Notitie
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen u aan te melden of de directory te wijzigen.
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen de mappen te wijzigen.
Azure Managed Instance voor Apache Cassandra biedt geautomatiseerde implementatie- en schaalbewerkingen voor beheerde opensource Apache Cassandra-datacenters. Deze functie versnelt hybride scenario's en helpt bij het verminderen van doorlopend onderhoud.
In deze quickstart ziet u hoe u Azure Portal gebruikt om een volledig beheerd Apache Spark-cluster te maken in het virtuele Azure-netwerk van uw Azure Managed Instance voor Apache Cassandra-cluster. U maakt het Spark-cluster in Azure Databricks. Later kunt u notebooks maken of koppelen aan het cluster, gegevens uit verschillende gegevensbronnen lezen en inzichten analyseren.
U kunt ook meer informatie vinden met gedetailleerde instructies over Het implementeren van Azure Databricks in uw virtuele Azure-netwerk (virtuele netwerkinjectie).
Vereisten
Als u geen Azure-abonnement hebt, maakt u een gratis account voordat u begint.
Een Azure Databricks-cluster maken
Volg deze stappen om een Azure Databricks-cluster te maken in een virtueel netwerk met azure Managed Instance voor Apache Cassandra:
Meld u aan bij het Azure-portaal.
Zoek Resourcegroepen in het linkerdeelvenster. Ga naar uw resourcegroep die het virtuele netwerk bevat waarin uw beheerde exemplaar is geïmplementeerd.
Open de resource van het virtuele netwerk en noteer de adresruimte.
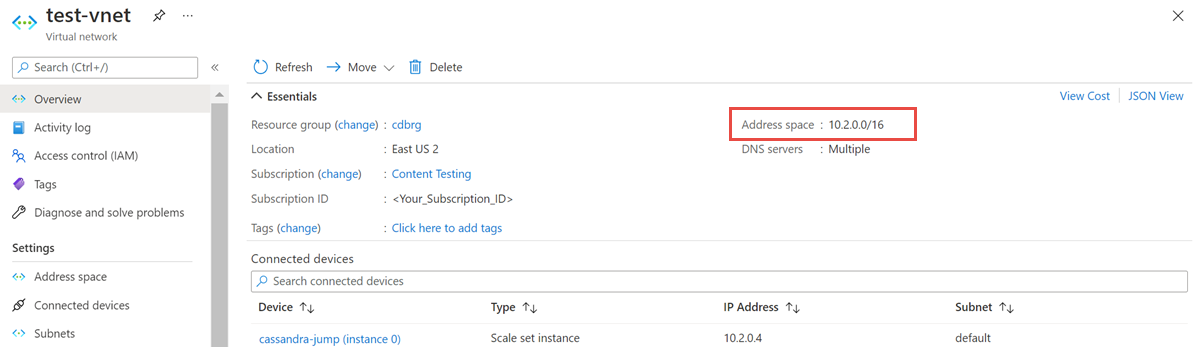
Selecteer in de resourcegroep Toevoegen en zoeken naar Azure Databricks in het zoekveld.
Selecteer Maken om een Azure Databricks-account te maken.
