Kusto-querytaal in Microsoft Sentinel
Kusto-querytaal is de taal die u gebruikt om met gegevens in Microsoft Sentinel te werken en te bewerken. De logboeken die u in uw werkruimte invoert, zijn niet veel waard als u ze niet kunt analyseren en de belangrijke informatie in al die gegevens kunt ophalen. Kusto-querytaal heeft niet alleen de kracht en flexibiliteit om die informatie op te halen, maar de eenvoud om snel aan de slag te gaan. Als u een achtergrond hebt in het uitvoeren van scripts of het werken met databases, zult u veel van de inhoud van dit artikel vertrouwd voelen. Als dat niet het probleem is, maakt u zich geen zorgen, omdat u snel met de intuïtieve aard van de taal uw eigen query's kunt schrijven en waarde kunt aansturen voor uw organisatie.
In dit artikel worden de basisbeginselen van Kusto-querytaal geïntroduceerd, die betrekking hebben op een aantal van de meest gebruikte functies en operators, die 75 tot 80 procent van de query's moeten aanpakken die u dagelijks schrijft. Wanneer u meer diepte nodig hebt of meer geavanceerde query's wilt uitvoeren, kunt u profiteren van de nieuwe geavanceerde KQL voor Microsoft Sentinel-werkmap (zie dit inleidende blogbericht). Zie ook de officiële Kusto-querytaal documentatie en een verscheidenheid aan online cursussen (zoals Pluralsight).
Achtergrond- Waarom Kusto-querytaal?
Microsoft Sentinel is gebouwd op basis van de Azure Monitor-service en maakt gebruik van de Log Analytics-werkruimten van Azure Monitor om alle gegevens op te slaan. Deze gegevens omvatten een van de volgende:
- gegevens die zijn opgenomen uit externe bronnen in vooraf gedefinieerde tabellen met behulp van Microsoft Sentinel-gegevensconnectors.
- gegevens die zijn opgenomen uit externe bronnen in door de gebruiker gedefinieerde aangepaste tabellen, met behulp van aangepaste gegevensconnectors en sommige typen out-of-the-box-connectors.
- gegevens die door Microsoft Sentinel zelf zijn gemaakt, als gevolg van de analyses die worden gemaakt en uitgevoerd, zoals waarschuwingen, incidenten en UEBA-gerelateerde informatie.
- gegevens die zijn geüpload naar Microsoft Sentinel om u te helpen bij detectie en analyse, bijvoorbeeld feeds voor bedreigingsinformatie en volglijsten.
Kusto-querytaal is ontwikkeld als onderdeel van de Azure Data Explorer-service en is daarom geoptimaliseerd voor het zoeken naar big data-archieven in een cloudomgeving. Geïnspireerd door beroemde onderzeese ontdekkingsreiziger Jacques Cousteau (en uitgesproken als "koo-STOH"), is het ontworpen om u te helpen diep in uw oceanen met gegevens te duiken en hun verborgen schatten te verkennen.
Kusto-querytaal wordt ook gebruikt in Azure Monitor (en daarom in Microsoft Sentinel), inclusief enkele extra Azure Monitor-functies, waarmee u gegevens kunt ophalen, visualiseren, analyseren en parseren in Log Analytics-gegevensarchieven. In Microsoft Sentinel gebruikt u hulpprogramma's op basis van Kusto-querytaal wanneer u gegevens visualiseert en analyseert en zoekt naar bedreigingen, ongeacht in bestaande regels en werkmappen, of bij het bouwen van uw eigen regels en werkmappen.
Omdat Kusto-querytaal deel uitmaakt van bijna alles wat u doet in Microsoft Sentinel, kunt u duidelijk begrijpen hoe het werkt, zodat u zoveel meer uit uw SIEM kunt halen.
Wat is een query?
Een Kusto-querytaal-query is een alleen-lezenaanvraag voor het verwerken van gegevens en het retourneren van resultaten. Er worden geen gegevens geschreven. Query's worden uitgevoerd op gegevens die zijn ingedeeld in een hiërarchie van databases, tabellen en kolommen, vergelijkbaar met SQL.
Aanvragen worden in gewone taal vermeld en maken gebruik van een gegevensstroommodel dat is ontworpen om de syntaxis gemakkelijk te lezen, te schrijven en te automatiseren. We zien dit in detail.
Kusto-querytaal query's bestaan uit instructies gescheiden door puntkomma's. Er zijn veel soorten instructies, maar slechts twee veelgebruikte typen die we hier bespreken:
tabellaire expressie-instructies zijn wat we doorgaans bedoelen wanneer we het hebben over query's. Dit zijn de werkelijke hoofdtekst van de query. Het belangrijkste om te weten over instructies voor tabellaire expressies is dat ze een tabellaire invoer (een tabel of een andere tabellaire expressie) accepteren en een tabellaire uitvoer produceren. Ten minste één van deze is vereist. De meeste van de rest van dit artikel zullen dit soort beweringen bespreken.
met instructies kunt u variabelen en constanten buiten de hoofdtekst van de query maken en definiëren, voor eenvoudiger leesbaarheid en veelzijdigheid. Deze zijn optioneel en zijn afhankelijk van uw specifieke behoeften. Aan het einde van het artikel behandelen we dit soort instructies.
Demo-omgeving
U kunt oefenen met Kusto-querytaal instructies, inclusief de instructies in dit artikel, in een Log Analytics-demo-omgeving in Azure Portal. Er worden geen kosten in rekening gebracht voor het gebruik van deze oefenomgeving, maar u hebt wel een Azure-account nodig om er toegang toe te krijgen.
Verken de demo-omgeving. Net als Log Analytics in uw productieomgeving kan het op verschillende manieren worden gebruikt:
Kies een tabel waarop u een query wilt maken. Selecteer op het tabblad Standaardtabellen (weergegeven in de rode rechthoek linksboven) een tabel in de lijst met tabellen gegroepeerd op onderwerpen (linksonder). Vouw de onderwerpen uit om de afzonderlijke tabellen weer te geven en u kunt elke tabel verder uitvouwen om alle velden (kolommen) ervan weer te geven. Als u dubbelklikt op een tabel of een veldnaam, wordt deze op het punt van de cursor in het queryvenster geplaatst. Typ de rest van de query volgens de tabelnaam, zoals hieronder wordt beschreven.
Zoek een bestaande query om te bestuderen of te wijzigen. Selecteer het tabblad Query's (weergegeven in de rode rechthoek linksboven) om een lijst weer te geven met query's die standaard beschikbaar zijn. Of selecteer query's in de knopbalk rechtsboven. U kunt de query's verkennen die standaard worden geleverd met Microsoft Sentinel. Als u dubbelklikt op een query, wordt de hele query in het queryvenster op het punt van de cursor weergegeven.
