Machine Learning-pijplijnen activeren
VAN TOEPASSING OP: Python SDK azureml v1
Python SDK azureml v1
In dit artikel leert u hoe u programmatisch een pijplijn kunt plannen om te worden uitgevoerd in Azure. U kunt een planning maken op basis van verstreken tijd of wijzigingen in het bestandssysteem. Planningen op basis van tijd kunnen worden gebruikt om routinetaken uit te voeren, zoals bewaking voor gegevensdrift. Planningen op basis van wijzigingen kunnen worden gebruikt om te reageren op onregelmatige of onvoorspelbare wijzigingen, zoals nieuwe gegevens die worden geüpload of oude gegevens die worden bewerkt. Nadat u hebt geleerd hoe u planningen maakt, leert u hoe u ze kunt ophalen en deactiveren. Ten slotte leert u hoe u andere Azure-services, Azure Logic App en Azure Data Factory gebruikt om pijplijnen uit te voeren. Met een logische Azure-app kunt u complexere triggerlogica of -gedrag uitvoeren. Met Azure Data Factory-pijplijnen kunt u een machine learning-pijplijn aanroepen als onderdeel van een grotere pijplijn voor gegevensindeling.
Vereisten
Een Azure-abonnement. Als u geen Azure-abonnement hebt, maakt u een gratis account.
Een Python-omgeving waarin de Azure Machine Learning SDK voor Python is geïnstalleerd. Zie Herbruikbare omgevingen maken en beheren voor training en implementatie met Azure Machine Learning voor meer informatie.
Een Machine Learning-werkruimte met een gepubliceerde pijplijn. U kunt de ingebouwde machine learning-pijplijnen maken en uitvoeren met de Azure Machine Learning SDK.
Pijplijnen activeren met Azure Machine Learning SDK voor Python
Als u een pijplijn wilt plannen, hebt u een verwijzing nodig naar uw werkruimte, de id van uw gepubliceerde pijplijn en de naam van het experiment waarin u de planning wilt maken. U kunt deze waarden ophalen met de volgende code:
import azureml.core
from azureml.core import Workspace
from azureml.pipeline.core import Pipeline, PublishedPipeline
from azureml.core.experiment import Experiment
ws = Workspace.from_config()
experiments = Experiment.list(ws)
for experiment in experiments:
print(experiment.name)
published_pipelines = PublishedPipeline.list(ws)
for published_pipeline in published_pipelines:
print(f"{published_pipeline.name},'{published_pipeline.id}'")
experiment_name = "MyExperiment"
pipeline_id = "aaaaaaaaa-bbbb-cccc-dddd-eeeeeeeeeeee"
Een planning maken
Als u een pijplijn op terugkerende basis wilt uitvoeren, maakt u een planning. Een Schedule pijplijn, een experiment en een trigger worden gekoppeld. De trigger kan eenScheduleRecurrence beschrijving zijn van de wachttijd tussen taken of een gegevensarchiefpad waarmee een map wordt opgegeven om te controleren op wijzigingen. In beide gevallen hebt u de pijplijn-id en de naam van het experiment nodig waarin u de planning wilt maken.
Importeer de Schedule en ScheduleRecurrence klassen bovenaan uw Python-bestand:
from azureml.pipeline.core.schedule import ScheduleRecurrence, Schedule
Een schema op basis van tijd maken
De ScheduleRecurrence constructor heeft een vereist frequency argument dat een van de volgende tekenreeksen moet zijn: 'Minuut', 'Uur', 'Dag', 'Week' of 'Maand'. Er is ook een geheel getal-argument interval vereist dat aangeeft hoeveel van de frequency eenheden er tussen de planningsstarts moeten zijn verstreken. Met optionele argumenten kunt u specifieker zijn over de begintijden, zoals beschreven in de Documentatie over de ScheduleRecurrence SDK.
Maak een Schedule taak die elke 15 minuten begint:
recurrence = ScheduleRecurrence(frequency="Minute", interval=15)
recurring_schedule = Schedule.create(ws, name="MyRecurringSchedule",
description="Based on time",
pipeline_id=pipeline_id,
experiment_name=experiment_name,
recurrence=recurrence)
Een schema op basis van wijzigingen maken
Pijplijnen die worden geactiveerd door bestandswijzigingen, kunnen efficiënter zijn dan planningen op basis van tijd. Wanneer u iets wilt doen voordat een bestand wordt gewijzigd of wanneer een nieuw bestand wordt toegevoegd aan een gegevensmap, kunt u dat bestand vooraf verwerken. U kunt wijzigingen in een gegevensarchief of wijzigingen in een specifieke map in het gegevensarchief bewaken. Als u een specifieke map bewaakt, worden wijzigingen in submappen van die map geen taak geactiveerd.
