voor uitgaand verkeer te bereiken |
|---|---|---|---|---|---|---|---|---|---|
| Standard_ND96asr_v4 | A100 | 96 | 900 | 6000 | 8 | 40 | 24 | 120 | 5 |
| Standard_ND96amsr_A100_v4 | A100 | 96 | 1900 | 6400 | 8 | 80 | 24 | 120 | 5 |
| Standard_NC6s_v3 | V100 | 6 | 112 | 736 | 1 | 16 | 24 | 120 | 5 |
| Standard_NC12s_v3 | V100 | 12 | 224 | 1474 | 2 | 32 | 24 | 120 | 5 |
| Standard_NC24s_v3 | V100 | 24 | 448 | 2948 | 4 | 64 | 24 | 120 | 5 |
| Standard_NC24rs_v3 | V100 | 24 | 448 | 2948 | 4 | 64 | 24 | 120 | 5 |
| Standard_NC4as_T4_v3 | T4 | 4 | 28 | 180 | 1 | 16 | 8 | 120 | 15 |
| Standard_NC8as_T4_v3 | T4 | 8 | 56 | 360 | 1 | 16 | 8 | 120 | 15 |
| Standard_NC16as_T4_v3 | T4 | 16 | 110 | 360 | 1 | 16 | 8 | 120 | 15 |
| Standard_NC64as_T4_v3 | T4 | 64 | 440 | 2880 | 4 | 64 | 32 | 120 | 3 |
Beide A100/V100-SKU's hebben een maximale netwerkbandbreedte per knooppunt van 24 Gbit/s. Als elk knooppunt dat gegevens van één account leest, dicht bij het theoretische maximum van 24 Gbit/s kan lezen, treedt de capaciteit voor uitgaand verkeer op met vijf knooppunten. Het gebruik van zes of meer rekenknooppunten zou de gegevensdoorvoer voor alle knooppunten verminderen.
Belangrijk
Als uw workload meer dan 6 knooppunten van A100/V100 nodig heeft, of als u denkt dat u de standaardcapaciteit voor uitgaande opslag (120Gbit/s) overschrijdt, neemt u contact op met de ondersteuning (via Azure Portal) en vraagt u een limiet voor uitgaande opslag aan.
Schalen tussen meerdere opslagaccounts
Mogelijk overschrijdt u de maximale capaciteit voor uitgaande opslag en/of bereikt u de limieten voor de aanvraagsnelheid. Als deze problemen optreden, raden we u aan eerst contact op te nemen met de ondersteuning om deze limieten voor het opslagaccount te verhogen.
Als u de maximale uitgaande capaciteit of aanvraagsnelheidslimiet niet kunt verhogen, kunt u overwegen om de gegevens over meerdere opslagaccounts te repliceren. Kopieer de gegevens naar meerdere accounts met Azure Data Factory, Azure Storage Explorer of azcopy, en koppel alle accounts in uw trainingstaak. Alleen de gegevens die op een koppeling worden geopend, worden gedownload. Daarom kan uw trainingscode de RANK omgevingsvariabele lezen om te kiezen van welke van de meerdere invoerkoppelingen waaruit moet worden gelezen. Uw taakdefinitie geeft een lijst met opslagaccounts door:
$schema: https://azuremlschemas.azureedge.net/latest/commandJob.schema.json
code: src
command: >-
python train.py
--epochs ${{inputs.epochs}}
--learning-rate ${{inputs.learning_rate}}
--data ${{inputs.cifar_storage1}}, ${{inputs.cifar_storage2}}
inputs:
epochs: 1
learning_rate: 0.2
cifar_storage1:
type: uri_folder
path: azureml://datastores/storage1/paths/cifar
cifar_storage2:
type: uri_folder
path: azureml://datastores/storage2/paths/cifar
environment: azureml:AzureML-pytorch-1.9-ubuntu18.04-py37-cuda11-gpu@latest
compute: azureml:gpu-cluster
distribution:
type: pytorch
process_count_per_instance: 1
resources:
instance_count: 2
display_name: pytorch-cifar-distributed-example
experiment_name: pytorch-cifar-distributed-example
description: Train a basic convolutional neural network (CNN) with PyTorch on the CIFAR-10 dataset, distributed via PyTorch.
Uw Python-trainingscode kan vervolgens worden gebruikt RANK om het opslagaccount specifiek voor dat knooppunt op te halen:
import argparse
import os
parser = argparse.ArgumentParser()
parser.add_argument('--data', nargs='+')
args = parser.parse_args()
world_size = int(os.environ["WORLD_SIZE"])
rank = int(os.environ["RANK"])
local_rank = int(os.environ["LOCAL_RANK"])
data_path_for_this_rank = args.data[rank]
Veel problemen met kleine bestanden
Het lezen van bestanden uit de opslag omvat het indienen van aanvragen voor elk bestand. Het aantal aanvragen per bestand varieert, afhankelijk van de bestandsgrootten en de instellingen van de software die het bestand leest.
