Promptstroom integreren met DevOps op basis van LLM
In dit artikel leert u meer over de integratie van promptstroom met DEVOps op basis van LLM in Azure Machine Learning. Promptflow biedt een gebruiksvriendelijke en gebruiksvriendelijke code-first-ervaring voor het ontwikkelen en herhalen van stromen met uw volledige op LLM gebaseerde werkstroom voor toepassingsontwikkeling.
Het biedt een promptstroom-SDK en CLI, een VS-code-extensie en de nieuwe gebruikersinterface van flowmapverkenner om de lokale ontwikkeling van stromen, lokale triggering van stroomuitvoeringen en evaluatieuitvoeringen te vergemakkelijken en stromen over te zetten van lokale naar cloudomgevingen (Azure Machine Learning-werkruimte).
Deze documentatie is gericht op het effectief combineren van de mogelijkheden van de ervaring met promptstroomcode en DevOps om uw op LLM gebaseerde werkstromen voor toepassingsontwikkeling te verbeteren.

Introductie van code-first-ervaring in promptstroom
Bij het ontwikkelen van toepassingen met BEHULP van LLM is het gebruikelijk om een gestandaardiseerd toepassingsengineeringsproces te hebben dat codeopslagplaatsen en CI/CD-pijplijnen bevat. Deze integratie biedt een gestroomlijnd ontwikkelproces, versiebeheer en samenwerking tussen teamleden.
Voor ontwikkelaars die ervaring hebben met het ontwikkelen van code die een efficiënter LLMOps-iteratieproces zoeken, kunt u profiteren van de volgende belangrijke functies en voordelen van promptstroomcode:
- Stroomversiebeheer in codeopslagplaats. U kunt uw stroom definiëren in YAML-indeling, die kan worden afgestemd op de bronbestanden waarnaar wordt verwezen in een mapstructuur.
- Stroomuitvoering integreren met CI/CD-pijplijn. U kunt stroomuitvoeringen activeren met behulp van de CLI of SDK van de promptstroom, die naadloos kan worden geïntegreerd in uw CI/CD-pijplijn en leveringsproces.
- Soepele overgang van lokaal naar cloud. U kunt uw stroommap eenvoudig exporteren naar uw lokale of codeopslagplaats voor versiebeheer, lokale ontwikkeling en delen. Op dezelfde manier kan de stroommap moeiteloos worden geïmporteerd in de cloud voor verdere creatie, testen en implementatie in cloudresources.
Definitie van promptstroomcode openen
Elke stroom is gekoppeld aan een stroommapstructuur die essentiële bestanden bevat voor het definiëren van de stroom in de structuur van de codemap. Deze mapstructuur organiseert uw stroom, waardoor soepelere overgangen worden vergemakkelijkt.
Azure Machine Learning biedt een gedeeld bestandssysteem voor alle werkruimtegebruikers. Wanneer u een stroom maakt, wordt er automatisch een bijbehorende stroommap gegenereerd en opgeslagen, die zich in de Users/<username>/promptflow map bevindt.

Structuur van stroommap
Overzicht van de structuur van de stroommap en de belangrijkste bestanden die deze bevat:
- flow.dag.yaml: Dit primaire stroomdefinitiebestand, in YAML-indeling, bevat informatie over invoer, uitvoer, knooppunten, hulpprogramma's en varianten die in de stroom worden gebruikt. Het is integraal voor het ontwerpen en definiëren van de promptstroom.
- Broncodebestanden (.py, .jinja2): de stroommap bevat ook door de gebruiker beheerde broncodebestanden, waarnaar wordt verwezen door de hulpprogramma's/knooppunten in de stroom.
- Naar bestanden in de Python-indeling (.py) kan worden verwezen door het Python-hulpprogramma voor het definiëren van aangepaste Python-logica.
- Bestanden in jinja 2-indeling (.jinja2) kunnen worden verwezen door het prompthulpprogramma of LLM-hulpprogramma voor het definiëren van promptcontext.
- Niet-bronbestanden: De stroommap kan ook niet-bronbestanden bevatten, zoals hulpprogrammabestanden en gegevensbestanden die kunnen worden opgenomen in de bronbestanden.
Zodra de stroom is gemaakt, kunt u naar de pagina Stroomcreatie navigeren om de stroombestanden in de juiste verkenner weer te geven en te gebruiken. Hiermee kunt u uw bestanden bekijken, bewerken en beheren. Wijzigingen in de bestanden worden rechtstreeks doorgevoerd in de bestandsshareopslag.

