Notitie
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen u aan te melden of de directory te wijzigen.
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen de mappen te wijzigen.
In dit artikel leest u hoe u NVIDIA GPU-workloads gebruikt met Azure Red Hat OpenShift.
Vereiste voorwaarden
- OpenShift CLI
- jq, moreutils en gettext-pakket
- Azure Red Hat OpenShift 4.10
Als u een cluster wilt installeren, raadpleegt u zelfstudie: Een Azure Red Hat OpenShift 4-cluster maken. clusters moeten versie 4.10.x of hoger zijn.
Opmerking
Vanaf 4.10 is het niet meer nodig om rechten in te stellen voor het gebruik van de NVIDIA-operator. Dit heeft de installatie van het cluster voor GPU-workloads aanzienlijk vereenvoudigd.
Linux:
sudo dnf install jq moreutils gettext
macOS
brew install jq moreutils gettext
GPU-quotum aanvragen
Alle GPU-quota in Azure zijn standaard 0. U moet zich aanmelden bij Azure Portal en GPU-quotum aanvragen. Vanwege concurrentie voor GPU-werknemers moet u mogelijk een cluster inrichten in een regio waar u GPU daadwerkelijk kunt reserveren.
ondersteunt de volgende GPU-werkrollen:
- NC4as T4 v3
- NC6s v3
- NC8as T4 v3
- NC12s v3
- NC16as T4 v3
- NC24s v3
- NC24rs v3
- NC64as T4 v3
De volgende exemplaren worden ook ondersteund in aanvullende MachineSets:
- Standard_ND96asr_v4
- NC24ads_A100_v4
- NC48ads_A100_v4
- NC96ads_A100_v4
- ND96amsr_A100_v4
Opmerking
Wanneer u een quotum aanvraagt, moet u er rekening mee houden dat Azure per kern is. Als u één NC4as T4 v3-knooppunt wilt aanvragen, moet u een quotum aanvragen in groepen van 4. Als u een NC16as T4 v3 wilt aanvragen, moet u een quotum van 16 aanvragen.
Meld u aan bij Azure Portal.
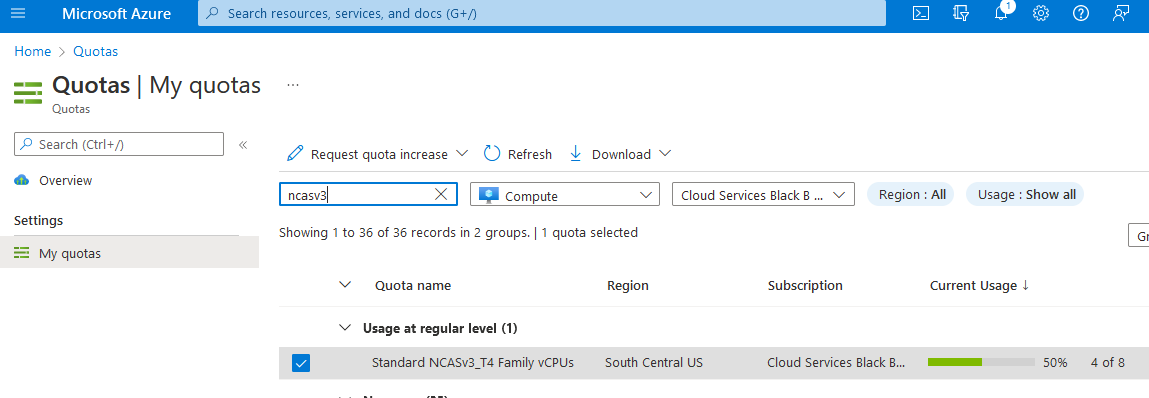
Voer quota in het zoekvak in en selecteer Compute.
Voer in het zoekvak NCAsv3_T4 in, schakel het selectievakje in voor de regio waarin uw cluster zich bevindt en selecteer vervolgens Quotumverhoging aanvragen.
Configureer quota.
Aanmelden bij uw cluster
Meld u aan bij OpenShift met een gebruikersaccount met bevoegdheden voor clusterbeheerders. In het onderstaande voorbeeld wordt een account met de naam kubadmin gebruikt:
oc login <apiserver> -u kubeadmin -p <kubeadminpass>
Pull-geheim (voorwaardelijk)
Werk uw pull-geheim bij om ervoor te zorgen dat u operators kunt installeren en verbinding kunt maken met cloud.redhat.com.
