Voorbeeldpijplijnen en -gegevenssets voor de Azure Machine Learning-ontwerpfunctie
Gebruik de ingebouwde voorbeelden in de Azure Machine Learning-ontwerpfunctie om snel aan de slag te gaan met het ontwerpen van uw eigen machine learning-pijplijnen. De GitHub-opslagplaats van de Azure Machine Learning-ontwerpfunctie bevat gedetailleerde documentatie om u te helpen enkele veelvoorkomende machine learning-scenario’s te begrijpen.
Vereisten
- Een Azure-abonnement. Als u nog geen Azure-abonnement hebt, maakt u een gratis account
- Een Azure Machine Learning-werkruimte
Belangrijk
Als u grafische elementen die in dit document worden vermeld, zoals knoppen in Studio of Designer, niet ziet, hebt u mogelijk niet het juiste machtigingsniveau voor de werkruimte. Neem contact op met de beheerder van uw Azure-abonnement om te controleren of u het juiste toegangsniveau hebt gekregen. Zie Gebruikers en rollen beherenvoor meer informatie.
Voorbeeldpijplijnen gebruiken
De ontwerpfunctie slaat een kopie van de voorbeeldpijplijnen op in uw Studio-werkruimte. U kunt de pijplijnen bewerken om ze op uw behoeften af te stemmen en als uw eigen opslaan. Gebruik ze als uitgangspunt om snel aan de slag te gaan met uw projecten.
Zo gebruikt u een voorbeeld in de ontwerpfunctie:
Meld u aan op ml.azure.com en selecteer de werkruimte waarmee u wilt werken.
Selecteer Ontwerper.
Selecteer een voorbeeldpijplijn in de sectie Nieuwe pijplijn.
Selecteer Meer voorbeelden weergeven voor een volledige lijst met voorbeelden.
Als u een pijplijn wilt uitvoeren, moet u eerst een standaard rekendoel instellen waarop de pijplijn wordt uitgevoerd.
In het deelvenster Instellingen rechts naast het canvas selecteert u Rekendoel selecteren.
In het dialoogvenster dat verschijnt, selecteert u een bestaand rekendoel of maakt u een nieuw rekendoel. Selecteer Opslaan.
Selecteer Verzenden boven aan het canvas om een pijplijntaak te verzenden.
Afhankelijk van de voorbeeldpijplijn en rekeninstellingen kan het enige tijd duren voordat taken zijn voltooid. De standaard rekeninstellingen hebben een minimale knooppuntgrootte van 0, wat betekent dat de ontwerpfunctie na inactiviteit resources moet toewijzen. Herhaalde pijplijntaken nemen minder tijd in beslag omdat de rekenresources al zijn toegewezen. Daarnaast gebruikt de ontwerper resultaten in de cache voor elk onderdeel om de efficiëntie verder te verbeteren.
Nadat de pijplijn is uitgevoerd, kunt u de pijplijn controleren en de uitvoer voor elk onderdeel bekijken voor meer informatie. Gebruik de volgende stappen om onderdeeluitvoer weer te geven:
- Klik met de rechtermuisknop op het onderdeel in het canvas waarvan u de uitvoer wilt zien.
- Selecteer Visualiseren.
Gebruik de voorbeelden als uitgangspunt voor enkele van de meestvoorkomende machine learning-scenario’s.
Regressie
Verken deze ingebouwde regressievoorbeelden.
| Voorbeeldtitel | Beschrijving |
|---|---|
| Regressie - Autoprijzen voorspellen (basis) | Voorspel autoprijzen met behulp van lineaire regressie. |
| Regressie - Autoprijzen voorspellen (geavanceerd) | Voorspel autoprijzen met behulp van regressors voor beslissingsforests en versterkte beslissingsstructuren. Vergelijk modellen om het beste algoritme te vinden. |
Classificatie
Verken deze ingebouwde classificatievoorbeelden. Meer informatie over de voorbeelden vindt u door de voorbeelden te openen en de opmerkingen van de onderdelen in de ontwerpfunctie te bekijken.
