Azure Databricks machine learning-experimenten bijhouden met MLflow en Azure Machine Learning
MLflow is een opensource-bibliotheek voor het beheren van de levenscyclus van uw machine learning-experimenten. U kunt MLflow gebruiken om Azure Databricks te integreren met Azure Machine Learning om ervoor te zorgen dat u het beste van beide producten krijgt.
In dit artikel leert u het volgende:
- De vereiste bibliotheken die nodig zijn voor het gebruik van MLflow met Azure Databricks en Azure Machine Learning.
- Azure Databricks-uitvoeringen bijhouden met MLflow in Azure Machine Learning.
- Modellen registreren met MLflow om ze geregistreerd te krijgen in Azure Machine Learning.
- Modellen implementeren en gebruiken die zijn geregistreerd in Azure Machine Learning.
Vereisten
- Het
azureml-mlflowpakket, dat de connectiviteit met Azure Machine Learning afhandelt, inclusief verificatie. - Een Azure Databricks-werkruimte en -cluster.
- Een Azure Machine Learning-werkruimte.
Bekijk welke toegangsmachtigingen u nodig hebt om uw MLflow-bewerkingen uit te voeren met uw werkruimte.
Voorbeeldnotebooks
De trainingsmodellen in Azure Databricks en deze implementeren in de Azure Machine Learning-opslagplaats laat zien hoe u modellen traint in Azure Databricks en implementeert in Azure Machine Learning. Ook wordt beschreven hoe u de experimenten en modellen bijhoudt met het MLflow-exemplaar in Azure Databricks. Hierin wordt beschreven hoe u Azure Machine Learning gebruikt voor implementatie.
Bibliotheken installeren
Bibliotheken op uw cluster installeren:
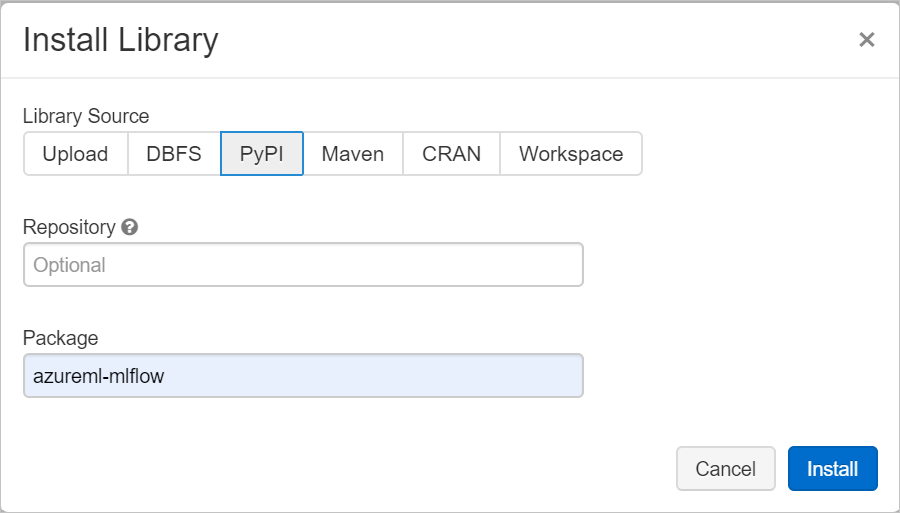
Navigeer naar het tabblad Bibliotheken en selecteer Nieuw installeren.

Typ in het veld Pakket azureml-mlflow en selecteer vervolgens Installeren. Herhaal deze stap indien nodig om andere pakketten te installeren in uw cluster voor uw experiment.
Azure Databricks-uitvoeringen bijhouden met MLflow
U kunt Azure Databricks op twee manieren configureren om experimenten bij te houden met behulp van MLflow:
- Bijhouden in zowel de Azure Databricks-werkruimte als de Azure Machine Learning-werkruimte (dual-tracking)
- Exclusief bijhouden in Azure Machine Learning
Wanneer u uw Azure Databricks-werkruimte koppelt, wordt dual-tracking standaard voor u geconfigureerd.
Dual track op Azure Databricks en Azure Machine Learning
Als u uw Azure Databricks-werkruimte koppelt aan uw Azure Machine Learning-werkruimte, kunt u uw experimentgegevens tegelijkertijd bijhouden in de Azure Machine Learning-werkruimte en Azure Databricks-werkruimte. Deze configuratie wordt Dual-tracking genoemd.
Dual-tracking in een Azure Machine Learning-werkruimte met private link wordt momenteel niet ondersteund. Configureer in plaats daarvan exclusieve tracering met uw Azure Machine Learning-werkruimte .
Dual-tracking wordt momenteel niet ondersteund in Microsoft Azure beheerd door 21Vianet. Configureer in plaats daarvan exclusieve tracering met uw Azure Machine Learning-werkruimte .