Notitie
Planningen op basis van wijzigingen ondersteunen alleen het bewaken van Azure Blob Storage.
Als u een bestand reactief Schedulewilt maken, moet u de datastore parameter instellen in de aanroep naar Schedule.create. Als u een map wilt bewaken, stelt u het path_on_datastore argument in.
Met polling_interval het argument kunt u in minuten de frequentie opgeven waarmee het gegevensarchief wordt gecontroleerd op wijzigingen.
Als de pijplijn is samengesteld met een DataPath PipelineParameter, kunt u die variabele instellen op de naam van het gewijzigde bestand door het data_path_parameter_name argument in te stellen.
datastore = Datastore(workspace=ws, name="workspaceblobstore")
reactive_schedule = Schedule.create(ws, name="MyReactiveSchedule", description="Based on input file change.",
pipeline_id=pipeline_id, experiment_name=experiment_name, datastore=datastore, data_path_parameter_name="input_data")
Optionele argumenten bij het maken van een planning
Naast de argumenten die eerder zijn besproken, kunt u het status argument instellen om "Disabled" een inactieve planning te maken. Ten slotte continue_on_step_failure kunt u een Booleaanse waarde doorgeven die het standaardfoutgedrag van de pijplijn overschrijft.
Uw geplande pijplijnen weergeven
Navigeer in uw webbrowser naar Azure Machine Learning. Kies in de sectie Eindpunten van het navigatiedeelvenster pijplijneindpunten. Hiermee gaat u naar een lijst met de pijplijnen die zijn gepubliceerd in de werkruimte.
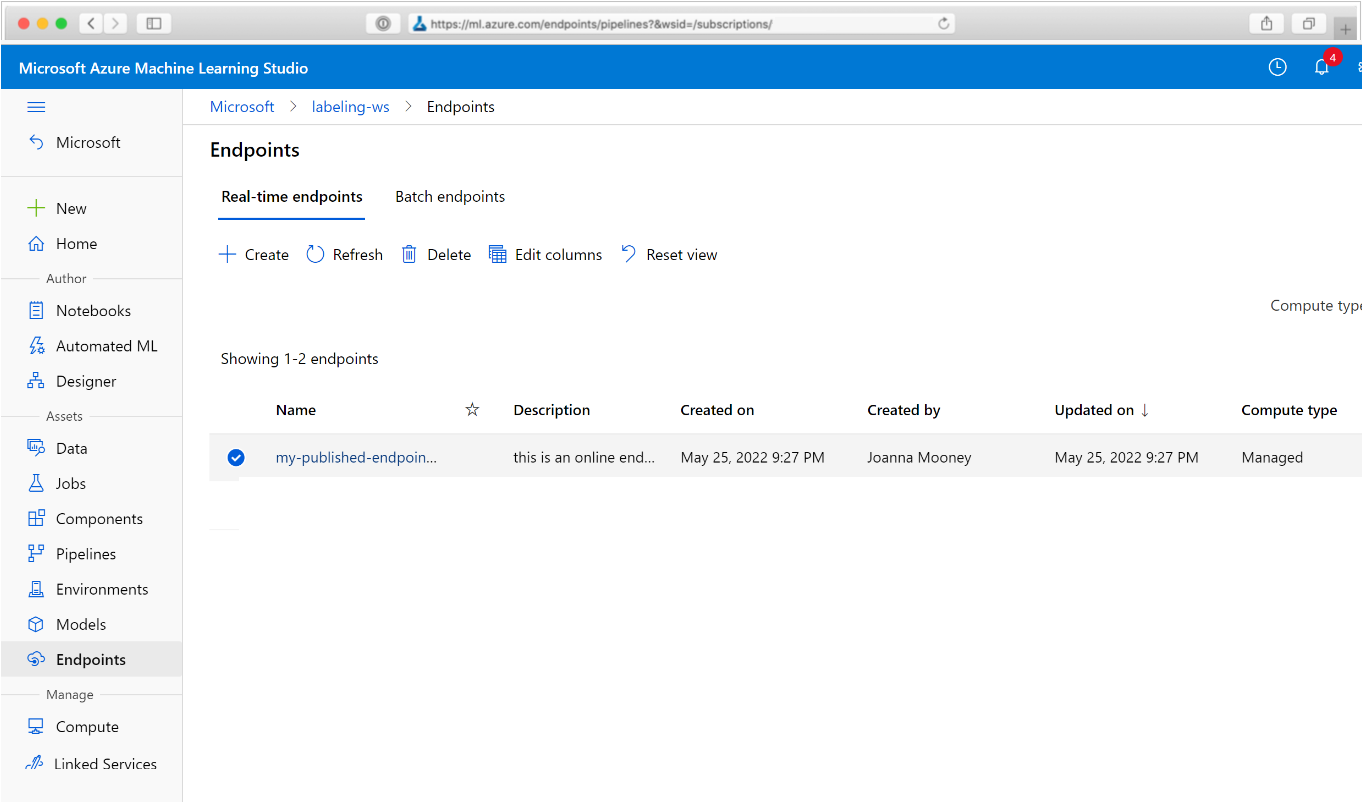
Op deze pagina ziet u overzichtsinformatie over alle pijplijnen in de werkruimte: namen, beschrijvingen, status, enzovoort. Zoom in door in uw pijplijn te klikken. Op de resulterende pagina vindt u meer informatie over uw pijplijn en kunt u inzoomen op afzonderlijke taken.