Als de modus Onbewerkt bestand is ingeschakeld, kunt u de onbewerkte inhoud van de bestanden in de bestandseditor bekijken en bewerken, inclusief het stroomdefinitiebestand flow.dag.yaml en de bronbestanden.


U kunt ook rechtstreeks toegang krijgen tot alle stroommappen in het Azure Machine Learning-notebook.

Promptstroom voor versiebeheer in codeopslagplaats
Als u uw stroom wilt inchecken in uw codeopslagplaats, kunt u de stroommap eenvoudig exporteren van de pagina stroomcreatie naar uw lokale systeem. Hiermee downloadt u een pakket met alle bestanden van de Verkenner naar uw lokale computer, die u vervolgens kunt inchecken in uw codeopslagplaats.

Zie Git-integratie in Azure Machine Learning voor meer informatie over DevOps-integratie met Azure Machine Learning
Uitvoeringen verzenden naar de cloud vanuit de lokale opslagplaats
Vereisten
Voltooi de resources maken om aan de slag te gaan als u nog geen Azure Machine Learning-werkruimte hebt.
Een Python-omgeving waarin u Azure Machine Learning Python SDK v2 hebt geïnstalleerd: installatie-instructies. Deze omgeving is bedoeld voor het definiëren en beheren van uw Azure Machine Learning-resources en is gescheiden van de omgeving die tijdens runtime wordt gebruikt. Zie voor meer informatie hoe u runtime beheert voor promptstroomengineering.
Sdk voor installatiepromptstroom
pip install -r ../../examples/requirements.txt
Verbinding maken naar Azure Machine Learning-werkruimte
az login
Bereid de run.yml configuratie voor voor deze stroomuitvoering in de cloud voor.
$schema: https://azuremlschemas.azureedge.net/promptflow/latest/Run.schema.json
flow: <path_to_flow>
data: <path_to_flow>/data.jsonl
column_mapping:
url: ${data.url}
# define cloud resource
# if omitted, it will use the automatic runtime, you can also specify the runtime name, specify automatic will also use the automatic runtime.
runtime: <runtime_name>
# define instance type only work for automatic runtime, will be ignored if you specify the runtime name.
# resources:
# instance_type: <instance_type>
# overrides connections
connections:
classify_with_llm:
connection: <connection_name>
deployment_name: <deployment_name>
summarize_text_content:
connection: <connection_name>
deployment_name: <deployment_name>
U kunt de verbindings- en implementatienaam voor elk hulpprogramma in de stroom opgeven. Als u de naam van de verbinding en implementatie niet opgeeft, wordt de ene verbinding en implementatie in het flow.dag.yaml bestand gebruikt. Ga als volgende te werk om verbindingen op te maken:
...
connections:
<node_name>:
connection: <connection_name>
deployment_name: <deployment_name>
...
pfazure run create --file run.yml
Bereid de run_evaluation.yml configuratie voor op de uitvoering van deze evaluatiestroom in de cloud.
$schema: https://azuremlschemas.azureedge.net/promptflow/latest/Run.schema.json
flow: <path_to_flow>
data: <path_to_flow>/data.jsonl
run: <id of web-classification flow run>
column_mapping:
groundtruth: ${data.answer}
prediction: ${run.outputs.category}
# define cloud resource
# if omitted, it will use the automatic runtime, you can also specify the runtime name, specif automatic will also use the automatic runtime.
runtime: <runtime_name>
# define instance type only work for automatic runtime, will be ignored if you specify the runtime name.
# resources:
# instance_type: <instance_type>
# overrides connections
connections:
classify_with_llm:
connection: <connection_name>
deployment_name: <deployment_name>
summarize_text_content:
connection: <connection_name>
deployment_name: <deployment_name>
pfazure run create --file run_evaluation.yml
Uitvoeringsresultaten weergeven in Azure Machine Learning-werkruimte
De stroomuitvoering verzenden naar de cloud retourneert de portal-URL van de uitvoering. U kunt de URI-weergave van de uitvoeringsresultaten openen in de portal.
U kunt ook de volgende opdracht gebruiken om resultaten voor uitvoeringen weer te geven.
