Overzicht van bedrijfscontinuïteit met Azure Database for PostgreSQL - Flexibele server
VAN TOEPASSING OP:  Azure Database for PostgreSQL - Flexibele server
Azure Database for PostgreSQL - Flexibele server
Bedrijfscontinuïteit in Flexibele Azure Database for PostgreSQL-server verwijst naar de mechanismen, beleidsregels en procedures waarmee uw bedrijf kan blijven werken ten aanzien van onderbrekingen, met name naar de computerinfrastructuur. In de meeste gevallen verwerkt de flexibele Azure Database for PostgreSQL-server verstorende gebeurtenissen die zich kunnen voordoen in de cloudomgeving en blijven uw toepassingen en bedrijfsprocessen actief. Er zijn echter enkele gebeurtenissen die niet automatisch kunnen worden verwerkt, zoals:
- Gebruiker verwijdert of werkt per ongeluk een rij in een tabel bij.
- Aardbeving veroorzaakt een stroomstoring en schakelt tijdelijk een beschikbaarheidszone of een regio uit.
- Databasepatching vereist om een probleem of beveiligingsprobleem op te lossen.
Azure Database for PostgreSQL flexibele server biedt functies die gegevens beschermen en downtime voor uw bedrijfskritieke databases beperken tijdens geplande en ongeplande downtimegebeurtenissen. Azure Database for PostgreSQL Flexibele server is gebouwd op basis van de Azure-infrastructuur die robuuste tolerantie en beschikbaarheid biedt, heeft functies voor bedrijfscontinuïteit die een andere foutbeveiliging bieden, hersteltijdvereisten aanpakken en blootstelling aan gegevensverlies verminderen. Wanneer u uw toepassingen ontwerpt, moet u rekening houden met de downtimetolerantie ( de beoogde hersteltijd ( RTO) en blootstelling aan gegevensverlies - de beoogde herstelpunt (RPO). Uw bedrijfskritieke database vereist bijvoorbeeld strengere uptime dan een testdatabase.
In de onderstaande tabel ziet u de functies die azure Database for PostgreSQL flexibele server biedt.
| Functie | Beschrijving | Overwegingen |
|---|---|---|
| Automatische back-ups | Azure Database for PostgreSQL Flexibele server voert automatisch dagelijkse back-ups van uw databasebestanden uit en maakt continu een back-up van transactielogboeken. Back-ups kunnen 7 tot 35 dagen worden bewaard. U kunt uw databaseserver herstellen naar een bepaald tijdstip binnen de bewaarperiode voor back-ups. RTO is afhankelijk van de grootte van de gegevens die moeten worden hersteld + de tijd die nodig is om logboekherstel uit te voeren. Het kan enkele minuten tot 12 uur duren. Zie Concepten - Back-up en herstel voor meer informatie. | Back-upgegevens blijven binnen de regio. |
| Zone-redundante hoge beschikbaarheid | Flexibele Azure Database for PostgreSQL-server kan worden geïmplementeerd met een zone-redundante hoge beschikbaarheidsconfiguratie waarbij primaire en stand-byservers worden geïmplementeerd in twee verschillende beschikbaarheidszones binnen een regio. Deze ha-configuratie beschermt uw databases tegen fouten op zoneniveau en helpt ook bij het verminderen van de downtime van toepassingen tijdens geplande en ongeplande downtimegebeurtenissen. Gegevens van de primaire server worden gerepliceerd naar de stand-byreplica in de synchrone modus. In het geval van onderbreking van de primaire server wordt de server automatisch een failover uitgevoerd naar de stand-byreplica. In de meeste gevallen is RTO naar verwachting minder dan 120. De RPO is naar verwachting nul (geen gegevensverlies). Zie Concepten - Hoge beschikbaarheid voor meer informatie. | Ondersteund in rekenlagen voor algemeen gebruik en geoptimaliseerd voor geheugen. Alleen beschikbaar in regio's waar meerdere zones beschikbaar zijn. |