| Voorbeeldtitel | Beschrijving |
|---|---|
| Binaire classificatie met functieselectie - Inkomen voorspellen | Voorspel inkomen als hoog of laag met behulp van een versterkte beslissingsstructuur met twee klassen. Gebruik Pearson-correlatie om functies te selecteren. |
| Binaire classificatie met aangepast Python-script - Kredietrisico voorspellen | Classificeer kredietaanvragen als hoog of laag risico. Gebruik het onderdeel Python-script uitvoeren om uw gegevens te wegen. |
| Binaire classificatie - Klantrelaties voorspellen | Voorspel klantverloop met behulp van versterkte beslissingsstructuren met twee klassen. Gebruik SMOTE bevooroordeelde gegevens te samplen. |
| Tekstclassificatie - Gegevensset Wikipedia SP 500 | Classificeer bedrijfstypen uit Wikipedia-artikelen met behulp van logistieke regressie met meerdere klassen. |
| Classificatie met meerdere klassen - Brieven herkennen | Maak een set binaire classificaties om geschreven brieven te classificeren. |
Computer Vision
Verken deze ingebouwde computervisievoorbeelden. Meer informatie over de voorbeelden vindt u door de voorbeelden te openen en de opmerkingen van de onderdelen in de ontwerpfunctie te bekijken.
| Voorbeeldtitel | Beschrijving |
|---|---|
| Afbeeldingsclassificatie met behulp van DenseNet | Computer Vision-onderdelen gebruiken om een model voor afbeeldingsclassificatie te bouwen op basis van PyTorch DenseNet. |
Aanbevelingsfunctie
Verken deze ingebouwde aanbevelingsvoorbeelden. Meer informatie over de voorbeelden vindt u door de voorbeelden te openen en de opmerkingen van de onderdelen in de ontwerpfunctie te bekijken.
| Voorbeeldtitel | Beschrijving |
|---|---|
| Wide & Deep-aanbeveling - Voorspelling van restaurantbeoordeling | Bouw een aanbevelingsengine voor restaurants van restaurant/gebruikersfuncties en beoordelingen. |
| Aanbeveling - Tweets met filmbeoordelingen | Maak een filmaanbevelings-engine van filmtitels, gebruikersfuncties en beoordelingen. |
Hulpprogramma
Meer informatie over de voorbeelden die machine learning-hulpprogramma’s en -functies demonstreren. Meer informatie over de voorbeelden vindt u door de voorbeelden te openen en de opmerkingen van de onderdelen in de ontwerpfunctie te bekijken.
| Voorbeeldtitel | Beschrijving |
|---|---|
| Binaire classificatie met behulp van Vowpal Wabbit Model - Volwassen inkomen voorspellen | Vowpal Wabbit is een machine learning-systeem dat de grens van machine learning pusht met technieken zoals online, hashing, allreduce, reducties, learning2search, actief en interactief leren. In dit voorbeeld ziet u hoe u het Vowpal Wabbit-model gebruikt om een binair classificatiemodel te maken. |
| Aangepast R-script gebruiken - Vertraagde vluchten voorspellen | Gebruik aangepast R-script om te voorspellen of een geplande vlucht meer dan 15 minuten vertraging gaat hebben. |
| Kruisvalidatie voor binaire classificatie - Volwassen inkomen voorspellen | Gebruik kruisvalidatie om een binaire classificatie voor volwassen inkomen te ontwerpen. |
| Belang van permutatiefunctie | Gebruik belang van permutatiefunctie om belangscores voor de testgegevensset te berekenen. |
| Parameters afstemmen voor binaire classificatie - Volwassen inkomen voorspellen | Gebruik Model Hyperparameters afstemmen voor het vinden van optimale hyperparameters om een binaire classificatie te ontwerpen. |
Gegevenssets
Wanneer u een nieuwe pijplijn maakt in de Azure Machine Learning-ontwerpfunctie, zijn er standaard een aantal voorbeeldgegevenssets inbegrepen. Deze voorbeeldgegevenssets worden gebruikt door de voorbeeldpijplijnen op de startpagina van de ontwerpfunctie.
