Notitie
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen u aan te melden of de directory te wijzigen.
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen de mappen te wijzigen.
VAN TOEPASSING OP: Azure Machine Learning SDK v1 voor Python
Azure Machine Learning SDK v1 voor Python
Belangrijk
Dit artikel biedt informatie over het gebruik van de Azure Machine Learning SDK v1. SDK v1 is vanaf 31 maart 2025 afgeschaft. Ondersteuning voor het zal eindigen op 30 juni 2026. U kunt SDK v1 tot die datum installeren en gebruiken. Uw bestaande werkstromen met SDK v1 blijven werken na de einddatum van de ondersteuning. Ze kunnen echter worden blootgesteld aan beveiligingsrisico's of incompatibiliteit door wijzigingen in de architectuur van het product.
We raden aan dat u overstapt naar SDK v2 vóór 30 juni 2026. Zie Wat is Azure Machine Learning CLI en Python SDK v2? en de SDK v2-verwijzing voor meer informatie over SDK v2.
In dit artikel leert u hoe u een regressiemodel traint met de Azure Machine Learning Python SDK met behulp van Azure Machine Learning Automated ML. Het regressiemodel voorspelt passagierstarieven voor taxi's die in New York City (NYC) werken. U schrijft code met de Python SDK om een werkruimte met voorbereide gegevens te configureren, het model lokaal te trainen met aangepaste parameters en de resultaten te verkennen.
Het proces accepteert trainingsgegevens en configuratie-instellingen. Het doorloopt automatisch combinaties van verschillende functienormalisatie-/standaardisatiemethoden, modellen en hyperparameterinstellingen om het beste model te bereiken. In het volgende diagram ziet u de processtroom voor de regressiemodeltraining:
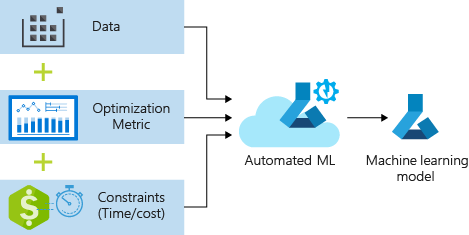
Vereisten
Een Azure-abonnement. U kunt een gratis of betaald account van Azure Machine Learning maken.
Een Azure Machine Learning-werkruimte of rekenproces. Zie quickstart: Aan de slag met Azure Machine Learning om deze resources voor te bereiden.
Haal de voorbereide voorbeeldgegevens voor de zelfstudieoefeningen op door een notebook in uw werkruimte te laden:
Ga naar uw werkruimte in de Azure Machine Learning-studio, selecteer Notitieblokken en selecteer vervolgens het tabblad Voorbeelden.
Vouw in de lijst met notebooks het knooppunt Samples>SDK v1>tutorials>regression-automl-nyc-taxi-data node uit.
Selecteer het notebook regression-automated-ml.ipynb .
Als u elke notebookcel wilt uitvoeren als onderdeel van deze zelfstudie, selecteert u Dit bestand klonen.
Alternatieve benadering: Als u wilt, kunt u de zelfstudieoefeningen uitvoeren in een lokale omgeving. De zelfstudie is beschikbaar in de Azure Machine Learning Notebooks-opslagplaats op GitHub. Volg deze stappen voor deze aanpak om de vereiste pakketten op te halen:
Voer de
pip install azureml-opendatasets azureml-widgetsopdracht uit op uw lokale computer om de vereiste pakketten op te halen.
Gegevens downloaden en voorbereiden
Het pakket Open Datasets bevat een klasse die elke gegevensbron (zoals NycTlcGreen) vertegenwoordigt om eenvoudig datumparameters te filteren voordat u deze downloadt.
Met de volgende code worden de benodigde pakketten geïmporteerd:
from azureml.opendatasets import NycTlcGreen
import pandas as pd
from datetime import datetime
from dateutil.relativedelta import relativedelta
De eerste stap is het maken van een dataframe voor de taxigegevens. Wanneer u in een niet-Spark-omgeving werkt, kunt u met het pakket Open Datasets slechts één maand aan gegevens tegelijk downloaden met bepaalde klassen. Deze aanpak helpt het probleem te voorkomen MemoryError dat zich voordoet met grote gegevenssets.