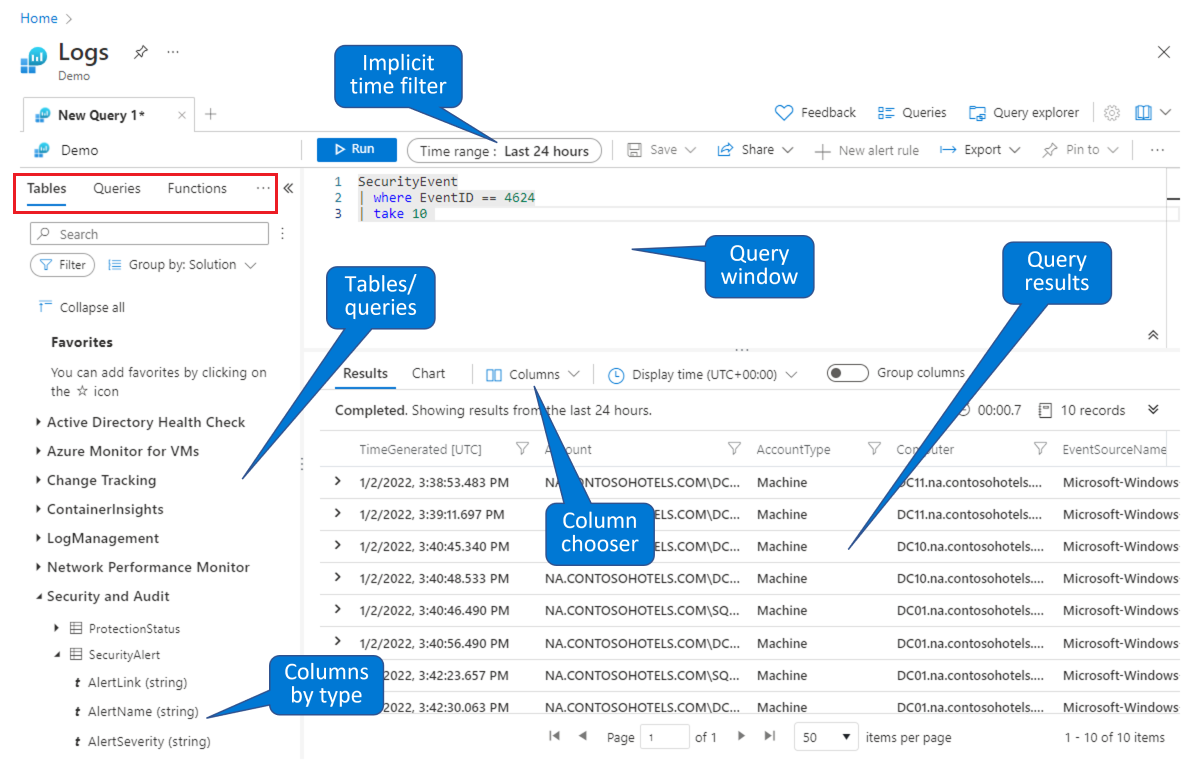
Net als in deze demo-omgeving kunt u gegevens opvragen en filteren op de pagina Microsoft Sentinel-logboeken. U kunt een tabel selecteren en inzoomen om kolommen weer te geven. U kunt de standaardkolommen wijzigen die worden weergegeven met de kolomkiezer en u kunt het standaardtijdbereik voor query's instellen. Als het tijdsbereik expliciet is gedefinieerd in de query, is het tijdfilter niet beschikbaar (grijs weergegeven).
Querystructuur
Een goede plek om te leren Kusto-querytaal is om inzicht te hebben in de algehele querystructuur. Het eerste wat u ziet wanneer u een Kusto-query bekijkt, is het gebruik van het pijpsymbool (|). De structuur van een Kusto-query begint met het ophalen van uw gegevens uit een gegevensbron en geeft vervolgens de gegevens door aan een 'pijplijn' en elke stap biedt een bepaald verwerkingsniveau en geeft vervolgens de gegevens door aan de volgende stap. Aan het einde van de pijplijn krijgt u het uiteindelijke resultaat. In feite is dit onze pijplijn:
Get Data | Filter | Summarize | Sort | Select
Dit concept van het doorgeven van gegevens in de pijplijn zorgt voor een zeer intuïtieve structuur, omdat het eenvoudig is om bij elke stap een mentale afbeelding van uw gegevens te maken.
Laten we hier eens kijken naar de volgende query, waarin de aanmeldingslogboeken van Microsoft Entra worden bekeken. Terwijl u elke regel doorloopt, ziet u de trefwoorden die aangeven wat er met de gegevens gebeurt. We hebben de relevante fase in de pijplijn opgenomen als opmerking in elke regel.
Notitie
U kunt opmerkingen toevoegen aan elke regel in een query door ze vooraf te laten gaan met een dubbele slash (//).
SigninLogs // Get data
| evaluate bag_unpack(LocationDetails) // Ignore this line for now; we'll come back to it at the end.
| where RiskLevelDuringSignIn == 'none' // Filter
and TimeGenerated >= ago(7d) // Filter
| summarize Count = count() by city // Summarize
| sort by Count desc // Sort
| take 5 // Select
Omdat de uitvoer van elke stap fungeert als invoer voor de volgende stap, kan de volgorde van de stappen de resultaten van de query bepalen en de prestaties ervan beïnvloeden. Het is van cruciaal belang dat u de stappen bestelt op basis van wat u uit de query wilt halen.
Fooi
- Een goede vuistregel is om uw gegevens vroeg te filteren, zodat u alleen relevante gegevens in de pijplijn doorgeeft. Dit verhoogt de prestaties aanzienlijk en zorgt ervoor dat u niet per ongeluk irrelevante gegevens in samenvattingsstappen opneemt.
- In dit artikel worden enkele andere aanbevolen procedures beschreven om rekening mee te houden. Zie best practices voor query's voor een volledigere lijst.
Hopelijk hebt u nu een waardering voor de algehele structuur van een query in Kusto-querytaal. Laten we nu eens kijken naar de werkelijke queryoperators zelf, die worden gebruikt om een query te maken.
Data types
Voordat we de queryoperators gaan gebruiken, gaan we eerst eens kijken naar gegevenstypen. Net als in de meeste talen bepaalt het gegevenstype welke berekeningen en manipulaties kunnen worden uitgevoerd op een waarde. Als u bijvoorbeeld een waarde hebt die van het type tekenreeks is, kunt u er geen rekenkundige berekeningen mee uitvoeren.