De logboeken streamen
pfazure run stream --name <run_name>
Uitvoer van uitvoeringen weergeven
pfazure run show-details --name <run_name>
Metrische gegevens van evaluatieuitvoering weergeven
pfazure run show-metrics --name <evaluation_run_name>
Belangrijk
Raadpleeg de CLI-documentatie voor promptstroom voor Azure voor meer informatie.
Iteratieve ontwikkeling van fine-tuning
Lokale ontwikkeling en testen
Tijdens iteratieve ontwikkeling kan het nuttig zijn om tijdens het verfijnen en verfijnen van uw stroom of prompts meerdere iteraties lokaal in uw codeopslagplaats uit te voeren. De communityversie, promptstroom VS Code-extensie en promptstroom lokale SDK & CLI wordt geleverd om pure lokale ontwikkeling en testen zonder Azure-binding mogelijk te maken.
Vs Code-extensie voor promptstroom
Als de VS Code-extensie voor de promptstroom is geïnstalleerd, kunt u uw stroom eenvoudig lokaal ontwerpen vanuit de VS Code-editor, wat een vergelijkbare gebruikersinterface-ervaring biedt als in de cloud.
De extensie gebruiken:
- Open een map met promptstromen in VS Code Desktop.
- Open het bestand ''flow.dag.yaml' in de notitieblokweergave.
- Gebruik de visuele editor om de benodigde wijzigingen aan te brengen in uw stroom, zoals het afstemmen van de prompts in varianten of het toevoegen van meer hulpprogramma's.
- Als u uw stroom wilt testen, selecteert u de knop Stroom uitvoeren boven aan de visual-editor. Hiermee wordt een stroomtest geactiveerd.

Prompt flow local SDK & CLI
Als u liever Jupyter, PyCharm, Visual Studio of andere IDE's gebruikt, kunt u de YAML-definitie rechtstreeks in het flow.dag.yaml bestand wijzigen.

U kunt vervolgens één stroomuitvoering activeren voor testen met behulp van de CLI of SDK van de promptstroom.
Ervan uitgaande dat u zich in de werkmap bevindt <path-to-the-sample-repo>/examples/flows/standard/
pf flow test --flow web-classification # "web-classification" is the directory name


Hierdoor kunt u snel wijzigingen aanbrengen en testen, zonder dat u telkens de hoofdcodeopslagplaats hoeft bij te werken. Zodra u tevreden bent met de resultaten van uw lokale test, kunt u vervolgens overstappen naar het verzenden van uitvoeringen naar de cloud vanuit de lokale opslagplaats om experimentuitvoeringen uit te voeren in de cloud.
Raadpleeg de GitHub-community voor meer informatie en richtlijnen over het gebruik van de lokale versies.
Ga terug naar de gebruikersinterface van studio voor continue ontwikkeling
U kunt ook teruggaan naar de gebruikersinterface van studio, met behulp van de cloudresources en ervaring om wijzigingen aan te brengen in uw stroom op de pagina voor het ontwerpen van stromen.
Als u wilt doorgaan met het ontwikkelen en werken met de meest recente versie van de stroombestanden, hebt u toegang tot de terminal in het notebook en haalt u de meest recente wijzigingen van de stroombestanden op uit uw opslagplaats.
Als u liever in de gebruikersinterface van Studio blijft werken, kunt u bovendien rechtstreeks een lokale stroommap importeren als een nieuwe conceptstroom. Hierdoor kunt u naadloos overstappen tussen lokale en cloudontwikkeling.

CI/CD-integratie
CI: Triggerstroomuitvoeringen in CI-pijplijn
Zodra u uw stroom hebt ontwikkeld en getest en deze hebt ingecheckt als de eerste versie, bent u klaar voor de volgende afstemming en test iteratie. In deze fase kunt u stroomuitvoeringen activeren, waaronder batchtests en evaluatieuitvoeringen, met behulp van de CLI van de promptstroom. Dit kan fungeren als een geautomatiseerde werkstroom in uw CI-pijplijn (Continuous Integration).
Gedurende de levenscyclus van uw stroom-iteraties kunnen verschillende bewerkingen worden geautomatiseerd:
- Promptstroom uitvoeren na een pull-aanvraag
- Evaluatie van promptstroom uitvoeren om ervoor te zorgen dat de resultaten van hoge kwaliteit zijn
- Promptstroommodellen registreren
- Implementatie van promptstroommodellen
Zie End-to-End LLMOps instellen met prompt Flow en GitHub en het GitHub-demoproject voor een uitgebreide handleiding over een end-to-end MLOps-pijplijn die een webclassificatiestroom uitvoert.
