Capaciteit van een zoekservice schatten en beheren
In Azure AI Search is capaciteit gebaseerd op replica's en partities die kunnen worden geschaald naar uw workload. Replica's zijn kopieën van de zoekmachine. Partities zijn opslageenheden. Elke nieuwe zoekservice begint met één service, maar u kunt onafhankelijk replica's en partities toevoegen of verwijderen om te voldoen aan fluctuerende workloads. Door capaciteit toe te voegen, worden de kosten voor het uitvoeren van een zoekservice verhoogd.
De fysieke kenmerken van replica's en partities, zoals verwerkingssnelheid en schijf-IO, variëren per servicelaag. In een standaardzoekservice zijn de replica's en partities sneller en groter dan die van een basisservice.
Het wijzigen van de capaciteit is niet onmiddellijk. Het kan een uur duren voordat partities in gebruik worden genomen of buiten gebruik worden gesteld, met name voor services met grote hoeveelheden gegevens.
Wanneer u een zoekservice schaalt, kunt u kiezen uit de volgende hulpprogramma's en benaderingen:
Notitie
Partities met hogere capaciteit zijn beschikbaar tegen hetzelfde factureringstarief voor nieuwere services die na april en mei 2024 zijn gemaakt. Zie Servicelimieten voor upgrades van partitiegrootten voor meer informatie.
Concepten: zoekeenheden, replica's, partities
Capaciteit wordt uitgedrukt in zoekeenheden die kunnen worden toegewezen in combinaties van partities en replica's.
| Concept | Definitie |
|---|---|
| Zoekeenheid | Eén verhoging van de totale beschikbare capaciteit (36 eenheden). Het is ook de factureringseenheid voor een Azure AI-Search-service. Er is minimaal één eenheid vereist om de service uit te voeren. |
| Replica | Exemplaren van de zoekservice, die voornamelijk worden gebruikt om querybewerkingen te verdelen. Elke replica fungeert als host voor één exemplaar van een index. Als u drie replica's toewijst, hebt u drie kopieën van een index die beschikbaar is voor het uitvoeren van queryaanvragen. |
| Partitie | Fysieke opslag en I/O voor lees-/schrijfbewerkingen (bijvoorbeeld bij het herbouwen of vernieuwen van een index). Elke partitie heeft een segment van de totale index. Als u drie partities toewijst, wordt uw index onderverdeeld in derde partities. |
Controleer de partities en replicatabel voor mogelijke combinaties die onder de limiet van 36 eenheden blijven.
Wanneer moet u capaciteit toevoegen
In eerste instantie wordt aan een service een minimaal niveau van resources toegewezen dat bestaat uit één partitie en één replica. De laag die u kiest , bepaalt de partitiegrootte en -snelheid en elke laag wordt geoptimaliseerd rond een set kenmerken die geschikt zijn voor verschillende scenario's. Als u een hogere laag kiest, hebt u mogelijk minder partities nodig dan als u met S1 gaat. Een van de vragen die u moet beantwoorden via zelfgestuurd testen, is of een grotere en duurdere partitie betere prestaties oplevert dan twee goedkopere partities op een service die is ingericht op een lagere laag.
Eén service moet voldoende resources hebben om alle workloads (indexering en query's) af te handelen. Geen van beide werkbelastingen wordt op de achtergrond uitgevoerd. U kunt indexering plannen voor tijden waarin queryaanvragen natuurlijk minder vaak voorkomen, maar de service geeft anders geen prioriteit aan de ene taak boven de andere. Bovendien zorgt een bepaalde mate van redundantie ervoor dat de queryprestaties worden verzacht wanneer services of knooppunten intern worden bijgewerkt.