| Dezelfde zone met hoge beschikbaarheid | Flexibele Azure Database for PostgreSQL-server kan worden geïmplementeerd met dezelfde hoge beschikbaarheidsconfiguratie (HA) voor zones waarbij primaire en stand-byservers worden geïmplementeerd in dezelfde beschikbaarheidszone in een regio. Deze ha-configuratie beveiligt uw databases tegen storingen op knooppuntniveau en helpt ook bij het verminderen van de downtime van toepassingen tijdens geplande en ongeplande downtimegebeurtenissen. Gegevens van de primaire server worden gerepliceerd naar de stand-byreplica in de synchrone modus. In het geval van onderbreking van de primaire server wordt de server automatisch een failover uitgevoerd naar de stand-byreplica. In de meeste gevallen is RTO naar verwachting minder dan 120. De RPO is naar verwachting nul (geen gegevensverlies). Zie Concepten - Hoge beschikbaarheid voor meer informatie. | Ondersteund in rekenlagen voor algemeen gebruik en geoptimaliseerd voor geheugen. |
| Premium beheerde schijven | Databasebestanden worden opgeslagen in een uiterst duurzame en betrouwbare, eersteklas beheerde opslag. Dit biedt gegevensredundantie met drie kopieën van replica's die zijn opgeslagen in een beschikbaarheidszone met een functionaliteit voor automatische gegevensherstel. Zie de documentatie voor beheerde schijven voor meer informatie. | Gegevens die zijn opgeslagen in een beschikbaarheidszone. |
| Zoneredundante back-up | Back-ups van flexibele azure Database for PostgreSQL-servers worden automatisch en veilig opgeslagen in een zone-redundante opslag binnen een regio, als de regio beschikbaarheidszones ondersteunt. Tijdens een fout op zoneniveau waarin uw server is ingericht en als uw server niet is geconfigureerd met zoneredundantie, kunt u uw database nog steeds herstellen met behulp van het meest recente herstelpunt in een andere zone. Zie Concepten - Back-up en herstel voor meer informatie. | Alleen van toepassing in regio's waar meerdere zones beschikbaar zijn. |
| Geografisch redundante back-up | Back-ups van flexibele azure Database for PostgreSQL-servers worden gekopieerd naar een externe regio. dat helpt bij herstel na noodgevallen in het geval dat de primaire serverregio uitvalt. | Deze functie is momenteel ingeschakeld in geselecteerde regio's. Het duurt een langere RTO en een hogere RPO, afhankelijk van de grootte van de gegevens die moeten worden hersteld en de hoeveelheid herstel die moet worden uitgevoerd. |
| Leesreplica | Leesreplica's tussen regio's kunnen worden geïmplementeerd om uw databases te beschermen tegen storingen op regioniveau. Leesreplica's worden asynchroon bijgewerkt met behulp van de fysieke replicatietechnologie van PostgreSQL en kunnen de primaire replica vertraging oplopen. Zie Concepten - Leesreplica's voor meer informatie. | Ondersteund in rekenlagen voor algemeen gebruik en geoptimaliseerd voor geheugen. |
In de volgende tabel worden RTO en RPO vergeleken in een typisch workloadscenario :
| Mogelijkheid | Burstable | Algemeen doel | Geoptimaliseerd voor geheugen |
|---|---|---|---|
| Herstel naar een bepaald tijdstip vanuit back-up | Elk herstelpunt binnen de bewaarperiode RTO - varieert RPO < 5 min. |
Elk herstelpunt binnen de bewaarperiode RTO - varieert RPO < 5 min. |
Elk herstelpunt binnen de bewaarperiode RTO - varieert RPO < 5 min. |
| Geo-herstel vanuit geo-gerepliceerde back-ups | RTO - varieert RPO < 1 h |
RTO - varieert RPO < 1 h |
RTO - varieert RPO < 1 h |
| Leesreplica's | RTO - Minuten* RPO < 5 min* |
RTO - Minuten* RPO < 5 min* |
RTO - Minuten* RPO < 5 min* |
* RTO en RPO kunnen in sommige gevallen veel hoger zijn, afhankelijk van verschillende factoren, waaronder latentie tussen sites, de hoeveelheid gegevens die moet worden verzonden en belangrijke primaire databaseschrijfworkload.
