Betrouwbaarheid in Azure Traffic Manager
Dit artikel bevat specifieke aanbevelingen voor betrouwbaarheid voor Azure Traffic Manager , evenals herstel na noodgevallen in meerdere regio's en ondersteuning voor bedrijfscontinuïteit voor Azure Traffic Manager.
Zie Azure-betrouwbaarheid voor een gedetailleerder overzicht van betrouwbaarheidsprincipes in Azure.
Aanbevelingen voor betrouwbaarheid
Deze sectie bevat aanbevelingen voor het bereiken van tolerantie en beschikbaarheid. Elke aanbeveling valt in een van de volgende twee categorieën:
Statusitems hebben betrekking op gebieden zoals configuratie-items en de juiste functie van de belangrijkste onderdelen waaruit uw Azure-workload bestaat, zoals azure-resourceconfiguratie-instellingen, afhankelijkheden van andere services, enzovoort.
Risico-items hebben betrekking op gebieden zoals beschikbaarheids- en herstelvereisten, testen, bewaken, implementeren en andere items die, indien onopgeloste, de kans op problemen in de omgeving vergroten.
Prioriteitsmatrix voor aanbevelingen voor betrouwbaarheid
Elke aanbeveling wordt gemarkeerd in overeenstemming met de volgende prioriteitsmatrix:
| Afbeelding | Prioriteit | Beschrijving |
|---|---|---|
| Hoog | Onmiddellijke oplossing nodig. | |
| Gemiddeld | Herstel binnen 3-6 maanden. | |
| Beperkt | Moet worden gecontroleerd. |
Samenvatting van aanbevelingen voor betrouwbaarheid
Beschikbaarheid
 De status van de Traffic Manager-monitor moet online zijn
De status van de Traffic Manager-monitor moet online zijn
De status van de monitor moet online zijn om failover voor de toepassingsworkload te bieden. Als de status van traffic manager een gedegradeerde status weergeeft, kan de status van een of meer eindpunten ook worden gedegradeerd.
Zie Traffic Manager-eindpuntbewaking voor meer informatie over eindpuntbewaking in Traffic Manager.
Als u problemen met een gedegradeerde status in Azure Traffic Manager wilt oplossen, raadpleegt u Problemen met gedegradeerde status in Azure Traffic Manager oplossen.
Traffic Manager-profielen moeten meer dan één eindpunt hebben
Wanneer u Azure Traffic Manager configureert, moet u minimaal twee eindpunten inrichten om een failover van de workload uit te voeren naar een ander exemplaar.
Zie Traffic Manager-eindpunten voor meer informatie over traffic manager-eindpunten.
Systeemefficiëntie
 TTL-waarde van gebruikersprofielen moet binnen 60 seconden zijn
TTL-waarde van gebruikersprofielen moet binnen 60 seconden zijn
Time to Live (TTL) beïnvloedt hoe snel een client een reactie krijgt als deze een aanvraag naar Azure Traffic Manager doet. Als de TTL-waarde wordt verlaagd, wordt de client in geval van een failover sneller gerouteerd naar een functionerend eindpunt. Stel uw TTL in op 60 seconden om verkeer zo snel mogelijk naar een werkend eindpunt te routeren.
Zie DNS Time to Live configureren voor meer informatie over het configureren van DNS TTL.
Herstel na noodgeval
Ten minste één eindpunt in een andere regio configureren
Profielen moeten meer dan één eindpunt hebben om de beschikbaarheid te garanderen als een eindpunt niet werkt. Het is ook raadzaam om alle eindpunten in verschillende regio's te plaatsen.
Zie Traffic Manager-eindpunten voor meer informatie over traffic manager-eindpunten.
Zorg ervoor dat het eindpunt is geconfigureerd voor (Alle wereld) voor geografische profielen
In het geval van geografische routering wordt verkeer gerouteerd naar eindpunten op basis van gedefinieerde regio's. Als er een fout optreedt in een regio, is er geen vooraf gedefinieerde failover. Als u een eindpunt hebt waarbij de regionale groepering is geconfigureerd voor 'Alle (wereld)' voor geografische profielen, voorkomt u dat verkeer zwart verkeer wordt ge hold en blijft de service gegarandeerd beschikbaar.
Zie Eindpunten toevoegen, uitschakelen, inschakelen, verwijderen of verplaatsen voor meer informatie over het toevoegen en configureren van een eindpunt.
Herstel na noodgevallen en bedrijfscontinuïteit tussen regio's
Herstel na noodgevallen (DR) gaat over het herstellen van gebeurtenissen met een hoge impact, zoals natuurrampen of mislukte implementaties die downtime en gegevensverlies tot gevolg hebben. Ongeacht de oorzaak is de beste oplossing voor een noodgeval een goed gedefinieerd en getest DR-plan en een toepassingsontwerp dat actief dr ondersteunt. Zie Aanbevelingen voordat u nadenkt over het maken van uw plan voor herstel na noodgevallen.
