Azure Machine Learning-gegevenssets versieren en bijhouden
VAN TOEPASSING OP: Python SDK azureml v1
Python SDK azureml v1
In dit artikel leert u hoe u Azure Machine Learning-gegevenssets kunt versieren en bijhouden voor reproduceerbaarheid. Bladwijzers voor versiebeheer van gegevenssets bevatten specifieke statussen van uw gegevens, zodat u een specifieke versie van de gegevensset kunt toepassen voor toekomstige experimenten.
Mogelijk wilt u uw Azure Machine Learning-resources versieren in deze typische scenario's:
- Wanneer er nieuwe gegevens beschikbaar komen voor opnieuw trainen
- Wanneer u verschillende benaderingen voor gegevensvoorbereiding of functie-engineering toepast
Vereisten
De Azure Machine Learning SDK voor Python. Deze SDK bevat het pakket azureml-datasets
Een Azure Machine Learning-werkruimte. Maak een nieuwe werkruimte of haal een bestaande werkruimte op met dit codevoorbeeld:
import azureml.core from azureml.core import Workspace ws = Workspace.from_config()
Gegevenssetversies registreren en ophalen
U kunt een geregistreerde gegevensset versie, hergebruiken en delen met experimenten en met uw collega's. U kunt meerdere gegevenssets onder dezelfde naam registreren en een specifieke versie ophalen op naam en versienummer.
Een gegevenssetversie registreren
In dit codevoorbeeld wordt de create_new_version parameter van de titanic_ds gegevensset ingesteld op True, om een nieuwe versie van die gegevensset te registreren. Als de werkruimte geen bestaande titanic_ds gegevensset heeft geregistreerd, wordt met de code een nieuwe gegevensset met de naam titanic_dsgemaakt en wordt de versie ingesteld op 1.
titanic_ds = titanic_ds.register(workspace = workspace,
name = 'titanic_ds',
description = 'titanic training data',
create_new_version = True)
Een gegevensset ophalen op naam
Standaard retourneert de Dataset klasse get_by_name() de meest recente versie van de gegevensset die is geregistreerd bij de werkruimte.
Deze code retourneert versie 1 van de titanic_ds gegevensset.
from azureml.core import Dataset
# Get a dataset by name and version number
titanic_ds = Dataset.get_by_name(workspace = workspace,
name = 'titanic_ds',
version = 1)
Best practice voor versiebeheer
Wanneer u een gegevenssetversie maakt, maakt u geen extra kopie van gegevens met de werkruimte. Omdat gegevenssets verwijzingen naar de gegevens in uw opslagservice zijn, hebt u één bron van waarheid, die wordt beheerd door uw opslagservice.
Belangrijk
Als de gegevens waarnaar wordt verwezen door uw gegevensset worden overschreven of verwijderd, wordt de wijziging niet hersteld door een aanroep naar een specifieke versie van de gegevensset.
Wanneer u gegevens uit een gegevensset laadt, wordt de huidige gegevensinhoud waarnaar wordt verwezen door de gegevensset altijd geladen. Als u ervoor wilt zorgen dat elke gegevenssetversie reproduceerbaar is, raden we u aan om het wijzigen van gegevensinhoud waarnaar wordt verwezen door de gegevenssetversie te voorkomen. Wanneer nieuwe gegevens binnenkomen, slaat u nieuwe gegevensbestanden op in een afzonderlijke gegevensmap en maakt u vervolgens een nieuwe gegevenssetversie om gegevens uit die nieuwe map op te nemen.