Als u de taxigegevens wilt downloaden, haalt u iteratief één maand per keer op. Voordat u de volgende set gegevens toevoegt aan het green_taxi_df dataframe, neemt u willekeurig 2000 records uit elke maand en bekijkt u vervolgens een voorbeeld van de gegevens. Deze aanpak helpt bij het voorkomen van bloating van het dataframe.
De volgende code maakt het dataframe, haalt de gegevens op en laadt deze in het dataframe:
green_taxi_df = pd.DataFrame([])
start = datetime.strptime("1/1/2015","%m/%d/%Y")
end = datetime.strptime("1/31/2015","%m/%d/%Y")
for sample_month in range(12):
temp_df_green = NycTlcGreen(start + relativedelta(months=sample_month), end + relativedelta(months=sample_month)) \
.to_pandas_dataframe()
green_taxi_df = green_taxi_df.append(temp_df_green.sample(2000))
green_taxi_df.head(10)
In de volgende tabel ziet u de vele kolommen met waarden in de voorbeeld taxigegevens:
| verkoper-ID | lpepPickupDatetime | lpepDropoffDatetime | aantal passagiers | reisafstand | puLocationId | doLocationId | pickupLongitude | pickupLatitude | afleveringslengtegraad | ... | betalingsType | tariefbedrag | extra | mtaTax | verbetertoeslag | fooibedrag | tolgeldenbedrag | ehailFee | totaalbedrag | tripType |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 2 | 2015-01-30 18:38:09 | 2015-01-30 19:01:49 | 1 | 1,88 | Geen | Geen | -73.996155 | 40.690903 | -73.964287 | ... | 1 | 15,0 | 1.0 | 0,5 | 0,3 | 4,00 | 0,0 | Geen | 20.80 | 1.0 |
| 1 | 2015-01-17 23:21:39 | 2015-01-17 23:35:16 | 1 | 2.70 | Geen | Geen | -73.978508 | 40.687984 | -73.955116 | ... | 1 | 11.5 | 0,5 | 0,5 | 0,3 | 2.55 | 0,0 | Geen | 15.35 | 1.0 |
| 2 | 2015-01-16 01:38:40 | 2015-01-16 01:52:55 | 1 | 3,54 | Geen | Geen | -73.957787 | 40.721779 | -73.963005 | ... | 1 | 13.5 | 0,5 | 0,5 | 0,3 | 2,80 | 0,0 | Geen | 17,60 | 1.0 |
| 2 | 2015-01-04 17:09:26 | 2015-01-04 17:16:12 | 1 | 1,00 | Geen | Geen | -73.919914 | 40.826023 | -73.904839 | ... | 2 | 6.5 | 0,0 | 0,5 | 0,3 | 0,00 | 0,0 | Geen | 7.30 | 1.0 |
| 1 | 2015-01-14 10:10:57 | 2015-01-14 10:33:30 | 1 | 5.10 | Geen | Geen | -73.943710 | 40.825439 | -73.982964 | ... | 1 | 18,5 | 0,0 | 0,5 | 0,3 | 3.85 | 0,0 | Geen | 23.15 | 1.0 |
| 2 | 2015-01-19 18:10:41 | 2015-01-19 18:32:20 | 1 | 7.41 | Geen | Geen | -73.940918 | 40.839714 | -73.994339 | ... | 1 | 24,0 | 0,0 | 0,5 | 0,3 | 4,80 | 0,0 | Geen | 29,60 | 1.0 |
| 2 | 2015-01-01 15:44:21 | 2015-01-01 15:50:16 | 1 | 1,03 | Geen | Geen | -73.985718 | 40.685646 | -73.996773 | ... | 1 | 6.5 | 0,0 | 0,5 | 0,3 | 1,30 | 0,0 | Geen | 8.60 | 1.0 |
| 2 | 2015-01-12 08:01:21 | 2015-01-12 08:14:52 | 5 | 2.94 | Geen | Geen | -73.939865 | 40.789822 | -73.952957 | ... | 2 | 12.5 | 0,0 | 0,5 | 0,3 | 0,00 | 0,0 | Geen | 13.30 | 1.0 |