Als het gaat om herstel na noodgevallen, gebruikt Microsoft het model voor gedeelde verantwoordelijkheid. In een model voor gedeelde verantwoordelijkheid zorgt Microsoft ervoor dat de basisinfrastructuur en platformservices beschikbaar zijn. Tegelijkertijd repliceren veel Azure-services niet automatisch gegevens of vallen ze terug van een mislukte regio om kruislings te repliceren naar een andere ingeschakelde regio. Voor deze services bent u verantwoordelijk voor het instellen van een plan voor herstel na noodgevallen dat geschikt is voor uw workload. De meeste services die worden uitgevoerd op PaaS-aanbiedingen (Platform as a Service) van Azure bieden functies en richtlijnen ter ondersteuning van herstel na noodgeval en u kunt servicespecifieke functies gebruiken om snel herstel te ondersteunen om uw DR-plan te ontwikkelen.
Azure Traffic Manager is een load balancer op basis van DNS waarmee u verkeer kunt distribueren naar uw openbare toepassingen in wereldwijde Azure-regio's. Traffic Manager biedt ook uw openbare eindpunten met hoge beschikbaarheid en snelle reactiesnelheid.
Traffic Manager gebruikt DNS om clientaanvragen naar het juiste service-eindpunt te leiden op basis van een verkeersrouteringsmethode. Traffic Manager biedt ook statuscontrole voor elk eindpunt. Het eindpunt kan elke internetgerichte service zijn die binnen of buiten Azure wordt gehost. Traffic Manager biedt een scala aan routeringsmethoden voor verkeer en opties voor eindpuntcontrole om verschillende toepassingsbehoeften en modellen voor automatische failover mogelijk te kunnen maken. Traffic Manager is bestand tegen storingen, waaronder het uitvallen van een hele Azure-regio.
Herstel na noodgevallen in geografie in meerdere regio's
DNS is een van de meest efficiënte mechanismen voor het omleiden van netwerkverkeer. DNS is efficiënt omdat DNS vaak globaal en extern is voor het datacenter. DNS is ook geïsoleerd van eventuele storingen op het niveau van een regionale of beschikbaarheidszone (AZ).
Er zijn twee technische aspecten voor het instellen van uw architectuur voor herstel na noodgevallen:
Met behulp van een implementatiemechanisme voor het repliceren van exemplaren, gegevens en configuraties tussen primaire en stand-byomgevingen. Dit type noodherstel kan systeemeigen worden uitgevoerd viaAzure Site Recovery. Raadpleeg de Documentatie voor Azure Site Recovery via Microsoft Azure-partnerapparaten/-services zoals Veritas of NetApp.
Het ontwikkelen van een oplossing voor het omleiden van netwerk-/webverkeer van de primaire site naar de stand-bysite. Dit type herstel na noodgevallen kan worden bereikt via Azure DNS, Azure Traffic Manager (DNS) of globale load balancers van derden.
Dit artikel is specifiek gericht op azure Traffic Manager-planning voor herstel na noodgevallen.
Detectie, melding en beheer van storingen
Tijdens een noodgeval wordt het primaire eindpunt getest en wordt de status gewijzigd in gedegradeerd en blijft de site voor herstel na noodgevallen online. Standaard verzendt Traffic Manager al het verkeer naar het primaire eindpunt (met de hoogste prioriteit). Als het primaire eindpunt gedegradeerd wordt weergegeven, stuurt Traffic Manager het verkeer naar het tweede eindpunt zolang het in orde blijft. U kunt meer eindpunten configureren in Traffic Manager die kunnen fungeren als extra failover-eindpunten, of als load balancers de belasting delen tussen eindpunten.
Herstel na noodgevallen en detectie van storingen instellen
Wanneer u complexe architecturen en meerdere sets resources hebt die dezelfde functie kunnen uitvoeren, kunt u Azure Traffic Manager (op basis van DNS) configureren om de status van uw resources te controleren en het verkeer van de niet-gezonde resource naar de resource in orde te routeren.
In het volgende voorbeeld hebben zowel de primaire regio als de secundaire regio een volledige implementatie. Deze implementatie omvat de cloudservices en een gesynchroniseerde database.