Enkele richtlijnen voor het bepalen of u capaciteit wilt toevoegen, zijn onder andere:
- Voldoen aan de criteria voor hoge beschikbaarheid voor service level agreement
- De frequentie van HTTP 503-fouten neemt toe
- Grote queryvolumes worden verwacht
In de regel hebben zoektoepassingen meestal meer replica's nodig dan partities, met name wanneer de servicebewerkingen worden bevooroordeeld voor queryworkloads. Elke replica is een kopie van uw index, zodat de service aanvragen kan verdelen over meerdere exemplaren. Alle taakverdeling en replicatie van een index worden beheerd door Azure AI Search en u kunt het aantal replica's dat is toegewezen voor uw service op elk gewenst moment wijzigen. U kunt maximaal 12 replica's toewijzen in een standaardzoekservice en 3 replica's in een Basic-zoekservice. Replicatoewijzing kan worden gemaakt vanuit Azure Portal of een van de programmatische opties.
Extra partities zijn handig voor intensieve indexeringsworkloads. Extra partities verspreiden lees-/schrijfbewerkingen over een groter aantal rekenresources.
Ten slotte duurt het langer om query's uit te voeren op grotere indexen. Als zodanig kan het zijn dat elke incrementele toename van partities een kleinere maar proportionele toename van replica's vereist. De complexiteit van uw query's en queryvolumes zal bepalen hoe snel query's worden uitgevoerd.
Notitie
Het toevoegen van meer replica's of partities verhoogt de kosten van het uitvoeren van de service en kan kleine variaties veroorzaken in de volgorde van resultaten. Controleer de prijscalculator om inzicht te krijgen in de gevolgen voor de facturering van het toevoegen van meer knooppunten. In de onderstaande grafiek kunt u kruislings verwijzen naar het aantal zoekeenheden dat nodig is voor een specifieke configuratie. Zie Orderresultaten voor meer informatie over hoe extra replica's van invloed zijn op de verwerking van query's.
Capaciteit wijzigen
Als u de capaciteit van uw zoekservice wilt vergroten of verkleinen, voegt u partities en replica's toe of verwijdert u deze.
Meld u aan bij Azure Portal en selecteer de zoekservice.
Open onder Instellingen de pagina Schaal om replica's en partities te wijzigen.
In de volgende schermopname ziet u een Standard-service die is ingericht met één replica en partitie. De formule onderaan geeft aan hoeveel zoekeenheden worden gebruikt (1). Als de eenheidsprijs $ 100 was (geen echte prijs), zou de maandelijkse kosten voor het uitvoeren van deze service gemiddeld $ 100 zijn.
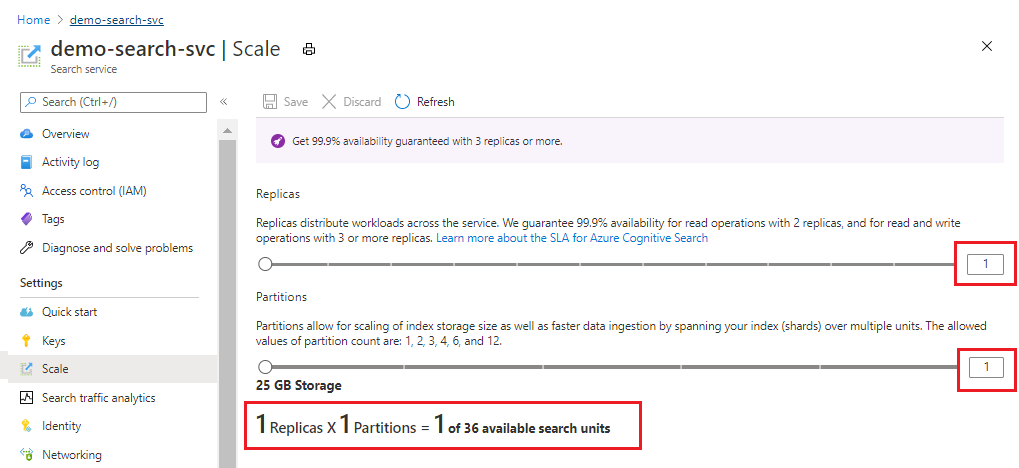
Gebruik de schuifregelaar om het aantal partities te vergroten of verkleinen. Selecteer Opslaan.
