Bedrijfscontinuïteitsbeheer in Azure
Azure onderhoudt een van de meest volwassen en gerespecteerde beheerprogramma's voor bedrijfscontinuïteit in de branche. Het doel van bedrijfscontinuïteit in Azure is het bouwen en bevorderen van herstelbaarheid en tolerantie voor alle onafhankelijk herstelbare services, ongeacht of een service klantgericht is (onderdeel van een Azure-aanbieding) of een interne ondersteunende platformservice.
Bij het begrijpen van bedrijfscontinuïteit is het belangrijk om te weten dat veel aanbiedingen bestaan uit meerdere services. In Azure wordt elke service statisch geïdentificeerd via hulpprogramma's en is de maateenheid die wordt gebruikt voor privacy, beveiliging, inventaris, risicobeheer voor bedrijfscontinuïteit en andere functies. Om de mogelijkheden van een service goed te meten, worden de drie elementen van personen, processen en technologie opgenomen voor elke service, ongeacht het servicetype.
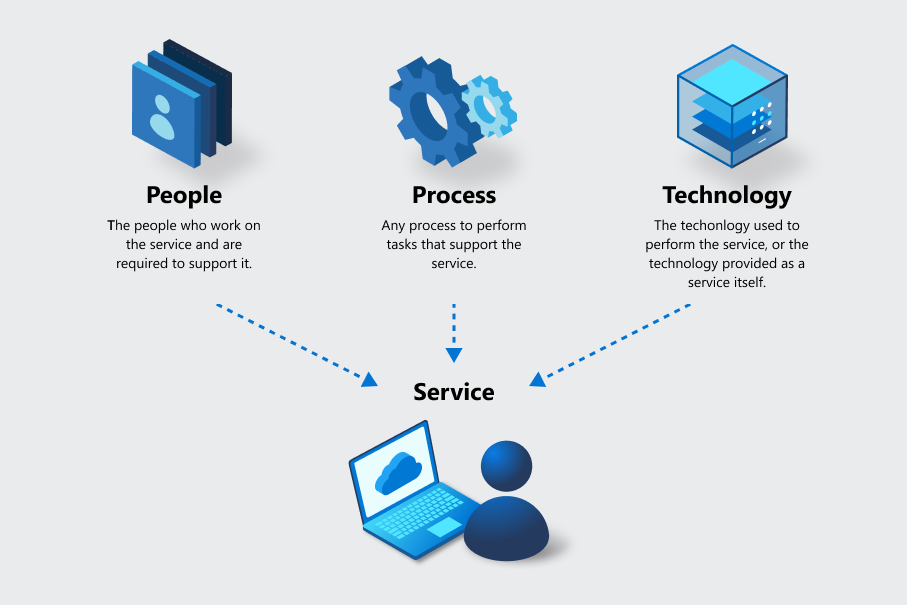
Bijvoorbeeld:
- Als er een bedrijfsproces is gebaseerd op personen, zoals een helpdesk of team, is de servicelevering wat ze doen. De mensen gebruiken processen en technologie om de service uit te voeren.
- Als er technologie als een service is, zoals Azure Virtual Machines, is de servicelevering de technologie, samen met de mensen en processen die ondersteuning bieden voor de werking ervan.
Model van gedeelde verantwoordelijkheid
Veel van de aanbiedingen van Azure vereisen dat u herstel na noodgevallen instelt in meerdere regio's en niet de verantwoordelijkheid van Microsoft bent. Niet alle Azure-services repliceren automatisch gegevens of vallen automatisch terug van een mislukte regio om kruislings te repliceren naar een andere ingeschakelde regio. In deze gevallen bent u verantwoordelijk voor het configureren van herstel en replicatie.
Microsoft zorgt ervoor dat de basisinfrastructuur en platformservices beschikbaar zijn. In sommige scenario's vraagt het gebruik echter om uw implementaties en opslag in een capaciteit voor meerdere regio's te dupliceren, als u dat wilt. Deze voorbeelden illustreren het model voor gedeelde verantwoordelijkheid. Het is een fundamentele pijler in uw strategie voor bedrijfscontinuïteit en herstel na noodgevallen.
Verdeling van verantwoordelijkheid
In elk on-premises datacenter bent u eigenaar van de hele stack. Wanneer u assets naar de cloud verplaatst, worden sommige verantwoordelijkheden overgedragen naar Microsoft. In het volgende diagram ziet u gebieden en de verdeling van de verantwoordelijkheid tussen u en Microsoft op basis van het type implementatie.