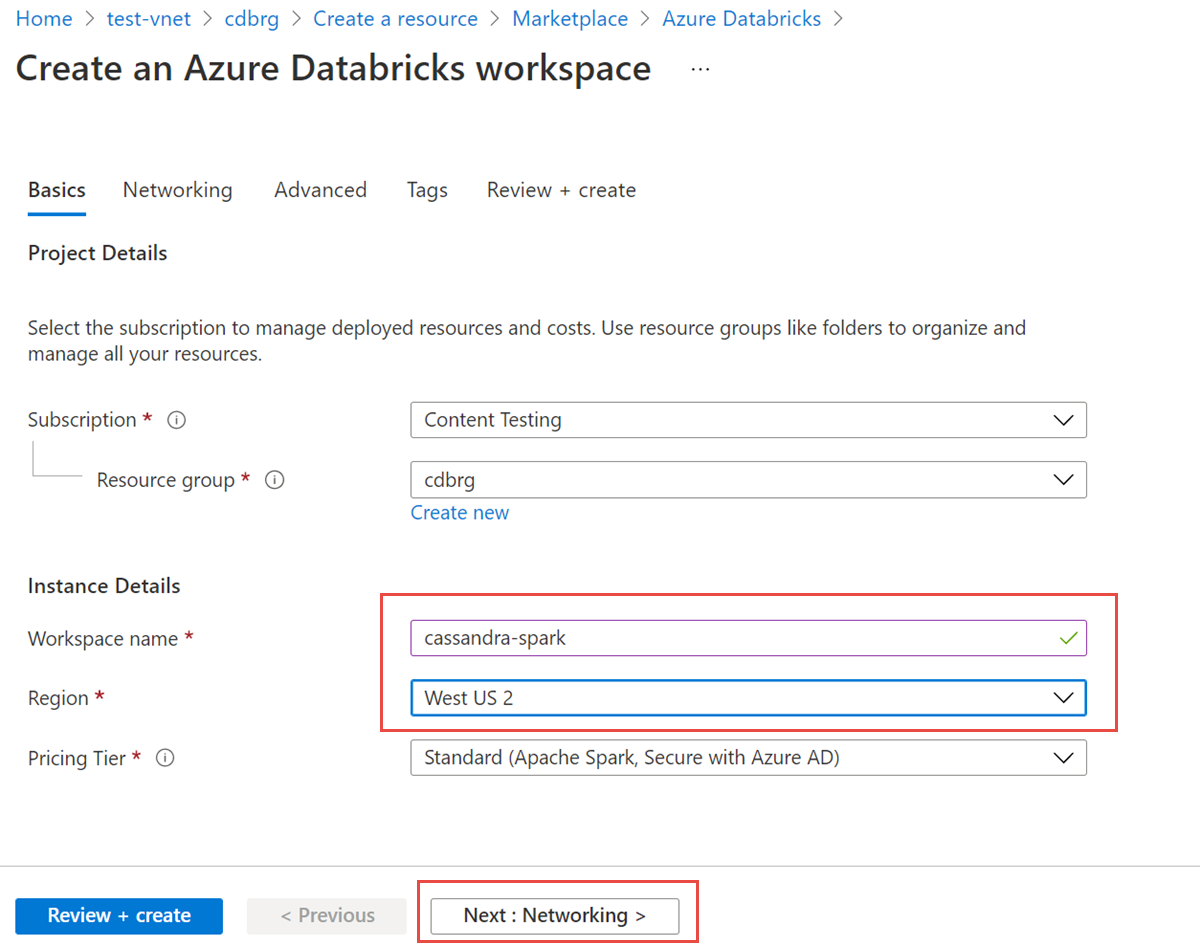
Voer de volgende waarden in:
- Werkruimtenaam: Geef een naam op voor uw Azure Databricks-werkruimte.
- Regio: Zorg ervoor dat u dezelfde regio selecteert als uw virtuele netwerk.
- Prijscategorie: Selecteer Standaard, Premium of Proefversie. Zie de pagina met prijzen van Azure Databricks voor meer informatie over deze lagen.
Selecteer het tabblad Netwerken en voer de volgende gegevens in:
- Azure Databricks-werkruimte implementeren in uw virtuele netwerk (VNet): Selecteer Ja.
- Virtueel netwerk: Kies in de vervolgkeuzelijst het virtuele netwerk waar uw beheerde exemplaar bestaat.
- Naam van openbaar subnet: voer een naam in voor het openbare subnet.
- CIDR-bereik van openbaar subnet: voer een IP-bereik in voor het openbare subnet.
- Private Subnet Name: Voer een naam in voor het privésubnet.
- CIDR-bereik voor privésubnet: voer een IP-bereik in voor het privésubnet.
