Zelfstudie: Designer: een machine learning-model implementeren
Gebruik de ontwerpfunctie om een machine learning-model te implementeren om de prijs van auto's te voorspellen. Deze zelfstudie is deel 2 van een tweedelige reeks.
Notitie
Designer ondersteunt twee typen onderdelen: klassieke vooraf samengestelde onderdelen (v1) en aangepaste onderdelen (v2). Deze twee typen onderdelen zijn NIET compatibel.
Klassieke vooraf samengestelde onderdelen bieden vooraf gebouwde onderdelen voor het grootste gedeelte voor gegevensverwerking en traditionele machine learning-taken, zoals regressie en classificatie. Dit type onderdeel wordt nog steeds ondersteund, maar er worden geen nieuwe onderdelen toegevoegd.
Met aangepaste onderdelen kunt u uw eigen code als onderdeel verpakken. Het ondersteunt het delen van onderdelen tussen werkruimten en naadloze creatie in studio-, CLI v2- en SDK v2-interfaces.
Voor nieuwe projecten raden we u ten zeerste aan om een aangepast onderdeel te gebruiken dat compatibel is met AzureML V2 en dat nieuwe updates blijft ontvangen.
Dit artikel is van toepassing op klassieke vooraf gebouwde onderdelen en niet compatibel met CLI v2 en SDK v2.
In deel één van de zelfstudie hebt u een lineair regressiemodel getraind op autoprijzen. In deel twee implementeert u het model om anderen de kans te geven het te gebruiken. In deze zelfstudie gaat u:
- Een realtime deductiepijplijn maken.
- Een deductiecluster maken.
- Het realtime-eindpunt implementeren.
- Het realtime-eindpunt testen.
Vereisten
Voltooi deel 1 van de zelfstudie om te leren hoe u een machine learning-model kunt trainen en een score kunt geven in de ontwerpfunctie.
Belangrijk
Als u grafische elementen die in dit document worden vermeld, zoals knoppen in Studio of Designer, niet ziet, hebt u mogelijk niet het juiste machtigingsniveau voor de werkruimte. Neem contact op met de beheerder van uw Azure-abonnement om te controleren of u het juiste toegangsniveau hebt gekregen. Zie Gebruikers en rollen beherenvoor meer informatie.
Een realtime deductiepijplijn maken
Voor het implementeren van uw pijplijn moet u de trainingspijplijn eerst converteren naar een realtime deductiepijplijn. Tijdens dit proces worden trainingsonderdelen verwijderd en de invoer en uitvoer van webservices toegevoegd voor het afhandelen van aanvragen.
Notitie
Deductiepijplijn maken ondersteunt alleen trainingspijplijnen die alleen de ingebouwde onderdelen van de ontwerpfunctie bevatten en die een onderdeel zoals Train Model moeten hebben dat het getrainde model uitvoert.
Een realtime deductiepijplijn maken
Selecteer op de detailpagina van de pijplijntaak boven het pijplijncanvas de optie Deductiepijplijn> inrealtime deductiepijplijn maken.
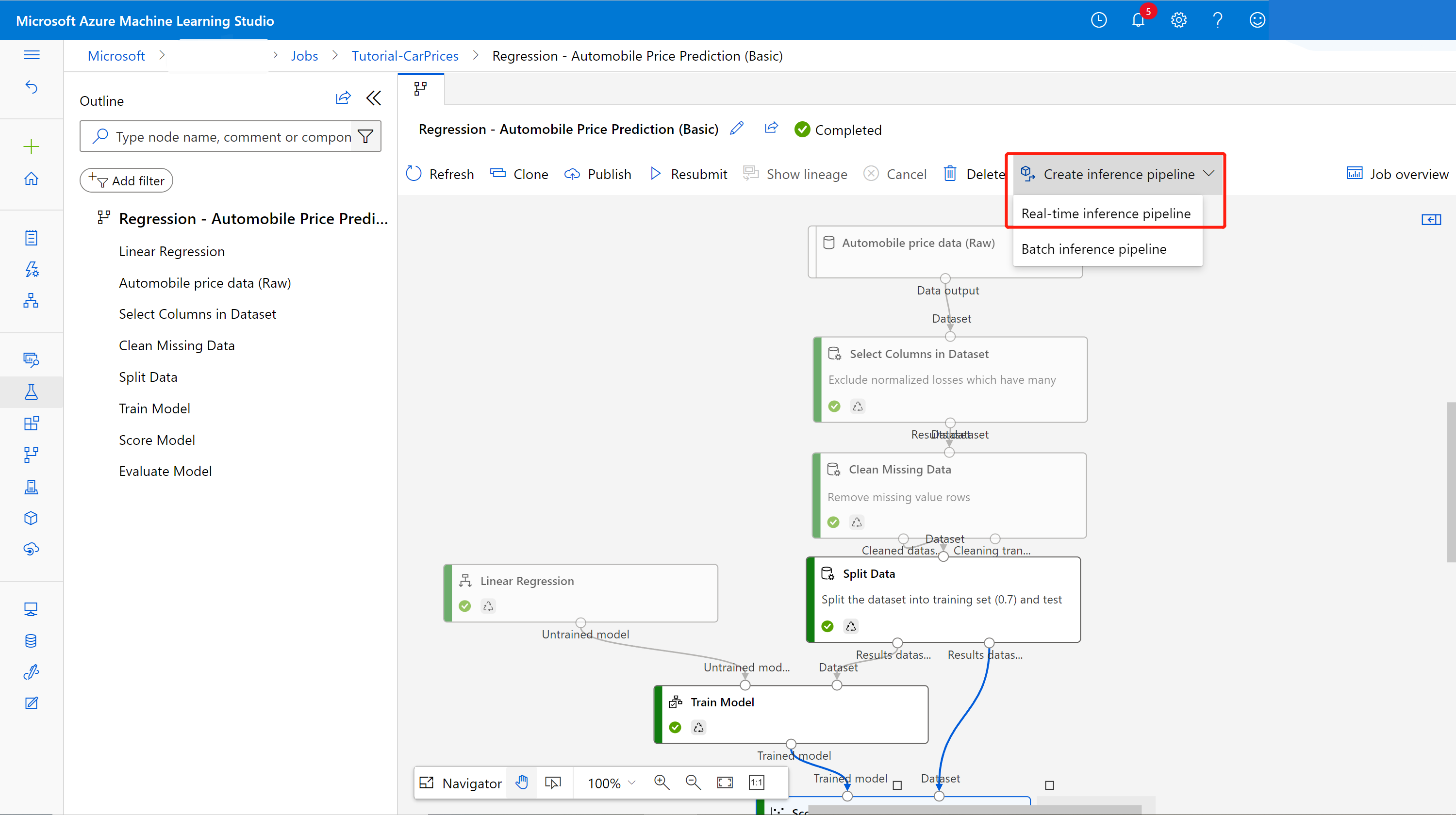
Uw nieuwe pijplijn ziet er nu als volgt uit:
Wanneer u Deductiepijplijn maken selecteert, gebeuren er verschillende dingen:
- Het getrainde model wordt opgeslagen als een gegevenssetonderdeel in het onderdelenpalet. U vindt deze onder Mijn gegevenssets.
- Trainingsonderdelen zoals Train Model en Split Data worden verwijderd.
- Het opgeslagen getrainde model wordt weer toegevoegd aan de pijplijn.
- Onderdelen webserviceinvoer en webservice-uitvoer worden toegevoegd. Deze onderdelen laten zien waar gebruikersgegevens de pijplijn binnenkomen en waar gegevens worden geretourneerd.