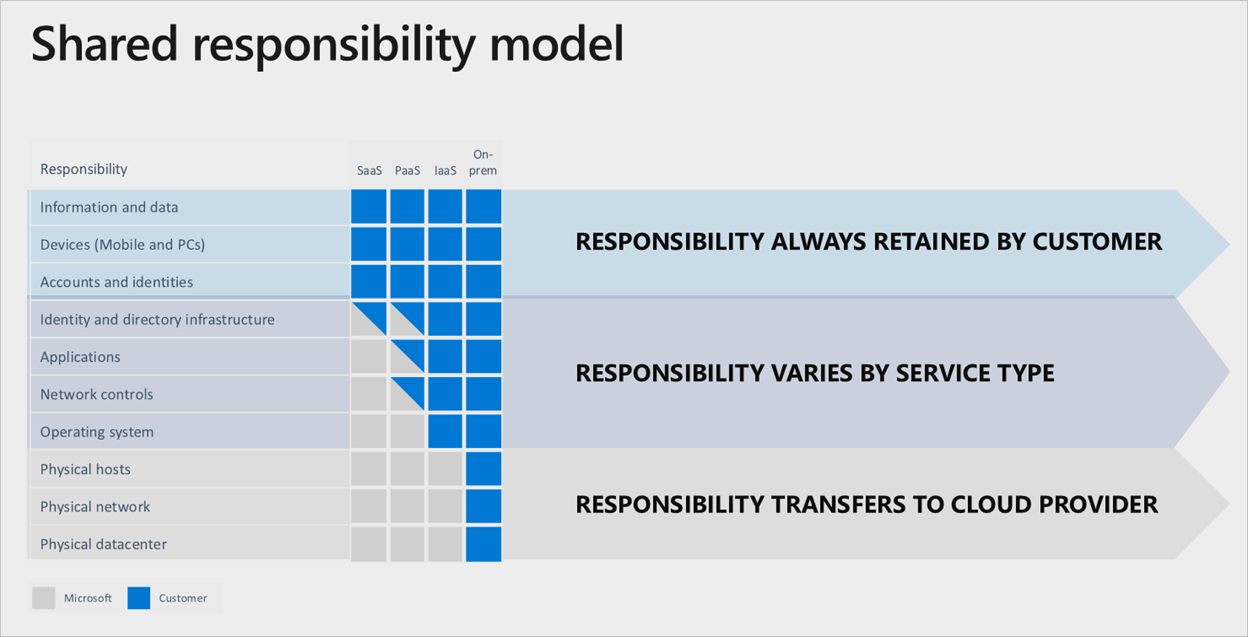
Een goed voorbeeld van het model voor gedeelde verantwoordelijkheid is de implementatie van virtuele machines. Als u replicatie tussen regio's wilt instellen voor tolerantie als er sprake is van een regiofout, moet u een dubbele set virtuele machines in een alternatieve regio implementeren. Azure repliceert deze services niet automatisch als er een fout opgetreden is. Het is uw verantwoordelijkheid om de benodigde assets te implementeren. U moet een proces hebben om primaire regio's handmatig te wijzigen, of u moet een Traffic Manager gebruiken om een failover te detecteren en automatisch uit te voeren.
Door de klant ingeschakelde services voor herstel na noodgevallen hebben allemaal openbare documentatie om u te helpen. Zie Azure Data Lake Analytics voor een voorbeeld van openbare documentatie voor herstel na noodgevallen waarvoor de klant is ingeschakeld.
Zie het Vertrouwenscentrum van Microsoft voor meer informatie over het model voor gedeelde verantwoordelijkheid.
Naleving van bedrijfscontinuïteit: verantwoordelijkheid op serviceniveau
Elke service is vereist om records voor bedrijfscontinuïteit na noodherstel te voltooien in het Azure Business Continuity Manager-hulpprogramma. Service-eigenaren kunnen het hulpprogramma gebruiken om binnen een federatief model te werken om vereisten te voltooien en op te nemen, waaronder:
Service-eigenschappen: definieert de service en hoe herstel na noodgevallen en tolerantie worden bereikt en identificeert de verantwoordelijke partij voor herstel na noodgevallen (voor technologie). Zie de discussie over het model voor gedeelde verantwoordelijkheid in de voorgaande sectie en het diagram voor meer informatie over het eigendom van het herstel.
Analyse van bedrijfsimpact: deze analyse helpt de service-eigenaar bij het definiëren van de beoogde hersteltijd (RTO) en de RPO (Recovery Point Objective) op basis van de ernst van de service in een tabel met gevolgen. Operationele, juridische, regelgeving, merkafbeelding en financiële impact worden gebruikt als doeldoelen voor herstel.
Notitie
Microsoft publiceert geen RTO of RTO's voor services, omdat deze gegevens alleen voor interne metingen zijn bedoeld. Alle beloftes en metingen van klanten zijn gebaseerd op een SLA, omdat deze betrekking heeft op een breder bereik versus RTO of RPO, wat alleen van toepassing is op catastrofaal verlies.
Afhankelijkheden: elke service wijst de afhankelijkheden (andere services) toe die nodig is om te werken, ongeacht hoe kritiek, en is toegewezen aan runtime, alleen nodig voor herstel of beide. Als er opslagafhankelijkheden zijn, worden andere gegevens toegewezen die bepalen wat er wordt opgeslagen en als er bijvoorbeeld momentopnamen van een bepaald tijdstip nodig zijn.