| 1 | 2015-01-16 21:54:26 | 2015-01-16 22:12:39 | 1 | 3,00 | Geen | Geen | -73.957939 | 40.721928 | -73.926247 | ... | 1 | 14.0 | 0,5 | 0,5 | 0,3 | 2.00 | 0,0 | Geen | 17:30 | 1.0 |
| 2 | 2015-01-06 06:34:53 | 2015-01-06 06:44:23 | 1 | 2.31 | Geen | Geen | -73.943825 | 40.810257 | -73.943062 | ... | 1 | 10.0 | 0,0 | 0,5 | 0,3 | 2.00 | 0,0 | Geen | 12,80 | 1.0 |
Het is handig om enkele kolommen te verwijderen die u niet nodig hebt voor training of andere functieopbouw. U kunt bijvoorbeeld de kolom lpepPickupDatetime verwijderen omdat Automated ML automatisch functies op basis van tijd verwerkt.
Met de volgende code worden 14 kolommen uit de voorbeeldgegevens verwijderd:
columns_to_remove = ["lpepDropoffDatetime", "puLocationId", "doLocationId", "extra", "mtaTax",
"improvementSurcharge", "tollsAmount", "ehailFee", "tripType", "rateCodeID",
"storeAndFwdFlag", "paymentType", "fareAmount", "tipAmount"
]
for col in columns_to_remove:
green_taxi_df.pop(col)
green_taxi_df.head(5)
Gegevens opschonen
De volgende stap is het opschonen van de gegevens.
Met de volgende code wordt de describe() functie op het nieuwe dataframe uitgevoerd om samenvattingsstatistieken voor elk veld te produceren:
green_taxi_df.describe()
In de volgende tabel ziet u overzichtsstatistieken voor de resterende velden in de voorbeeldgegevens:
| verkoper-ID | aantal passagiers | reisafstand | pickupLongitude | pickupLatitude | afleveringslengtegraad | dropoffbreedtegraad | totaalbedrag | |
|---|---|---|---|---|---|---|---|---|
| aantal | 24000.00 | 24000.00 | 24000.00 | 24000.00 | 24000.00 | 24000.00 | 24000.00 | 24000.00 |
| bedoelen | 1.777625 | 1.373625 | 2,893981 | -73.827403 | 40.689730 | -73.819670 | 40.684436 | 14.892744 |
| geslachtsziekte | 0.415850 | 1.046180 | 3.072343 | 2.821767 | 1.556082 | 2,901199 | 1.599776 | 12.339749 |
| Min | 1,00 | 0,00 | 0,00 | -74.357101 | 0,00 | -74.342766 | 0,00 | -120.80 |
| 25% | 2.00 | 1,00 | 1,05 | -73.959175 | 40.699127 | -73.966476 | 40.699459 | 8.00 |
| 50% | 2.00 | 1,00 | 1.93 | -73.945049 | 40.746754 | -73.944221 | 40.747536 | 11,30 |
| 75% | 2.00 | 1,00 | 3,70 | -73.917089 | 40.803060 | -73.909061 | 40.791526 | 17,80 |
| max | 2.00 | 8.00 | 154.28 | 0,00 | 41.109089 | 0,00 | 40.982826 | 425.00 |
De samenvattingsstatistieken geven verschillende velden weer die uitbijters zijn. Dit zijn waarden die de nauwkeurigheid van het model verminderen. U kunt dit probleem oplossen door de velden breedtegraad/lengtegraad (breedtegraad/lengtegraad) te filteren, zodat de waarden binnen de grenzen van het gebied Manhattan vallen. Deze aanpak filtert langere taxiritten of ritten die uitbijters zijn met betrekking tot hun relatie met andere functies.