Notitie
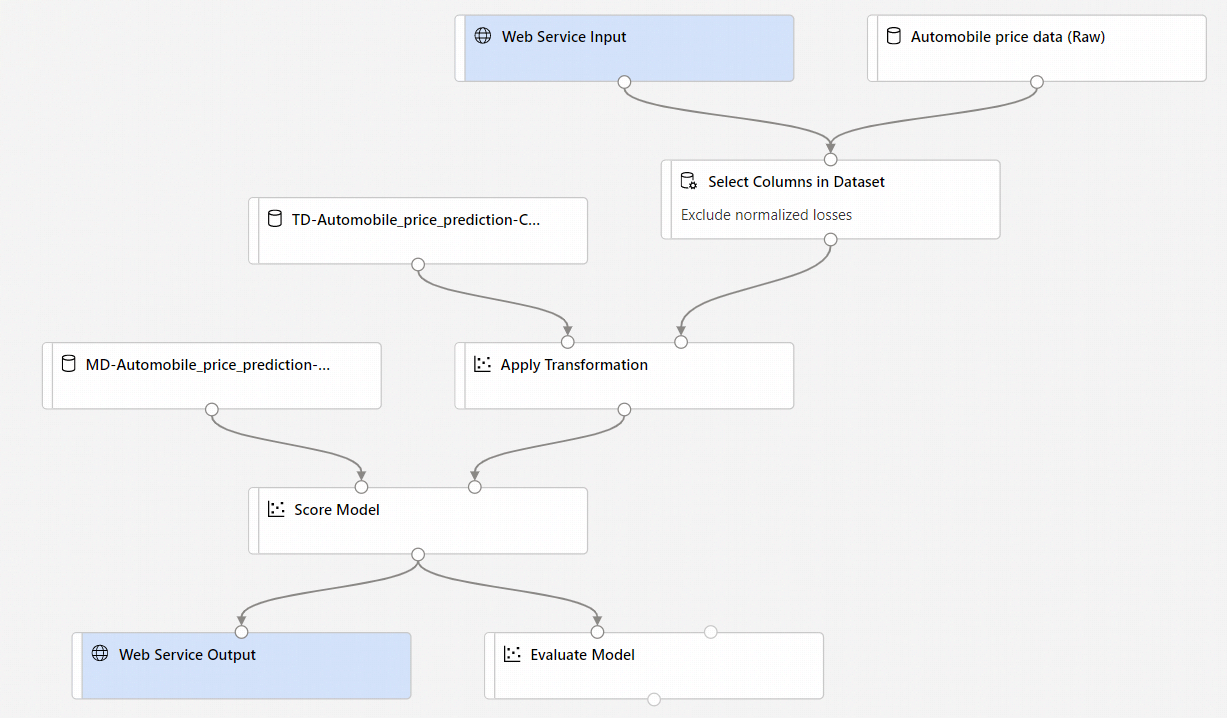
Standaard verwacht de webservice-invoer hetzelfde gegevensschema als de uitvoergegevens van het onderdeel die verbinding maken met dezelfde downstreampoort als deze. In dit voorbeeld maken webserviceinvoer en autoprijsgegevens (Raw) verbinding met hetzelfde downstreamonderdeel. Daarom verwacht WebService-invoer hetzelfde gegevensschema als Autoprijsgegevens (Raw) en is de kolom
pricedoelvariabele opgenomen in het schema. Wanneer u echter de gegevens scoren, weet u meestal niet welke waarden voor de doelvariabele worden gebruikt. In een dergelijk geval kunt u de kolom met doelvariabele in de deductiepijplijn verwijderen met behulp van het onderdeel Kolommen in gegevensset selecteren . Zorg ervoor dat de uitvoer van Kolommen selecteren in gegevensset verwijderen van de kolom doelvariabele is verbonden met dezelfde poort als de uitvoer van het onderdeel WebService-invoer .Selecteer Verzendenen gebruik hetzelfde rekendoel en experiment dat u in deel 1 hebt gebruikt.
Als dit de eerste taak is, kan het tot 20 minuten duren voordat de pijplijn is voltooid. De standaardrekeninstellingen hebben een minimale knooppuntgrootte van 0, wat betekent dat de ontwerpfunctie na inactiviteit resources moet toewijzen. Herhaalde pijplijntaken nemen minder tijd in beslag omdat de rekenresources al zijn toegewezen. Daarnaast gebruikt de ontwerpfunctie resultaten in de cache voor elk onderdeel om de efficiëntie verder te verbeteren.
Ga naar de details van de pijplijntaak voor realtime deductie door de koppeling Taakdetails in het linkerdeelvenster te selecteren.
Selecteer Implementeren op de pagina met taakgegevens.
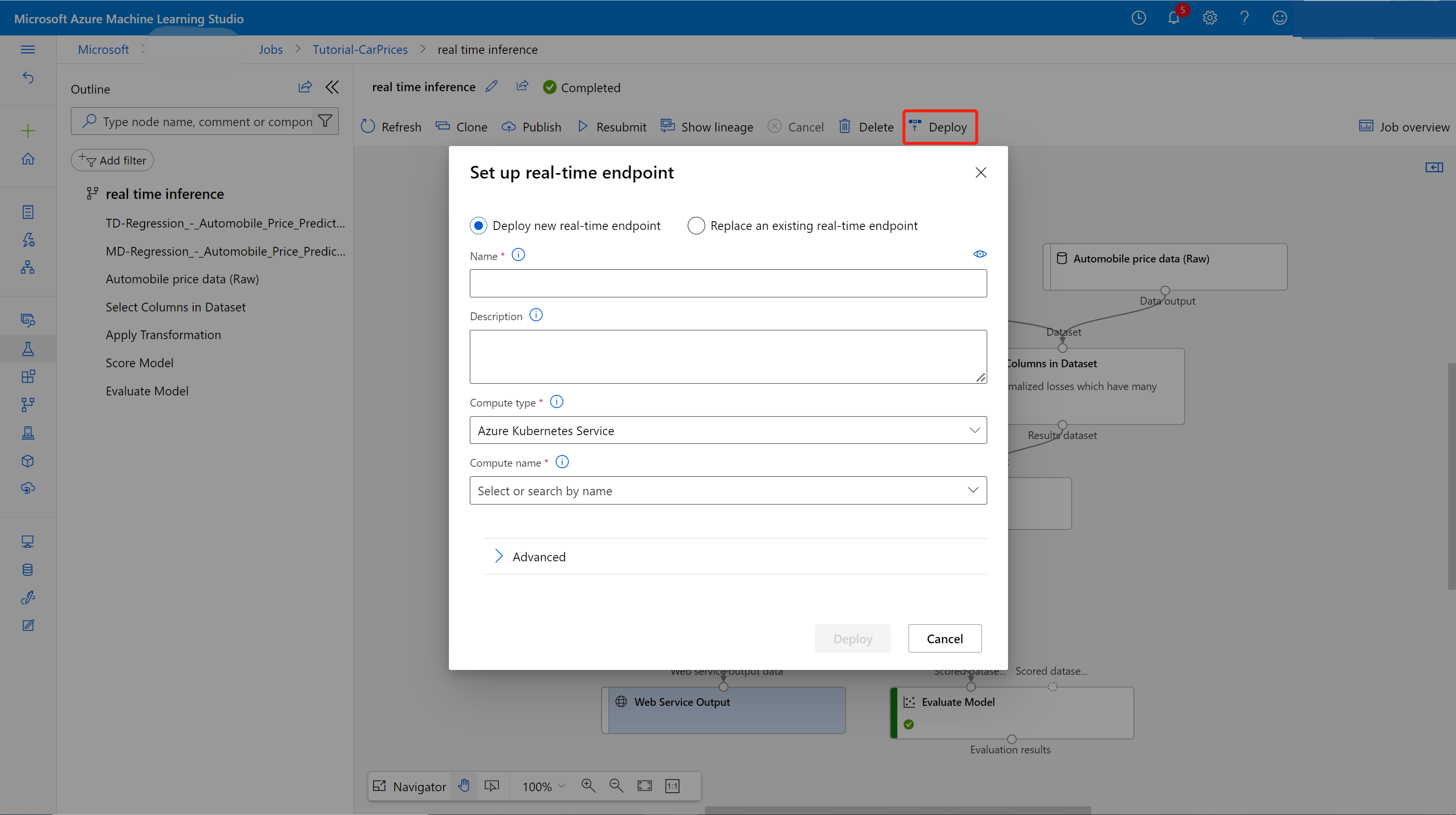
Een deductiecluster maken
In het dialoogvenster dat wordt weergegeven kunt u willekeurige Azure Kubernetes Service (AKS)-clusters selecteren om uw model naar te implementeren. Als u geen AKS-cluster hebt, gebruikt u de volgende stappen om er een te maken.