Geplande downtimegebeurtenissen
Hieronder ziet u enkele geplande onderhoudsscenario's. Deze gebeurtenissen veroorzaken doorgaans maximaal enkele minuten downtime en zonder gegevensverlies.
| Scenario | Verwerken |
|---|---|
| Rekenkracht schalen (door de gebruiker geïnitieerd) | Tijdens de berekeningsbewerking kunnen actieve controlepunten worden voltooid, clientverbindingen worden leeggemaakt, worden alle niet-doorgevoerde transacties geannuleerd, wordt de opslag losgekoppeld en wordt deze afgesloten. Een nieuw exemplaar van een flexibele Azure Database for PostgreSQL-server met dezelfde databaseservernaam wordt ingericht met de geschaalde rekenconfiguratie. De opslag wordt vervolgens gekoppeld aan de nieuwe server en de database wordt gestart, waarmee, indien nodig, herstel wordt uitgevoerd voordat clientverbindingen worden geaccepteerd. |
| Opslag omhoog schalen (door de gebruiker geïnitieerd) | Wanneer een opslagbewerking voor omhoog schalen wordt gestart, kunnen actieve controlepunten worden voltooid, worden clientverbindingen leeggemaakt en worden eventuele niet-doorgevoerde transacties geannuleerd. Daarna wordt de server afgesloten. De opslag wordt geschaald naar de gewenste grootte en vervolgens gekoppeld aan de nieuwe server. Er wordt indien nodig een herstel uitgevoerd voordat clientverbindingen worden geaccepteerd. Houd er rekening mee dat omlaag schalen van de opslaggrootte niet wordt ondersteund. |
| Nieuwe software-implementatie (door Azure geïnitieerd) | Nieuwe functies worden automatisch geïmplementeerd of opgeloste fouten als onderdeel van gepland onderhoud van de service en u kunt plannen wanneer deze activiteiten plaatsvinden. Raadpleeg uw portal voor meer informatie. |
| Secundaire versie-upgrades (door Azure geïnitieerd) | In Azure Database for PostgreSQL worden databaseservers automatisch gepatcht naar de secundaire versie die wordt bepaald door Azure. Dit gebeurt als onderdeel van het geplande onderhoud van de service. De databaseserver wordt automatisch opnieuw opgestart met de nieuwe secundaire versie. Raadpleeg de documentatie voor meer informatie. U kunt ook uw portal controleren. |
Wanneer het flexibele serverexemplaren van Azure Database for PostgreSQL is geconfigureerd met hoge beschikbaarheid, voert de service eerst de schaal- en onderhoudsbewerkingen uit op de stand-byserver. Zie Concepten - Hoge beschikbaarheid voor meer informatie.
Niet-geplande uitvaltijd beperken
Niet-geplande downtime kan optreden als gevolg van onvoorziene onderbrekingen, zoals onderliggende hardwarestoringen, netwerkproblemen en softwarefouten. Als de databaseserver die is geconfigureerd met hoge beschikbaarheid onverwacht uitvalt, wordt de stand-byreplica geactiveerd en kunnen de clients hun bewerkingen hervatten. Als deze niet is geconfigureerd met hoge beschikbaarheid (HA), wordt automatisch een nieuwe databaseserver ingericht als de poging tot opnieuw opstarten mislukt. Hoewel een niet-geplande downtime niet kan worden vermeden, helpt Azure Database for PostgreSQL flexibele server de downtime te beperken door automatisch herstelbewerkingen uit te voeren zonder menselijke tussenkomst.
Hoewel we continu streven naar hoge beschikbaarheid, zijn er momenten waarop azure Database for PostgreSQL flexibele server uitvalt, waardoor de databases niet beschikbaar zijn en dus van invloed zijn op uw toepassing. Wanneer onze servicebewaking problemen detecteert die wijdverspreide connectiviteitsfouten, fouten of prestatieproblemen veroorzaken, declareert de service automatisch een storing om u op de hoogte te houden.
Service-onderbreking
In het geval van een storing in Azure Database for PostgreSQL Flexibele server ziet u meer informatie met betrekking tot de storing op de volgende plaatsen:
- Azure Portal-banner: Als uw abonnement wordt beïnvloed, treedt er een storingswaarschuwing op van een serviceprobleem in uw Azure Portal-meldingen.