In Kusto-querytaal volgen de meeste gegevenstypen standaardconventies en hebben namen die u waarschijnlijk eerder hebt gezien. In de volgende tabel ziet u de volledige lijst:
Gegevenstypetabel
| Type | Aanvullende naam of namen | Equivalent .NET-type |
|---|---|---|
bool |
Boolean |
System.Boolean |
datetime |
Date |
System.DateTime |
dynamic |
System.Object |
|
guid |
uuid, uniqueid |
System.Guid |
int |
System.Int32 |
|
long |
System.Int64 |
|
real |
Double |
System.Double |
string |
System.String |
|
timespan |
Time |
System.TimeSpan |
decimal |
System.Data.SqlTypes.SqlDecimal |
Hoewel de meeste gegevenstypen standaard zijn, bent u mogelijk minder bekend met typen zoals dynamische, tijdspanne en guid.
Dynamisch heeft een structuur die vergelijkbaar is met JSON, maar met één belangrijk verschil: het kan Kusto-querytaal-specifieke gegevenstypen opslaan die traditionele JSON niet kan, zoals een geneste dynamische waarde of tijdspanne. Hier volgt een voorbeeld van een dynamisch type:
{
"countryOrRegion":"US",
"geoCoordinates": {
"longitude":-122.12094116210936,
"latitude":47.68050003051758
},
"state":"Washington",
"city":"Redmond"
}
Tijdspanne is een gegevenstype dat verwijst naar een meting van tijd, zoals uren, dagen of seconden. Verwar tijdsperiode niet met datum/tijd, die resulteert in een werkelijke datum en tijd, niet meting van tijd. In de volgende tabel ziet u een lijst met tijdspanachtervoegsels .
Tijdspanachtervoegsels
| Functie | Omschrijving |
|---|---|
D |
dagen |
H |
uur |
M |
minutes |
S |
seconden |
Ms |
milliseconden |
Microsecond |
Microseconden |
Tick |
nanoseconden |
Guid is een gegevenstype dat een 128-bits, globaal unieke id vertegenwoordigt, die de standaardindeling van [8]-[4]-[4]-[4]-[12] vertegenwoordigt, waarbij elk [getal] het aantal tekens aangeeft en elk teken kan variëren van 0-9 of a-f.
Notitie
Kusto-querytaal heeft zowel tabellaire als scalaire operatoren. Als u in de rest van dit artikel gewoon het woord operator ziet, kunt u ervan uitgaan dat dit een tabellaire operator betekent, tenzij anders vermeld.
Gegevens ophalen, beperken, sorteren en filteren
Het belangrijkste vocabulaire van Kusto-querytaal - de basis waarmee u het overgrote deel van uw taken kunt uitvoeren - is een verzameling operators voor het filteren, sorteren en selecteren van uw gegevens. Voor de resterende taken die u moet uitvoeren, moet u uw kennis van de taal uitrekken om te voldoen aan uw geavanceerdere behoeften. Laten we een paar opdrachten uitvouwen die we in ons bovenstaande voorbeeld hebben gebruikt en kijken takenaar , sorten where.
Voor elk van deze operators bekijken we het gebruik ervan in ons vorige voorbeeld van SigninLogs en leren we een handige tip of een best practice.
Gegevens ophalen
De eerste regel van een basisquery geeft aan met welke tabel u wilt werken. In het geval van Microsoft Sentinel is dit waarschijnlijk de naam van een logboektype in uw werkruimte, zoals SigninLogs, SecurityAlert of CommonSecurityLog. Bijvoorbeeld:
SigninLogs
Houd er rekening mee dat logboeknamen in Kusto-querytaal hoofdlettergevoelig zijn en SigninLogs signinLogs dus anders worden geïnterpreteerd. Wees voorzichtig bij het kiezen van namen voor uw aangepaste logboeken, zodat ze gemakkelijk kunnen worden geïdentificeerd en niet te vergelijkbaar zijn met een ander logboek.
Gegevens beperken: limiet aannemen /
De operator take (en de identieke operator voor limieten ) wordt gebruikt om uw resultaten te beperken door slechts een bepaald aantal rijen te retourneren. Het wordt gevolgd door een geheel getal dat het aantal rijen aangeeft dat moet worden geretourneerd. Normaal gesproken wordt deze gebruikt aan het einde van een query nadat u de sorteervolgorde hebt bepaald. In dat geval wordt het opgegeven aantal rijen boven aan de gesorteerde volgorde geretourneerd.
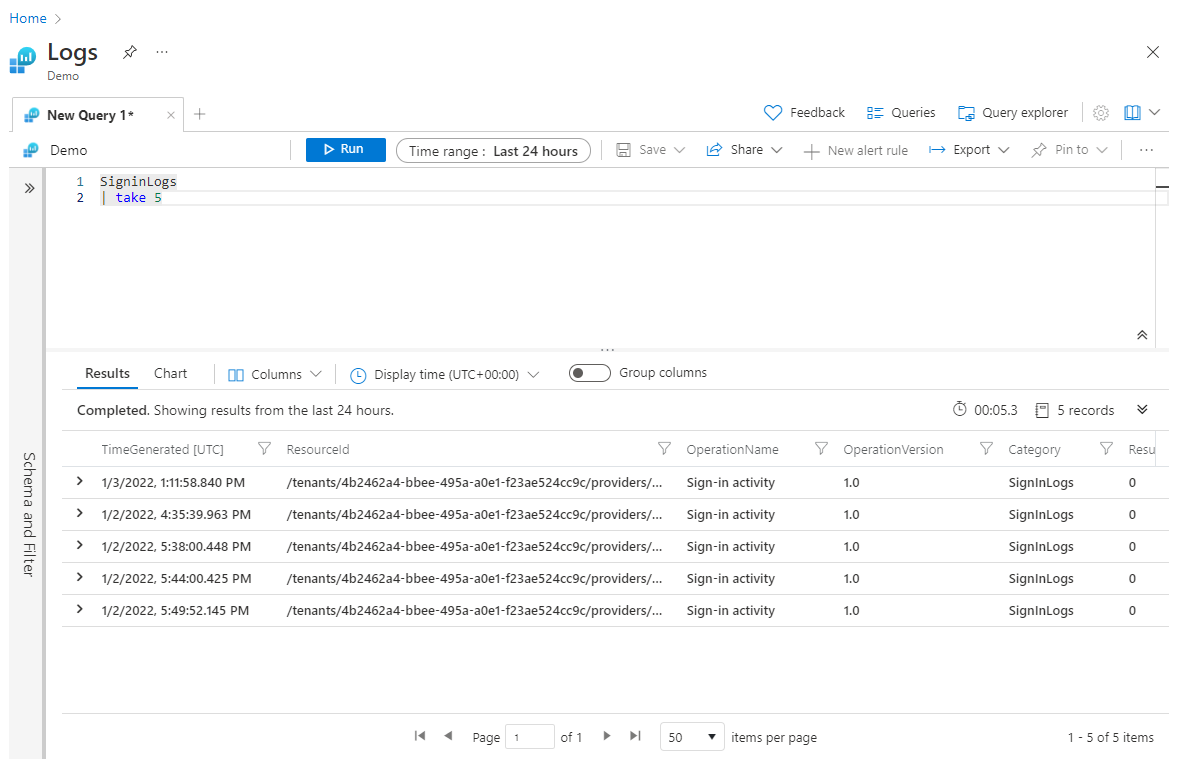
Het gebruik van take eerder in de query kan handig zijn voor het testen van een query wanneer u geen grote gegevenssets wilt retourneren. Als u de take bewerking echter plaatst voordat sort er bewerkingen worden uitgevoerd, worden rijen die willekeurig zijn geselecteerd, en mogelijk een andere set rijen telkens wanneer de query wordt uitgevoerd, take geretourneerd. Hier volgt een voorbeeld van het gebruik van take:
SigninLogs
| take 5
Fooi
Wanneer u aan een gloednieuwe query werkt, waar u mogelijk niet weet hoe de query eruitziet, kan het handig zijn om een take instructie aan het begin te plaatsen om uw gegevensset kunstmatig te beperken voor snellere verwerking en experimenten. Zodra u tevreden bent met de volledige query, kunt u de eerste take stap verwijderen.