Opmerking
Sla deze stap over als u al een volledig pull-geheim hebt gemaakt met cloud.redhat.com ingeschakeld.
Meld u aan bij cloud.redhat.com.
Navigeer naar https://cloud.redhat.com/openshift/install/azure/aro-provisioned.
Selecteer Pull-geheim downloaden en sla het pull-geheim op als
pull-secret.txt.Belangrijk
De resterende stappen in deze sectie moeten worden uitgevoerd in dezelfde werkmap als
pull-secret.txt.Exporteer het bestaande pull-geheim.
oc get secret pull-secret -n openshift-config -o json | jq -r '.data.".dockerconfigjson"' | base64 --decode > export-pull.jsonVoeg het gedownloade pull-geheim samen met het systeem pull-geheim om toe te voegen
cloud.redhat.com.jq -s '.[0] * .[1]' export-pull.json pull-secret.txt | tr -d "\n\r" > new-pull-secret.jsonUpload het nieuwe geheime bestand.
oc set data secret/pull-secret -n openshift-config --from-file=.dockerconfigjson=new-pull-secret.jsonMogelijk moet u ongeveer 1 uur wachten totdat alles is gesynchroniseerd met cloud.redhat.com.
Geheimen verwijderen.
rm pull-secret.txt export-pull.json new-pull-secret.json
GPU-machineset
maakt gebruik van Kubernetes MachineSet om machinesets te maken. In de onderstaande procedure wordt uitgelegd hoe u de eerste machine die in een cluster is ingesteld, exporteert en deze als sjabloon gebruikt om één GPU-machine te bouwen.
Bestaande machinesets weergeven.
Voor het gemak van de installatie wordt in dit voorbeeld de eerste machineset gebruikt als de set die moet worden gekloond om een nieuwe GPU-machineset te maken.
MACHINESET=$(oc get machineset -n openshift-machine-api -o=jsonpath='{.items[0]}' | jq -r '[.metadata.name] | @tsv')Sla een kopie van de voorbeeldcomputerset op.
oc get machineset -n openshift-machine-api $MACHINESET -o json > gpu_machineset.jsonWijzig het
.metadata.nameveld in een nieuwe unieke naam.jq '.metadata.name = "nvidia-worker-<region><az>"' gpu_machineset.json| sponge gpu_machineset.jsonZorg ervoor dat
spec.replicasdeze overeenkomt met het gewenste aantal replica's voor de machineset.jq '.spec.replicas = 1' gpu_machineset.json| sponge gpu_machineset.jsonWijzig het
.spec.selector.matchLabels.machine.openshift.io/cluster-api-machinesetveld zodat het overeenkomt met het.metadata.nameveld.jq '.spec.selector.matchLabels."machine.openshift.io/cluster-api-machineset" = "nvidia-worker-<region><az>"' gpu_machineset.json| sponge gpu_machineset.jsonWijzig de
.spec.template.metadata.labels.machine.openshift.io/cluster-api-machinesetwaarde die overeenkomt met het.metadata.nameveld.jq '.spec.template.metadata.labels."machine.openshift.io/cluster-api-machineset" = "nvidia-worker-<region><az>"' gpu_machineset.json| sponge gpu_machineset.jsonWijzig de
spec.template.spec.providerSpec.value.vmSizewaarde zodat deze overeenkomt met het gewenste GPU-exemplaartype van Azure.De machine die in dit voorbeeld wordt gebruikt, is Standard_NC4as_T4_v3.
jq '.spec.template.spec.providerSpec.value.vmSize = "Standard_NC4as_T4_v3"' gpu_machineset.json | sponge gpu_machineset.jsonWijzig de
spec.template.spec.providerSpec.value.zonewaarde zodat deze overeenkomt met de gewenste zone vanuit Azure.jq '.spec.template.spec.providerSpec.value.zone = "1"' gpu_machineset.json | sponge gpu_machineset.jsonVerwijder de
.statussectie van het yaml-bestand.jq 'del(.status)' gpu_machineset.json | sponge gpu_machineset.jsonControleer de andere gegevens in het yaml-bestand.
Zorg ervoor dat de juiste SKU is ingesteld
Afhankelijk van de installatiekopieën die voor de machineset worden gebruikt, moeten beide waarden voor image.sku en image.version dienovereenkomstig worden ingesteld. Dit is om ervoor te zorgen dat de virtuele machine van generatie 1 of 2 voor Hyper-V wordt gebruikt. Zie hier voor meer informatie.