Om bereikconflicten te voorkomen, moet u ervoor zorgen dat u hogere bereiken selecteert. Gebruik zo nodig een visual subnet calculator om de bereiken te verdelen.
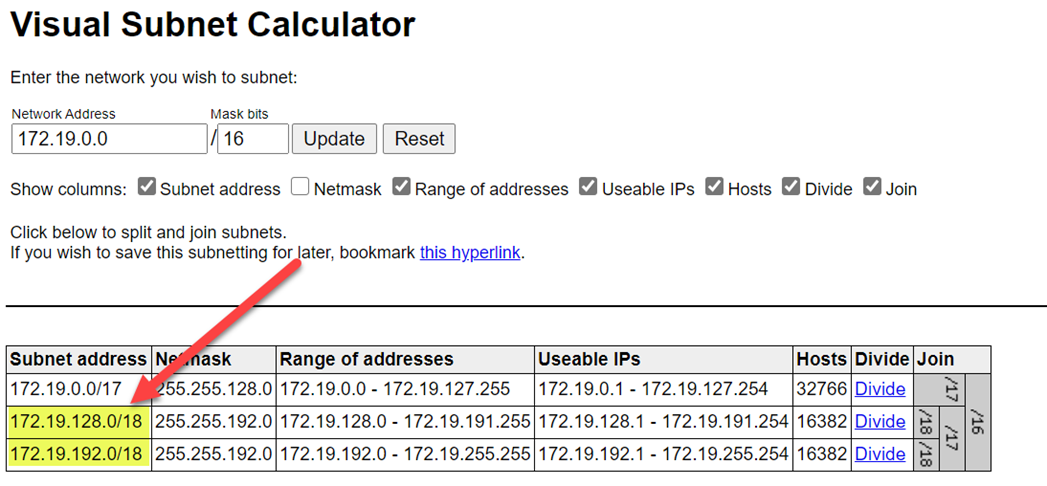
In de volgende schermopname ziet u voorbeelddetails in het netwerkvenster.
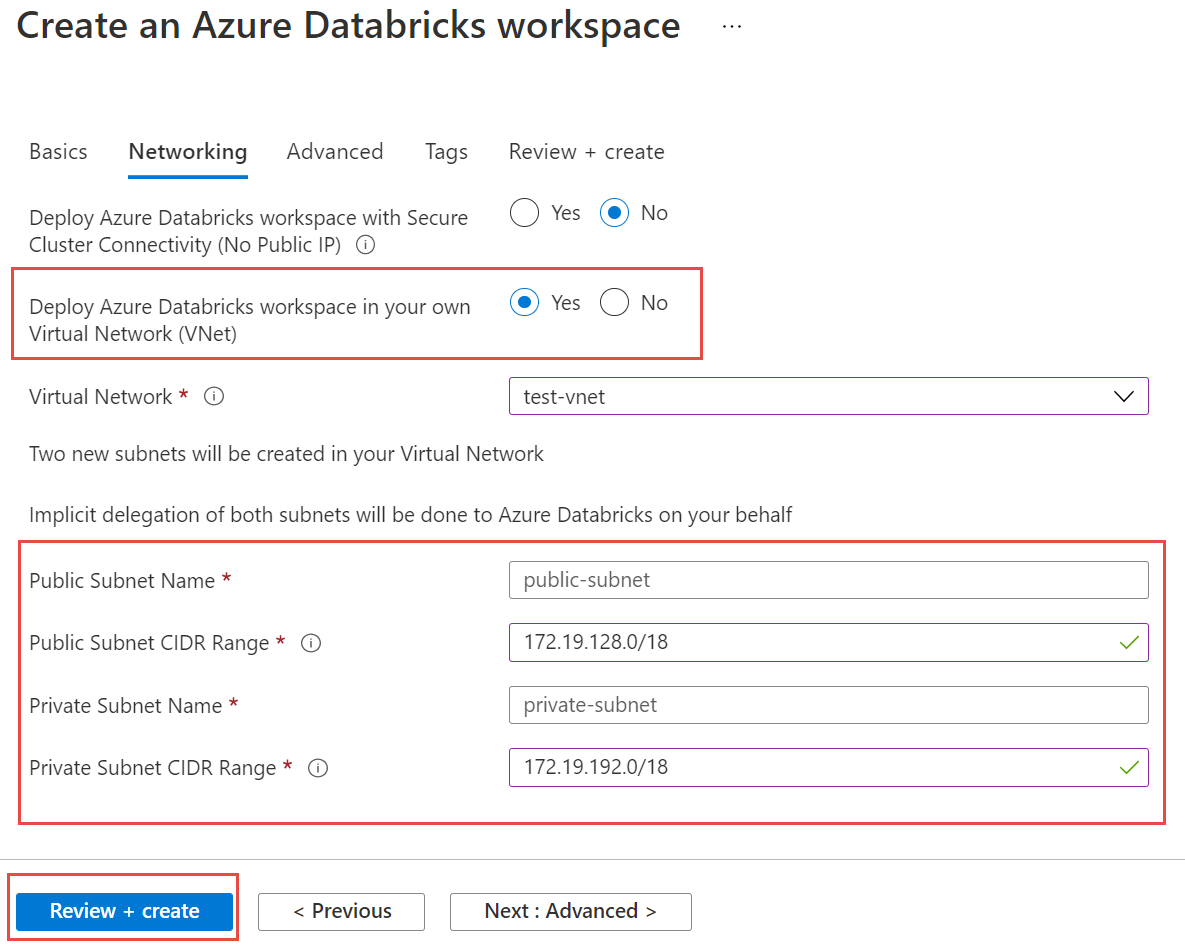
Selecteer Beoordelen en maken en selecteer vervolgens Maken om de werkruimte te implementeren.
Open de werkruimte nadat deze is gemaakt.
U wordt omgeleid naar de Azure Databricks-portal. Selecteer in de portal Nieuw cluster.
Accepteer in het deelvenster Nieuw cluster de standaardwaarden voor alle andere velden dan de volgende velden:
- Clusternaam: Voer een naam in voor het cluster.
- Databricks Runtime-versie: u wordt aangeraden Azure Databricks Runtime versie 7.5 of hoger te selecteren voor ondersteuning voor Spark 3.x.

Vouw Geavanceerde opties uit en voeg de volgende configuratie toe. Zorg ervoor dat u de IP-adressen en referenties van het knooppunt vervangt.