Selecteer Compute in het dialoogvenster dat wordt weergegeven om naar de pagina Compute te gaan.
Selecteer Deductieclusters>+ Nieuw op het navigatielint.
Configureer een nieuwe Kubernetes Service in het deelvenster Deductiecluster.
Geef aks-compute op als Compute-naam.
Selecteer een regio in de buurt die beschikbaar is voor de Regio.
Selecteer Maken.
Notitie
Het duurt ongeveer 15 minuten om een AKS-service te maken. U kunt de inrichtingsstatus bekijken op de pagina Deductieclusters.
Het realtime-eindpunt implementeren
Wanneer de inrichting van uw AKS-service is voltooid, gaat u terug naar de realtime deductiepijplijn om de implementatie te voltooien.
Selecteer Implementeren boven het canvas.
Selecteer Nieuw realtime-eindpunt implementeren.
Selecteer de AKS-cluster die u hebt gemaakt.
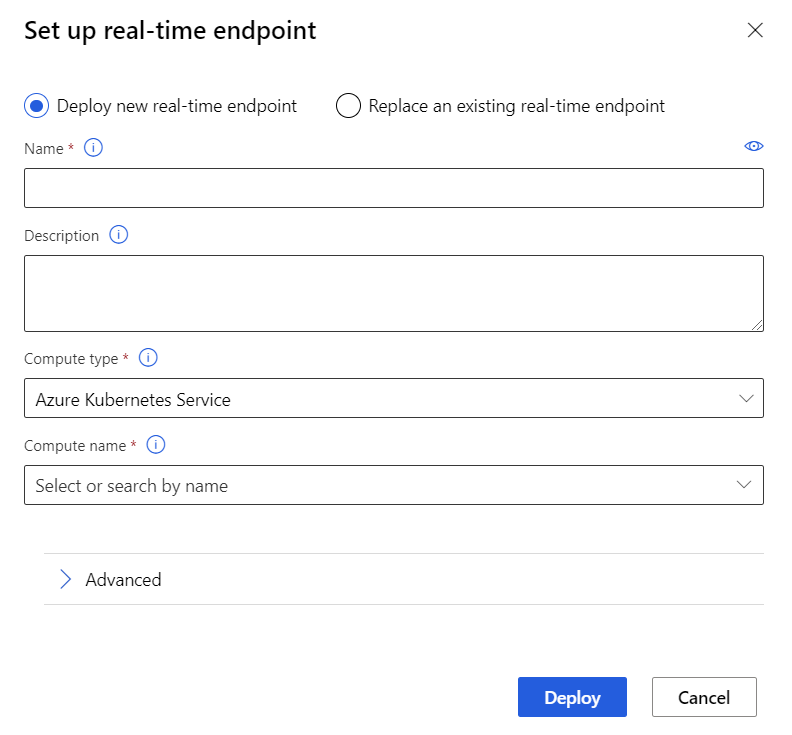
U kunt ook de geavanceerde instelling voor uw realtime-eindpunt wijzigen.
Geavanceerde instelling Beschrijving Diagnostische gegevens en gegevensverzameling van Application Insights inschakelen Of u Azure-toepassing Insights wilt inschakelen om gegevens van de geïmplementeerde eindpunten te verzamelen.
Standaard: false.Time-out voor scoren Een time-out in milliseconden om af te dwingen voor het scoren van aanroepen naar de webservice.
Standaard: 60000.Automatisch schalen ingeschakeld Of automatisch schalen moet worden ingeschakeld voor de webservice.
Standaard: true.Minimale replica's Het minimale aantal containers dat moet worden gebruikt bij het automatisch schalen van deze webservice.
Standaard: 1.Maximum aantal replica's Het maximale aantal containers dat moet worden gebruikt wanneer deze webservice automatisch wordt geschaald.
Standaard: 10.Doelgebruik Het doelgebruik (in procenten van 100) dat de automatische schaalaanpassing moet proberen aan te houden voor deze webservice.
Standaard: 70.Vernieuwingsperiode Hoe vaak (in seconden) de automatische schaalaanpassing deze webservice probeert te schalen.
Standaard: 1.CPU-reservecapaciteit Het aantal CPU-kernen dat moet worden toegewezen voor deze webservice.
Standaard: 0.1.Geheugenreservecapaciteit De hoeveelheid geheugen in GB dat moet worden toegewezen voor deze webservice.
Standaard: 0,5.Selecteer Implementeren.
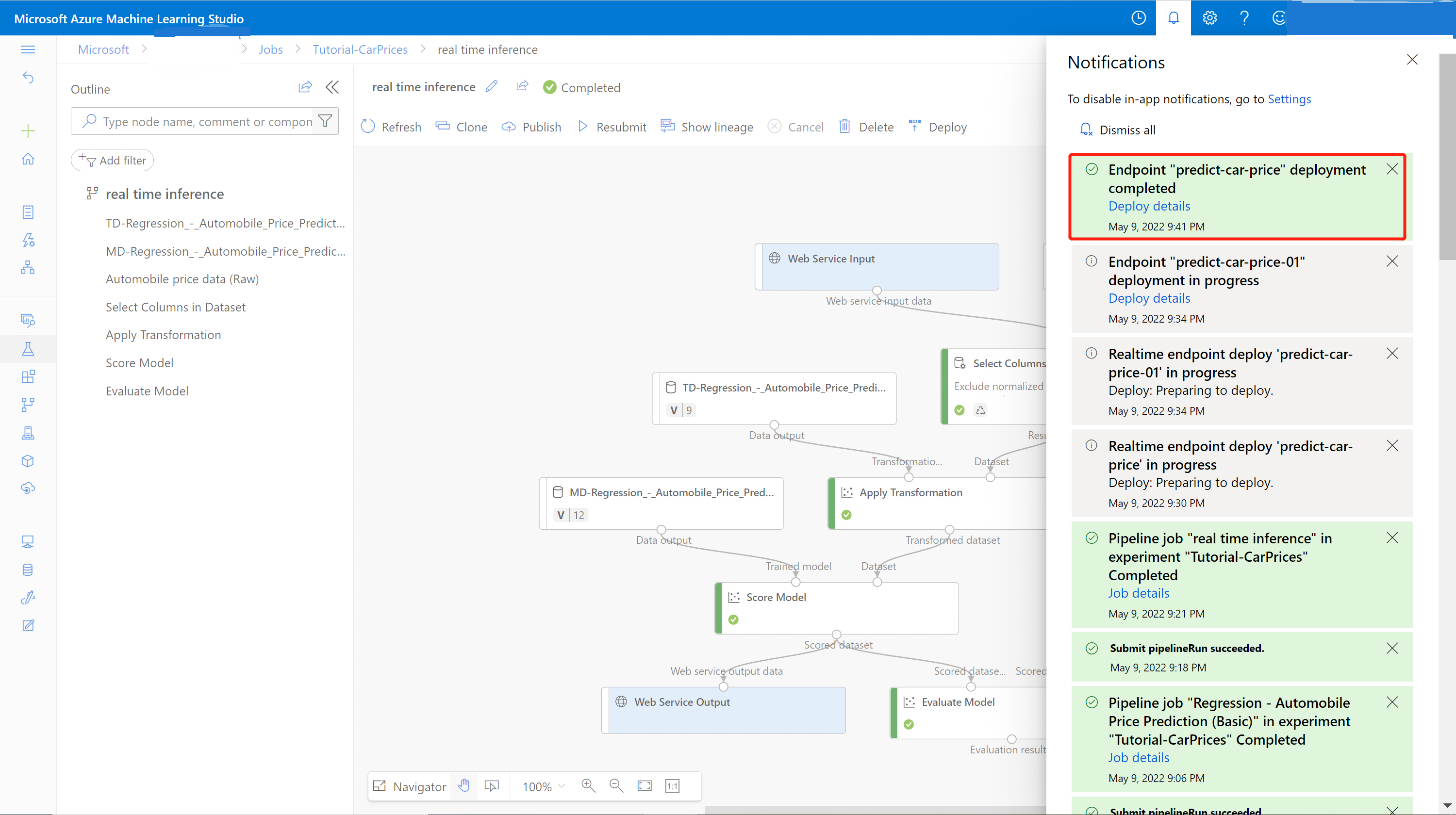
Er wordt een melding weergegeven van het meldingencentrum nadat de implementatie is voltooid. Dit kan enkele minuten duren.