Voorbeeld:
Als u beide versies gebruikt Standard_NC4as_T4_v3, worden beide versies ondersteund. Zoals vermeld in functieondersteuning. In dit geval zijn er geen wijzigingen vereist.
Als u de VM van de tweede generatie gebruiktStandard_NC24ads_A100_v4, wordt alleen ondersteund.
In dit geval moet de image.sku waarde de equivalente versie van de installatiekopieën v2 volgen die overeenkomt met het oorspronkelijke image.skucluster. In dit voorbeeld is v410-v2de waarde .
U vindt deze met behulp van de volgende opdracht:
az vm image list --architecture x64 -o table --all --offer aro4 --publisher azureopenshift
Filtered output:
SKU VERSION
------- ---------------
v410-v2 410.84.20220125
aro_410 410.84.20220125
Als het cluster is gemaakt met de basis-SKU-installatiekopieën aro_410en dezelfde waarde wordt bewaard in de computerset, mislukt het met de volgende fout:
failure sending request for machine myworkernode: cannot create vm: compute.VirtualMachinesClient#CreateOrUpdate: Failure sending request: StatusCode=400 -- Original Error: Code="BadRequest" Message="The selected VM size 'Standard_NC24ads_A100_v4' cannot boot Hypervisor Generation '1'.
GPU-machineset maken
Gebruik de volgende stappen om de nieuwe GPU-machine te maken. Het kan 10-15 minuten duren voordat een nieuwe GPU-machine is ingericht. Als deze stap mislukt, meldt u zich aan bij Azure Portal en zorgt u ervoor dat er geen beschikbaarheidsproblemen zijn. Hiervoor gaat u naar Virtuele machines en zoekt u de werkrolnaam die u eerder hebt gemaakt om de status van VM's weer te geven.
Maak de GPU-machineset.
oc create -f gpu_machineset.jsonHet voltooien van deze opdracht duurt enkele minuten.
Controleer de GPU-machineset.
Machines moeten worden geïmplementeerd. U kunt de status van de machineset weergeven met de volgende opdrachten:
oc get machineset -n openshift-machine-api oc get machine -n openshift-machine-apiZodra de machines zijn ingericht (wat 5-15 minuten kan duren), worden machines weergegeven als knooppunten in de lijst met knooppunten:
oc get nodesU ziet nu een knooppunt met de
nvidia-worker-southcentralus1naam die eerder is gemaakt.
NVIDIA GPU-operator installeren
In deze sectie wordt uitgelegd hoe u de nvidia-gpu-operator naamruimte maakt, de operatorgroep instelt en de NVIDIA GPU-operator installeert.
Maak NVIDIA-naamruimte.
cat <<EOF | oc apply -f - apiVersion: v1 kind: Namespace metadata: name: nvidia-gpu-operator EOFOperatorgroep maken.
cat <<EOF | oc apply -f - apiVersion: operators.coreos.com/v1 kind: OperatorGroup metadata: name: nvidia-gpu-operator-group namespace: nvidia-gpu-operator spec: targetNamespaces: - nvidia-gpu-operator EOFDownload het nieuwste NVIDIA-kanaal met behulp van de volgende opdracht:
CHANNEL=$(oc get packagemanifest gpu-operator-certified -n openshift-marketplace -o jsonpath='{.status.defaultChannel}')
Opmerking
Als uw cluster is gemaakt zonder het pull-geheim op te geven, bevat het cluster geen voorbeelden of operators van Red Hat of van gecertificeerde partners. Dit resulteert in het volgende foutbericht:
Fout van server (NotFound): packagemanifests.packages.operators.coreos.com 'gpu-operator-certified' niet gevonden.
Volg deze richtlijnen om uw Red Hat-pull-geheim toe te voegen aan een Azure Red Hat OpenShift-cluster.
Download het nieuwste NVIDIA-pakket met behulp van de volgende opdracht:
PACKAGE=$(oc get packagemanifests/gpu-operator-certified -n openshift-marketplace -ojson | jq -r '.status.channels[] | select(.name == "'$CHANNEL'") | .currentCSV')Abonnement maken.