spark.cassandra.connection.host <node1 IP>,<node 2 IP>, <node IP> spark.cassandra.auth.password cassandra spark.cassandra.connection.port 9042 spark.cassandra.auth.username cassandra spark.cassandra.connection.ssl.enabled trueVoeg de Apache Spark Cassandra Connector-bibliotheek toe aan uw cluster om verbinding te maken met zowel systeemeigen als Azure Cosmos DB Cassandra-eindpunten. In uw cluster selecteer Bibliotheken>Nieuwe installeren>Maven, en voeg vervolgens
com.datastax.spark:spark-cassandra-connector-assembly_2.12:3.0.0toe in het veld Maven-coördinaten.
Selecteer Installeren.
Resources opschonen
Als u dit beheerde exemplaarcluster niet meer gaat gebruiken, volgt u deze stappen om het te verwijderen:
- Selecteer Resourcegroepen in het linkermenu van de Azure-portal.
- Kies in de lijst de resourcegroep die u voor deze quickstart hebt gemaakt.
- Selecteer Resourcegroep verwijderen in het deelvenster Overzicht van de resourcegroep.
- Voer in het volgende deelvenster de naam in van de resourcegroep die u wilt verwijderen en selecteer vervolgens Verwijderen.
Volgende stap
In deze quickstart hebt u geleerd hoe u een volledig beheerd Apache Spark-cluster maakt in het virtuele netwerk van uw Azure Managed Instance voor Apache Cassandra-cluster. Hierna leert u hoe u de cluster- en datacenterbronnen beheert.