CD: Continue implementatie
De laatste stap om naar productie te gaan, is het implementeren van uw stroom als een online-eindpunt in Azure Machine Learning. Hiermee kunt u uw stroom integreren in uw toepassing en deze beschikbaar maken voor gebruik.
Zie Stromen implementeren in een online-eindpunt van Azure Machine Learning voor realtime deductie met CLI en SDK voor meer informatie over het implementeren van uw stroom.
Samenwerken aan stroomontwikkeling in productie
In de context van het ontwikkelen van een LLM-toepassing met promptstroom is samenwerking tussen teamleden vaak essentieel. Teamleden kunnen betrokken zijn bij het ontwerpen en testen van dezelfde stroom, werken aan diverse facetten van de stroom of gelijktijdig iteratieve wijzigingen en verbeteringen aanbrengen.
Deze samenwerking vereist een efficiënte en gestroomlijnde aanpak voor het delen van code, het bijhouden van wijzigingen, het beheren van versies en het integreren van deze wijzigingen in het uiteindelijke project.
De introductie van de promptstroom-SDK /CLI en de Visual Studio Code-extensie als onderdeel van de code-ervaring van de promptstroom vereenvoudigt de samenwerking bij stroomontwikkeling in uw codeopslagplaats. Het is raadzaam om een cloudgebaseerde codeopslagplaats te gebruiken, zoals GitHub of Azure DevOps, voor het bijhouden van wijzigingen, het beheren van versies en het integreren van deze wijzigingen in het uiteindelijke project.
Best practice voor gezamenlijke ontwikkeling
Uw stroom lokaal ontwerpen en één test uitvoeren - Codeopslagplaats en VSC-extensie
- De eerste stap van dit samenwerkingsproces omvat het gebruik van een codeopslagplaats als basis voor uw projectcode, waaronder de promptstroomcode.
- Deze gecentraliseerde opslagplaats maakt een efficiënte organisatie mogelijk, tracering van alle codewijzigingen en samenwerking tussen teamleden.
- Zodra de opslagplaats is ingesteld, kunnen teamleden de VSC-extensie gebruiken voor lokaal ontwerpen en één invoertest van de stroom.
- Deze gestandaardiseerde geïntegreerde ontwikkelomgeving bevordert samenwerking tussen meerdere leden die aan verschillende aspecten van de stroom werken.
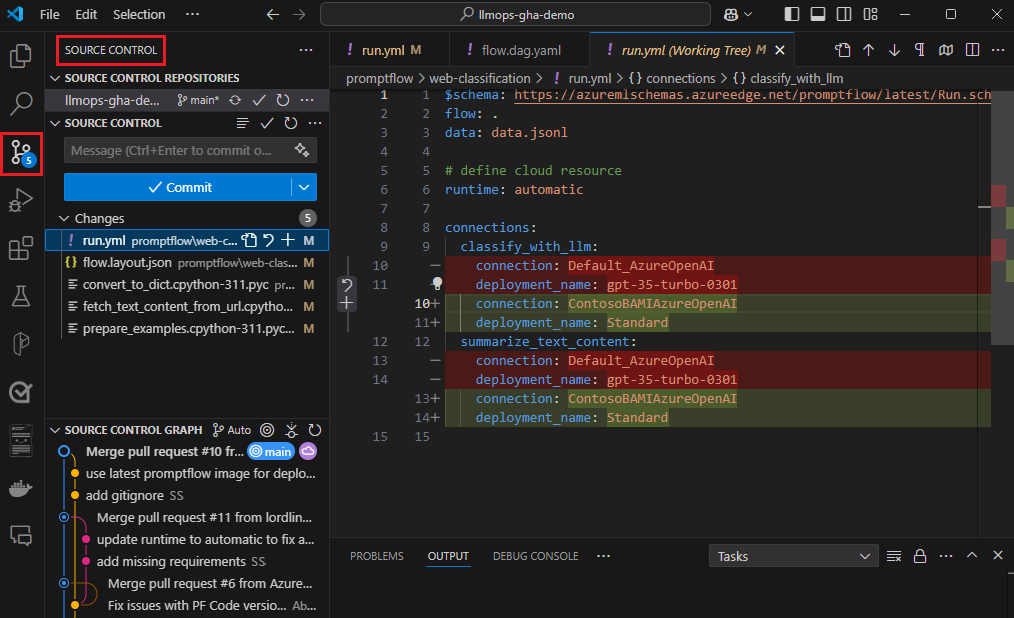
- Deze gestandaardiseerde geïntegreerde ontwikkelomgeving bevordert samenwerking tussen meerdere leden die aan verschillende aspecten van de stroom werken.