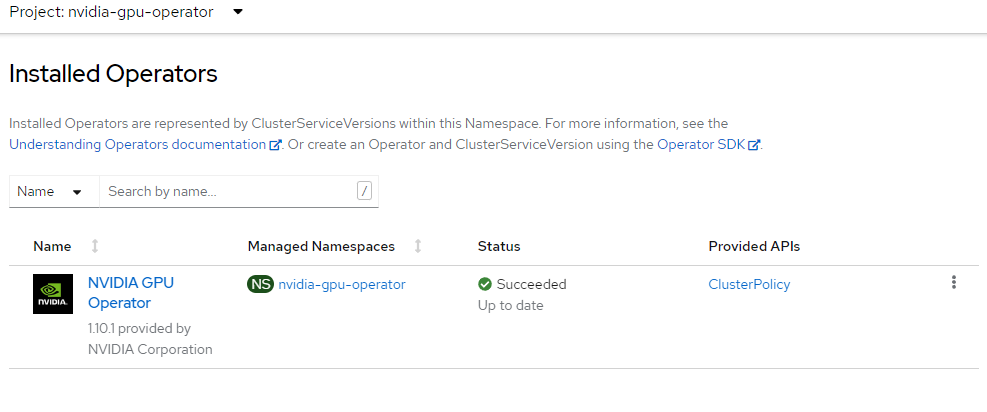
envsubst <<EOF | oc apply -f - apiVersion: operators.coreos.com/v1alpha1 kind: Subscription metadata: name: gpu-operator-certified namespace: nvidia-gpu-operator spec: channel: "$CHANNEL" installPlanApproval: Automatic name: gpu-operator-certified source: certified-operators sourceNamespace: openshift-marketplace startingCSV: "$PACKAGE" EOFWacht tot de installatie van Operator is voltooid.
Ga pas verder als u hebt gecontroleerd of de operator klaar is met installeren. Zorg er ook voor dat uw GPU-werkrol online is.
Detectieoperator voor knooppuntfuncties installeren
De detectieoperator voor knooppuntfuncties detecteert de GPU op uw knooppunten en labelt de knooppunten op de juiste manier, zodat u deze kunt richten op workloads.
In dit voorbeeld wordt de NFD-operator in de openshift-ndf naamruimte geïnstalleerd en wordt het 'abonnement' gemaakt. Dit is de configuratie voor NFD.
Officiële documentatie voor het installeren van knooppuntfunctiedetectieoperator.
Stel
Namespacein.cat <<EOF | oc apply -f - apiVersion: v1 kind: Namespace metadata: name: openshift-nfd EOFOperatorGroupmaken.cat <<EOF | oc apply -f - apiVersion: operators.coreos.com/v1 kind: OperatorGroup metadata: generateName: openshift-nfd- name: openshift-nfd namespace: openshift-nfd EOFSubscriptionmaken.cat <<EOF | oc apply -f - apiVersion: operators.coreos.com/v1alpha1 kind: Subscription metadata: name: nfd namespace: openshift-nfd spec: channel: "stable" installPlanApproval: Automatic name: nfd source: redhat-operators sourceNamespace: openshift-marketplace EOFWacht totdat de installatie van knooppuntfuncties is voltooid.
U kunt zich aanmelden bij uw OpenShift-console om operators weer te geven of een paar minuten te wachten. Als de operator niet is geïnstalleerd, treedt er een fout op in de volgende stap.
Een NFD-exemplaar maken.