Bestanden worden meestal gelezen in blokken van 1-4 MB in grootte. Bestanden die kleiner zijn dan een blok worden gelezen met één aanvraag (GET file.jpg 0-4 MB) en bestanden die groter zijn dan een blok, hebben één aanvraag per blok (GET file.jpg 0-4 MB, GET file.jpg 4-8 MB). In deze tabel ziet u dat bestanden die kleiner zijn dan een blok van 4 MB resulteren in meer opslagaanvragen in vergelijking met grotere bestanden:
| #Bestanden | Bestandsgrootte | Totale gegevensgrootte | Blokgrootte | # Opslagaanvragen |
|---|---|---|---|---|
| 2,000,000 | 500 KB | 1 TB | 4 MB | 2,000,000 |
| 1.000 | 1 GB | 1 TB | 4 MB | 256,000 |
Voor kleine bestanden omvat het latentie-interval meestal het verwerken van de aanvragen voor opslag, in plaats van gegevensoverdracht. Daarom bieden we deze aanbevelingen om de bestandsgrootte te vergroten:
- Voor ongestructureerde gegevens (afbeeldingen, tekst, video, enzovoort), archiveren (zip/tar) kleine bestanden, om ze op te slaan als een groter bestand dat in meerdere segmenten kan worden gelezen. Deze grotere gearchiveerde bestanden kunnen worden geopend in de rekenresource en PyTorch Archive DataPipes kunnen de kleinere bestanden extraheren.
- Bekijk uw ETL-proces voor gestructureerde gegevens (CSV, parquet, enzovoort) om ervoor te zorgen dat bestanden worden samenvermeld om de grootte te vergroten. Spark heeft
repartition()encoalesce()methoden om de bestandsgrootten te vergroten.
Als u uw bestandsgrootten niet kunt vergroten, verkent u uw Azure Storage-opties.
Opties voor Azure Storage
Azure Storage biedt twee lagen: Standard en Premium:
| Storage | Scenario |
|---|---|
| Azure Blob - Standard (HDD) | Uw gegevens zijn gestructureerd in grotere blobs: afbeeldingen, video, enzovoort. |
| Azure Blob - Premium (SSD) | Hoge transactiesnelheden, kleinere objecten of consistent lage opslaglatentievereisten |
Tip
Voor 'veel' kleine bestanden (KB-grootte) raden we u aan premium (SSD) te gebruiken omdat de opslagkosten lager zijn dan de kosten van het uitvoeren van GPU-rekenkracht.
Gegevensassets van V1 lezen
In deze sectie wordt uitgelegd hoe u V1 FileDataset - en TabularDataset gegevensentiteiten in een V2-taak leest.
Lees een FileDataset
Geef in het Input object het object op type als AssetTypes.MLTABLE en mode als InputOutputModes.EVAL_MOUNT:
Notitie
Als u serverloze berekeningen wilt gebruiken, verwijdert compute="cpu-cluster", u deze code.
Ga naar Verbinding maken met een werkruimte voor meer informatie over het MLClient-object, de initialisatieopties voor MLClient-objecten en het maken van verbinding met een werkruimte.
from azure.ai.ml import command
from azure.ai.ml.entities import Data
from azure.ai.ml import Input
from azure.ai.ml.constants import AssetTypes, InputOutputModes
from azure.ai.ml import MLClient
ml_client = MLClient.from_config(credential=DefaultAzureCredential())
filedataset_asset = ml_client.data.get(name="<filedataset_name>", version="<version>")
my_job_inputs = {
"input_data": Input(
type=AssetTypes.MLTABLE,
path=filedataset_asset.id,
mode=InputOutputModes.EVAL_MOUNT
)
}
job = command(
code="./src", # Local path where the code is stored
command="ls ${{inputs.input_data}}",
inputs=my_job_inputs,
environment="<environment_name>:<version>",
compute="cpu-cluster",
)
# Submit the command
returned_job = ml_client.jobs.create_or_update(job)
# Get a URL for the job status
returned_job.services["Studio"].endpoint
Lees een TabularDataset
Geef in het Input object de type waarde op als AssetTypes.MLTABLEen mode als InputOutputModes.DIRECT:
Notitie
Als u serverloze berekeningen wilt gebruiken, verwijdert compute="cpu-cluster", u deze code.
from azure.ai.ml import command
from azure.ai.ml.entities import Data
from azure.ai.ml import Input
from azure.ai.ml.constants import AssetTypes, InputOutputModes
from azure.ai.ml import MLClient
ml_client = MLClient.from_config(credential=DefaultAzureCredential())
filedataset_asset = ml_client.data.get(name="<tabulardataset_name>", version="<version>")
my_job_inputs = {
"input_data": Input(
type=AssetTypes.MLTABLE,
path=filedataset_asset.id,
mode=InputOutputModes.DIRECT
)
}
job = command(
code="./src", # Local path where the code is stored
command="python train.py --inputs ${{inputs.input_data}}",
inputs=my_job_inputs,
environment="<environment_name>:<version>",
compute="cpu-cluster",
)
# Submit the command
returned_job = ml_client.jobs.create_or_update(job)
# Get a URL for the status of the job
returned_job.services["Studio"].endpoint