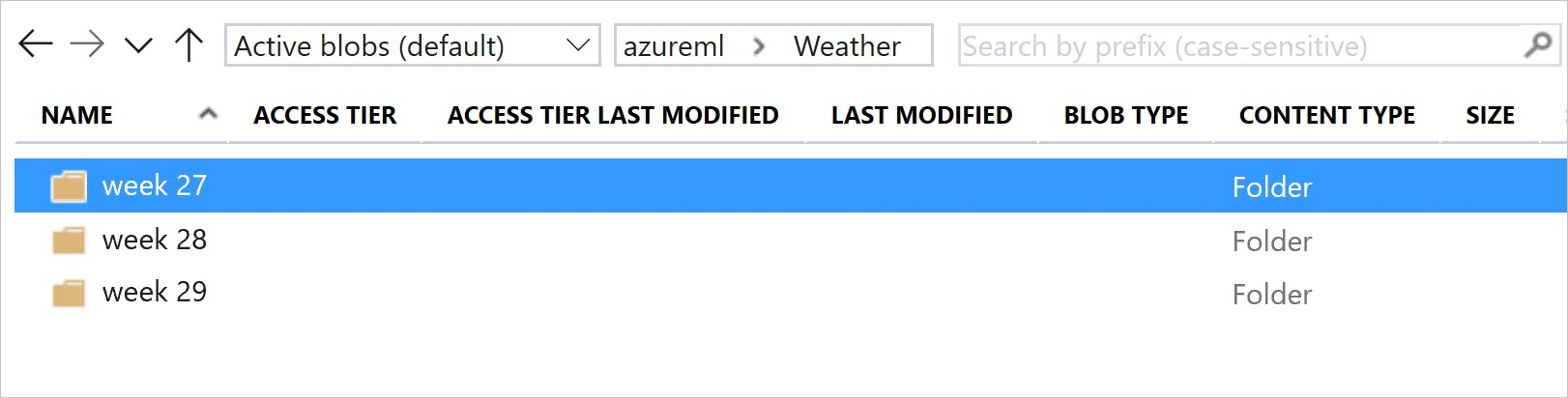
Deze afbeelding en voorbeeldcode geven de aanbevolen manier weer om uw gegevensmappen te structuren en gegevenssetversies te maken die verwijzen naar deze mappen:
from azureml.core import Dataset
# get the default datastore of the workspace
datastore = workspace.get_default_datastore()
# create & register weather_ds version 1 pointing to all files in the folder of week 27
datastore_path1 = [(datastore, 'Weather/week 27')]
dataset1 = Dataset.File.from_files(path=datastore_path1)
dataset1.register(workspace = workspace,
name = 'weather_ds',
description = 'weather data in week 27',
create_new_version = True)
# create & register weather_ds version 2 pointing to all files in the folder of week 27 and 28
datastore_path2 = [(datastore, 'Weather/week 27'), (datastore, 'Weather/week 28')]
dataset2 = Dataset.File.from_files(path = datastore_path2)
dataset2.register(workspace = workspace,
name = 'weather_ds',
description = 'weather data in week 27, 28',
create_new_version = True)
Versie van een ML-pijplijnuitvoergegevensset
U kunt een gegevensset gebruiken als invoer en uitvoer van elke ML-pijplijnstap . Wanneer u pijplijnen opnieuw uitvoert, wordt de uitvoer van elke pijplijnstap geregistreerd als een nieuwe versie van de gegevensset.
Machine Learning-pijplijnen vullen de uitvoer van elke stap in een nieuwe map telkens wanneer de pijplijn opnieuw wordt uitgevoerd. De versie van de uitvoergegevenssets worden vervolgens reproduceerbaar. Ga naar gegevenssets in pijplijnen voor meer informatie.
from azureml.core import Dataset
from azureml.pipeline.steps import PythonScriptStep
from azureml.pipeline.core import Pipeline, PipelineData
from azureml.core. runconfig import CondaDependencies, RunConfiguration
# get input dataset
input_ds = Dataset.get_by_name(workspace, 'weather_ds')
# register pipeline output as dataset
output_ds = PipelineData('prepared_weather_ds', datastore=datastore).as_dataset()
output_ds = output_ds.register(name='prepared_weather_ds', create_new_version=True)
conda = CondaDependencies.create(
pip_packages=['azureml-defaults', 'azureml-dataprep[fuse,pandas]'],
pin_sdk_version=False)
run_config = RunConfiguration()
run_config.environment.docker.enabled = True
run_config.environment.python.conda_dependencies = conda