Gegevens sorteren: sorteervolgorde /
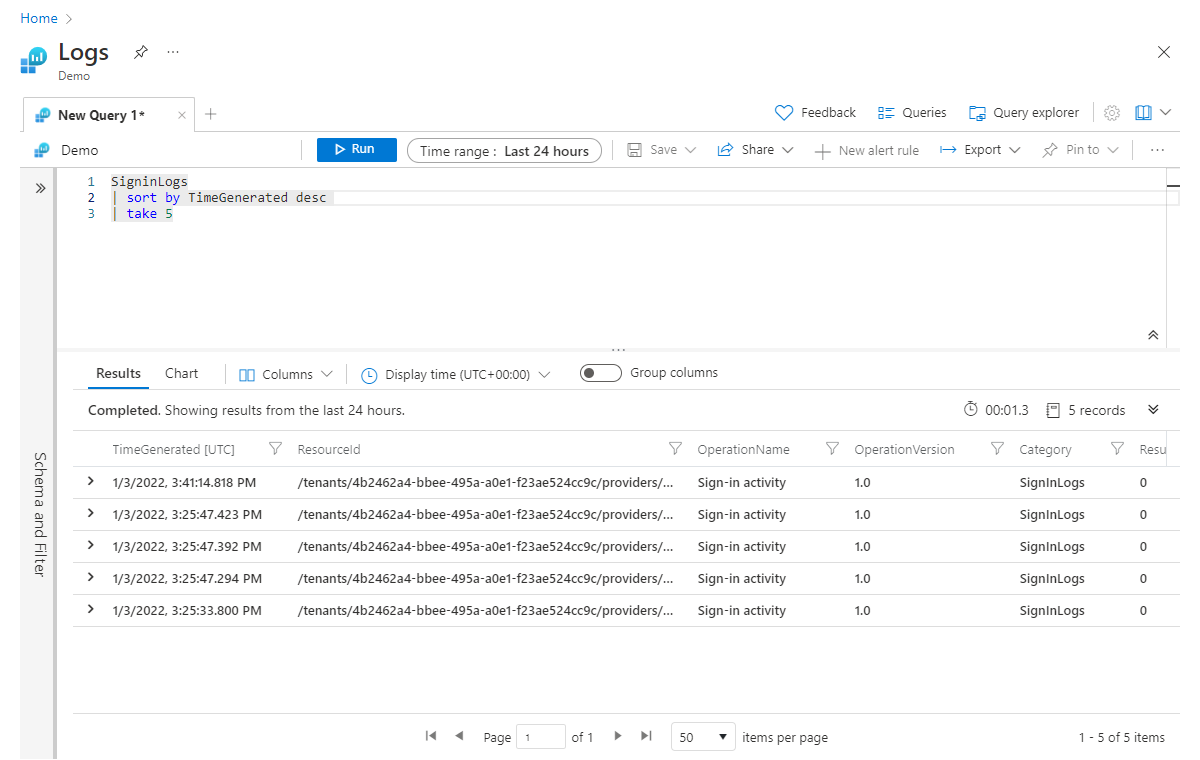
De sorteeroperator (en de identieke orderoperator ) wordt gebruikt om uw gegevens te sorteren op een opgegeven kolom. In het volgende voorbeeld hebben we de resultaten gesorteerd op TimeGenerated en de volgorderichting ingesteld op aflopend met de desc-parameter, waarbij de hoogste waarden eerst worden geplaatst; voor oplopende volgorde zouden we asc gebruiken.
Notitie
De standaardrichting voor sorteringen is aflopend, dus technisch gezien hoeft u alleen op te geven of u in oplopende volgorde wilt sorteren. Als u echter de sorteerrichting opgeeft, kan uw query beter leesbaar worden.
SigninLogs
| sort by TimeGenerated desc
| take 5
Zoals we al zeiden, plaatsen we de sort operator vóór de take operator. We moeten eerst sorteren om ervoor te zorgen dat we de juiste vijf records krijgen.
Top
Met de bovenste operator kunnen we de sort en take bewerkingen combineren tot één operator:
SigninLogs
| top 5 by TimeGenerated desc
In gevallen waarin twee of meer records dezelfde waarde hebben in de kolom waarop u sorteert, kunt u meer kolommen toevoegen om op te sorteren. Voeg extra sorteerkolommen toe in een door komma's gescheiden lijst, die zich na de eerste sorteerkolom bevindt, maar vóór het trefwoord sorteervolgorde. Bijvoorbeeld:
SigninLogs
| sort by TimeGenerated, Identity desc
| take 5
Als TimeGenerated nu hetzelfde is tussen meerdere records, wordt geprobeerd om te sorteren op de waarde in de kolom Identiteit.
Notitie
Wanneer te gebruiken sort en take, en wanneer te gebruiken top
Als u slechts op één veld sorteert, gebruikt
topu , omdat het betere prestaties biedt dan de combinatie vansortentake.Als u wilt sorteren op meer dan één veld (zoals in het vorige voorbeeld hierboven),
topkunt u dat niet doen, dus moet u gebruikensortentake.