Filter vervolgens het tripDistance veld op waarden die groter zijn dan nul, maar minder dan 31 mijl (de haversinusafstand tussen de twee lat/lange paren). Deze techniek elimineert lange uitbijters die inconsistente reiskosten hebben.
Ten slotte heeft het totalAmount veld negatieve waarden voor de taxitarieven, wat niet zinvol is in de context van het model. Het passengerCount veld bevat ook ongeldige gegevens waarbij de minimumwaarde nul is.
Met de volgende code worden deze waardeafwijkingen gefilterd met behulp van queryfuncties. De code verwijdert vervolgens de laatste paar kolommen die niet nodig zijn voor training:
final_df = green_taxi_df.query("pickupLatitude>=40.53 and pickupLatitude<=40.88")
final_df = final_df.query("pickupLongitude>=-74.09 and pickupLongitude<=-73.72")
final_df = final_df.query("tripDistance>=0.25 and tripDistance<31")
final_df = final_df.query("passengerCount>0 and totalAmount>0")
columns_to_remove_for_training = ["pickupLongitude", "pickupLatitude", "dropoffLongitude", "dropoffLatitude"]
for col in columns_to_remove_for_training:
final_df.pop(col)
De laatste stap in deze volgorde is om de describe() functie opnieuw aan te roepen op de gegevens om ervoor te zorgen dat de opschoning werkt zoals verwacht. U hebt nu een voorbereide en opgeschoonde set taxi-, vakantie- en weergegevens die u kunt gebruiken voor machine learning-modeltraining:
final_df.describe()
Werkruimte configureren
Maak een werkruimte-object van de bestaande werkruimte. Een Werkruimte is een klasse die uw Azure-abonnement en resourcegegevens accepteert. Hier wordt ook een cloudresource gemaakt om de uitvoeringen van uw model te controleren en bij te houden.
Met de volgende code wordt de functie aangeroepen om het Workspace.from_config() te lezen en de verificatiegegevens in een object met de naam wste laden.
from azureml.core.workspace import Workspace
ws = Workspace.from_config()
Het ws object wordt in de rest van de code in deze zelfstudie gebruikt.
Gegevens splitsen in sets voor trainen en voor testen
Splits de gegevens in trainings- en testsets met behulp van de train_test_split functie in de scikit-learn-bibliotheek . Met deze functie worden de gegevens verdeeld in de gegevensset x (kenmerken) voor het trainen van het model, en de gegevensset y (te voorspellen waarden) voor testen.
Met de parameter test_size wordt het percentage gegevens bepaald dat moet worden toegewezen aan testen. Met de parameter random_state wordt de willekeurige generator ingesteld, zodat de verdeling tussen trainen en testen deterministisch is.
Met de volgende code wordt de train_test_split functie aangeroepen om de x- en y-gegevenssets te laden:
from sklearn.model_selection import train_test_split
x_train, x_test = train_test_split(final_df, test_size=0.2, random_state=223)
Het doel van deze stap is het voorbereiden van gegevenspunten om het voltooide model te testen dat niet wordt gebruikt om het model te trainen. Deze punten worden gebruikt om de werkelijke nauwkeurigheid te meten. Een goed getraind model is een model dat nauwkeurige voorspellingen kan doen op basis van ongelezen gegevens. U hebt nu gegevens voorbereid voor het automatisch trainen van een machine learning-model.
Model automatisch trainen
Als u automatisch een model wilt trainen, voert u de volgende stappen uit:
Definieer de instellingen voor het uitvoeren van het experiment. Koppel uw trainingsgegevens aan de configuratie en wijzig de instellingen voor het trainingsproces.
Verzend het experiment om het model af te stemmen. Nadat u het experiment hebt verzonden, doorloopt het proces verschillende machine learning-algoritmen en hyperparameterinstellingen, die voldoen aan uw gedefinieerde beperkingen. Het optimale model worden gekozen door een metrische nauwkeurigheidswaarde te optimaliseren.