# configure pipeline step to use dataset as the input and output
prep_step = PythonScriptStep(script_name="prepare.py",
inputs=[input_ds.as_named_input('weather_ds')],
outputs=[output_ds],
runconfig=run_config,
compute_target=compute_target,
source_directory=project_folder)
Gegevens bijhouden in uw experimenten
Azure Machine Learning houdt uw gegevens in uw experiment bij als invoer- en uitvoergegevenssets. In deze scenario's worden uw gegevens bijgehouden als invoergegevensset:
Als object
DatasetConsumptionConfig, via deinputsofargumentsparameter van uwScriptRunConfigobject, bij het verzenden van de experimenttaakWanneer uw script bepaalde methoden aanroept,
get_by_name()bijvoorbeeldget_by_id(). De naam die is toegewezen aan de gegevensset op het moment dat u die gegevensset aan de werkruimte hebt geregistreerd, is de weergegeven naam
In deze scenario's worden uw gegevens bijgehouden als een uitvoergegevensset:
Geef een
OutputFileDatasetConfigobject door via deoutputsofargumentsparameter wanneer u een experimenttaak verzendt.OutputFileDatasetConfigobjecten kunnen ook gegevens tussen pijplijnstappen behouden. Ga naar Gegevens verplaatsen tussen ML-pijplijnstappen voor meer informatieRegistreer een gegevensset in uw script. De naam die is toegewezen aan de gegevensset wanneer u deze hebt geregistreerd bij de werkruimte, is de naam die wordt weergegeven. In dit codevoorbeeld
training_dsziet u de weergegeven naam:training_ds = unregistered_ds.register(workspace = workspace, name = 'training_ds', description = 'training data' )Het verzenden van een onderliggende taak, met een niet-geregistreerde gegevensset, in het script. Deze inzending resulteert in een anonieme opgeslagen gegevensset
Gegevenssets traceren in experimenttaken
Voor elk Machine Learning-experiment kunt u de invoergegevenssets voor het experimentobject Job traceren. In dit codevoorbeeld wordt de get_details() methode gebruikt om de invoergegevenssets bij te houden die worden gebruikt bij de uitvoering van het experiment:
# get input datasets
inputs = run.get_details()['inputDatasets']
input_dataset = inputs[0]['dataset']
# list the files referenced by input_dataset
input_dataset.to_path()
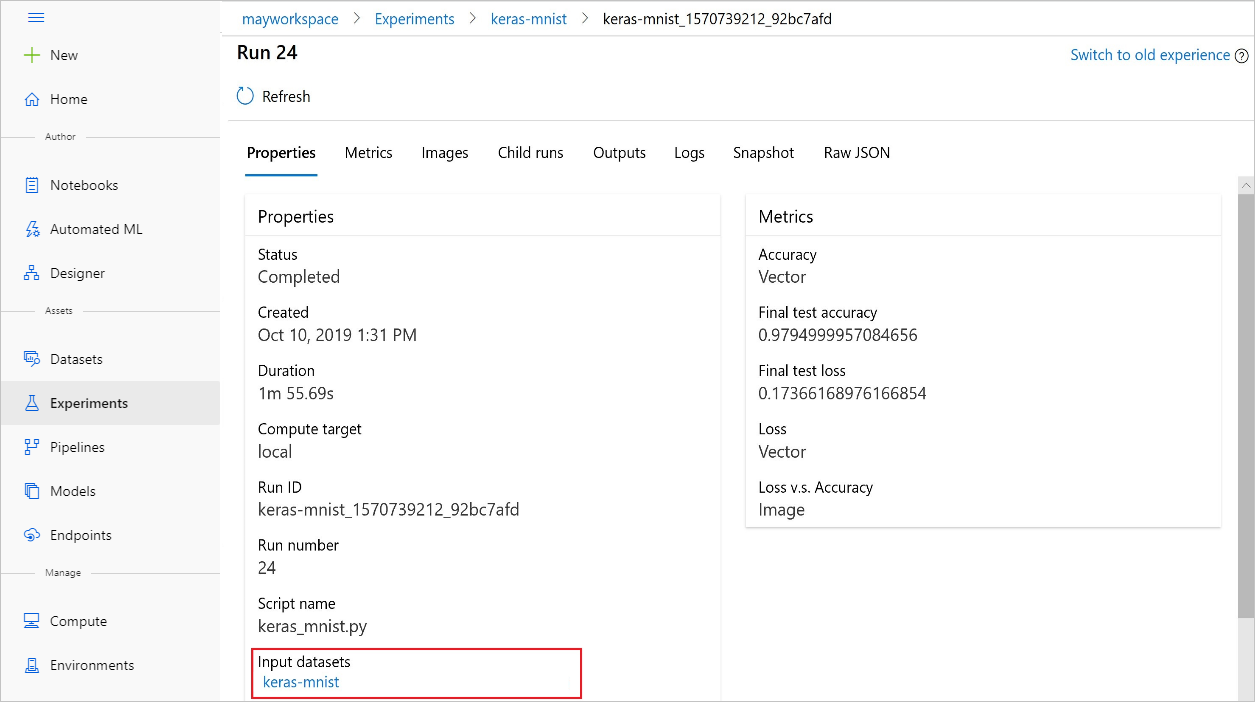
U kunt de input_datasets experimenten ook vinden met de Azure Machine Learning-studio.
