Zelfstudie: Uw eerste Machine Learning-model trainen (SDK v1, deel 2 van 3)
VAN TOEPASSING OP: Python SDK azureml v1
Python SDK azureml v1
Deze zelfstudie laat zien hoe u een machine learning-model traint in Azure Machine Learning. Deze zelfstudie is deel 2 van een tweedelige reeks zelfstudies.
In deel 1: 'Hallo wereld!' van de reeks uitvoeren, hebt u geleerd hoe u een besturingsscript gebruikt om een taak uit te voeren in de cloud.
In deze zelfstudie voert u de volgende stap uit door een script te verzenden dat een machine learning-model traint. In dit voorbeeld leert u hoe Azure Machine Learning consistent gedrag vereenvoudigt tussen lokale foutopsporing en externe uitvoeringen.
In deze zelfstudie hebt u:
- Maak een trainingsscript.
- Conda gebruiken om een Azure Machine Learning-omgeving te definiëren.
- Een besturingsscript maken.
- Inzicht krijgen in Azure Machine Learning-klassen (
Environment,Run,Metrics). - Uw trainingsscript verzenden en uitvoeren.
- De code-uitvoer weergeven in de cloud.
- De metrische gegevens vastleggen in Azure Machine Learning.
- Uw metrische gegevens bekijken in de cloud.
Vereisten
- Voltooiing van deel 1 van de reeks.
Trainingsscripts maken
Eerst definieert u de neurale netwerkarchitectuur in een model.py-bestand . Al uw trainingscode gaat naar de src submap, inclusief model.py.
De trainingscode is afkomstig uit dit inleidende voorbeeld van PyTorch. De Azure Machine Learning-concepten zijn van toepassing op machine learning-code, niet alleen Op PyTorch.
Maak een model.py-bestand in de src-submap . Kopieer deze code naar het bestand:
import torch.nn as nn import torch.nn.functional as F class Net(nn.Module): def __init__(self): super(Net, self).__init__() self.conv1 = nn.Conv2d(3, 6, 5) self.pool = nn.MaxPool2d(2, 2) self.conv2 = nn.Conv2d(6, 16, 5) self.fc1 = nn.Linear(16 * 5 * 5, 120) self.fc2 = nn.Linear(120, 84) self.fc3 = nn.Linear(84, 10) def forward(self, x): x = self.pool(F.relu(self.conv1(x))) x = self.pool(F.relu(self.conv2(x))) x = x.view(-1, 16 * 5 * 5) x = F.relu(self.fc1(x)) x = F.relu(self.fc2(x)) x = self.fc3(x) return xSelecteer Opslaan op de werkbalk om het bestand op te slaan. Sluit desgewenst het tabblad.
Definieer vervolgens het trainingsscript, ook in de src-submap . Met dit script wordt de CIFAR10-gegevensset gedownload met behulp van PyTorch-API's
torchvision.dataset, wordt het netwerk ingesteld dat is gedefinieerd in model.py en wordt deze getraind voor twee tijdvakken met behulp van standaard-SGD- en entropieverlies.Maak een train.py script in de submap src :
import torch import torch.optim as optim import torchvision import torchvision.transforms as transforms from model import Net # download CIFAR 10 data trainset = torchvision.datasets.CIFAR10( root="../data", train=True, download=True, transform=torchvision.transforms.ToTensor(), ) trainloader = torch.utils.data.DataLoader( trainset, batch_size=4, shuffle=True, num_workers=2 ) if __name__ == "__main__": # define convolutional network net = Net() # set up pytorch loss / optimizer criterion = torch.nn.CrossEntropyLoss() optimizer = optim.SGD(net.parameters(), lr=0.001, momentum=0.9) # train the network for epoch in range(2): running_loss = 0.0 for i, data in enumerate(trainloader, 0): # unpack the data inputs, labels = data # zero the parameter gradients optimizer.zero_grad() # forward + backward + optimize outputs = net(inputs) loss = criterion(outputs, labels) loss.backward() optimizer.step() # print statistics running_loss += loss.item() if i % 2000 == 1999: loss = running_loss / 2000 print(f"epoch={epoch + 1}, batch={i + 1:5}: loss {loss:.2f}") running_loss = 0.0 print("Finished Training")U hebt nu de volgende mapstructuur:
Lokaal testen
Selecteer Opslaan en script uitvoeren in terminal om het train.py script rechtstreeks op het rekenproces uit te voeren.