cat <<EOF | oc apply -f - kind: NodeFeatureDiscovery apiVersion: nfd.openshift.io/v1 metadata: name: nfd-instance namespace: openshift-nfd spec: customConfig: configData: | # - name: "more.kernel.features" # matchOn: # - loadedKMod: ["example_kmod3"] # - name: "more.features.by.nodename" # value: customValue # matchOn: # - nodename: ["special-.*-node-.*"] operand: image: >- registry.redhat.io/openshift4/ose-node-feature-discovery@sha256:07658ef3df4b264b02396e67af813a52ba416b47ab6e1d2d08025a350ccd2b7b servicePort: 12000 workerConfig: configData: | core: # labelWhiteList: # noPublish: false sleepInterval: 60s # sources: [all] # klog: # addDirHeader: false # alsologtostderr: false # logBacktraceAt: # logtostderr: true # skipHeaders: false # stderrthreshold: 2 # v: 0 # vmodule: ## NOTE: the following options are not dynamically run-time ## configurable and require a nfd-worker restart to take effect ## after being changed # logDir: # logFile: # logFileMaxSize: 1800 # skipLogHeaders: false sources: # cpu: # cpuid: ## NOTE: attributeWhitelist has priority over attributeBlacklist # attributeBlacklist: # - "BMI1" # - "BMI2" # - "CLMUL" # - "CMOV" # - "CX16" # - "ERMS" # - "F16C" # - "HTT" # - "LZCNT" # - "MMX" # - "MMXEXT" # - "NX" # - "POPCNT" # - "RDRAND" # - "RDSEED" # - "RDTSCP" # - "SGX" # - "SSE" # - "SSE2" # - "SSE3" # - "SSE4.1" # - "SSE4.2" # - "SSSE3" # attributeWhitelist: # kernel: # kconfigFile: "/path/to/kconfig" # configOpts: # - "NO_HZ" # - "X86" # - "DMI" pci: deviceClassWhitelist: - "0200" - "03" - "12" deviceLabelFields: # - "class" - "vendor" # - "device" # - "subsystem_vendor" # - "subsystem_device" # usb: # deviceClassWhitelist: # - "0e" # - "ef" # - "fe" # - "ff" # deviceLabelFields: # - "class" # - "vendor" # - "device" # custom: # - name: "my.kernel.feature" # matchOn: # - loadedKMod: ["example_kmod1", "example_kmod2"] # - name: "my.pci.feature" # matchOn: # - pciId: # class: ["0200"] # vendor: ["15b3"] # device: ["1014", "1017"] # - pciId : # vendor: ["8086"] # device: ["1000", "1100"] # - name: "my.usb.feature" # matchOn: # - usbId: # class: ["ff"] # vendor: ["03e7"] # device: ["2485"] # - usbId: # class: ["fe"] # vendor: ["1a6e"] # device: ["089a"] # - name: "my.combined.feature" # matchOn: # - pciId: # vendor: ["15b3"] # device: ["1014", "1017"] # loadedKMod : ["vendor_kmod1", "vendor_kmod2"] EOFControleer of NFD gereed is.
De status van deze operator moet worden weergegeven als Beschikbaar.

NVIDIA-clusterconfiguratie toepassen
In deze sectie wordt uitgelegd hoe u de configuratie van het NVIDIA-cluster toepast. Lees de NVIDIA-documentatie over het aanpassen hiervan als u uw eigen persoonlijke opslagplaatsen of specifieke instellingen hebt. Dit proces kan enkele minuten duren.
Clusterconfiguratie toepassen.
cat <<EOF | oc apply -f - apiVersion: nvidia.com/v1 kind: ClusterPolicy metadata: name: gpu-cluster-policy spec: migManager: enabled: true operator: defaultRuntime: crio initContainer: {} runtimeClass: nvidia deployGFD: true dcgm: enabled: true gfd: {} dcgmExporter: config: name: '' driver: licensingConfig: nlsEnabled: false configMapName: '' certConfig: name: '' kernelModuleConfig: name: '' repoConfig: configMapName: '' virtualTopology: config: '' enabled: true use_ocp_driver_toolkit: true devicePlugin: {} mig: strategy: single validator: plugin: env: - name: WITH_WORKLOAD value: 'true' nodeStatusExporter: enabled: true daemonsets: {} toolkit: enabled: true EOFControleer het clusterbeleid.
Meld u aan bij de OpenShift-console en blader naar operators. Zorg ervoor dat u zich in de
nvidia-gpu-operatornaamruimte bevindt. Het zou moeten zeggenState: Ready once everything is complete.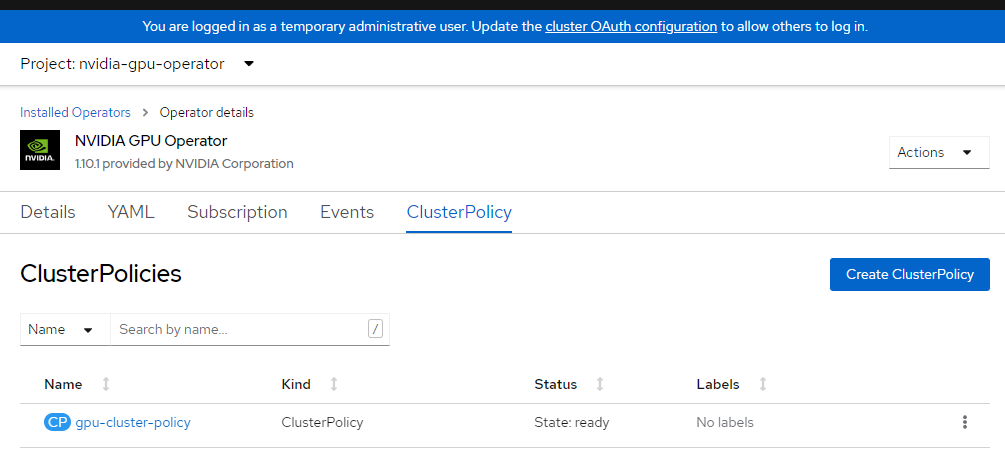
GPU valideren
Het kan enige tijd duren voordat de NVIDIA-operator en NFD de machines volledig installeren en zelf identificeren. Voer de volgende opdrachten uit om te controleren of alles wordt uitgevoerd zoals verwacht:
Controleer of NFD uw GPU('s) kan zien.