In deze schermopname ziet u waar u de invoergegevensset van een experiment op Azure Machine Learning-studio kunt vinden. Voor dit voorbeeld begint u in het deelvenster Experimenten en opent u het tabblad Eigenschappen voor een specifieke uitvoering van uw experiment. keras-mnist
Met deze code worden modellen geregistreerd met gegevenssets:
model = run.register_model(model_name='keras-mlp-mnist',
model_path=model_path,
datasets =[('training data',train_dataset)])
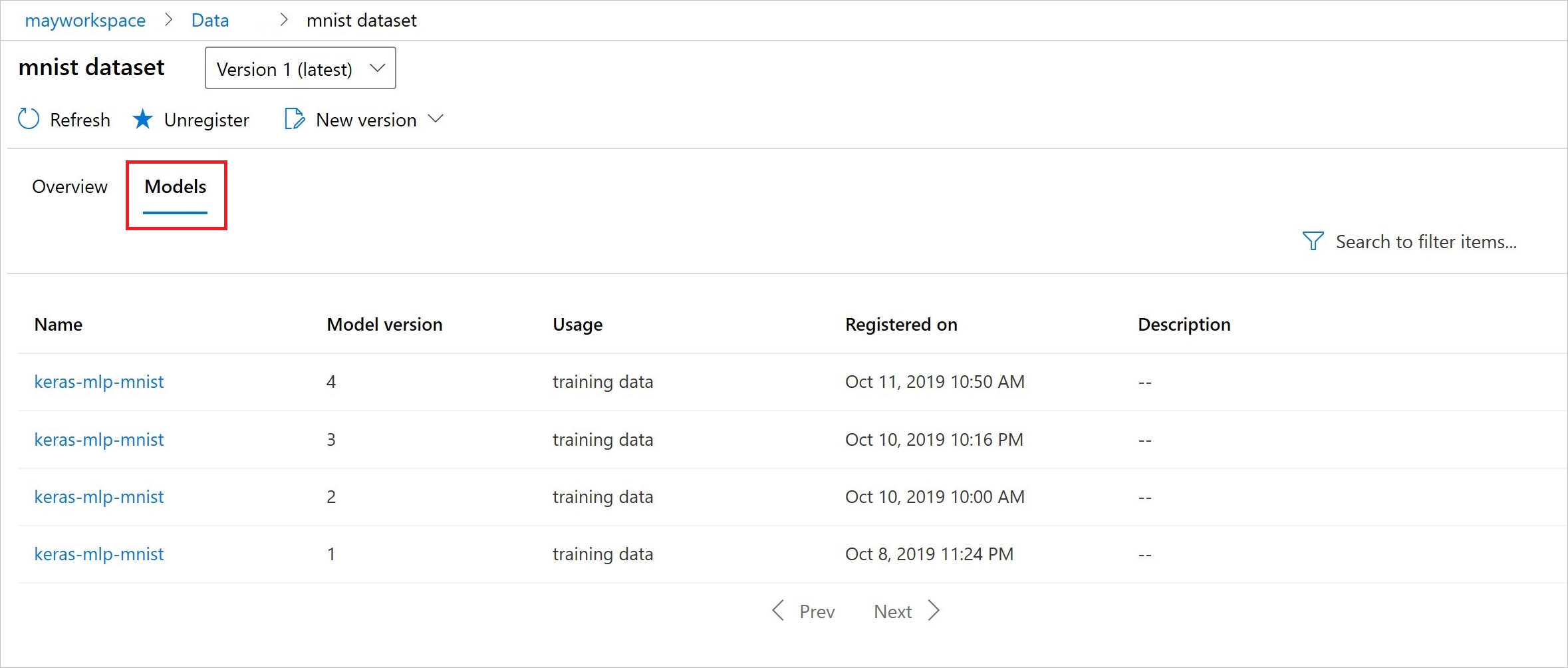
Na de registratie ziet u de lijst met modellen die zijn geregistreerd bij de gegevensset met Python of de studio.
Thia-schermopname bevindt zich in het deelvenster Gegevenssets onder Assets. Selecteer de gegevensset en selecteer vervolgens het tabblad Modellen voor een lijst met de modellen die zijn geregistreerd bij de gegevensset.