Nadat het script is voltooid, selecteert u Vernieuwen boven de bestandsmappen. U ziet de nieuwe gegevensmap aan de slag /gegevens Vouw deze map uit om de gedownloade gegevens weer te geven.
Een Python-omgeving maken
Azure Machine Learning biedt het concept van een omgeving als een reproduceerbare Python-omgeving met versies waarin u experimenten kunt uitvoeren. Het is eenvoudig om een omgeving te maken op basis van een lokale Conda- of PIP-omgeving.
Eerst maakt u een bestand met de pakketafhankelijkheden.
Maak een nieuw bestand in de map Aan de slag met de naam
pytorch-env.yml:name: pytorch-env channels: - defaults - pytorch dependencies: - python=3.7 - pytorch - torchvisionSelecteer Opslaan op de werkbalk om het bestand op te slaan. Sluit desgewenst het tabblad.
Het besturingsscript maken
Het verschil tussen het volgende besturingsscript en het script dat u hebt gebruikt om 'Hallo wereld!' in te dienen, is dat u een aantal extra regels toevoegt om de omgeving in te stellen.
Maak een nieuw Python-bestand in de map Aan de slag met de naamrun-pytorch.py:
# run-pytorch.py
from azureml.core import Workspace
from azureml.core import Experiment
from azureml.core import Environment
from azureml.core import ScriptRunConfig
if __name__ == "__main__":
ws = Workspace.from_config()
experiment = Experiment(workspace=ws, name='day1-experiment-train')
config = ScriptRunConfig(source_directory='./src',
script='train.py',
compute_target='cpu-cluster')
# set up pytorch environment
env = Environment.from_conda_specification(
name='pytorch-env',
file_path='pytorch-env.yml'
)
config.run_config.environment = env
run = experiment.submit(config)
aml_url = run.get_portal_url()
print(aml_url)
Tip
Als u een andere naam hebt gebruikt bij het maken van uw rekencluster, moet u ook de naam in de code compute_target='cpu-cluster' aanpassen.
De codewijzigingen begrijpen
env = ...
Verwijst naar het afhankelijkheidsbestand dat u hierboven hebt gemaakt.
config.run_config.environment = env
De omgeving wordt toegevoegd aan ScriptRunConfig.
De uitvoering versturen naar Microsoft Azure Machine Learning
Selecteer Opslaan en script uitvoeren in terminal om het run-pytorch.py script uit te voeren.
U ziet een koppeling in het terminalvenster dat wordt geopend. Selecteer de koppeling om de taak weer te geven.
Notitie
Er worden mogelijk enkele waarschuwingen weergegeven die beginnen met fouten tijdens het laden van azureml_run_type_providers.... U kunt deze waarschuwingen negeren. Gebruik de koppeling onder aan deze waarschuwingen om de uitvoer weer te geven.
De uitvoer weergeven
- Op de pagina die wordt geopend, ziet u de taakstatus. De eerste keer dat u dit script uitvoert, bouwt Azure Machine Learning een nieuwe Docker-installatiekopieën uit uw PyTorch-omgeving. Het kan ongeveer 10 minuten duren voordat de hele taak is voltooid. Deze installatiekopieën worden in toekomstige taken opnieuw gebruikt om ze veel sneller uit te voeren.
- U kunt de Build-logboeken van Docker bekijken in de Azure Machine Learning-studio. om de buildlogboeken weer te geven:
- Selecteer het tabblad Uitvoer en logboeken.
- Selecteer de map azureml-logs .
- Selecteer 20_image_build_log.txt.