Uw Azure Databricks-werkruimte koppelen aan een nieuwe of bestaande Azure Machine Learning-werkruimte:
Meld u aan bij het Azure-portaal.
Navigeer naar de overzichtspagina van uw Azure Databricks-werkruimte.
Selecteer Azure Machine Learning-werkruimte koppelen.


Nadat u uw Azure Databricks-werkruimte hebt gekoppeld aan uw Azure Machine Learning-werkruimte, wordt MLflow-tracering automatisch bijgehouden op de volgende plaatsen:
- De gekoppelde Azure Machine Learning-werkruimte.
- Uw oorspronkelijke Azure Databricks-werkruimte.
U kunt vervolgens MLflow in Azure Databricks gebruiken op dezelfde manier als waar u gewend bent. In het volgende voorbeeld wordt de naam van het experiment ingesteld zoals gebruikelijk in Azure Databricks en begint u met het vastleggen van enkele parameters.
import mlflow
experimentName = "/Users/{user_name}/{experiment_folder}/{experiment_name}"
mlflow.set_experiment(experimentName)
with mlflow.start_run():
mlflow.log_param('epochs', 20)
pass
Notitie
In tegenstelling tot bijhouden ondersteunen modelregisters het registreren van modellen niet tegelijkertijd op zowel Azure Machine Learning als Azure Databricks. Zie Modellen registreren in het register met MLflow voor meer informatie.
Exclusief bijhouden in Azure Machine Learning-werkruimte
Als u uw bijgehouden experimenten liever op een centrale locatie wilt beheren, kunt u MLflow-tracering zo instellen dat ze alleen worden bijgehouden in uw Azure Machine Learning-werkruimte. Deze configuratie heeft het voordeel dat u eenvoudiger implementatiepad kunt inschakelen met behulp van Azure Machine Learning-implementatieopties.
Waarschuwing
Voor een Azure Machine Learning-werkruimte waarvoor Private Link is ingeschakeld, moet u Azure Databricks implementeren in uw eigen netwerk (VNet-injectie) om de juiste connectiviteit te garanderen.
Configureer de MLflow-tracerings-URI zodat deze exclusief verwijst naar Azure Machine Learning, zoals wordt weergegeven in het volgende voorbeeld:
Tracerings-URI configureren
Haal de tracerings-URI voor uw werkruimte op.
VAN TOEPASSING OP:
 Azure CLI ml-extensie v2 (huidige)
Azure CLI ml-extensie v2 (huidige)Meld u aan en configureer uw werkruimte.
az account set --subscription <subscription> az configure --defaults workspace=<workspace> group=<resource-group> location=<location>U kunt de tracerings-URI ophalen met behulp van de
az ml workspaceopdracht.az ml workspace show --query mlflow_tracking_uri
Configureer de tracerings-URI.
De methode
set_tracking_uri()verwijst de MLflow-tracerings-URI naar die URI.import mlflow mlflow.set_tracking_uri(mlflow_tracking_uri)
Tip
Wanneer u werkt met gedeelde omgevingen, zoals een Azure Databricks-cluster, Azure Synapse Analytics-cluster of vergelijkbaar, kunt u de omgevingsvariabele MLFLOW_TRACKING_URI instellen op clusterniveau. Met deze methode kunt u de MLflow-tracerings-URI automatisch configureren om te verwijzen naar Azure Machine Learning voor alle sessies die in het cluster worden uitgevoerd in plaats van dit per sessie te doen.

Nadat u de omgevingsvariabele hebt geconfigureerd, wordt elk experiment dat in een dergelijk cluster wordt uitgevoerd, bijgehouden in Azure Machine Learning.
Verificatie configureren
Nadat u tracering hebt geconfigureerd, configureert u hoe u zich kunt verifiëren bij de gekoppelde werkruimte. De Azure Machine Learning-invoegtoepassing voor MLflow opent standaard een browser om interactief om referenties te vragen. Zie MLflow configureren voor Azure Machine Learning: Verificatie configureren voor andere manieren om verificatie voor MLflow in Azure Machine Learning-werkruimten te configureren.
Voor interactieve taken waarbij er een gebruiker is verbonden met de sessie, kunt u vertrouwen op interactieve verificatie en hoeft u dus geen verdere actie te ondernemen.
Waarschuwing
Met interactieve browserverificatie wordt de uitvoering van code geblokkeerd wanneer er om referenties wordt gevraagd. Deze benadering is niet geschikt voor verificatie in omgevingen zonder toezicht, zoals trainingstaken. U wordt aangeraden een andere verificatiemodus te configureren.