De voorbeeldgegevenssets zijn beschikbaar onder de categorie Gegevenssets-Voorbeelden. U vindt dit in het onderdeelpalet links van het canvas in de ontwerpfunctie. U kunt elk van deze gegevenssets in uw eigen pijplijn gebruiken door deze naar het canvas te slepen.
| Naam van gegevensset | Beschrijving van gegevensset |
|---|---|
| Gegevensset Binaire classificatie voor volwassen Census-inkomen | Een subset van de volkstellingsdatabase van 1994, waarbij werkende volwassenen ouder dan 16 jaar worden gebruikt met een aangepaste inkomensindex van > 100. Gebruik: Classificeer personen die demografische gegevens gebruiken om te voorspellen of een persoon meer dan 50.000 per jaar verdient. Gerelateerd onderzoek: Kohavi, R., Becker, B., (1996). UCI Machine Learning Repository. Irvine, CA: University of California, School of Information and Computer Science |
| Autoprijsgegevens (onbewerkt) | Informatie over auto’s per merk en model, waaronder de prijs, kenmerken zoals het aantal cilinders en MPG, evenals een verzekeringsrisicoscore. De risicoscore is aanvankelijk gekoppeld aan de autoprijs. Vervolgens wordt het aangepast voor daadwerkelijk risico in een proces dat verzekeringswiskundigen symbolisering noemen. Een waarde van +3 geeft aan dat de auto risicovol is, en een waarde van -3 dat deze waarschijnlijk veilig is. Gebruik: De risicoscore voorspellen op basis van functies, met behulp van regressie of multivariate classificatie. Gerelateerd onderzoek: Schlimmer, J.C. (1987). UCI Machine Learning Repository. Irvine, CA: University of California, School of Information and Computer Science. |
| Gedeelde labels CRM-verlangen | Labels uit de KDD Cup 2009-uitdaging Klantrelaties voorspellen (orange_small_train_appetency.labels). |
| Gedeelde labels CRM-verloop | Labels uit de KDD Cup 2009-uitdaging Klantrelaties voorspellen (orange_small_train_churn.labels). |
| Gedeelde CRM-gegevensset | Deze gegevens komen uit de KDD Cup 2009-uitdaging Klantrelaties voorspellen (orange_small_train.data.zip). De gegevensset bevat 50.000 klanten van het Franse telecombedrijf Orange. Elke klant heeft 230 geanonimiseerde kenmerken, waarvan 190 numeriek en 40 categorisch zijn. De kenmerken zijn zeer verspreid. |
| Gedeelde labels CRM-upselling | Labels uit de KDD Cup 2009-uitdaging Klantrelaties voorspellen (orange_large_train_upselling.labels). |