- De eerste stap van dit samenwerkingsproces omvat het gebruik van een codeopslagplaats als basis voor uw projectcode, waaronder de promptstroomcode.
Experimentele batchtests en -evaluatie in de cloud- en promptstroom-CLI/SDK en de gebruikersinterface van de werkruimteportal
- Na de lokale ontwikkelings- en testfase kunnen stroomontwikkelaars de pfazure CLI of SDK gebruiken om batchuitvoeringen en evaluatieuitvoeringen vanuit de lokale stroombestanden naar de cloud te verzenden.
- Deze actie biedt een manier voor het verbruik van cloudresources, resultaten die permanent en efficiënt moeten worden opgeslagen met een portalgebruikersinterface in de Azure Machine Learning-werkruimte. Met deze stap kunt u het verbruik van cloudresources, inclusief reken- en opslag- en verdere eindpunten voor implementaties.
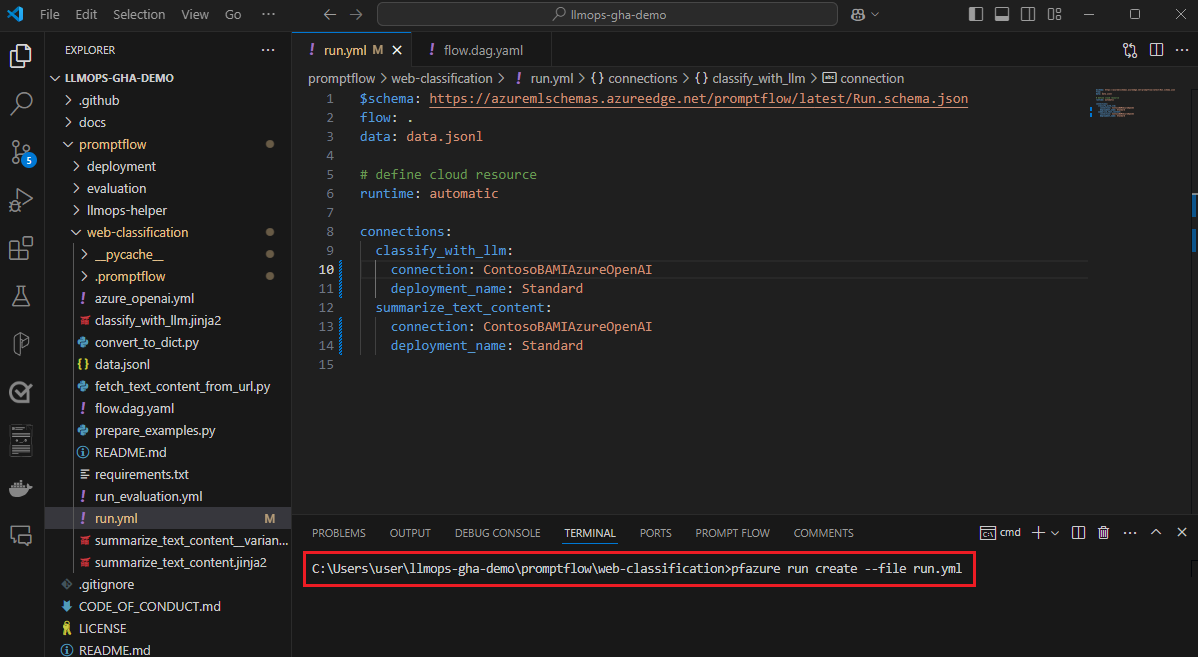
- Deze actie biedt een manier voor het verbruik van cloudresources, resultaten die permanent en efficiënt moeten worden opgeslagen met een portalgebruikersinterface in de Azure Machine Learning-werkruimte. Met deze stap kunt u het verbruik van cloudresources, inclusief reken- en opslag- en verdere eindpunten voor implementaties.