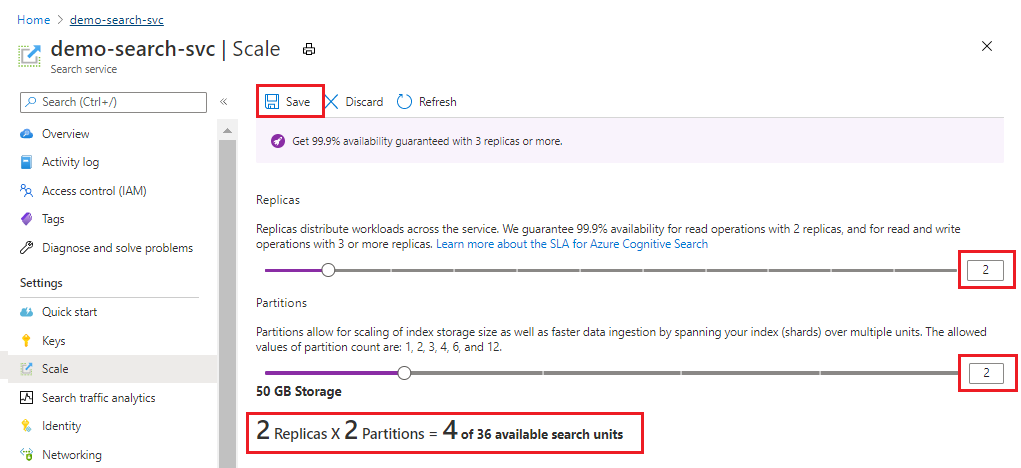
In dit voorbeeld wordt een tweede replica en partitie toegevoegd. Let op het aantal zoekeenheden; dit is nu vier omdat de factureringsformule replica's is vermenigvuldigd met partities (2 x 2). Verdubbeling van capaciteit meer dan verdubbelt de kosten voor het uitvoeren van de service. Als de kosten van de zoekeenheid $ 100 waren, zou de nieuwe maandelijkse factuur nu $ 400 zijn.
Ga naar de pagina Prijzen voor de huidige kosten per eenheid van elke laag.
Nadat u de bewerking hebt opgeslagen, kunt u de meldingen controleren om te bevestigen dat de actie is geslaagd.
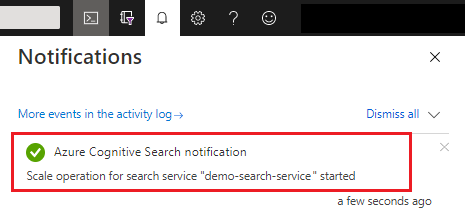
Het kan 15 minuten tot enkele uren duren voordat wijzigingen in de capaciteit zijn voltooid. U kunt niet annuleren nadat het proces is gestart en er is geen realtime bewaking voor replica- en partitieaanpassingen. Het volgende bericht blijft echter zichtbaar terwijl er wijzigingen worden doorgevoerd.

Notitie
Nadat een service is ingericht, kan deze niet worden bijgewerkt naar een hogere laag. U moet een zoekservice maken in de nieuwe laag en uw indexen opnieuw laden. Zie Een Azure AI-Search-service maken in de portal voor hulp bij het inrichten van services.
Hoe schaalaanvragen worden verwerkt
Na ontvangst van een schaalaanvraag, de zoekservice:
- Controleert of de aanvraag geldig is.
- Hiermee wordt een back-up gemaakt van gegevens en systeeminformatie.
- Controleert of de service al een inrichtingsstatus heeft (momenteel replica's of partities toevoegen of elimineren).
- Begint met inrichten.
Het schalen van een service kan maximaal 15 minuten of langer dan een uur duren, afhankelijk van de grootte van de service en het bereik van de aanvraag. Het maken van een back-up kan enkele minuten duren, afhankelijk van de hoeveelheid gegevens en het aantal partities en replica's.
De bovenstaande stappen zijn niet volledig opeenvolgend. Het systeem wordt bijvoorbeeld ingericht wanneer dit veilig kan, wat kan zijn wanneer de back-up afneemt.
Fouten tijdens het schalen
Het foutbericht 'Service-updatebewerkingen zijn op dit moment niet toegestaan omdat we een vorige aanvraag verwerken' wordt veroorzaakt door het herhalen van een aanvraag om omlaag of omhoog te schalen wanneer de service al een eerdere aanvraag verwerkt.