| Gegevens over vluchtvertragingen | Passagiersvlucht on-time prestatiegegevens die zijn genomen uit de TranStats-gegevensverzameling van het Amerikaanse Ministerie van Transport (On-Time). De gegevensset dekt de tijdsperiode april t/m oktober 2013. Voordat u naar de ontwerpfunctie uploadt, is de gegevensset als volgt verwerkt: - De gegevensset is gefilterd om alleen de 70 drukste luchthavens in de continentale VS te dekken - Geannuleerde vluchten zijn gelabeld als vertraagd met meer dan 15 minuten - Afwijkende vluchten zijn uitgefilterd - De volgende kolommen zijn geselecteerd: Year, Month, DayofMonth, DayOfWeek, Carrier, OriginAirportID, DestAirportID, CRSDepTime, DepDelay, DepDel15, CRSArrTime, ArrDelay, ArrDel15, Canceled |
| Gegevensset UCI German Credit Card | De gegevensset UCI Statlog (German Credit Card) (Statlog+German+Credit+Data), die het german.data-bestand gebruikt. De gegevensset classificeert personen, beschreven door een set kenmerken, als laag of hoog kredietrisico. Elk voorbeeld vertegenwoordigt een persoon. Er zijn 20 kenmerken, zowel numeriek als categorisch, en een binair label (de kredietrisicowaarde). Vermeldingen van een hoog kredietrisico hebben label = 2, vermeldingen van een laag kredietrisico hebben label = 1. De kosten van het verkeerd classificeren van een voorbeeld met laag risico als hoog is 1, en de kosten van het verkeerd classificeren van een voorbeeld met hoog risico als laag is 5. |
| IMDB-filmtitels | De gegevensset bevat informatie over films die zijn geclassificeerd in Twitter-tweets: IMDB-film-id, filmnaam, genre en productiejaar. De gegevensset bevat 17.000 films. De gegevensset werd geïntroduceerd in het rapport "S. Dooms, T. De Pessemier en L. Martens. MovieTweetings: a Movie Rating Dataset Collected From Twitter. Workshop on Crowdsourcing and Human Computation for Recommender Systems, CrowdRec at RecSys 2013." |
| Filmbeoordelingen | Deze gegevensset is een uitgebreide versie van de gegevensset MovieTweetings. De gegevensset bevat 170.000 beoordelingen van films, geëxtraheerd uit goed gestructureerde tweets op Twitter. Elk exemplaar vertegenwoordigt een tweet en is een tuple: gebruikers-ID, IMDB-film-ID, beoordeling, tijdstempel, aantal vind-ik-leuks van deze tweet en aantal retweets van deze tweet. De gegevensset werd beschikbaar gesteld door A. Said, S. Dooms, B. Loni en D. Tikk voor Recommender Systems Challenge 2014. |
| Gegevensset Weer | Weerobservaties op het land per uur van NOAA (samengevoegde gegevens van 201304 tot 201310). De weersgegevens komen van observaties uit weerstations op luchthavens en dekken de tijdsperiode april t/m oktober 2013. Voordat u naar de ontwerpfunctie uploadt, is de gegevensset als volgt verwerkt: - Weerstation-id's zijn toegewezen aan bijbehorende luchthaven-id's - Weerstations die niet zijn gekoppeld aan de 70 drukste luchthavens werden uitgefilterd - De kolom Date is gesplitst in afzonderlijke kolommen Year, Month en Day - De volgende kolommen zijn geselecteerd: AirportID, Year, Month, Day, Time, Time, SkyCondition, Visibility, WeatherType, DryBulbFarenheit, DryBulbCelsius, WetBulbFarenheit, WetBulbFarenhius, DewPointFarenheit, DewPointCelsius, RelativeHumidity, WindSpeed, WindDirection, ValueForWindCharacter, StationPressure, PressureTendency, PressureChange, SeaLevelPressure, RecordType, HourlyPrecip, Altimeter |