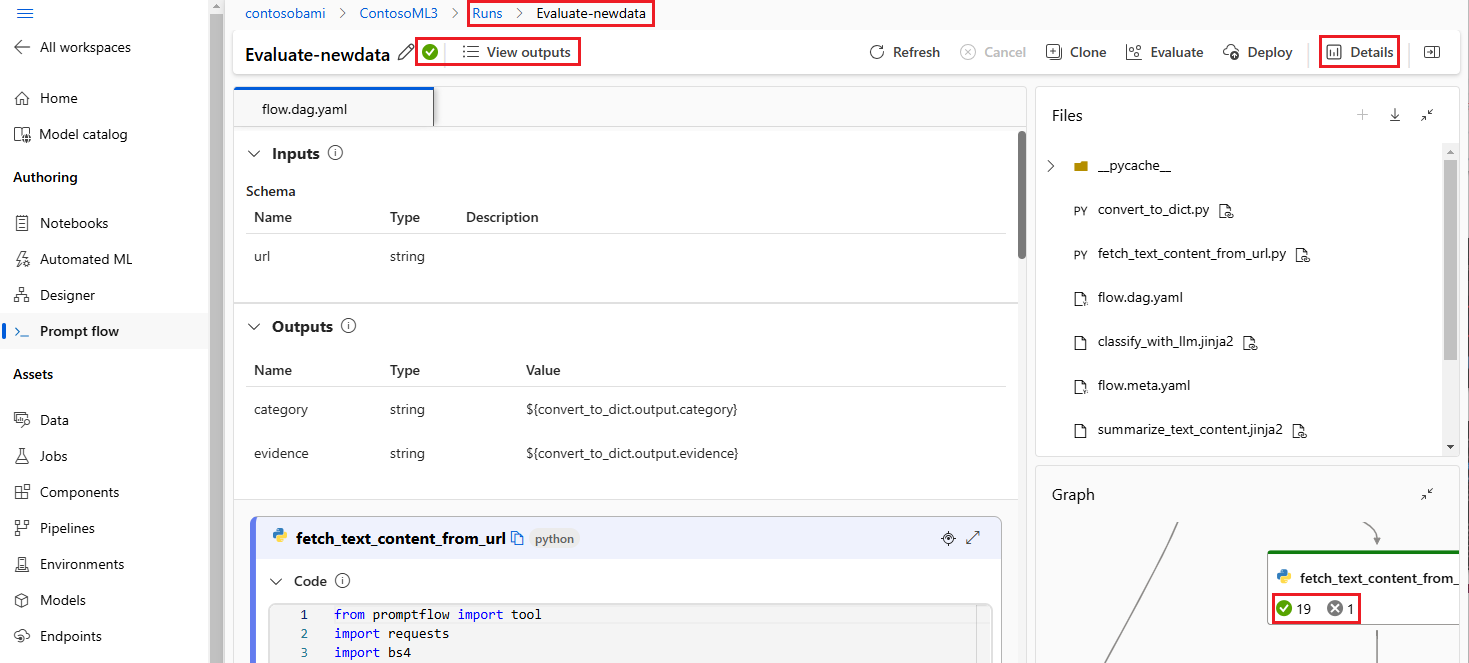
- Na verzendingen naar de cloud hebben teamleden toegang tot de gebruikersinterface van de cloudportal om de resultaten te bekijken en de experimenten efficiënt te beheren.
- Deze cloudwerkruimte biedt een centrale locatie voor het verzamelen en beheren van alle uitvoeringsgeschiedenis, logboeken, momentopnamen, uitgebreide resultaten, inclusief de invoer en uitvoer op exemplaarniveau.
- In de lijst met uitvoeringen waarin alle uitvoeringsgeschiedenis van tijdens de ontwikkeling wordt vastgelegd, kunnen teamleden eenvoudig de resultaten van verschillende uitvoeringen vergelijken, hulp bij kwaliteitsanalyse en noodzakelijke aanpassingen.