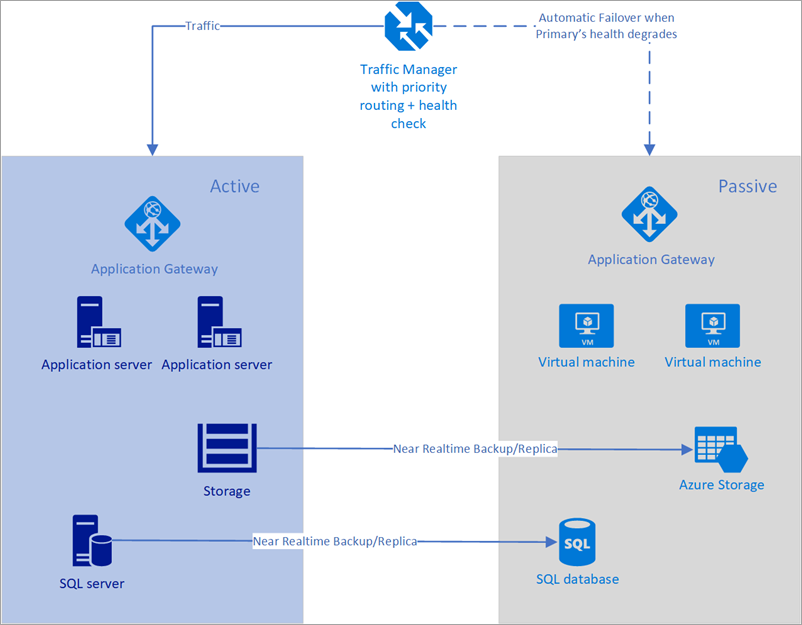
Afbeelding: automatische failover met Behulp van Azure Traffic Manager
Alleen de primaire regio verwerkt echter actief netwerkaanvragen van de gebruikers. De secundaire regio wordt alleen actief wanneer de primaire regio een serviceonderbreking ondervindt. In dat geval worden alle nieuwe netwerkaanvragen doorgestuurd naar de secundaire regio. Omdat de back-up van de database bijna onmiddellijk is, hebben beide load balancers IP-adressen die kunnen worden gecontroleerd en de exemplaren altijd actief zijn, biedt deze topologie een optie voor een lage RTO en failover zonder handmatige tussenkomst. De secundaire failoverregio moet direct na het mislukken van de primaire regio klaar zijn om live te kunnen gaan.
Dit scenario is ideaal voor het gebruik van Azure Traffic Manager met ingebouwde tests voor verschillende soorten statuscontroles, waaronder http/https en TCP. Azure Traffic Manager heeft ook een regelengine die kan worden geconfigureerd om een failover uit te voeren wanneer er een fout optreedt, zoals hieronder wordt beschreven. Laten we eens kijken naar de volgende oplossing met Traffic Manager:
- De klant heeft het eindpunt Regio #1 dat bekend staat als prod.contoso.com met een statisch IP-adres als 100.168.124.44 en een regio #2-eindpunt dat bekend staat als dr.contoso.com met een statisch IP-adres als 100.168.124.43.
- Elk van deze omgevingen vindt plaats via een openbare eigenschap, zoals een load balancer. De load balancer kan worden geconfigureerd voor een op DNS gebaseerd eindpunt of een FQDN (Fully Qualified Domain Name) zoals hierboven wordt weergegeven.
- Alle exemplaren in regio 2 bevinden zich in bijna realtime replicatie met Regio 1. Bovendien zijn de machineinstallatiekopieën up-to-date en worden alle software-/configuratiegegevens gepatcht en zijn ze in overeenstemming met Regio 1.
- Automatisch schalen wordt vooraf geconfigureerd.
De failover configureren met Azure Traffic Manager:
Maak een nieuw Azure Traffic Manager-profiel maak een nieuw Azure Traffic Manager-profiel met de naam contoso123 en selecteer de routeringsmethode als Prioriteit. Als u een bestaande resourcegroep hebt waaraan u wilt koppelen, kunt u een bestaande resourcegroep selecteren, anders maakt u een nieuwe resourcegroep.
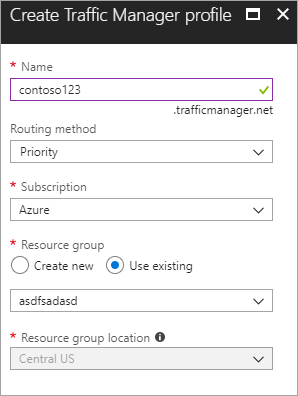
Afbeelding - Een Traffic Manager-profiel maken
Eindpunten maken in het Traffic Manager-profiel
In deze stap maakt u eindpunten die verwijzen naar de productie- en herstelsites na noodgevallen. Kies hier het type als een extern eindpunt, maar als de resource wordt gehost in Azure, kunt u ook Azure-eindpunt kiezen. Als u een Azure-eindpunt kiest, selecteert u een doelresource die een App Service of een openbaar IP-adres is dat door Azure wordt toegewezen. De prioriteit wordt ingesteld als 1 omdat dit de primaire service voor Regio 1 is. Maak ook het eindpunt voor herstel na noodgevallen in Traffic Manager.