| Gegevensset Wikipedia SP 500 | Gegevens zijn afkomstig van Wikipedia (https://www.wikipedia.org/) op basis van artikelen van elk S&P 500-bedrijf, opgeslagen als XML-gegevens. Voordat u naar de ontwerpfunctie uploadt, is de gegevensset als volgt verwerkt: - Tekstinhoud extraheren voor elk specifiek bedrijf - Wikiopmaak verwijderen - Niet-alfanumerieke tekens verwijderen - Alle tekst converteren naar kleine letters - Bekende bedrijfscategorieën zijn toegevoegd Voor sommige bedrijven kon er geen artikel worden gevonden, waardoor het aantal records minder dan 500 is. |
| Gegevens over restaurantkenmerken | Een set metagegevens over restaurants en hun kenmerken, zoals type gerechten, beoogd publiek en locatie. Gebruik: Gebruik deze gegevensset in combinatie met de andere twee restaurantgegevenssets om een aanbevelingssysteem te trainen en te testen. Gerelateerd onderzoek: Bache, K. en Lichman, M. (2013). UCI Machine Learning Repository. Irvine, CA: University of California, School of Information and Computer Science. |
| Restaurantbeoordelingen | Bevat beoordelingen van gebruikers over restaurants op een schaal van 0 tot 2. Gebruik: Gebruik deze gegevensset in combinatie met de andere twee restaurantgegevenssets om een aanbevelingssysteem te trainen en te testen. Gerelateerd onderzoek: Bache, K. en Lichman, M. (2013). UCI Machine Learning Repository. Irvine, CA: University of California, School of Information and Computer Science. |
| Gegevens van bezoekers van restaurants | Een set metagegevens over klanten, inclusief demografische informatie en voorkeuren. Gebruik: Gebruik deze gegevensset in combinatie met de andere twee restaurantgegevenssets om een aanbevelingssysteem te trainen en te testen. Gerelateerd onderzoek: Bache, K. en Lichman, M. (2013). UCI Machine Learning Repository Irvine, CA: University of California, School of Information and Computer Science. |
Resources opschonen
Belangrijk
U kunt de resources die u hebt gemaakt, gebruiken als vereisten voor andere Azure Machine Learning-zelfstudies en artikelen met procedures.
Alles verwijderen
Als u niets wilt gebruiken dat u hebt gemaakt, kunt u de hele resourcegroep verwijderen zodat er geen kosten voor in rekening worden gebracht.
Selecteer in Azure Portal, aan de linkerkant in het venster, de optie Resourcegroepen.
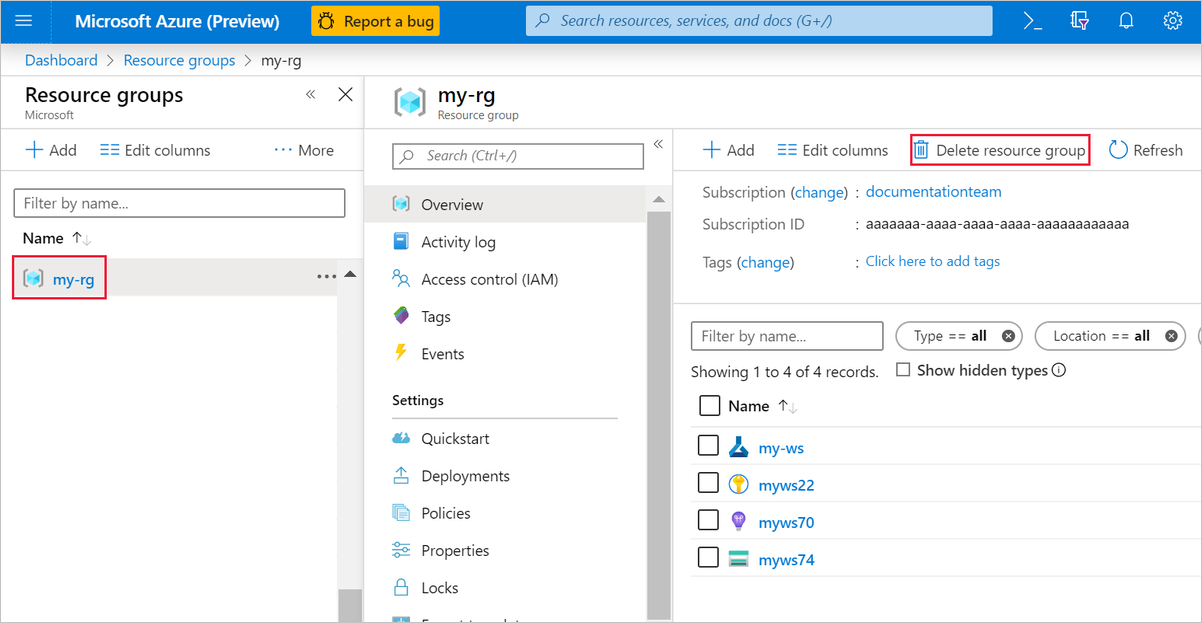
Selecteer de resourcegroep die u hebt gemaakt in de lijst.