Gegevens filteren: waar
De operator waar de belangrijkste operator is, omdat het de sleutel is om ervoor te zorgen dat u alleen werkt met de subset gegevens die relevant zijn voor uw scenario. U moet uw best doen om uw gegevens zo vroeg mogelijk in de query te filteren, omdat hierdoor de prestaties van query's worden verbeterd door de hoeveelheid gegevens te verminderen die in de volgende stappen moet worden verwerkt; het zorgt er ook voor dat u alleen berekeningen uitvoert op de gewenste gegevens. Zie dit voorbeeld:
SigninLogs
| where TimeGenerated >= ago(7d)
| sort by TimeGenerated, Identity desc
| take 5
De where operator geeft een variabele, een vergelijkingsoperator (scalaire) en een waarde op. In ons geval geven >= we aan dat de waarde in de kolom TimeGenerated groter moet zijn dan (dat wil gezegd, later dan) of gelijk aan zeven dagen geleden.
Er zijn twee typen vergelijkingsoperatoren in Kusto-querytaal: tekenreeks en numeriek. In de volgende tabel ziet u de volledige lijst met numerieke operatoren:
Numerieke operators
| Operator | Omschrijving |
|---|---|
+ |
Aanvullend |
- |
Aftrekken |
* |
Vermenigvuldigen |
/ |
Divisie |
% |
Modulo |
< |
Kleiner dan |
> |
Groter dan |
== |
Gelijk aan |
!= |
Niet gelijk aan |
<= |
Kleiner dan of gelijk aan |
>= |
Groter dan of gelijk aan |
in |
Gelijk aan een van de elementen |
!in |
Niet gelijk aan een van de elementen |
De lijst met tekenreeksoperators is een veel langere lijst omdat deze permutaties heeft voor hoofdlettergevoeligheid, subtekenreekslocaties, voorvoegsels, achtervoegsels en nog veel meer. De == operator is zowel een numerieke operator als een tekenreeksoperator, wat betekent dat deze kan worden gebruikt voor zowel getallen als tekst. Beide van de volgende instructies zijn bijvoorbeeld geldig wanneer de instructies:
| where ResultType == 0| where Category == 'SignInLogs'
Fooi
Best Practice: In de meeste gevallen wilt u uw gegevens waarschijnlijk filteren op meer dan één kolom of op meerdere manieren dezelfde kolom filteren. In deze gevallen zijn er twee best practices waar u rekening mee moet houden.
U kunt meerdere where instructies combineren in één stap met behulp van het en trefwoord. Bijvoorbeeld:
SigninLogs
| where Resource == ResourceGroup
and TimeGenerated >= ago(7d)
Wanneer u meerdere filters hebt samengevoegd in één where instructie met behulp van het en trefwoord, zoals hierboven, krijgt u betere prestaties door filters te plaatsen die slechts naar één kolom verwijzen. Dus een betere manier om de bovenstaande query te schrijven, is:
SigninLogs
| where TimeGenerated >= ago(7d)
and Resource == ResourceGroup
In dit voorbeeld vermeldt het eerste filter één kolom (TimeGenerated), terwijl de tweede verwijst naar twee kolommen (Resource en ResourceGroup).
Gegevens samenvatten
Samenvatten is een van de belangrijkste operatoren in tabelvorm in Kusto-querytaal, maar het is ook een van de complexere operatoren om te leren als u geen querytalen in het algemeen hebt. De taak summarize is om een tabel met gegevens op te nemen en een nieuwe tabel uit te voeren die wordt geaggregeerd door een of meer kolommen.
Structuur van de samenvattingsinstructie
De basisstructuur van een summarize instructie is als volgt:
| summarize <aggregation> by <column>
Het volgende retourneert bijvoorbeeld het aantal records voor elke CounterName-waarde in de tabel Perf :
Perf
| summarize count() by CounterName
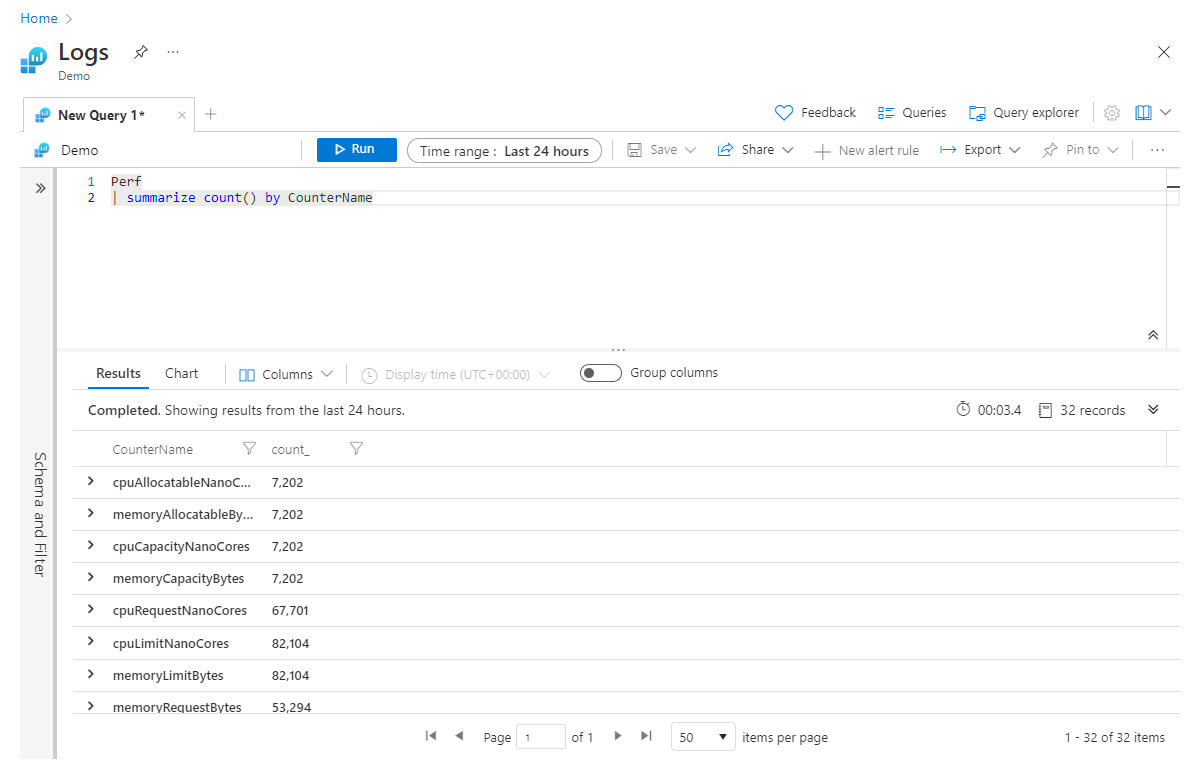
Omdat de uitvoer van summarize een nieuwe tabel is, worden kolommen die niet expliciet in de summarize instructie zijn opgegeven, niet doorgegeven aan de pijplijn. Bekijk dit voorbeeld om dit concept te illustreren:
Perf
| project ObjectName, CounterValue, CounterName
| summarize count() by CounterName
| sort by ObjectName asc
Op de tweede regel geven we aan dat we alleen om de kolommen ObjectName, CounterValue en CounterName geven. Vervolgens zijn we samengevat om het aantal records op te halen op CounterName en ten slotte proberen we de gegevens in oplopende volgorde te sorteren op basis van de kolom ObjectName . Helaas mislukt deze query met een fout (wat aangeeft dat objectnaam onbekend is) omdat we bij samenvatten alleen de kolommen Count en CounterName in onze nieuwe tabel hebben opgenomen. Om deze fout te voorkomen, kunnen we gewoon ObjectName toevoegen aan het einde van de summarize stap, zoals deze:
Perf
| project ObjectName, CounterValue , CounterName
| summarize count() by CounterName, ObjectName
| sort by ObjectName asc
De manier om de summarize lijn in uw hoofd te lezen, is: 'een overzicht van het aantal records per CounterName en groeperen op ObjectName'. U kunt doorgaan met het toevoegen van kolommen, gescheiden door komma's, aan het einde van de summarize instructie.