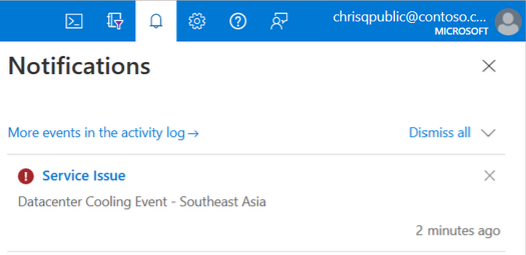
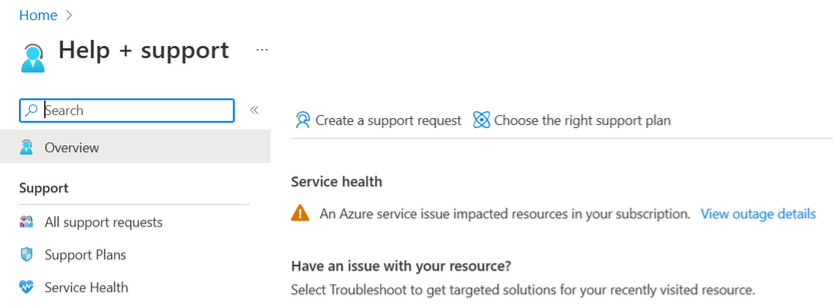
- Help + ondersteuning of ondersteuning + probleemoplossing: wanneer u een ondersteuningsticket maakt via Help + ondersteuning of ondersteuning en probleemoplossing, vindt u informatie over eventuele problemen die van invloed zijn op uw resources. Selecteer Onderbrekingsdetails weergeven voor meer informatie en een samenvatting van de impact. Er wordt ook een waarschuwing weergegeven op de pagina Nieuwe ondersteuningsaanvraag.
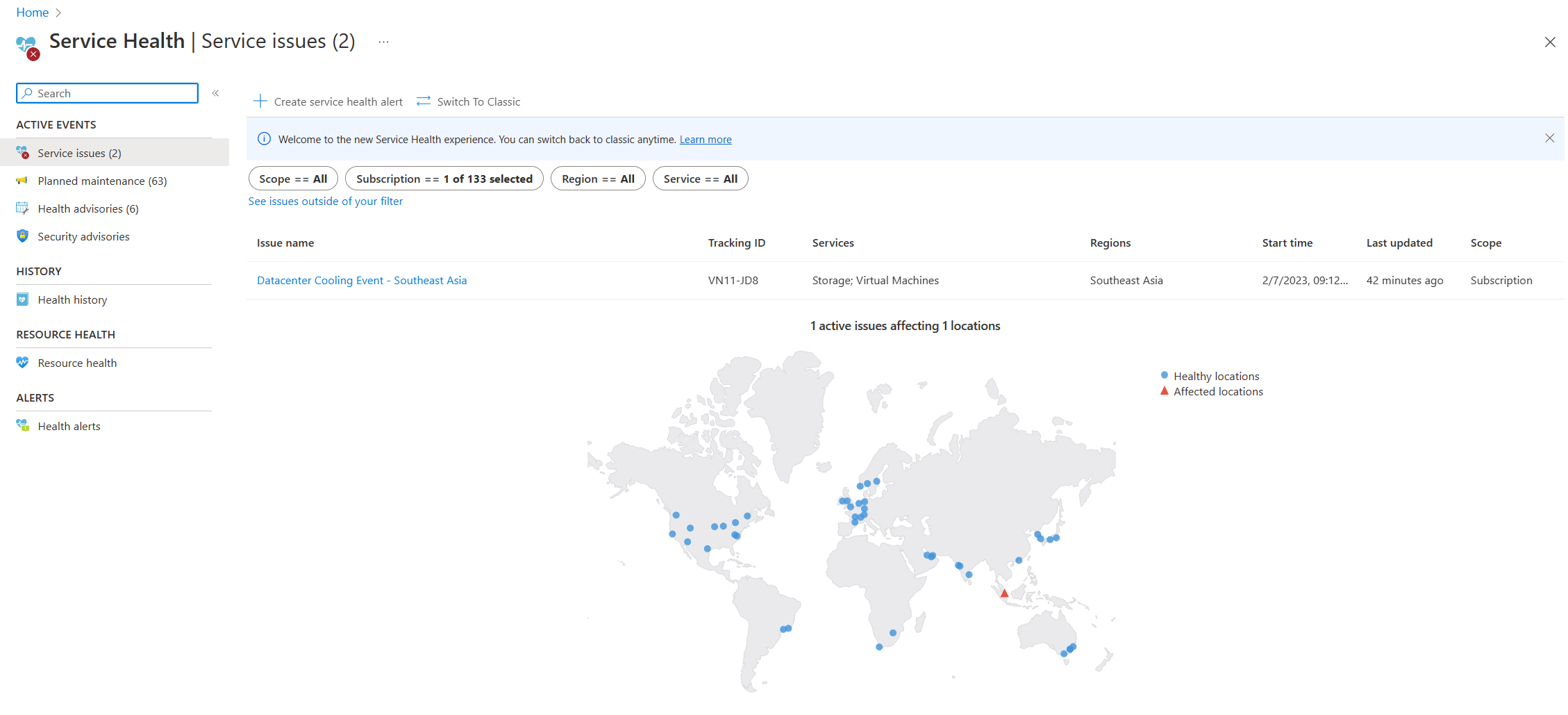
- Service-help: de pagina Servicestatus in Azure Portal bevat informatie over de status van het Azure-datacenter wereldwijd. Zoek in de zoekbalk in Azure Portal naar servicestatus en bekijk vervolgens serviceproblemen in de categorie Actieve gebeurtenissen. U kunt ook de status van afzonderlijke resources bekijken op de pagina Resourcestatus van elke resource in het menu Help. Een voorbeeldschermopname van de pagina Service Health volgt, met informatie over een actief serviceprobleem in Zuidoost-Azië.