Tip
U kunt ook implementeren naar Azure Container Instance (ACI) als u Azure Container Instance als Rekentype selecteert in het vak realtime eindpuntinstelling. Azure Container Instance wordt gebruikt voor testen of ontwikkelen. Gebruik ACI voor workloads op basis van een lage cpu waarvoor minder dan 48 GB RAM-geheugen is vereist.
Het realtime-eindpunt testen
Nadat de implementatie is voltooid, kunt u uw realtime-eindpunt bekijken door naar de pagina Eindpunten te gaan.
Selecteer op de pagina Eindpunten het eindpunt dat u hebt geïmplementeerd.
Op het tabblad Details ziet u meer informatie, zoals de REST-URI, Swagger-definitie, status en tags.
Op het tabblad Verbruik vindt u voorbeeldverbruikscode, beveiligingssleutels en instellen van verificatiemethoden.
Op het tabblad Implementatielogboeken vindt u de gedetailleerde implementatielogboeken van uw realtime-eindpunt.
Als u uw eindpunt wilt testen, gaat u naar het tabblad Testen . Hier kunt u testgegevens invoeren en Test de uitvoer van uw eindpunt controleren selecteren.
Het realtime-eindpunt bijwerken
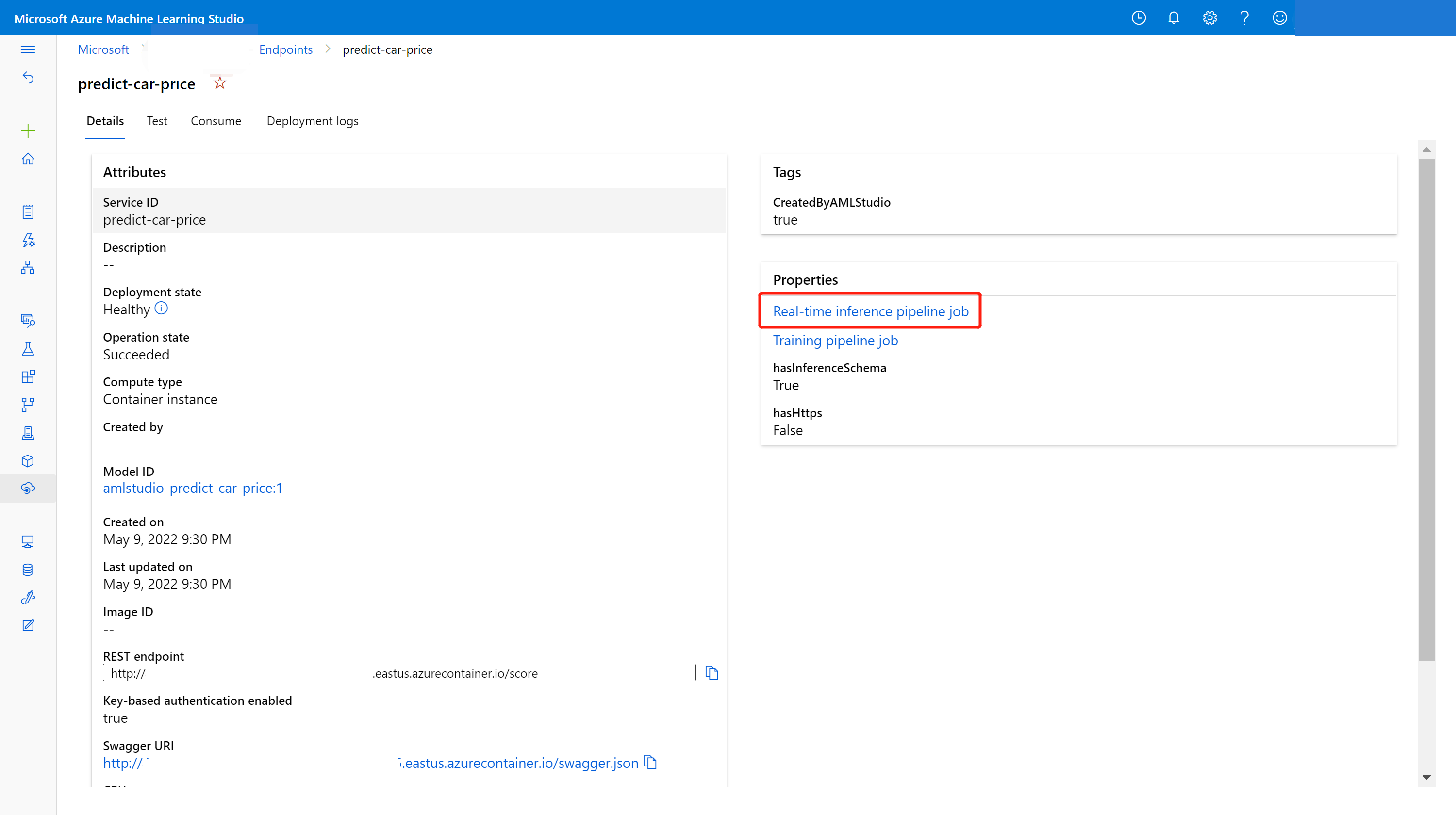
U kunt het online-eindpunt bijwerken met een nieuw model dat is getraind in de ontwerpfunctie. Zoek op de detailpagina van het online-eindpunt uw vorige trainingspijplijntaak en deductiepijplijntaak.
U kunt het concept van de trainingspijplijn rechtstreeks vinden en wijzigen op de startpagina van de ontwerper.
U kunt ook de koppeling voor de trainingspijplijntaak openen en deze vervolgens klonen in een nieuw pijplijnconcept om door te gaan met bewerken.
Nadat u de gewijzigde trainingspijplijn hebt ingediend, gaat u naar de pagina met taakgegevens.
Wanneer de taak is voltooid, klikt u met de rechtermuisknop op Model trainen en selecteert u Gegevens registreren.
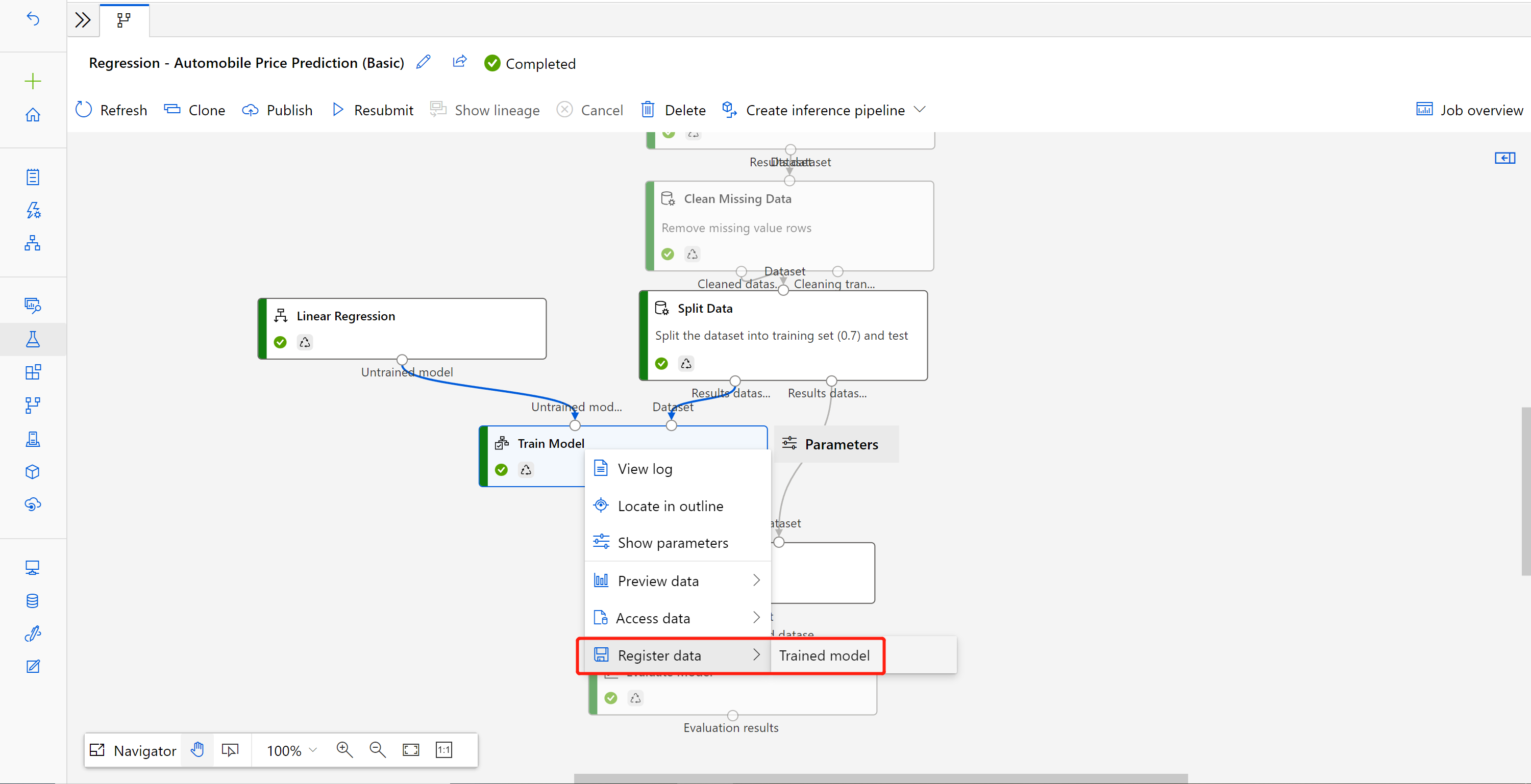
Voer de naam in en selecteer Bestandstype .