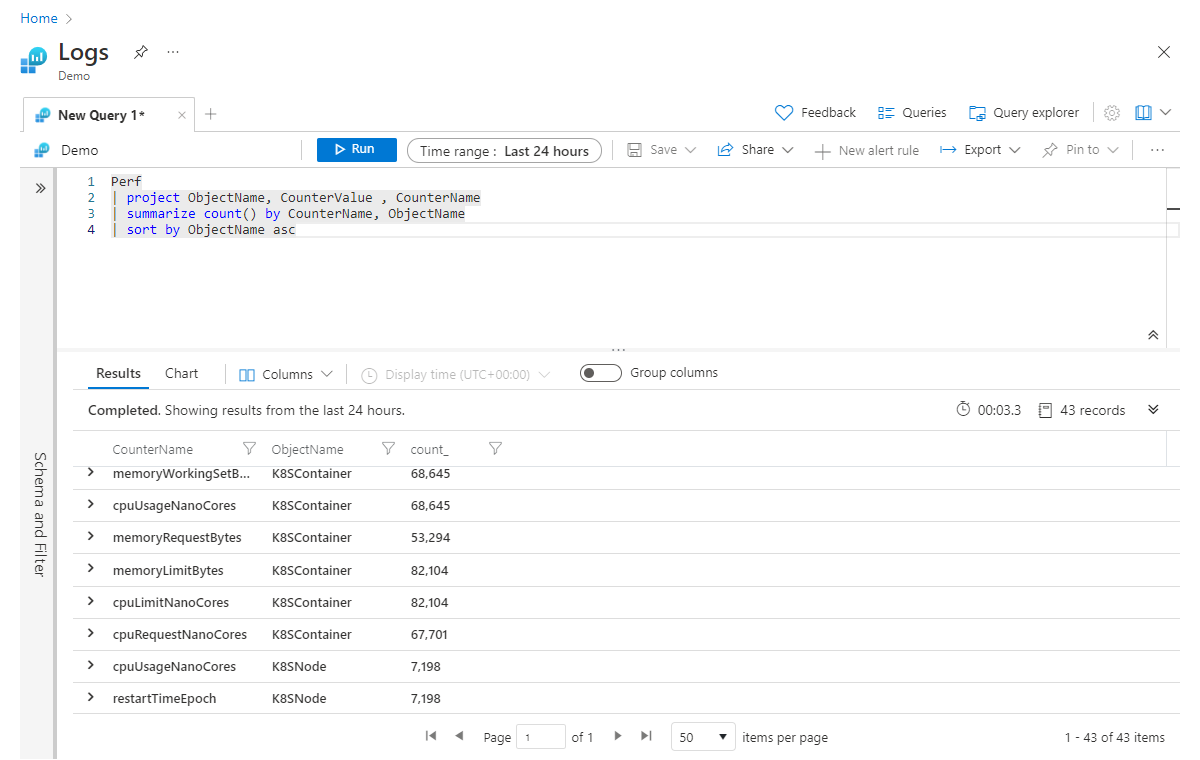
Als we op basis van het vorige voorbeeld meerdere kolommen tegelijk willen aggregeren, kunnen we dit bereiken door aggregaties toe te voegen aan de summarize operator, gescheiden door komma's. In het onderstaande voorbeeld krijgen we niet alleen een telling van alle records, maar ook een som van de waarden in de kolom CounterValue voor alle records (die overeenkomen met filters in de query):
Perf
| project ObjectName, CounterValue , CounterName
| summarize count(), sum(CounterValue) by CounterName, ObjectName
| sort by ObjectName asc
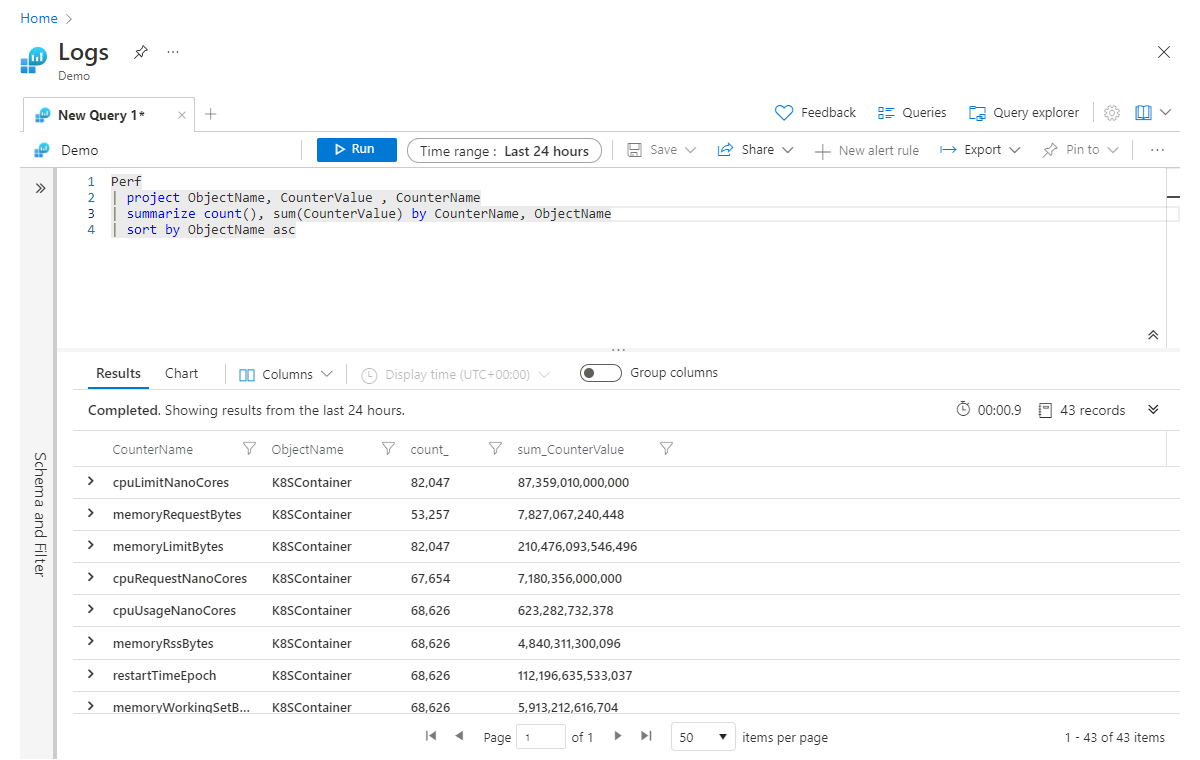
De naam van samengevoegde kolommen wijzigen
Dit lijkt een goed moment om te praten over kolomnamen voor deze samengevoegde kolommen. Aan het begin van deze sectie hebben we gezegd dat de summarize operator een tabel met gegevens inneemt en een nieuwe tabel produceert. Alleen de kolommen die u in de summarize instructie opgeeft, gaan verder in de pijplijn. Als u het bovenstaande voorbeeld zou uitvoeren, zijn de resulterende kolommen voor onze aggregatie daarom count_ en sum_CounterValue.