Trainingsinstellingen definiëren
Definieer de experimentparameter en modelinstellingen voor training. Bekijk de volledige lijst met instellingen. Het verzenden van het experiment met deze standaardinstellingen duurt ongeveer 5-20 minuten. Als u de uitvoeringstijd wilt verlagen, vermindert u de experiment_timeout_hours parameter.
| Eigenschappen | Waarde in deze zelfstudie | Beschrijving |
|---|---|---|
iteration_timeout_minutes |
10 | Tijdslimiet in minuten voor elke iteratie. Verhoog deze waarde voor grotere gegevenssets die meer tijd nodig hebben voor elke iteratie. |
experiment_timeout_hours |
0,3 | Maximale tijdsduur in uren dat de combinatie van alle iteraties voordat het experiment wordt beëindigd, kan duren. |
enable_early_stopping |
Waar | Vlag om vroegtijdige beëindiging in te schakelen als de score op korte termijn niet wordt verbeterd. |
primary_metric |
speermaancorrelatie | De metrische gegevens die u wilt optimaliseren. Het best passende model wordt gekozen op basis van deze metrische waarde. |
featurization |
Auto | Met de automatische waarde kan het experiment de invoergegevens vooraf verwerken, waaronder het verwerken van ontbrekende gegevens, het converteren van tekst naar numeriek, enzovoort. |
verbosity |
logging.INFO | Hiermee bepaalt u het niveau van logboekregistratie. |
n_cross_validations |
5 | Aantal kruisvalidatiesplitsingen dat moet worden uitgevoerd wanneer er geen validatiegegevens zijn opgegeven. |
Met de volgende code wordt het experiment verzonden:
import logging
automl_settings = {
"iteration_timeout_minutes": 10,
"experiment_timeout_hours": 0.3,
"enable_early_stopping": True,
"primary_metric": 'spearman_correlation',
"featurization": 'auto',
"verbosity": logging.INFO,
"n_cross_validations": 5
}
Met de volgende code kunt u uw gedefinieerde trainingsinstellingen gebruiken als parameter **kwargs voor een AutoMLConfig object. Daarnaast geeft u uw trainingsgegevens en het type model op, wat in dit geval het geval is regression .
from azureml.train.automl import AutoMLConfig
automl_config = AutoMLConfig(task='regression',
debug_log='automated_ml_errors.log',
training_data=x_train,
label_column_name="totalAmount",
**automl_settings)
Notitie
Geautomatiseerde voorverwerkingsstappen van ML (functienormalisatie, verwerking van ontbrekende gegevens, het converteren van tekst naar numeriek, enzovoort) worden onderdeel van het onderliggende model. Wanneer u het model gebruikt voor voorspellingen, worden dezelfde voorverwerkingsstappen die tijdens de training worden toegepast, automatisch toegepast op uw invoergegevens.
Automatisch regressiemodel trainen
Maak een experimentobject in uw werkruimte. Een experiment fungeert als een container voor uw afzonderlijke taken. Geef het gedefinieerde automl_config object door aan het experiment en stel de uitvoer in op True om de voortgang tijdens de taak weer te geven.
Nadat u het experiment hebt gestart, worden de weergegeven uitvoerupdates live bijgewerkt terwijl het experiment wordt uitgevoerd. Voor elke iteratie ziet u het modeltype, de uitvoeringsduur en de nauwkeurigheid van de training. In het veld BEST wordt de best uitgevoerde trainingsscore bijgehouden op basis van uw metrische gegevenstype:
from azureml.core.experiment import Experiment
experiment = Experiment(ws, "Tutorial-NYCTaxi")
local_run = experiment.submit(automl_config, show_output=True)
Dit is de uitvoer:
Running on local machine
Parent Run ID: AutoML_1766cdf7-56cf-4b28-a340-c4aeee15b12b
Current status: DatasetFeaturization. Beginning to featurize the dataset.
Current status: DatasetEvaluation. Gathering dataset statistics.