oc describe node | egrep 'Roles|pci-10de' | grep -v masterDe uitvoer moet er ongeveer als volgt uitzien:
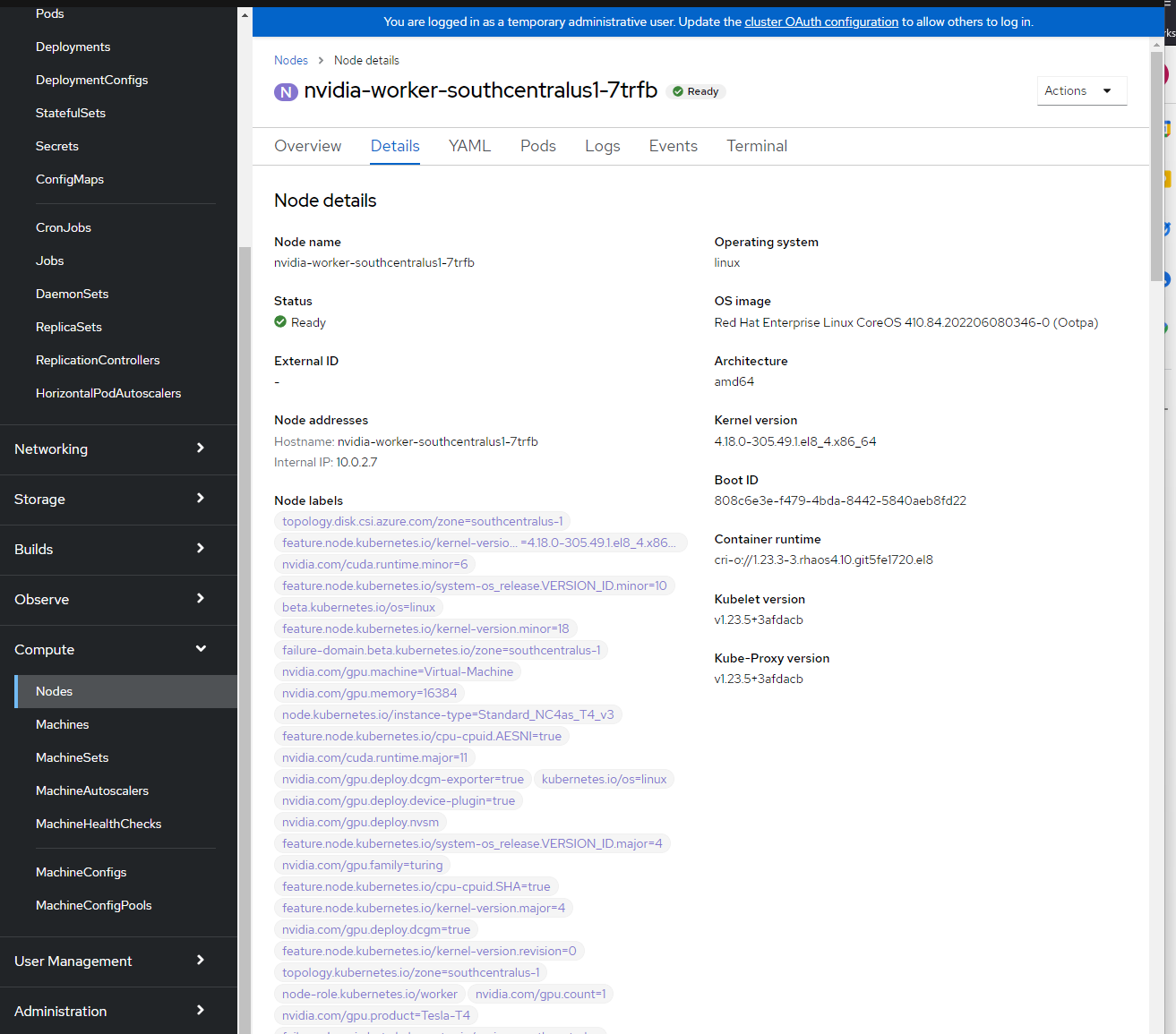
Roles: worker feature.node.kubernetes.io/pci-10de.present=trueControleer knooppuntlabels.