- E-mailmelding: Als u waarschuwingen hebt ingesteld, ontvangt u een e-mailmelding wanneer een servicestoring van invloed is op uw abonnement en resource. De e-mailberichten komen van 'azure-noreply@microsoft.com'. De hoofdtekst van het e-mailbericht begint met 'De waarschuwing voor het activiteitenlogboek... is geactiveerd door een serviceprobleem voor het Azure-abonnement...". Zie Waarschuwingen voor activiteitenlogboeken ontvangen in Azure-servicemeldingen met behulp van de Azure-portal voor meer informatie over servicestatuswaarschuwingen.
Belangrijk
Zoals de naam al aangeeft, worden tijdelijke tabelruimten in PostgreSQL gebruikt voor tijdelijke objecten, evenals andere interne databasebewerkingen, zoals sorteren. Daarom raden we u niet aan om gebruikersschemaobjecten te maken in tijdelijke tabelruimte, omdat we niet garanderen dat dergelijke objecten na het opnieuw opstarten van de server, ha-failovers, enzovoort.
Niet-geplande downtime: foutscenario's en serviceherstel
Hieronder ziet u enkele niet-geplande foutscenario's en het herstelproces.
| Scenario | Herstelproces [Servers geconfigureerd zonder zone-redundante hoge beschikbaarheid] |
Herstelproces [Servers geconfigureerd met zone-redundante HA] |
|---|---|---|
| Databaseserverfout | Als de databaseserver niet beschikbaar is, probeert Azure de databaseserver opnieuw op te starten. Als dat mislukt, wordt de databaseserver opnieuw opgestart op een ander fysiek knooppunt. De hersteltijd (RTO) is afhankelijk van verschillende factoren, waaronder de activiteit op het moment van fout, zoals grote transacties, en het volume van herstel dat moet worden uitgevoerd tijdens het opstarten van de databaseserver. Toepassingen die gebruikmaken van de PostgreSQL-databases moeten worden gebouwd op een manier waarop ze verbroken verbindingen en mislukte transacties detecteren en opnieuw proberen. |
Als de databaseserverfout wordt gedetecteerd, wordt er een failover van de server naar de stand-byserver uitgevoerd, waardoor de downtime wordt verminderd. Zie de pagina concepten voor hoge beschikbaarheid voor meer informatie. RTO zal naar verwachting 60-120s zijn, zonder gegevensverlies. |
| Opslagfout | Toepassingen zien geen gevolgen voor opslaggerelateerde problemen, zoals een schijffout of een beschadiging van een fysiek blok. Omdat de gegevens in drie kopieën worden opgeslagen, wordt de kopie van de gegevens geleverd door de overlevende opslag. Het beschadigde gegevensblok wordt automatisch hersteld en er wordt automatisch een nieuwe kopie van de gegevens gemaakt. | Voor zeldzame en niet-herstelbare fouten, zoals de volledige opslag, is het flexibele serverexemplaren van Azure Database for PostgreSQL overgeschakeld naar de stand-byreplica om de downtime te verminderen. Zie de pagina concepten voor hoge beschikbaarheid voor meer informatie. |
| Logische/gebruikersfouten | Als u wilt herstellen van gebruikersfouten, zoals per ongeluk verwijderde tabellen of onjuist bijgewerkte gegevens, moet u een herstel naar een bepaald tijdstip (PITR) uitvoeren. Tijdens het uitvoeren van de herstelbewerking geeft u het aangepaste herstelpunt op. Dit is het tijdstip voordat de fout is opgetreden. Als u alleen een subset van databases of specifieke tabellen wilt herstellen in plaats van alle databases op de databaseserver, kunt u de databaseserver in een nieuw exemplaar herstellen, de tabel(s) exporteren via pg_dump en vervolgens pg_restore gebruiken om deze tabellen in uw database te herstellen. |