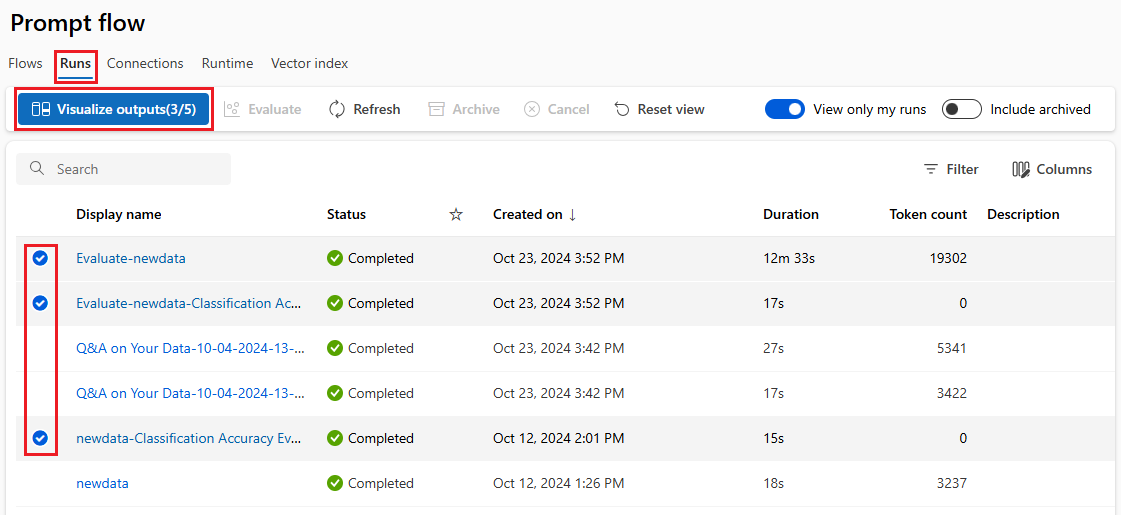

- Deze cloudwerkruimte biedt een centrale locatie voor het verzamelen en beheren van alle uitvoeringsgeschiedenis, logboeken, momentopnamen, uitgebreide resultaten, inclusief de invoer en uitvoer op exemplaarniveau.
- Na de lokale ontwikkelings- en testfase kunnen stroomontwikkelaars de pfazure CLI of SDK gebruiken om batchuitvoeringen en evaluatieuitvoeringen vanuit de lokale stroombestanden naar de cloud te verzenden.
Lokale iteratieve ontwikkeling of ui-implementatie in één stap voor productie
- Na de analyse van experimenten kunnen teamleden terugkeren naar de codeopslagplaats voor een andere ontwikkeling en afstemming. Volgende uitvoeringen kunnen vervolgens op een iteratieve manier naar de cloud worden verzonden.
- Deze iteratieve benadering zorgt voor consistente verbeteringen totdat het team tevreden is met de kwaliteit die gereed is voor productie.
- Zodra het team volledig vertrouwen heeft in de kwaliteit van de stroom, kan deze naadloos worden geïmplementeerd via een ui-wizard als een online-eindpunt in Azure Machine Learning. Zodra het team volledig vertrouwen heeft in de kwaliteit van de stroom, kan het naadloos worden overgezet naar productie via een implementatiewizard van de gebruikersinterface als een online-eindpunt in een robuuste cloudomgeving.
- Deze implementatie op een online-eindpunt kan worden gebaseerd op een momentopname van uitvoering, waardoor stabiele en veilige services mogelijk zijn, verdere resourcetoewijzing en gebruikstracering en logboekbewaking in de cloud.
- Deze implementatie op een online-eindpunt kan worden gebaseerd op een momentopname van uitvoering, waardoor stabiele en veilige services mogelijk zijn, verdere resourcetoewijzing en gebruikstracering en logboekbewaking in de cloud.
- Na de analyse van experimenten kunnen teamleden terugkeren naar de codeopslagplaats voor een andere ontwikkeling en afstemming. Volgende uitvoeringen kunnen vervolgens op een iteratieve manier naar de cloud worden verzonden.







Waarom we aanraden om de codeopslagplaats te gebruiken voor gezamenlijke ontwikkeling
Voor iteratieve ontwikkeling is een combinatie van een lokale ontwikkelomgeving en een versiebeheersysteem, zoals Git, doorgaans effectiever. U kunt wijzigingen aanbrengen en uw code lokaal testen en vervolgens de wijzigingen doorvoeren in Git. Hiermee maakt u een doorlopende record van uw wijzigingen en kunt u indien nodig terugkeren naar eerdere versies.
Wanneer stromen in verschillende omgevingen worden gedeeld , is het raadzaam om een cloudgebaseerde codeopslagplaats, zoals GitHub of Azure-opslagplaatsen, te gebruiken. Hierdoor hebt u vanaf elke locatie toegang tot de meest recente versie van uw code en beschikt u over hulpprogramma's voor samenwerking en codebeheer.
Door deze best practice te volgen, kunnen teams een naadloze, efficiënte en productieve samenwerkingsomgeving creëren voor snelle stroomontwikkeling.