- Wanneer de status van de taak is voltooid, selecteert u Uitvoer en logboeken.
- Selecteer user_logs en std_log.txt om de uitvoer van uw taak weer te geven.
Downloading https://www.cs.toronto.edu/~kriz/cifar-10-python.tar.gz to ../data/cifar-10-python.tar.gz
Extracting ../data/cifar-10-python.tar.gz to ../data
epoch=1, batch= 2000: loss 2.19
epoch=1, batch= 4000: loss 1.82
epoch=1, batch= 6000: loss 1.66
...
epoch=2, batch= 8000: loss 1.51
epoch=2, batch=10000: loss 1.49
epoch=2, batch=12000: loss 1.46
Finished Training
Als er een fout wordt weergegeven Your total snapshot size exceeds the limit, bevindt de gegevensmap zich in de source_directory waarde die wordt gebruikt in ScriptRunConfig.
Selecteer de ... aan het einde van de map en selecteer vervolgens Verplaatsen om gegevens naar de map Aan de slag te verplaatsen.
Metrische gegevens van training registreren
Nu u een modeltraining in Azure Machine Learning hebt, kunt u een aantal prestatiegegevens gaan bijhouden.
Met het huidige trainingsscript worden metrische gegevens naar de terminal afgedrukt. Azure Machine Learning biedt een mechanisme voor het vastleggen van metrische gegevens met meer functionaliteit. Door een paar regels code toe te voegen, krijgt u de mogelijkheid om metrische gegevens in de studio te visualiseren en metrische gegevens tussen meerdere taken te vergelijken.
Train.py wijzigen om logboekregistratie op te nemen
Wijzig uw train.py script zodat er nog twee regels code worden opgenomen:
import torch import torch.optim as optim import torchvision import torchvision.transforms as transforms from model import Net from azureml.core import Run # ADDITIONAL CODE: get run from the current context run = Run.get_context() # download CIFAR 10 data trainset = torchvision.datasets.CIFAR10( root='./data', train=True, download=True, transform=torchvision.transforms.ToTensor() ) trainloader = torch.utils.data.DataLoader( trainset, batch_size=4, shuffle=True, num_workers=2 ) if __name__ == "__main__": # define convolutional network net = Net() # set up pytorch loss / optimizer criterion = torch.nn.CrossEntropyLoss() optimizer = optim.SGD(net.parameters(), lr=0.001, momentum=0.9) # train the network for epoch in range(2): running_loss = 0.0 for i, data in enumerate(trainloader, 0): # unpack the data inputs, labels = data # zero the parameter gradients optimizer.zero_grad() # forward + backward + optimize outputs = net(inputs) loss = criterion(outputs, labels) loss.backward() optimizer.step() # print statistics running_loss += loss.item() if i % 2000 == 1999: loss = running_loss / 2000 # ADDITIONAL CODE: log loss metric to AML run.log('loss', loss) print(f'epoch={epoch + 1}, batch={i + 1:5}: loss {loss:.2f}') running_loss = 0.0 print('Finished Training')Sla dit bestand op en sluit het tabblad desgewenst.
Meer informatie over de twee extra regels code
In train.py opent u het uitvoeringsobject vanuit het trainingsscript zelf met behulp van de Run.get_context() methode en gebruikt u het om metrische gegevens te registreren:
# ADDITIONAL CODE: get run from the current context
run = Run.get_context()
...
# ADDITIONAL CODE: log loss metric to AML
run.log('loss', loss)
De metrische gegevens in Azure Machine Learning zijn:
- Geordend op experiment en uitvoering, zodat u gemakkelijk metrische gegevens kunt bijhouden en vergelijken.
- Voorzien van een gebruikersinterface, zodat u de trainingsprestaties in de studio kunt visualiseren.
- Ontworpen om te worden geschaald, dus u behoudt deze voordelen, zelfs als u honderden experimenten uitvoert.