De pijplijn deactiveren
Als u een Pipeline gepubliceerde, maar niet geplande versie hebt, kunt u deze uitschakelen met:
pipeline = PublishedPipeline.get(ws, id=pipeline_id)
pipeline.disable()
Als de pijplijn is gepland, moet u eerst het schema annuleren. Haal de id van de planning op uit de portal of door het volgende uit te voeren:
ss = Schedule.list(ws)
for s in ss:
print(s)
Zodra u de functie hebt die u wilt uitschakelen, voert u het schedule_id volgende uit:
def stop_by_schedule_id(ws, schedule_id):
s = next(s for s in Schedule.list(ws) if s.id == schedule_id)
s.disable()
return s
stop_by_schedule_id(ws, schedule_id)
Als u vervolgens opnieuw uitvoert Schedule.list(ws) , krijgt u een lege lijst.
Azure Logic Apps gebruiken voor complexe triggers
Complexere triggerregels of -gedrag kunnen worden gemaakt met behulp van een logische Azure-app.
Als u een logische Azure-app wilt gebruiken om een Machine Learning-pijplijn te activeren, hebt u het REST-eindpunt nodig voor een gepubliceerde Machine Learning-pijplijn. Maak en publiceer uw pijplijn. Zoek vervolgens het REST-eindpunt van uw PublishedPipeline bestand met behulp van de pijplijn-id:
# You can find the pipeline ID in Azure Machine Learning studio
published_pipeline = PublishedPipeline.get(ws, id="<pipeline-id-here>")
published_pipeline.endpoint
Een logische app maken in Azure
Maak nu een exemplaar van een logische Azure-app . Nadat uw logische app is ingericht, gebruikt u deze stappen om een trigger voor uw pijplijn te configureren:
Maak een door het systeem toegewezen beheerde identiteit om de app toegang te geven tot uw Azure Machine Learning-werkruimte.
Navigeer naar de weergave Ontwerpfunctie voor logische apps en selecteer de sjabloon Lege logische app.
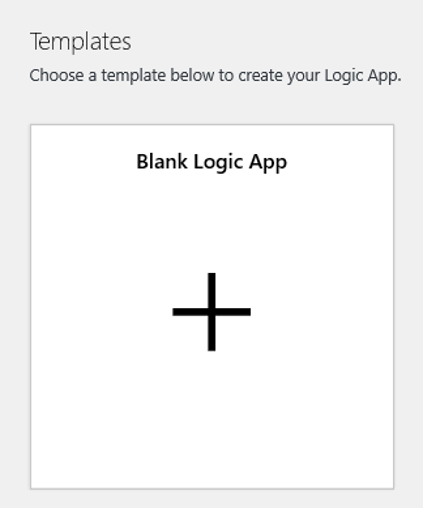
Zoek in de ontwerpfunctie naar blob. Selecteer de trigger Wanneer een blob wordt toegevoegd of gewijzigd (alleen eigenschappen) en voeg deze trigger toe aan uw logische app.