Personeel: Zoals vermeld in de definitie van een service, is het belangrijk om de locatie en hoeveelheid werknemers te kennen die de service kunnen ondersteunen, ervoor te zorgen dat er geen single points of failure worden gegarandeerd en als kritieke werknemers verspreid zijn om fouten te voorkomen door cohabitatie op één locatie.
Externe leveranciers: Microsoft houdt een uitgebreide lijst met externe leveranciers bij en de leveranciers die essentieel worden geacht, worden gemeten voor mogelijkheden. Als dit wordt geïdentificeerd door een service als een afhankelijkheid, worden de mogelijkheden van leveranciers vergeleken met de behoeften van de service om ervoor te zorgen dat een storing van derden azure-services niet verstoort.
Herstelclassificatie: deze classificatie is uniek voor het Azure Business Continuity Management-programma. Deze classificatie meet verschillende belangrijke elementen om een tolerantiescore te maken:
- De bereidheid om een failover uit te voeren: Hoewel er een proces kan zijn, is het mogelijk niet de eerste keuze voor storingen op korte termijn.
- Automatisering van failover.
- Automatisering van de beslissing om een failover uit te geven.
De meest betrouwbare en kortste tijd voor failover is een service die geautomatiseerd is en waarvoor geen menselijke beslissing nodig is. Een geautomatiseerde service maakt gebruik van heartbeat-bewaking of synthetische transacties om te bepalen dat een service niet beschikbaar is en om onmiddellijk herstel te starten.
Herstelplan en test: Azure vereist dat elke service een gedetailleerd herstelplan heeft en dat plan test alsof de service is mislukt vanwege een catastrofale storing. De herstelplannen moeten worden geschreven, zodat iemand met vergelijkbare vaardigheden en toegang de taken kan uitvoeren. Een schriftelijk plan voorkomt dat deskundigen op het gebied van onderwerp beschikbaar zijn.
Testen wordt op verschillende manieren uitgevoerd, waaronder zelftests in een productie- of bijna-productieomgeving, en als onderdeel van inzoomen in volledige regio in Azure in canary-regiosets. Deze ingeschakelde regio's zijn identiek aan productieregio's, maar kunnen worden uitgeschakeld zonder dat dit van invloed is op uw services. Testen wordt als geïntegreerd beschouwd omdat alle services tegelijkertijd worden beïnvloed.
Inschakeling van de klant: Wanneer u verantwoordelijk bent voor het instellen van herstel na noodgevallen, is Azure vereist om richtlijnen voor openbare documentatie te hebben. Voor al deze services worden koppelingen verstrekt naar documentatie en details over het proces.
De naleving van uw bedrijfscontinuïteit controleren
Wanneer een service de record voor bedrijfscontinuïteitsbeheer heeft voltooid, moet u deze ter goedkeuring indienen. Het is toegewezen aan een ervaren beroepsbeoefenaar voor bedrijfscontinuïteitsmanagement die de volledige record beoordeelt op volledigheid en kwaliteit. Als de record aan alle vereisten voldoet, wordt deze goedgekeurd. Als dit niet het probleem is, wordt het geweigerd met een verzoek om opnieuw te bewerken. Dit proces zorgt ervoor dat beide partijen ermee akkoord gaan dat aan naleving van bedrijfscontinuïteit is voldaan en dat het werk alleen door de service-eigenaar wordt getest. Interne audit- en complianceteams van Azure voeren ook periodieke willekeurige steekproeven uit om ervoor te zorgen dat de beste gegevens worden ingediend.
Testen van services
Microsoft en Azure voeren uitgebreide tests uit voor herstel na noodgevallen en voor gereedheid van beschikbaarheidszones. Services worden zelf getest in een productie- of preproductieomgeving om onafhankelijke herstelmogelijkheden te demonstreren voor services die niet afhankelijk zijn van belangrijke platformfailovers.
Om ervoor te zorgen dat services op dezelfde manier kunnen worden hersteld in een waar regio-down scenario, wordt 'pull-the-plug'-type testen uitgevoerd in canaire omgevingen die volledig zijn geïmplementeerd in regio's die overeenkomen met de productie. De clusters, rekken en energie-eenheden worden bijvoorbeeld letterlijk uitgeschakeld om een storing in de totale regio te simuleren.
Tijdens deze tests gebruikt Azure hetzelfde productieproces voor detectie, melding, reactie en herstel. Er zijn geen personen die een analyse verwachten en technici die afhankelijk zijn van herstel, zijn de normale on-call rotatiebronnen. Deze timing voorkomt, afhankelijk van deskundigen die mogelijk niet beschikbaar zijn tijdens een werkelijke gebeurtenis.
Opgenomen in deze tests zijn services waarbij u verantwoordelijk bent voor het instellen van herstel na noodgevallen volgens openbare documentatie van Microsoft. Serviceteams maken klantachtige exemplaren om aan te geven dat herstel na noodgevallen door de klant naar verwachting werkt en dat de verstrekte instructies nauwkeurig zijn.
Zie het Vertrouwenscentrum van Microsoft en de sectie over naleving voor meer informatie over certificeringen.