Voor deze scenario's waarbij uitvoering zonder toezicht is vereist, moet u een service-principal configureren om te communiceren met Azure Machine Learning.
import os
os.environ["AZURE_TENANT_ID"] = "<AZURE_TENANT_ID>"
os.environ["AZURE_CLIENT_ID"] = "<AZURE_CLIENT_ID>"
os.environ["AZURE_CLIENT_SECRET"] = "<AZURE_CLIENT_SECRET>"
Tip
Wanneer u aan gedeelde omgevingen werkt, raden we u aan deze omgevingsvariabelen te configureren bij de berekening. Als best practice kunt u ze beheren als geheimen in een exemplaar van Azure Key Vault.
In Azure Databricks kunt u bijvoorbeeld geheimen in omgevingsvariabelen als volgt gebruiken in de clusterconfiguratie: AZURE_CLIENT_SECRET={{secrets/<scope-name>/<secret-name>}} Zie Referentie voor een geheim in een omgevingsvariabele of raadpleeg de documentatie voor uw platform voor meer informatie over het implementeren van deze benadering in Azure Databricks.
Naamexperiment in Azure Machine Learning
Wanneer u MLflow configureert om uitsluitend experimenten in de Azure Machine Learning-werkruimte bij te houden, moet de naamconventie van het experiment worden gevolgd die wordt gebruikt door Azure Machine Learning. In Azure Databricks worden experimenten bijvoorbeeld benoemd met het pad naar waar het experiment wordt opgeslagen /Users/alice@contoso.com/iris-classifier. In Azure Machine Learning geeft u echter rechtstreeks de naam van het experiment op. Hetzelfde experiment zou rechtstreeks een naam iris-classifier krijgen.
mlflow.set_experiment(experiment_name="experiment-name")
Parameters, metrische gegevens en artefacten bijhouden
Na deze configuratie kunt u MLflow in Azure Databricks op dezelfde manier gebruiken als u gewend bent. Zie logboekgegevens en logboekbestanden voor meer informatie.
Logboekmodellen met MLflow
Nadat uw model is getraind, kunt u het registreren bij de traceringsserver met de mlflow.<model_flavor>.log_model() methode. <model_flavor> verwijst naar het framework dat is gekoppeld aan het model. Meer informatie over welke modelsmaak wordt ondersteund.
In het volgende voorbeeld wordt een model dat is gemaakt met de Spark-bibliotheek MLLib geregistreerd.
mlflow.spark.log_model(model, artifact_path = "model")
De smaak spark komt niet overeen met het feit dat u een model traint in een Spark-cluster. In plaats daarvan volgt dit uit het gebruikte trainingsframework. U kunt een model trainen met Behulp van TensorFlow met Spark. De smaak die moet worden gebruikt, zou zijn tensorflow.
Modellen worden geregistreerd in de uitvoering die wordt bijgehouden. Dat betekent dat modellen beschikbaar zijn in zowel Azure Databricks als Azure Machine Learning (standaard) of uitsluitend in Azure Machine Learning als u de tracerings-URI zo hebt geconfigureerd dat deze verwijst.
Belangrijk
De parameter registered_model_name is niet opgegeven. Zie Modellen registreren in het register met MLflow voor meer informatie over deze parameter en het register.
Modellen registreren in het register met MLflow
In tegenstelling tot bijhouden kunnen modelregisters niet tegelijkertijd worden uitgevoerd in Azure Databricks en Azure Machine Learning. Ze moeten een of de andere gebruiken. Modelregisters maken standaard gebruik van de Azure Databricks-werkruimte. Als u ervoor kiest om MLflow-tracering zo in te stellen dat deze alleen wordt bijgehouden in uw Azure Machine Learning-werkruimte, is het modelregister de Azure Machine Learning-werkruimte.
Als u de standaardconfiguratie gebruikt, registreert de volgende code een model in de bijbehorende uitvoeringen van zowel Azure Databricks als Azure Machine Learning, maar registreert deze alleen op Azure Databricks.
mlflow.spark.log_model(model, artifact_path = "model",
registered_model_name = 'model_name')
- Als er geen geregistreerd model met de naam bestaat, registreert de methode een nieuw model, maakt u versie 1 en retourneert u een
ModelVersionMLflow-object. - Als er al een geregistreerd model met de naam bestaat, maakt de methode een nieuwe modelversie en retourneert het versieobject.
Azure Machine Learning-register gebruiken met MLflow
Als u Azure Machine Learning Model Registry wilt gebruiken in plaats van Azure Databricks, raden we u aan MLflow-tracering in te stellen om alleen bij te houden in uw Azure Machine Learning-werkruimte. Deze aanpak verwijdert de dubbelzinnigheid van waar modellen worden geregistreerd en vereenvoudigt de configuratie.