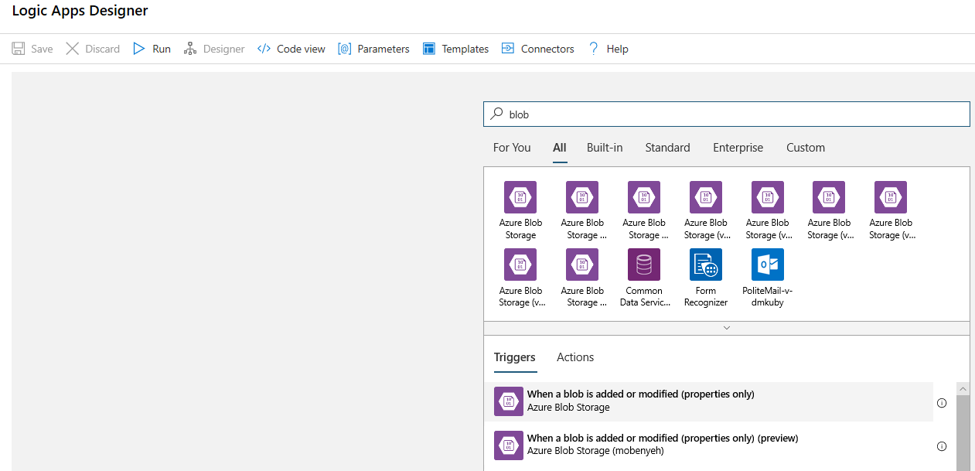
Vul de verbindingsgegevens in voor het Blob Storage-account dat u wilt controleren op toevoegingen of wijzigingen van blobs. Selecteer de container die u wilt bewaken.
Kies het interval en de frequentie om te peilen naar updates die voor u werken.
Notitie
Met deze trigger wordt de geselecteerde container bewaakt, maar worden geen submappen bewaakt.
Voeg een HTTP-actie toe die wordt uitgevoerd wanneer een nieuwe of gewijzigde blob wordt gedetecteerd. Selecteer + Nieuwe stap, zoek en selecteer de HTTP-actie.
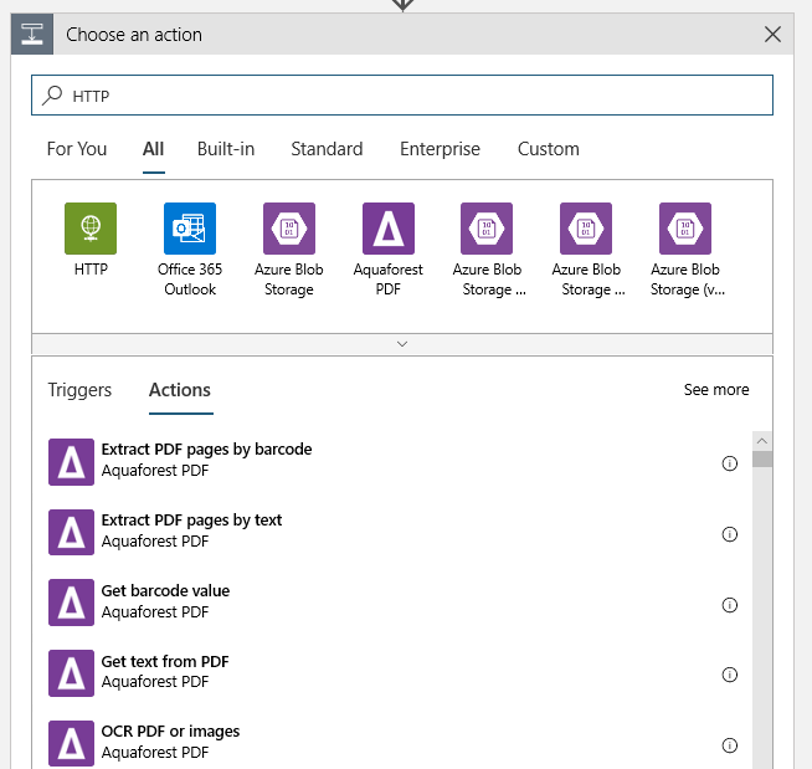
Gebruik de volgende instellingen om uw actie te configureren:
| Instelling | Weergegeven als |
|---|---|
| HTTP-actie | POSTEN |
| URI | het eindpunt voor de gepubliceerde pijplijn die u hebt gevonden als een vereiste |
| Verificatiemodus | Beheerde identiteit |
Stel uw planning in om de waarde in te stellen van alle DataPath PipelineParameters die u mogelijk hebt:
{ "DataPathAssignments": { "input_datapath": { "DataStoreName": "<datastore-name>", "RelativePath": "@{triggerBody()?['Name']}" } }, "ExperimentName": "MyRestPipeline", "ParameterAssignments": { "input_string": "sample_string3" }, "RunSource": "SDK" }Gebruik de
DataStoreNamedie u aan uw werkruimte hebt toegevoegd als een vereiste.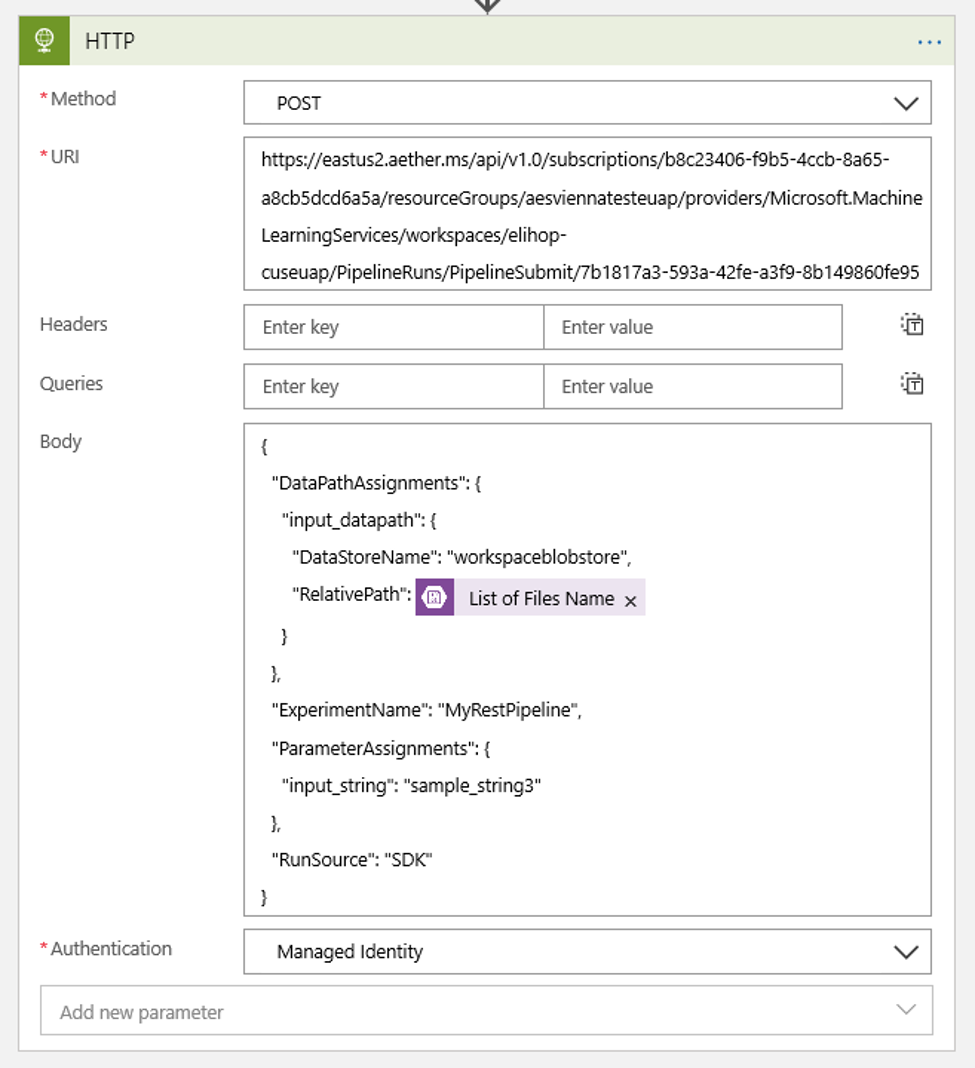