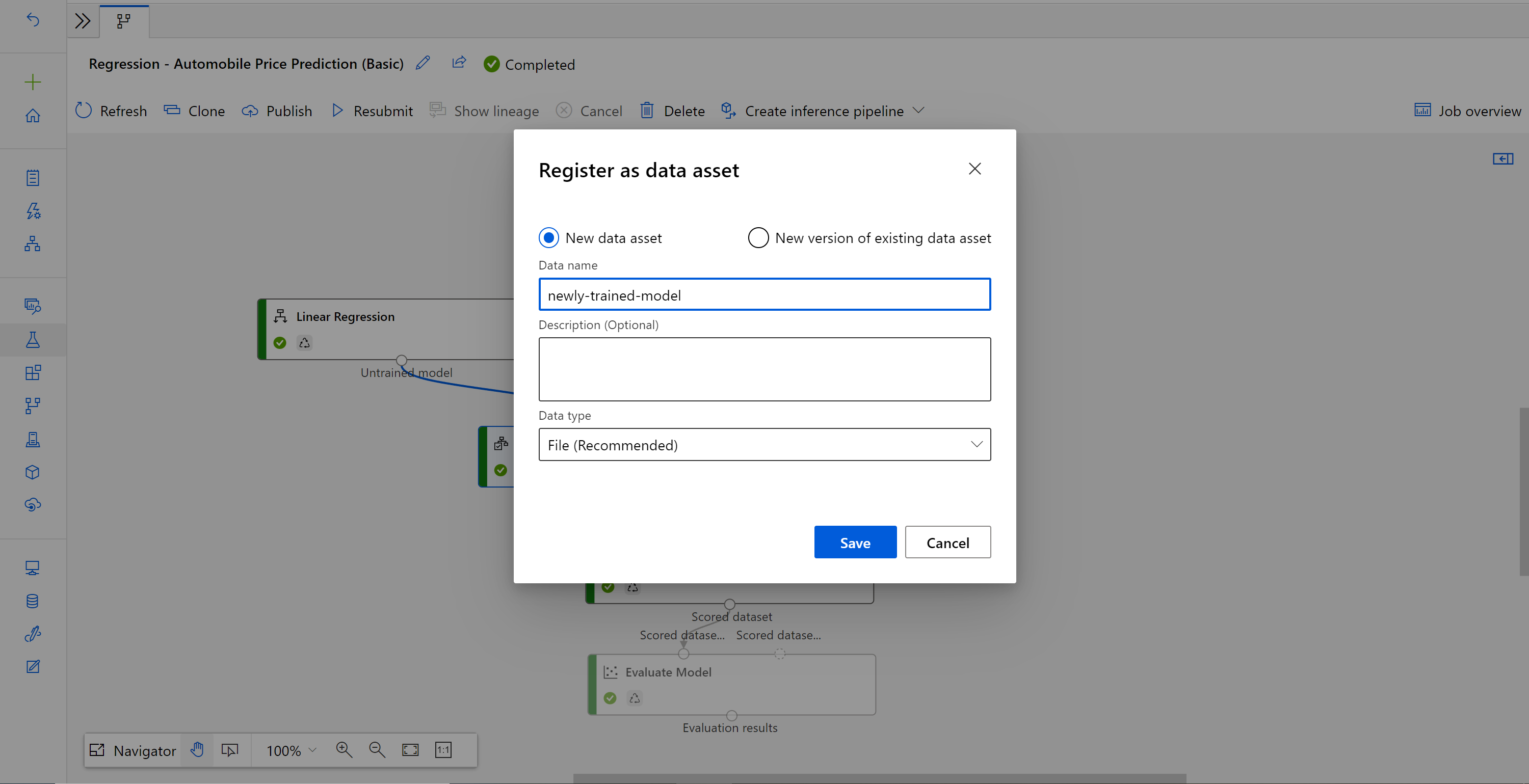
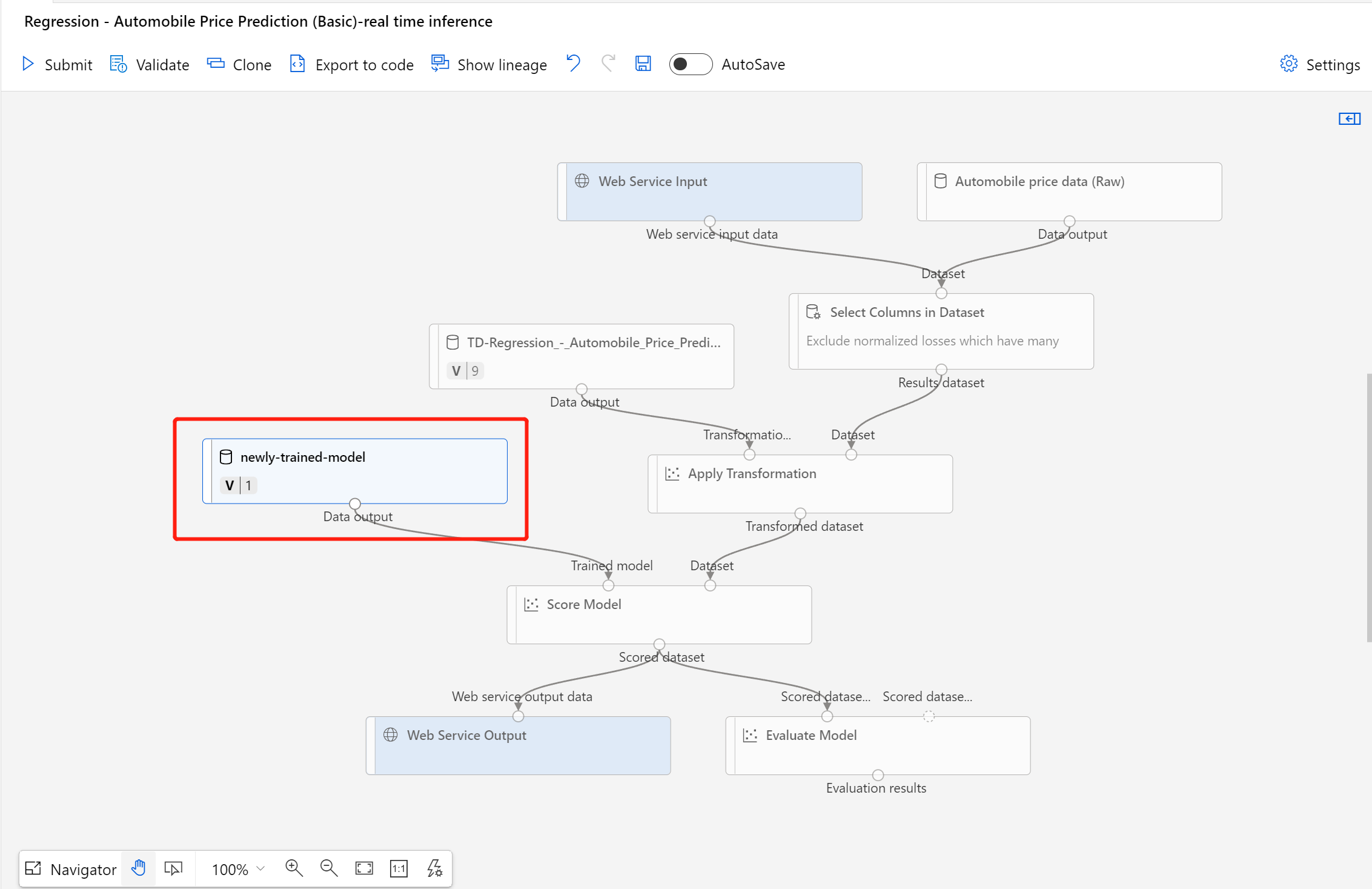
Nadat de gegevensset is geregistreerd, opent u het concept van de deductiepijplijn of kloont u de vorige deductiepijplijntaak naar een nieuw concept. Vervang in het concept van de deductiepijplijn het vorige getrainde model dat wordt weergegeven als het knooppunt MD-XXXX dat is verbonden met het onderdeel Score Model door de zojuist geregistreerde gegevensset.