U kunt de knooppuntlabels zien door u aan te melden bij de OpenShift-console -> Compute -> Knooppunten -> nvidia-worker-southcentralus1-. U ziet nu meerdere NVIDIA GPU-labels en het pci-10de-apparaat van bovenaf.
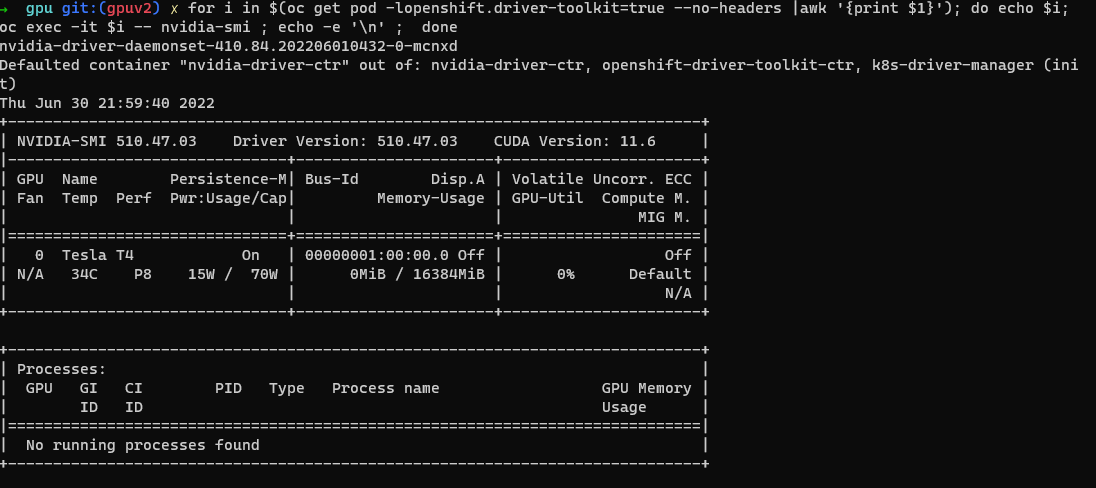
Verificatie van NVIDIA SMI-hulpprogramma's.
oc project nvidia-gpu-operator for i in $(oc get pod -lopenshift.driver-toolkit=true --no-headers |awk '{print $1}'); do echo $i; oc exec -it $i -- nvidia-smi ; echo -e '\n' ; doneU ziet uitvoer met de GPU's die beschikbaar zijn op de host, zoals in deze voorbeeldschermafbeelding. (Varieert afhankelijk van het type GPU-werkrol)
Pod maken om een GPU-workload uit te voeren
oc project nvidia-gpu-operator cat <<EOF | oc apply -f - apiVersion: v1 kind: Pod metadata: name: cuda-vector-add spec: restartPolicy: OnFailure containers: - name: cuda-vector-add image: "quay.io/giantswarm/nvidia-gpu-demo:latest" resources: limits: nvidia.com/gpu: 1 nodeSelector: nvidia.com/gpu.present: true EOFLogboeken weergeven.
oc logs cuda-vector-add --tail=-1
Opmerking
Als er een fout optreedt Error from server (BadRequest): container "cuda-vector-add" in pod "cuda-vector-add" is waiting to start: ContainerCreating, voert oc delete pod cuda-vector-add u de bovenstaande create-instructie opnieuw uit en voert u de bovenstaande instructie opnieuw uit.
De uitvoer moet er ongeveer als volgt uitzien (afhankelijk van GPU):
[Vector addition of 5000 elements]
Copy input data from the host memory to the CUDA device
CUDA kernel launch with 196 blocks of 256 threads
Copy output data from the CUDA device to the host memory
Test PASSED
Done
Als dit lukt, kan de pod worden verwijderd:
oc delete pod cuda-vector-add