Selecteer Opslaan en uw planning is nu gereed.
Belangrijk
Als u op rollen gebaseerd toegangsbeheer van Azure (Azure RBAC) gebruikt om de toegang tot uw pijplijn te beheren, stelt u de machtigingen in voor uw pijplijnscenario (training of score).
Machine Learning-pijplijnen aanroepen vanuit Azure Data Factory-pijplijnen
In een Azure Data Factory-pijplijn voert de activiteit Machine Learning-pijplijn uitvoeren een Azure Machine Learning-pijplijn uit. U vindt deze activiteit op de ontwerppagina van Data Factory onder de categorie Machine Learning :
Volgende stappen
In dit artikel hebt u de Azure Machine Learning SDK voor Python gebruikt om een pijplijn op twee verschillende manieren te plannen. Eén schema recurs op basis van verstreken kloktijd. De andere planningstaken als een bestand wordt gewijzigd op een opgegeven Datastore of in een map in dat archief. U hebt gezien hoe u de portal kunt gebruiken om de pijplijn en afzonderlijke taken te onderzoeken. U hebt geleerd hoe u een planning uitschakelt, zodat de pijplijn niet meer wordt uitgevoerd. Ten slotte hebt u een logische Azure-app gemaakt om een pijplijn te activeren.
Zie voor meer informatie:
- Meer informatie over pijplijnen
- Meer informatie over het verkennen van Azure Machine Learning met Jupyter