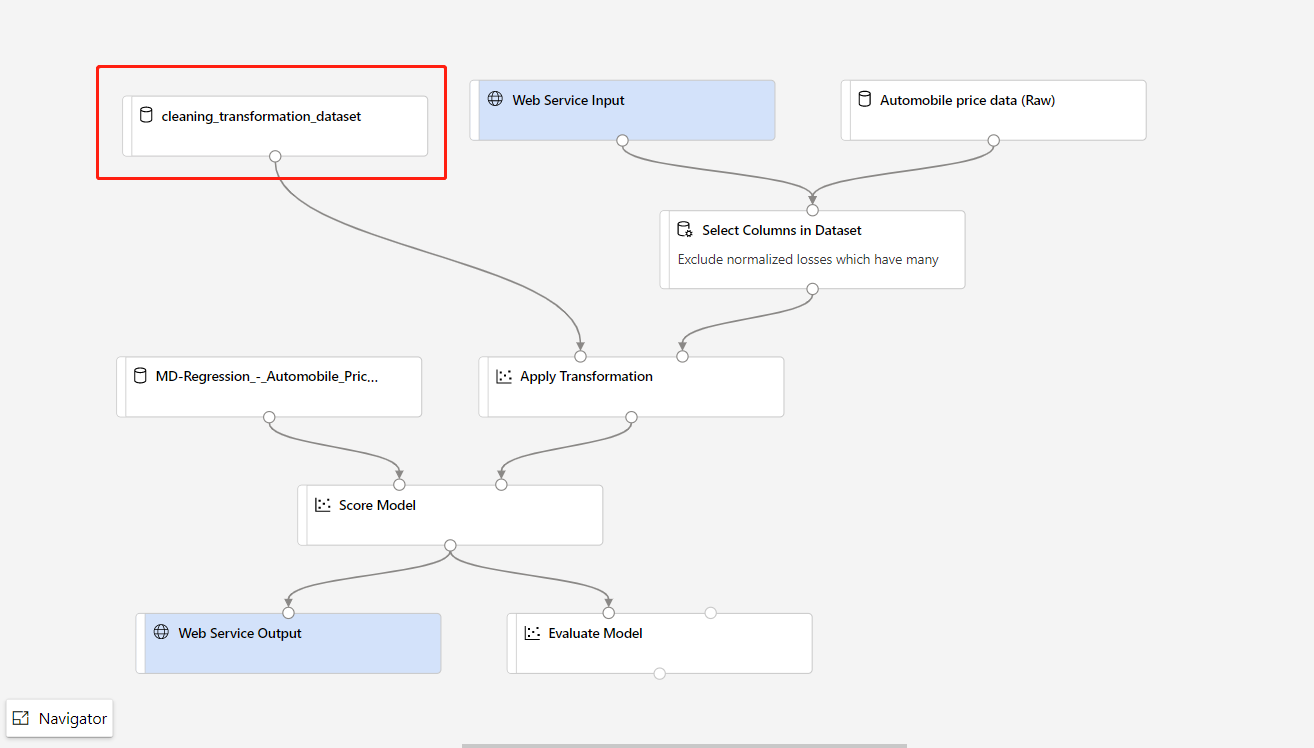
Als u het voorverwerkingsonderdeel voor gegevens in uw trainingspijplijn wilt bijwerken en dit wilt bijwerken naar de deductiepijplijn, is de verwerking vergelijkbaar met de bovenstaande stappen.
U hoeft alleen de transformatie-uitvoer van het transformatieonderdeel te registreren als gegevensset.
Vervang vervolgens handmatig de TD-component in deductiepijplijn door de geregistreerde gegevensset.
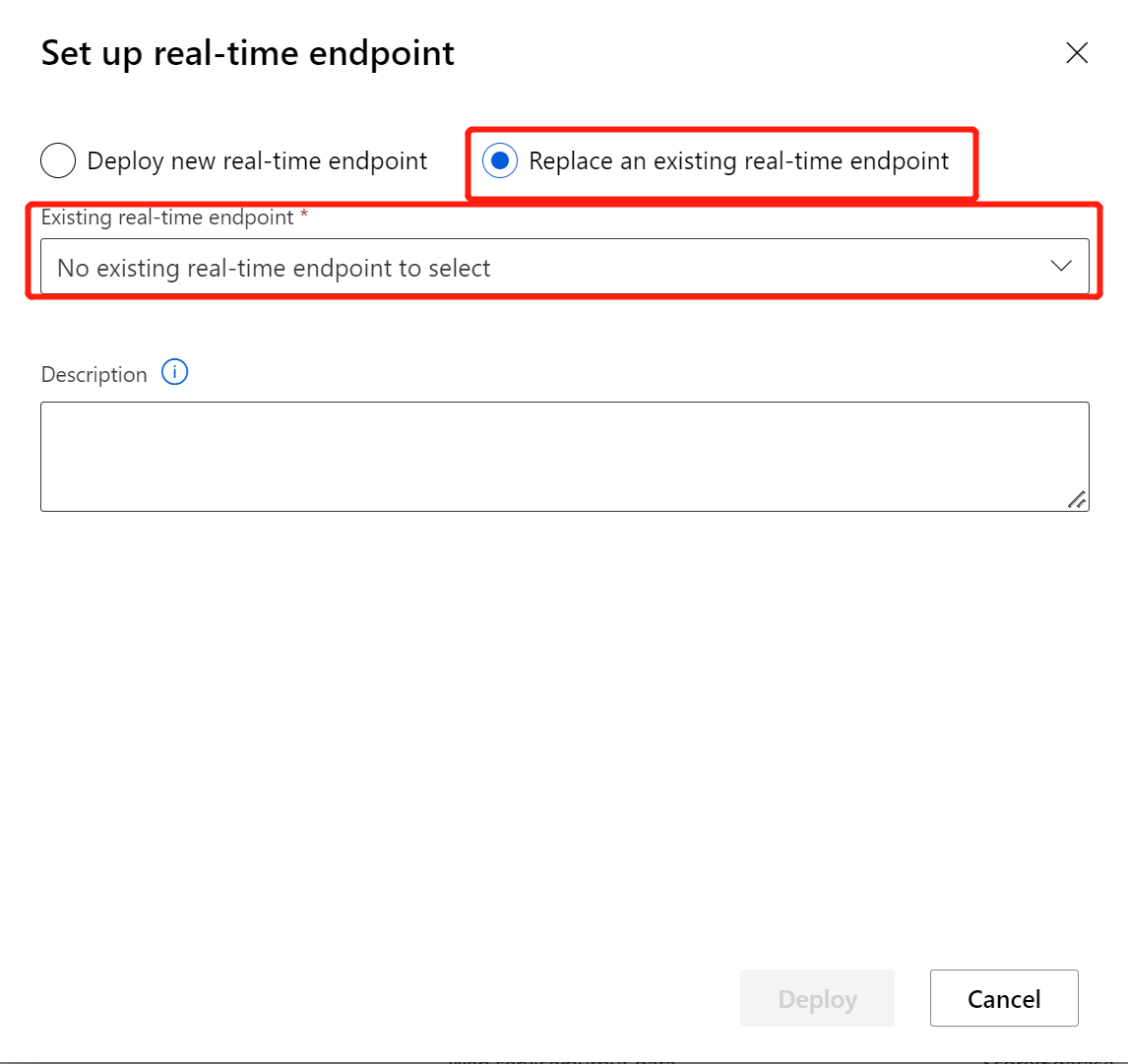
Nadat u uw deductiepijplijn hebt gewijzigd met het zojuist getrainde model of de zojuist getrainde transformatie, dient u deze in. Wanneer de taak is voltooid, implementeert u deze op het bestaande online-eindpunt dat eerder is geïmplementeerd.