Deze gebruikersfouten worden niet beveiligd met hoge beschikbaarheid, omdat alle wijzigingen synchroon worden gerepliceerd naar de stand-byreplica. U moet herstel naar een bepaald tijdstip uitvoeren om te herstellen van dergelijke fouten. |
| Fout in beschikbaarheidszone | Als u wilt herstellen van een fout op zoneniveau, kunt u herstel naar een bepaald tijdstip uitvoeren met behulp van de back-up en een aangepast herstelpunt kiezen met de laatste tijd om de meest recente gegevens te herstellen. Een nieuw exemplaar van een flexibele Azure Database for PostgreSQL-server wordt geïmplementeerd in een andere niet-beïnvloede zone. De tijd die nodig is om te herstellen, is afhankelijk van de vorige back-up en het volume van transactielogboeken dat moet worden hersteld. | Flexibele Azure Database for PostgreSQL-server wordt automatisch overgeschakeld naar de stand-byserver binnen 60-120 en zonder gegevensverlies. Zie de pagina concepten voor hoge beschikbaarheid voor meer informatie. |
| Regiofout | Als uw server is geconfigureerd met geografisch redundante back-up, kunt u geo-herstel uitvoeren in de gekoppelde regio. Er wordt een nieuwe server ingericht en hersteld naar de laatst beschikbare gegevens die naar deze regio zijn gekopieerd. U kunt ook leesreplica's in meerdere regio's gebruiken. In het geval van een regiofout kunt u herstel na noodgevallen uitvoeren door uw leesreplica te promoveren tot een zelfstandige, leesbare server. RPO duurt naar verwachting maximaal 5 minuten (mogelijk gegevensverlies), behalve in het geval van ernstige regionale storingen wanneer de RPO zich op het moment van storing dicht bij de replicatievertraging kan bevinden. |
Hetzelfde proces. |
Uw database configureren na herstel na regionale fouten
- Als u geo-herstel of geo-replica gebruikt om te herstellen na een storing, moet u ervoor zorgen dat de verbinding met de nieuwe server correct is geconfigureerd, zodat de normale toepassingsfunctie kan worden hervat. U kunt de taken na het terugzetten volgen.
- Als u eerder een diagnostische instelling hebt ingesteld op de oorspronkelijke server, moet u zo nodig hetzelfde doen op de doelserver, zoals uitgelegd in Logboeken configureren en openen in Azure Database for PostgreSQL - Flexible Server.
- Telemetriewaarschuwingen instellen, moet u ervoor zorgen dat uw bestaande instellingen voor waarschuwingsregels worden bijgewerkt om toe te wijzen aan de nieuwe server. Zie De Azure-portal gebruiken om waarschuwingen in te stellen voor metrische gegevens voor Azure Database for PostgreSQL - Flexible Server voor meer informatie over waarschuwingsregels.
Belangrijk
Verwijderde servers kunnen worden hersteld. Als u de server verwijdert, kunt u onze richtlijnen volgen om een verwijderde Azure-database te herstellen - Azure Database for PostgreSQL - Flexible Server om te herstellen. Gebruik Azure-resourcevergrendeling om te voorkomen dat uw server per ongeluk wordt verwijderd.
Volgende stappen
- Meer informatie over implementatiemodellen met hoge beschikbaarheid
- Meer informatie over back-up en herstel
Feedback
Binnenkort beschikbaar: In de loop van 2024 zullen we GitHub-problemen geleidelijk uitfaseren als het feedbackmechanisme voor inhoud en deze vervangen door een nieuw feedbacksysteem. Zie voor meer informatie: https://aka.ms/ContentUserFeedback.
Feedback verzenden en weergeven voor