Selecteer Resourcegroep verwijderen.
Als u de resource groep verwijdert, worden ook alle resources verwijderd die u in de ontwerpfunctie hebt gemaakt.
Afzonderlijke assets verwijderen
In de ontwerpfunctie waar u uw experiment hebt gemaakt, verwijdert u afzonderlijke assets door ze te selecteren en vervolgens de knop Verwijderen te selecteren.
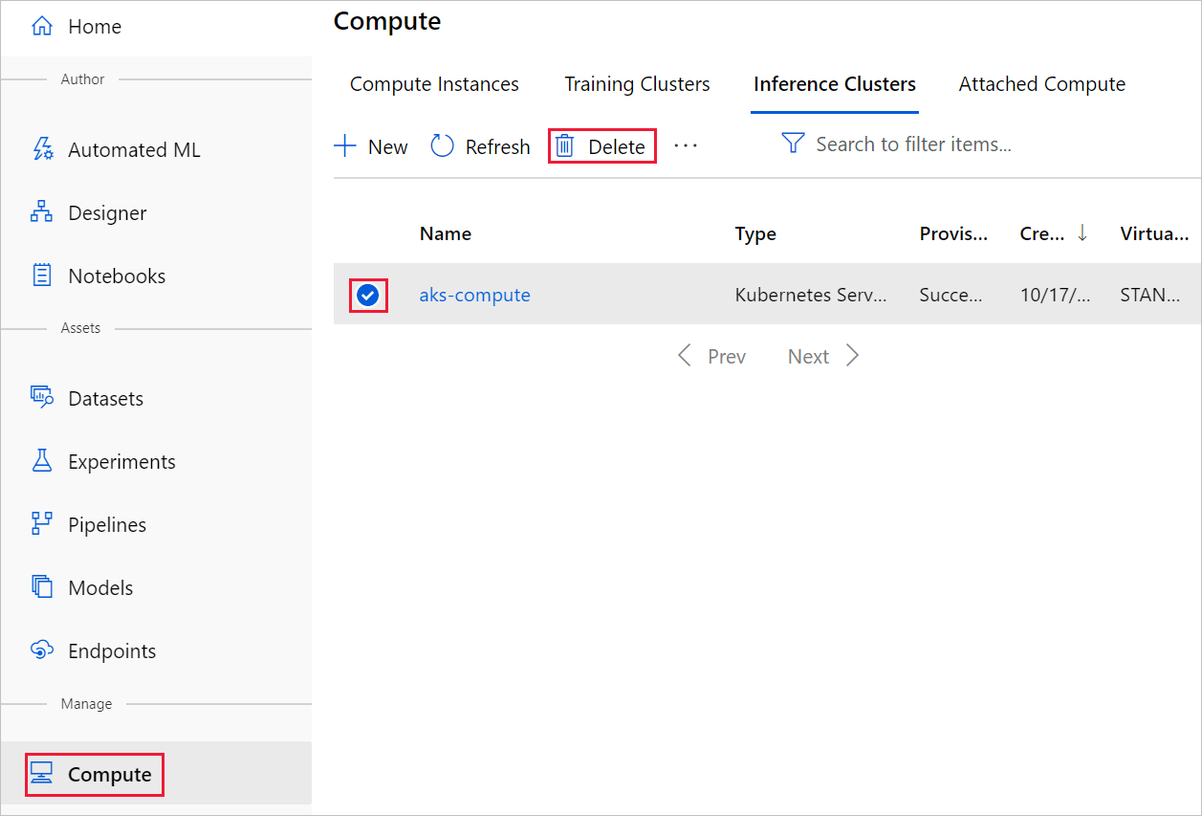
Het rekendoel dat u hier hebt gemaakt, wordt, wanneer het niet wordt gebruikt, automatisch geschaald naar nul knooppunten. Deze actie wordt uitgevoerd om de kosten te minimaliseren. Als u het rekendoel wilt verwijderen, voert u de volgende stappen uit:
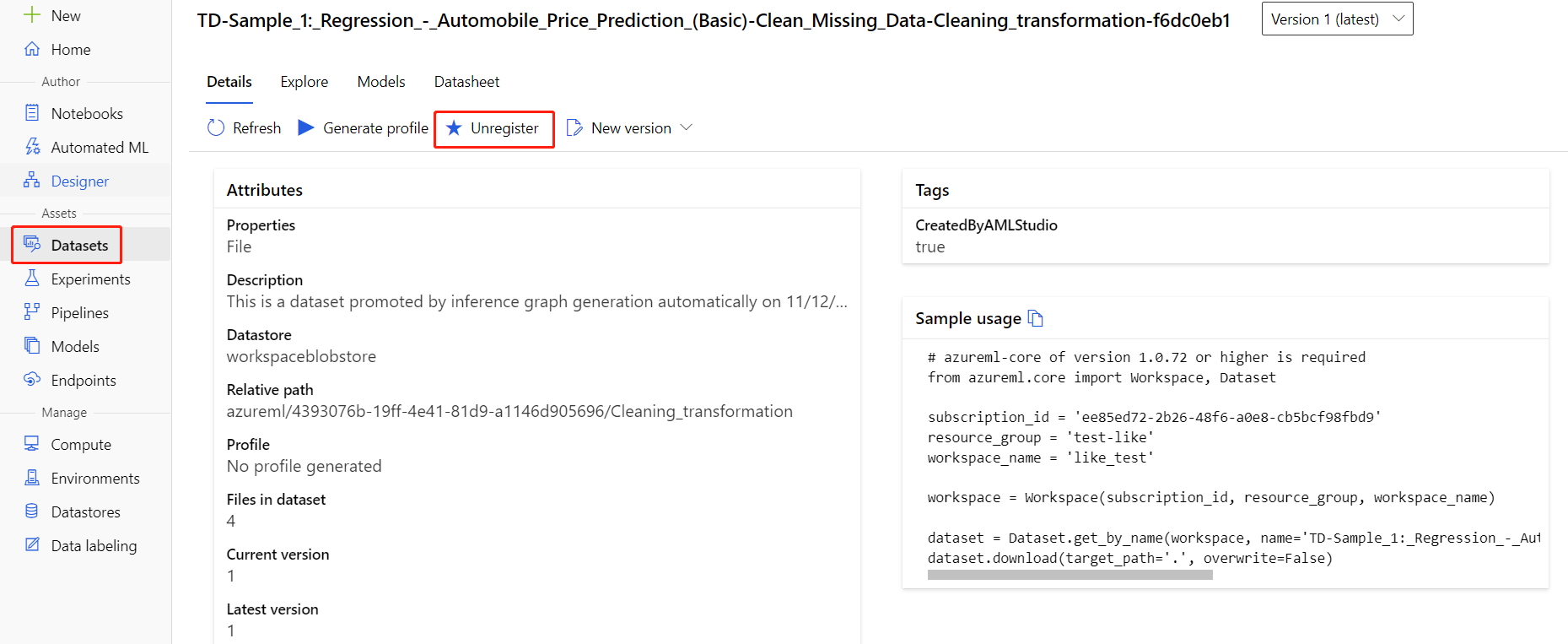
U kunt de registratie van gegevenssets vanuit uw werkruimte opheffen door alle gegevenssets te selecteren en Registratie opheffen te selecteren.
Als u een gegevensset wilt verwijderen, gaat u naar het opslagaccount via Azure Portal of Azure Storage Explorer en verwijdert u de assets handmatig.
Volgende stappen
Leer de basisprincipes van predictive analytics en machine learning met zelfstudie: Autoprijs voorspellen met de ontwerper