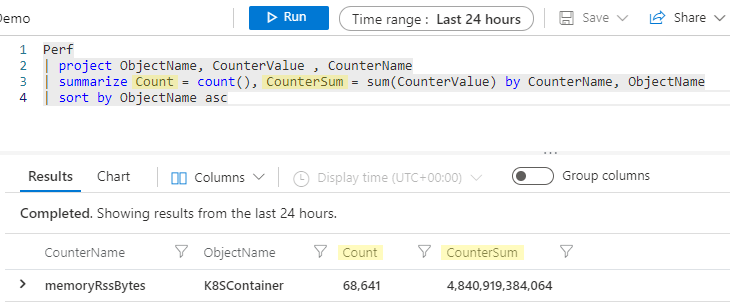
De Kusto-engine maakt automatisch een kolomnaam zonder dat we expliciet hoeven te zijn, maar vaak zult u merken dat u de voorkeur geeft aan uw nieuwe kolom met een meer beschrijvende naam. U kunt de naam van de kolom in de summarize instructie eenvoudig wijzigen door een nieuwe naam op te geven, gevolgd door = en de aggregatie, zoals:
Perf
| project ObjectName, CounterValue , CounterName
| summarize Count = count(), CounterSum = sum(CounterValue) by CounterName, ObjectName
| sort by ObjectName asc
Nu krijgen onze samengevatte kolommen de naam Count en CounterSum.
Er is veel meer voor de summarize operator dan we hier kunnen bespreken, maar u moet de tijd investeren om dit te leren omdat het een belangrijk onderdeel is van elke gegevensanalyse die u wilt uitvoeren op uw Microsoft Sentinel-gegevens.
Aggregatiereferentie
De zijn veel aggregatiefuncties, maar sommige van de meest gebruikte zijn sum(), count()en avg(). Hier volgt een gedeeltelijke lijst (zie de volledige lijst):
Aggregatiefuncties
| Functie | Omschrijving |
|---|---|
arg_max() |
Retourneert een of meer expressies wanneer het argument is gemaximaliseerd |
arg_min() |
Retourneert een of meer expressies wanneer het argument wordt geminimaliseerd |
avg() |
Retourneert de gemiddelde waarde in de groep |
buildschema() |
Retourneert het minimale schema dat alle waarden van de dynamische invoer toekent |
count() |
Geeft als resultaat het aantal groepen |
countif() |
Geeft als resultaat het aantal met het predicaat van de groep |
dcount() |
Retourneert bij benadering het aantal afzonderlijke elementen van de groep |
make_bag() |
Retourneert een eigenschapsverzameling met dynamische waarden binnen de groep |
make_list() |
Retourneert een lijst met alle waarden in de groep |
make_set() |
Retourneert een set afzonderlijke waarden binnen de groep |
max() |
Retourneert de maximumwaarde in de groep |
min() |
Retourneert de minimumwaarde in de groep |
percentiles() |
Geeft als resultaat het percentiel bij benadering van de groep |
stdev() |
Retourneert de standaarddeviatie in de groep |
sum() |
Geeft als resultaat de som van de elementen in de groep |
take_any() |
Retourneert een willekeurige niet-lege waarde voor de groep |
variance() |
Geeft als resultaat de variantie in de groep |
Selecteren: kolommen toevoegen en verwijderen
Naarmate u meer met query's gaat werken, is het mogelijk dat u meer informatie hebt dan u nodig hebt voor uw onderwerpen (dat wil gezegd, te veel kolommen in uw tabel). Of mogelijk hebt u meer informatie nodig dan u hebt (dat wil gezegd, moet u een nieuwe kolom toevoegen die de resultaten van de analyse van andere kolommen bevat). Laten we eens kijken naar een paar van de sleuteloperators voor kolombewerking.