Los deze fout op door de servicestatus te controleren om de inrichtingsstatus te controleren:
- Gebruik de REST API voor beheer, Azure PowerShell of Azure CLI om de servicestatus op te halen.
- Roep Service ophalen (REST) of gelijkwaardig aan voor PowerShell of de CLI.
- Controleer het antwoord op 'provisioningState': 'provisioning'
Als de status Inrichten is, wacht u totdat de aanvraag is voltooid. De status moet 'Geslaagd' of 'Mislukt' zijn voordat een andere aanvraag wordt geprobeerd. Er is geen status voor back-up. Back-up is een interne bewerking en het is onwaarschijnlijk dat het een factor is bij elke onderbreking van een schaaloefening.
Als uw zoekservice in een inrichtingsstatus lijkt te zijn vastgelopen, controleert u op zwevende indexen die onbruikbaar zijn, met nul queryvolumes en geen indexupdates. Een onbruikbare index kan wijzigingen in de servicecapaciteit blokkeren. Zoek met name naar indexen die CMK-versleuteld zijn, waarvan de sleutels niet meer geldig zijn. U moet de index verwijderen of de sleutels herstellen om de index weer online te brengen en de schaalbewerking te deblokkeren.
Partitie- en replicacombinaties
De volgende grafiek is van toepassing op de Standard-laag en hoger. Het toont alle mogelijke combinaties van partities en replica's, afhankelijk van het maximum van 36 zoekeenheden per service.
| 1 partitie | 2 partities | 3 partities | 4 partities | 6 partities | 12 partities | |
|---|---|---|---|---|---|---|
| 1 replica | 1 SU | 2 SU | 3 SU | 4 SU | 6 SU | 12 SU |
| 2 replica's | 2 SU | 4 SU | 6 SU | 8 SU | 12 SU | 24 SU |
| 3 replica's | 3 SU | 6 SU | 9 SU | 12 SU | 18 SU | 36 SU |
| 4 replica's | 4 SU | 8 SU | 12 SU | 16 SU | 24 SU | N.v.t. |
| 5 replica's | 5 SU | 10 SU | 15 SU | 20 SU | 30 SU | N.v.t. |
| 6 replica's | 6 SU | 12 SU | 18 SU | 24 SU | 36 SU | N.v.t. |
| 12 replica's | 12 SU | 24 SU | 36 SU | N.v.t. | N.v.t. | N.v.t. |
Basiszoekservices hebben lagere aantallen zoekeenheden.
Bij zoekservices die vóór 3 april 2024 zijn gemaakt, kan een eenvoudige zoekservice precies één partitie en maximaal drie replica's hebben, voor een maximumlimiet van drie RU's. De enige aanpasbare resource is replica's.
Bij zoekservices die zijn gemaakt na 3 april 2024 in ondersteunde regio's, kunnen basisservices maximaal drie partities en drie replica's hebben. De maximale SU-limiet is negen ter ondersteuning van een volledige aanvulling op partities en replica's.
Voor zoekservices op een factureerbare laag, ongeacht de aanmaakdatum, hebt u minimaal twee replica's nodig voor hoge beschikbaarheid voor query's.
Zie de pagina met prijzen voor Azure AI Search voor factureringstarieven per laag en valuta.
Capaciteit schatten met behulp van een factureerbare laag
Opslagbehoeften worden bepaald door de grootte van de indexen die u verwacht te bouwen. Er zijn geen solide heuristieken of generaliteiten die helpen bij schattingen. De enige manier om de grootte van een index te bepalen, is een index maken. De grootte ervan is gebaseerd op tokenisatie en insluitingen, en of u suggesties, filteren en sorteren inschakelt of gebruik kunt maken van vectorcompressie.
U wordt aangeraden een schatting te maken van een factureerbare laag, Basic of hoger. De gratis laag wordt uitgevoerd op fysieke resources die door meerdere klanten worden gedeeld en is onderhevig aan factoren die buiten uw beheer vallen. Alleen de toegewezen resources van een factureerbare zoekservice kunnen tijdens de ontwikkeling grotere steekproeven en verwerkingstijden bieden voor realistischere schattingen van de indexhoeveelheid, grootte en queryvolumes.