Beperkingen
Als uw deductiepijplijn het onderdeel Import Data of Export Data bevat, worden deze vanwege een beperking voor toegang tot het gegevensarchief automatisch verwijderd wanneer de pijplijn in realtime wordt geïmplementeerd.
Als u gegevenssets in de realtime deductiepijplijn hebt en deze wilt implementeren in een realtime-eindpunt, ondersteunt deze stroom momenteel alleen gegevenssets die zijn geregistreerd vanuit het Blob-gegevensarchief . Als u gegevenssets van andere typen gegevensarchieven wilt gebruiken, kunt u Kolom selecteren gebruiken om verbinding te maken met uw eerste gegevensset met instellingen voor het selecteren van alle kolommen, de uitvoer van Kolom selecteren als bestandsgegevensset registreren en vervolgens de eerste gegevensset in de realtime-deductiepijplijn vervangen door deze zojuist geregistreerde gegevensset.
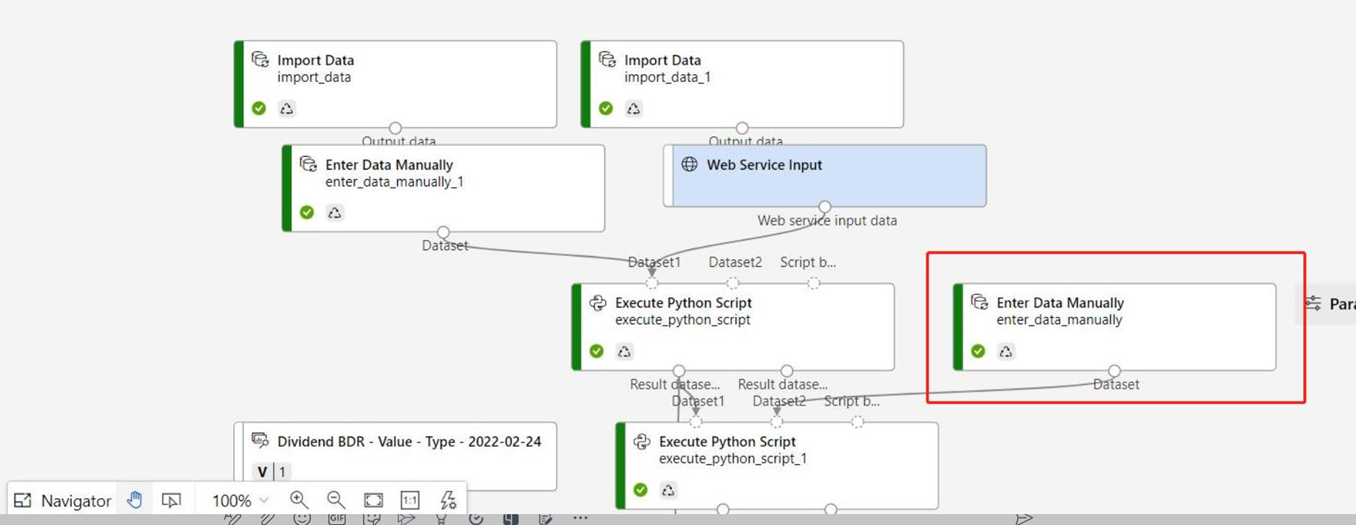
Als uw deductiegrafiek het onderdeel Gegevens handmatig invoeren bevat dat niet is verbonden met dezelfde poort als het onderdeel Webservice-invoer, wordt het onderdeel Gegevens handmatig invoeren niet uitgevoerd tijdens de verwerking van HTTP-aanroepen. Een tijdelijke oplossing is om de uitvoer van het onderdeel 'Gegevens handmatig invoeren' te registreren als gegevensset en vervolgens in het concept van de deductiepijplijn het onderdeel 'Gegevens handmatig invoeren' te vervangen door de geregistreerde gegevensset.
Resources opschonen
Belangrijk
U kunt de resources die u hebt gemaakt, gebruiken als vereisten voor andere Azure Machine Learning-zelfstudies en artikelen met procedures.
Alles verwijderen
Als u niets wilt gebruiken dat u hebt gemaakt, kunt u de hele resourcegroep verwijderen zodat er geen kosten voor in rekening worden gebracht.
Selecteer in Azure Portal, aan de linkerkant in het venster, de optie Resourcegroepen.
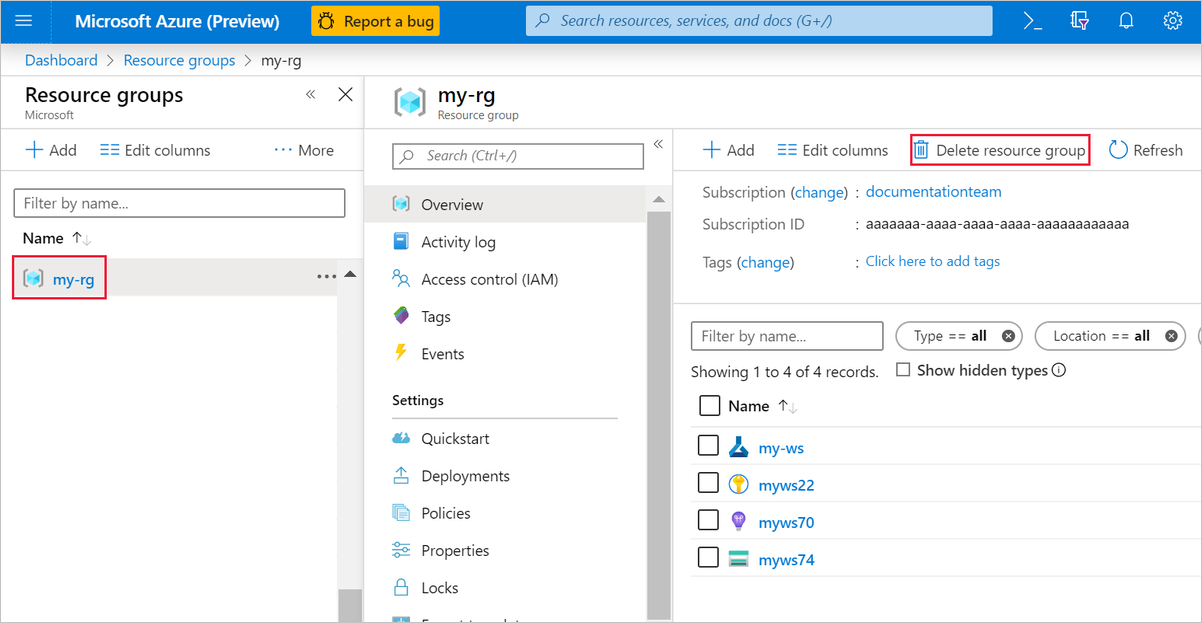
Selecteer de resourcegroep die u hebt gemaakt in de lijst.
Selecteer Resourcegroep verwijderen.