Het Conda-omgevingsbestand bijwerken
Het train.py-script heeft zojuist een nieuwe afhankelijkheid van azureml.core gekregen. Werk pytorch-env.yml bij om deze wijziging weer te geven:
name: pytorch-env
channels:
- defaults
- pytorch
dependencies:
- python=3.7
- pytorch
- torchvision
- pip
- pip:
- azureml-sdk
Zorg ervoor dat u dit bestand opslaat voordat u de uitvoering verzendt.
De uitvoering versturen naar Microsoft Azure Machine Learning
Selecteer het tabblad voor het run-pytorch.py script en selecteer vervolgens Opslaan en script uitvoeren in terminal om het run-pytorch.py script opnieuw uit te voeren. Zorg ervoor dat u de wijzigingen pytorch-env.yml eerst opslaat.
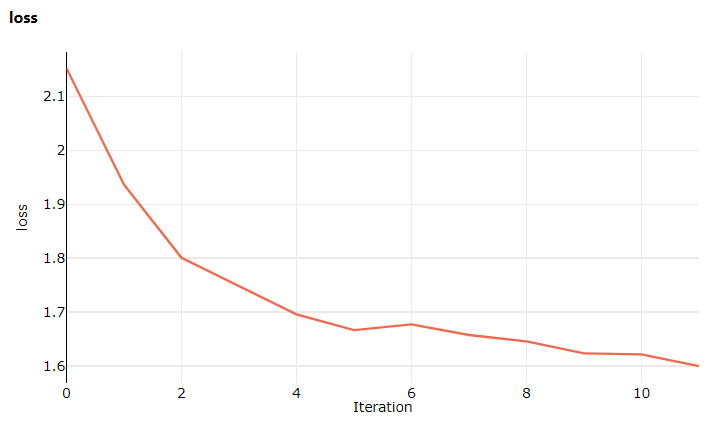
Wanneer u deze keer de studio bezoekt, gaat u naar het tabblad Metrische gegevens, waar u nu live-updates kunt zien van het modeltrainingsverlies. Het kan 1 tot 2 minuten duren voordat de training begint.
Resources opschonen
Als u van plan bent om nu door te gaan naar een andere zelfstudie of als u uw eigen trainingstaken wilt starten, gaat u verder met gerelateerde resources.
Rekenproces stoppen
Als u deze nu niet gaat gebruiken, stopt u het rekenproces:
- Selecteer Compute in de studio aan de linkerkant.
- Selecteer op de bovenste tabbladen Rekeninstanties
- Selecteer het rekenproces in de lijst.
- Selecteer Stoppen op de bovenste werkbalk.
Alle resources verwijderen
Belangrijk
De resources die u hebt gemaakt, kunnen worden gebruikt als de vereisten voor andere Azure Machine Learning-zelfstudies en artikelen met procedures.
Als u niet van plan bent om een van de resources te gebruiken die u hebt gemaakt, verwijdert u deze zodat er geen kosten in rekening worden gebracht:
Voer in azure Portal in het zoekvak resourcegroepen in en selecteer deze in de resultaten.
Selecteer de resourcegroep die u hebt gemaakt uit de lijst.
Selecteer op de pagina Overzicht de optie Resourcegroep verwijderen.
Voer de naam van de resourcegroup in. Selecteer daarna Verwijderen.
U kunt de resourcegroep ook bewaren en slechts één werkruimte verwijderen. Bekijk de eigenschappen van de werkruimte en selecteer Verwijderen.
Verwante resources
In deze sessie hebt u een upgrade uitgevoerd van een eenvoudig Hallo wereld-script naar een realistischer trainingsscript waarvoor een specifieke Python-omgeving moest worden uitgevoerd. U hebt gezien hoe u gecureerde Azure Machine Learning-omgevingen gebruikt. Ten slotte hebt u gezien hoe u in een paar regels code de metrische gegevens kunt vastleggen voor Azure Machine Learning.
Er zijn andere manieren om Azure Machine Learning-omgevingen te maken, zoals van een TXT-bestand met PIP-vereisten of van een bestaande lokale Conda-omgeving.