Controleer servicelimieten op elke laag om te bepalen of lagere lagen het aantal indexen kunnen ondersteunen dat u nodig hebt. Overweeg of u meerdere kopieën van een index nodig hebt voor actieve ontwikkeling, testen en productie.
Een zoekservice is onderhevig aan objectlimieten (maximum aantal indexen, indexeerfuncties, vaardighedensets, enzovoort) en opslaglimieten. Welke limiet het eerst wordt bereikt, is de effectieve limiet.
Maak een service in een factureerbare laag. Lagen zijn geoptimaliseerd voor bepaalde workloads. De laag Geoptimaliseerd voor opslag heeft bijvoorbeeld een limiet van 10 indexen, omdat deze is ontworpen om een laag aantal zeer grote indexen te ondersteunen.
Begin laag, bij Basic of S1, als u niet zeker weet wat de verwachte belasting is.
Start hoog, bij S2 of zelfs S3, als het testen grootschalige indexering en querybelastingen omvat.
Begin met Geoptimaliseerd voor opslag, bij L1 of L2, als u een grote hoeveelheid gegevens indexeert en querybelasting relatief laag is, net als bij een interne bedrijfstoepassing.
Bouw een initiële index om te bepalen hoe brongegevens worden omgezet in een index. Dit is de enige manier om de indexgrootte te schatten. Kenmerken van de velddefinities zijn van invloed op fysieke opslagvereisten:
Voor trefwoorden zoeken vergroot het markeren van velden als filterbaar en sorteerbaar de indexgrootte.
Voor vectorzoekopdrachten kunt u parameters instellen om de opslag te verminderen.
Bewaak opslag, servicelimieten, queryvolume en latentie in de portal. In de portal ziet u query's per seconde, beperkte query's en zoeklatentie. Al deze waarden kunnen u helpen beslissen of u de juiste laag hebt geselecteerd.
Voeg replica's toe voor hoge beschikbaarheid of om trage queryprestaties te beperken.
Er zijn geen richtlijnen voor het aantal replica's dat nodig is voor het laden van query's. Queryprestaties zijn afhankelijk van de complexiteit van de query en concurrerende workloads. Hoewel het toevoegen van replica's duidelijk resulteert in betere prestaties, is het resultaat niet strikt lineair: het toevoegen van drie replica's garandeert geen drievoudige doorvoer. Zie Prestaties analyseren en query's bewaken voor hulp bij het schatten van QPS voor uw oplossing.
Voor een omgekeerde index wordt de grootte en complexiteit bepaald door inhoud, niet noodzakelijkerwijs door de hoeveelheid gegevens die u erin invoert. Een grote gegevensbron met hoge redundantie kan leiden tot een kleinere index dan een kleinere gegevensset die zeer variabele inhoud bevat. Het is dus zelden mogelijk om de indexgrootte af te stellen op basis van de grootte van de oorspronkelijke gegevensset.
Opslagvereisten kunnen worden vergroot als u gegevens opneemt die nooit worden doorzocht. In het ideale voorbeeld bevatten documenten alleen de gegevens die u nodig hebt voor de zoekervaring.
Overwegingen voor serviceovereenkomsten
De gratis laag en preview-functies vallen niet onder serviceovereenkomsten (SLA's). Voor alle factureerbare lagen worden SLA's van kracht wanneer u voldoende redundantie voor uw service inricht.
Twee of meer replica's voldoen aan query-SLA's (lezen).
Drie of meer replica's voldoen aan query- en indexerings-SLA's (read-write).
Het aantal partities heeft geen invloed op SLA's.
Volgende stappen
Feedback
Binnenkort beschikbaar: In de loop van 2024 zullen we GitHub-problemen geleidelijk uitfaseren als het feedbackmechanisme voor inhoud en deze vervangen door een nieuw feedbacksysteem. Zie voor meer informatie: https://aka.ms/ContentUserFeedback.
Feedback verzenden en weergeven voor