Als u de resource groep verwijdert, worden ook alle resources verwijderd die u in de ontwerpfunctie hebt gemaakt.
Afzonderlijke assets verwijderen
In de ontwerpfunctie waar u uw experiment hebt gemaakt, verwijdert u afzonderlijke assets door ze te selecteren en vervolgens de knop Verwijderen te selecteren.
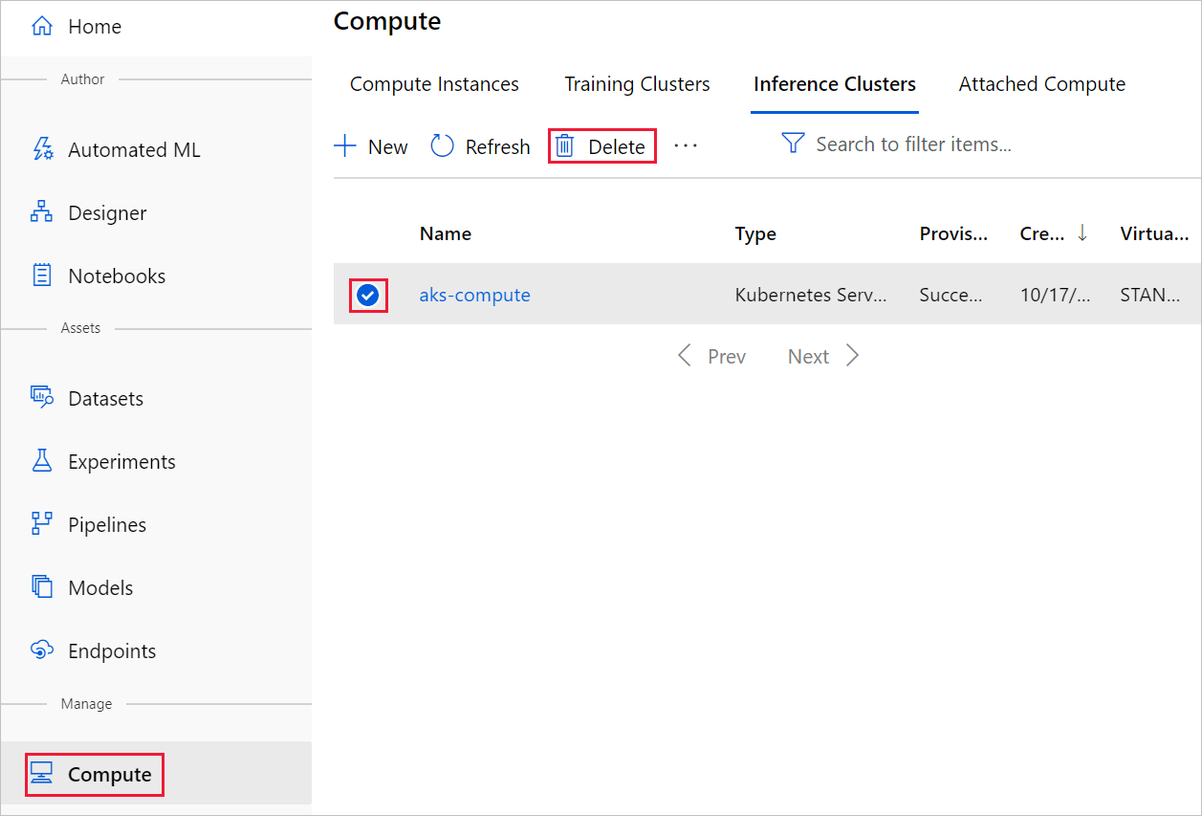
Het rekendoel dat u hier hebt gemaakt, wordt, wanneer het niet wordt gebruikt, automatisch geschaald naar nul knooppunten. Deze actie wordt uitgevoerd om de kosten te minimaliseren. Als u het rekendoel wilt verwijderen, voert u de volgende stappen uit:
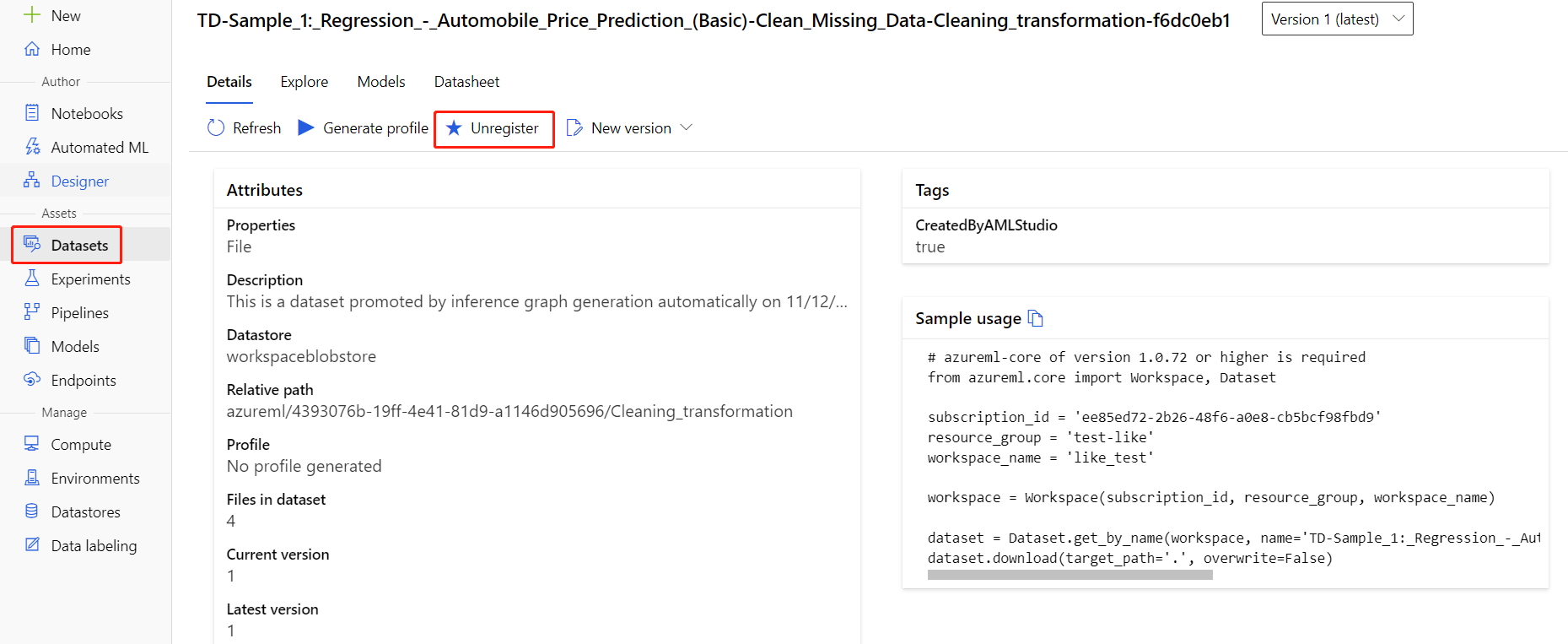
U kunt de registratie van gegevenssets vanuit uw werkruimte opheffen door alle gegevenssets te selecteren en Registratie opheffen te selecteren.
Als u een gegevensset wilt verwijderen, gaat u naar het opslagaccount via Azure Portal of Azure Storage Explorer en verwijdert u de assets handmatig.
Volgende stappen
In deze zelfstudie hebt u de belangrijkste stappen geleerd voor het maken, implementeren en gebruiken van een machine learning-model in de ontwerpfunctie. Bekijk de volgende koppelingen voor meer informatie over hoe u de ontwerpfunctie kunt gebruiken:
- Voorbeelden van ontwerpfunctie: Meer informatie over het gebruik van de ontwerpfunctie om andere typen problemen op te lossen.
- Azure Machine Learning Studio gebruiken in een virtueel Azure-netwerk.
Feedback
Binnenkort beschikbaar: In de loop van 2024 zullen we GitHub-problemen geleidelijk uitfaseren als het feedbackmechanisme voor inhoud en deze vervangen door een nieuw feedbacksysteem. Zie voor meer informatie: https://aka.ms/ContentUserFeedback.
Feedback verzenden en weergeven voor