Als u de mogelijkheden voor dubbel bijhouden wilt blijven gebruiken, maar modellen wilt registreren in Azure Machine Learning, kunt u MLflow instrueren om Azure Machine Learning te gebruiken voor modelregisters door de register-URI van het MLflow-model te configureren. Deze URI heeft dezelfde indeling en waarde als de MLflow die de URI bijhoudt.
mlflow.set_registry_uri(azureml_mlflow_uri)
Notitie
De waarde van azureml_mlflow_uri is op dezelfde manier verkregen als beschreven in MLflow-tracering instellen om alleen bij te houden in uw Azure Machine Learning-werkruimte.
Zie Trainingsmodellen in Azure Databricks en implementeer deze in Azure Machine Learning voor een volledig voorbeeld van dit scenario.
Modellen implementeren en gebruiken die zijn geregistreerd in Azure Machine Learning
Modellen die zijn geregistreerd in Azure Machine Learning Service met behulp van MLflow, kunnen worden gebruikt als:
- Een Azure Machine Learning-eindpunt (realtime en batch). Met deze implementatie kunt u azure Machine Learning-implementatiemogelijkheden gebruiken voor zowel realtime als batchdeductie in Azure Container Instances, Azure Kubernetes of Beheerde deductie-eindpunten.
- MLFlow-modelobjecten of door de gebruiker gedefinieerde Pandas-functies (UDF's), die kunnen worden gebruikt in Azure Databricks-notebooks in streaming- of batchpijplijnen.
Modellen implementeren in Azure Machine Learning-eindpunten
U kunt de azureml-mlflow invoegtoepassing gebruiken om een model te implementeren in uw Azure Machine Learning-werkruimte. Voor meer informatie over het implementeren van modellen op de verschillende doelen : MLflow-modellen implementeren.
Belangrijk
Modellen moeten worden geregistreerd in het Azure Machine Learning-register om ze te kunnen implementeren. Als uw modellen zijn geregistreerd in het MLflow-exemplaar in Azure Databricks, moet u ze opnieuw registreren in Azure Machine Learning. Zie Trainingsmodellen in Azure Databricks en deze implementeren in Azure Machine Learning voor meer informatie
Modellen implementeren in Azure Databricks voor batchgewijs scoren met behulp van UDF's
U kunt Azure Databricks-clusters kiezen voor batchgewijs scoren. Met Behulp van Mlflow kunt u elk model oplossen vanuit het register waaraan u bent verbonden. Meestal gebruikt u een van de volgende methoden:
- Als uw model is getraind en gebouwd met Spark-bibliotheken zoals
MLLib, gebruiktmlflow.pyfunc.spark_udfu om een model te laden en gebruikt als spark Pandas UDF om nieuwe gegevens te scoren. - Als uw model niet is getraind of gebouwd met Spark-bibliotheken, gebruikt
mlflow.pyfunc.load_modelofmlflow.<flavor>.load_modellaadt u het model in het clusterstuurprogramma. U moet eventuele parallelle uitvoeringen of werkdistributie indelen die u in het cluster wilt uitvoeren. MLflow installeert geen bibliotheek die uw model moet uitvoeren. Deze bibliotheken moeten worden geïnstalleerd in het cluster voordat u deze uitvoert.
In het volgende voorbeeld ziet u hoe u een model laadt uit het register met de naam uci-heart-classifier en gebruikt als spark Pandas UDF om nieuwe gegevens te scoren.
from pyspark.sql.types import ArrayType, FloatType
model_name = "uci-heart-classifier"
model_uri = "models:/"+model_name+"/latest"
#Create a Spark UDF for the MLFlow model
pyfunc_udf = mlflow.pyfunc.spark_udf(spark, model_uri)
Zie Modellen laden uit het register voor meer manieren om te verwijzen naar modellen uit het register.
Nadat het model is geladen, kunt u deze opdracht gebruiken om nieuwe gegevens te scoren.
#Load Scoring Data into Spark Dataframe
scoreDf = spark.table({table_name}).where({required_conditions})
#Make Prediction
preds = (scoreDf
.withColumn('target_column_name', pyfunc_udf('Input_column1', 'Input_column2', ' Input_column3', …))
)
display(preds)
Resources opschonen
Als u uw Azure Databricks-werkruimte wilt behouden, maar de Azure Machine Learning-werkruimte niet meer nodig hebt, kunt u de Azure Machine Learning-werkruimte verwijderen. Deze actie resulteert in het ontkoppelen van uw Azure Databricks-werkruimte en de Azure Machine Learning-werkruimte.
Als u niet van plan bent om de vastgelegde metrische gegevens en artefacten in uw werkruimte te gebruiken, verwijdert u de resourcegroep die het opslagaccount en de werkruimte bevat.
- Zoek in Azure Portal naar Resourcegroepen. Selecteer resourcegroepen onder services.
- Zoek en selecteer in de lijst Resourcegroepen de resourcegroep die u hebt gemaakt om deze te openen.
- Selecteer op de pagina Overzicht de optie Resourcegroep verwijderen.
- Voer de naam van de resourcegroep in om het verwijderen te controleren.