Current status: FeaturesGeneration. Generating features for the dataset.
Current status: DatasetFeaturizationCompleted. Completed featurizing the dataset.
Current status: DatasetCrossValidationSplit. Generating individually featurized CV splits.
Current status: ModelSelection. Beginning model selection.
****************************************************************************************************
ITERATION: The iteration being evaluated.
PIPELINE: A summary description of the pipeline being evaluated.
DURATION: Time taken for the current iteration.
METRIC: The result of computing score on the fitted pipeline.
BEST: The best observed score thus far.
****************************************************************************************************
ITERATION PIPELINE DURATION METRIC BEST
0 StandardScalerWrapper RandomForest 0:00:16 0.8746 0.8746
1 MinMaxScaler RandomForest 0:00:15 0.9468 0.9468
2 StandardScalerWrapper ExtremeRandomTrees 0:00:09 0.9303 0.9468
3 StandardScalerWrapper LightGBM 0:00:10 0.9424 0.9468
4 RobustScaler DecisionTree 0:00:09 0.9449 0.9468
5 StandardScalerWrapper LassoLars 0:00:09 0.9440 0.9468
6 StandardScalerWrapper LightGBM 0:00:10 0.9282 0.9468
7 StandardScalerWrapper RandomForest 0:00:12 0.8946 0.9468
8 StandardScalerWrapper LassoLars 0:00:16 0.9439 0.9468
9 MinMaxScaler ExtremeRandomTrees 0:00:35 0.9199 0.9468
10 RobustScaler ExtremeRandomTrees 0:00:19 0.9411 0.9468
11 StandardScalerWrapper ExtremeRandomTrees 0:00:13 0.9077 0.9468
12 StandardScalerWrapper LassoLars 0:00:15 0.9433 0.9468
13 MinMaxScaler ExtremeRandomTrees 0:00:14 0.9186 0.9468
14 RobustScaler RandomForest 0:00:10 0.8810 0.9468
15 StandardScalerWrapper LassoLars 0:00:55 0.9433 0.9468
16 StandardScalerWrapper ExtremeRandomTrees 0:00:13 0.9026 0.9468
17 StandardScalerWrapper RandomForest 0:00:13 0.9140 0.9468
18 VotingEnsemble 0:00:23 0.9471 0.9471
19 StackEnsemble 0:00:27 0.9463 0.9471
Resultaten verkennen
Bekijk de resultaten van de automatische training met een Jupyter-widget. Met de widget kunt u een grafiek en tabel van alle afzonderlijke taakiteraties bekijken, samen met metrische gegevens en metagegevens voor de nauwkeurigheid van de training. Daarnaast kunt u met behulp van de vervolgkeuzelijst filteren op andere metrische nauwkeurigheidsgegevens dan de eerste metrische gegevens.
De volgende code produceert een grafiek om de resultaten te verkennen:
from azureml.widgets import RunDetails
RunDetails(local_run).show()
De uitvoeringsdetails voor de Jupyter-widget:

Het grafiekdiagram voor de Jupyter-widget:

Beste model ophalen
Met de volgende code kunt u het beste model selecteren in uw iteraties. De methode get_output retourneert de beste uitvoering en het aangepaste model voor de laatste aangepaste aanroep. Door de overbelasting van de get_output functie te gebruiken, kunt u de beste uitvoering en aangepast model ophalen voor alle vastgelegde metrische gegevens of een bepaalde iteratie.
best_run, fitted_model = local_run.get_output()
print(best_run)
print(fitted_model)
De beste modelnauwkeurigheid testen
Gebruik het beste model om voorspellingen uit te voeren op de testgegevensset om taxitarieven te voorspellen. De predict functie maakt gebruik van het beste model en voorspelt de waarden van y, reiskosten, uit de x_test gegevensset.