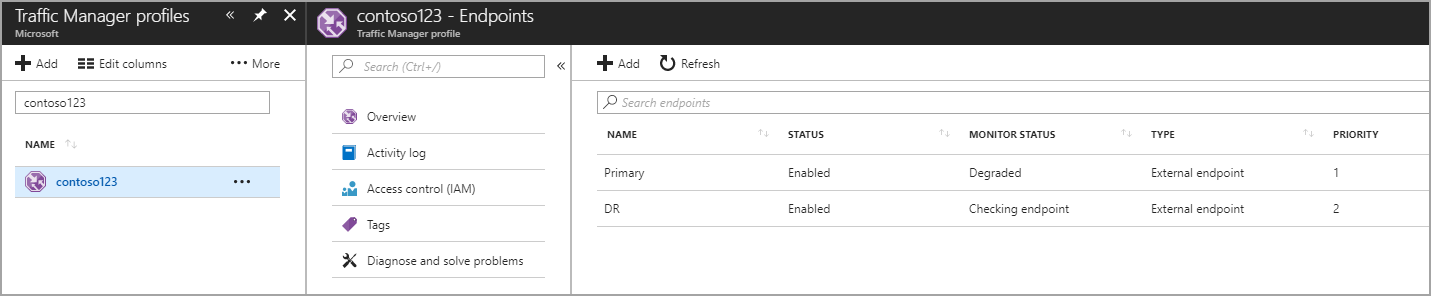
Afbeelding: eindpunten voor herstel na noodgevallen maken
Statuscontrole en failoverconfiguratie instellen
In deze stap stelt u de DNS-TTL in op 10 seconden, wat wordt gehonoreerd door de meeste recursieve resolvers op internet. Deze configuratie betekent dat er gedurende meer dan 10 seconden geen DNS-resolver meer dan 10 seconden in de cache wordt opgeslagen.
Voor de instellingen van de eindpuntmonitor is het pad actueel ingesteld op/of hoofdmap, maar u kunt de eindpuntinstellingen aanpassen om een pad te evalueren, bijvoorbeeld prod.contoso.com/index.
In het onderstaande voorbeeld ziet u de https als het testprotocol. U kunt echter ook http of tcp kiezen. De keuze van het protocol is afhankelijk van de eindtoepassing. Het testinterval is ingesteld op 10 seconden, waardoor snel testen mogelijk is en het opnieuw proberen is ingesteld op 3. Als gevolg hiervan voert Traffic Manager een failover uit naar het tweede eindpunt als er drie opeenvolgende intervallen een fout registreren.
De volgende formule definieert de totale tijd voor een automatische failover:
Time for failover = TTL + Retry * Probing intervalIn dit geval is de waarde 10 + 3 * 10 = 40 seconden (Max).
Als de nieuwe poging is ingesteld op 1 en TTL is ingesteld op 10 seconden, wordt de tijd voor failover 10 + 1 * 10 = 20 seconden.
Stel de nieuwe poging in op een waarde die groter is dan 1 om de kans op failovers te elimineren vanwege fout-positieven of kleine netwerk-blip's.
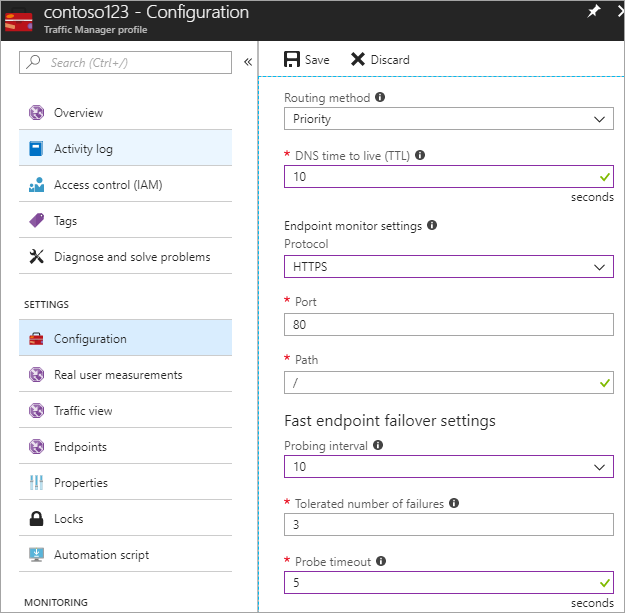
Afbeelding: statuscontrole en failoverconfiguratie instellen
Volgende stappen
Meer informatie over Azure Traffic Manager.
Meer informatie over Azure DNS.
Feedback
Binnenkort beschikbaar: In de loop van 2024 zullen we GitHub-problemen geleidelijk uitfaseren als het feedbackmechanisme voor inhoud en deze vervangen door een nieuw feedbacksysteem. Zie voor meer informatie: https://aka.ms/ContentUserFeedback.
Feedback verzenden en weergeven voor