Met de volgende code worden de eerste tien voorspelde kostenwaarden uit de y_predict gegevensset afgedrukt:
y_test = x_test.pop("totalAmount")
y_predict = fitted_model.predict(x_test)
print(y_predict[:10])
Bereken de root mean squared error van de resultaten. Converteer het y_test dataframe naar een lijst en vergelijk met de voorspelde waarden. De mean_squared_error functie gebruikt twee matrices met waarden en berekent de gemiddelde kwadratische fout ertussen. De vierkantswortel van het resultaat veroorzaakt een fout in dezelfde eenheden als de variabele y (kosten). Deze waarde geeft aan in welke mate de voorspelde taxitarieven ongeveer afwijken van de werkelijke tarieven.
from sklearn.metrics import mean_squared_error
from math import sqrt
y_actual = y_test.values.flatten().tolist()
rmse = sqrt(mean_squared_error(y_actual, y_predict))
rmse
Voer de volgende code uit om MAPE (het gemiddelde absolute foutpercentage) te berekenen met behulp van de volledige gegevenssets y_actual en y_predict. Met deze statistiek wordt een absoluut verschil tussen elke voorspelde en werkelijke waarde berekent en worden alle verschillen opgeteld. Vervolgens wordt die som weergegeven als een percentage van het totaal van de werkelijke waarden.
sum_actuals = sum_errors = 0
for actual_val, predict_val in zip(y_actual, y_predict):
abs_error = actual_val - predict_val
if abs_error < 0:
abs_error = abs_error * -1
sum_errors = sum_errors + abs_error
sum_actuals = sum_actuals + actual_val
mean_abs_percent_error = sum_errors / sum_actuals
print("Model MAPE:")
print(mean_abs_percent_error)
print()
print("Model Accuracy:")
print(1 - mean_abs_percent_error)
Dit is de uitvoer:
Model MAPE:
0.14353867606052823
Model Accuracy:
0.8564613239394718
In de twee metrische nauwkeurigheidsgegevens van de voorspellingen kunt u zien dat het model redelijk goed is in het voorspellen van taxitarieven op basis van de functies van de gegevensset; gewoonlijk $4,00 te veel of te weinig en een foutmarge van circa 15%.
Het traditionele proces voor het ontwikkelen van machine learning-modellen is zeer resource-intensief. Het vereist aanzienlijke domeinkennis en tijdsinvesteringen om de resultaten van tientallen modellen uit te voeren en te vergelijken. Geautomatiseerde machine learning is een uitstekende manier om in korte tijd veel verschillende modellen voor uw scenario te testen.
Resources opschonen
Als u niet van plan bent om te werken aan andere Azure Machine Learning-zelfstudies, voert u de volgende stappen uit om de resources te verwijderen die u niet meer nodig hebt.
Rekenproces stoppen
Als u een rekenproces hebt gebruikt, kunt u de virtuele machine stoppen wanneer u deze niet gebruikt en uw kosten verlagen:
Ga naar uw werkruimte in de Azure Machine Learning-studio en selecteer Compute.
Selecteer in de lijst het rekenproces dat u wilt stoppen en selecteer vervolgens Stoppen.
Wanneer u klaar bent om de berekening opnieuw te gebruiken, kunt u de virtuele machine opnieuw opstarten.
Andere resources verwijderen
Als u niet van plan bent om de resources te gebruiken die u in deze zelfstudie hebt gemaakt, kunt u ze verwijderen en verdere kosten voorkomen.
Volg deze stappen om de resourcegroep en alle resources te verwijderen:
Ga in Azure Portal naar Resourcegroepen.
Selecteer in de lijst de resourcegroep die u in deze zelfstudie hebt gemaakt en selecteer vervolgens Resourcegroep verwijderen.
Voer bij de bevestigingsprompt de naam van de resourcegroep in en selecteer vervolgens Verwijderen.
Als u de resourcegroep wilt behouden en alleen één werkruimte wilt verwijderen, voert u de volgende stappen uit:
Ga in Azure Portal naar de resourcegroep die de werkruimte bevat die u wilt verwijderen.
Selecteer de werkruimte, selecteer Eigenschappen en selecteer vervolgens Verwijderen.