Project en project-afwezig
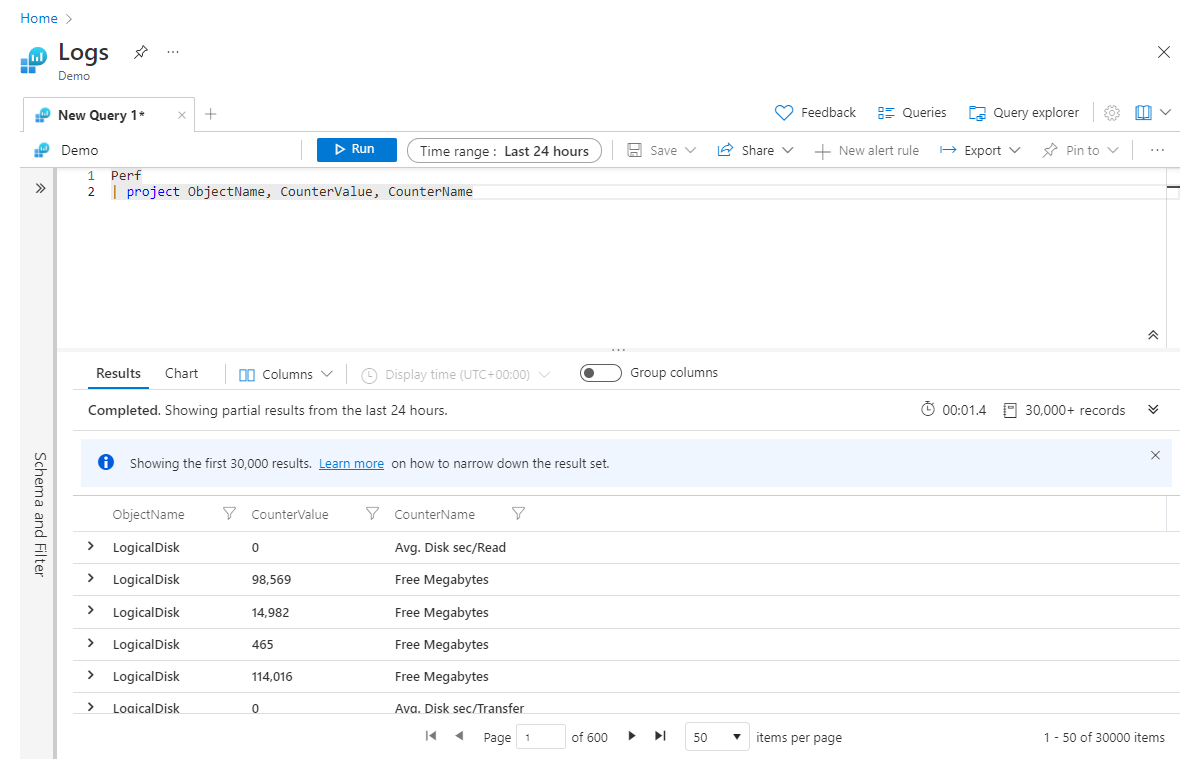
Project is ongeveer gelijk aan de select-instructies van veel talen. Hiermee kunt u kiezen welke kolommen u wilt behouden. De volgorde van de geretourneerde kolommen komt overeen met de volgorde van de kolommen die u in uw project instructie opneemt, zoals wordt weergegeven in dit voorbeeld:
Perf
| project ObjectName, CounterValue, CounterName
Zoals u zich kunt voorstellen, hebt u, wanneer u met zeer brede gegevenssets werkt, mogelijk veel kolommen die u wilt behouden en moet u ze allemaal op naam opgeven. Voor deze gevallen hebt u project-afwezig, waarmee u kunt opgeven welke kolommen moeten worden verwijderd, in plaats van welke kolommen u wilt behouden, zoals:
Perf
| project-away MG, _ResourceId, Type
Fooi
Het kan handig zijn om te gebruiken project op twee locaties in uw query's, aan het begin en opnieuw aan het einde. Door project vroeg in uw query te gebruiken, kunt u de prestaties verbeteren door grote stukken gegevens weg te halen die u niet nodig hebt om de pijplijn door te geven. Door deze opnieuw aan het einde te gebruiken, kunt u alle kolommen verwijderen die mogelijk in de vorige stappen zijn gemaakt en die niet nodig zijn in de uiteindelijke uitvoer.
Uitbreiden
Uitbreiden wordt gebruikt om een nieuwe berekende kolom te maken. Dit kan handig zijn als u een berekening wilt uitvoeren op basis van bestaande kolommen en de uitvoer voor elke rij wilt bekijken. Laten we eens kijken naar een eenvoudig voorbeeld waarin we een nieuwe kolom met de naam Kbytes berekenen, die we kunnen berekenen door de MB-waarde (in de bestaande kolom Hoeveelheid ) te vermenigvuldigen met 1024.
Usage
| where QuantityUnit == 'MBytes'
| extend KBytes = Quantity * 1024
| project ResourceUri, MBytes=Quantity, KBytes
Op de laatste regel in onze project instructie hebben we de naam van de kolom Hoeveelheid gewijzigd in Mbytes, zodat we eenvoudig kunnen zien welke maateenheid relevant is voor elke kolom.
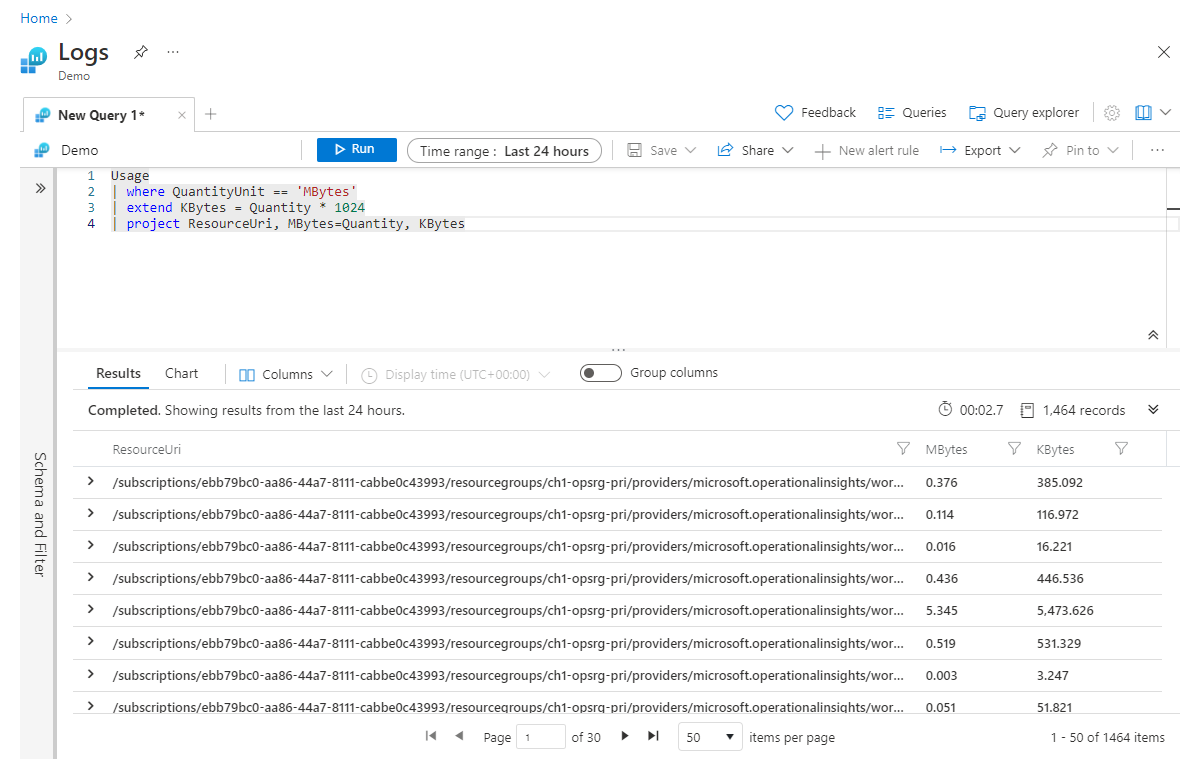
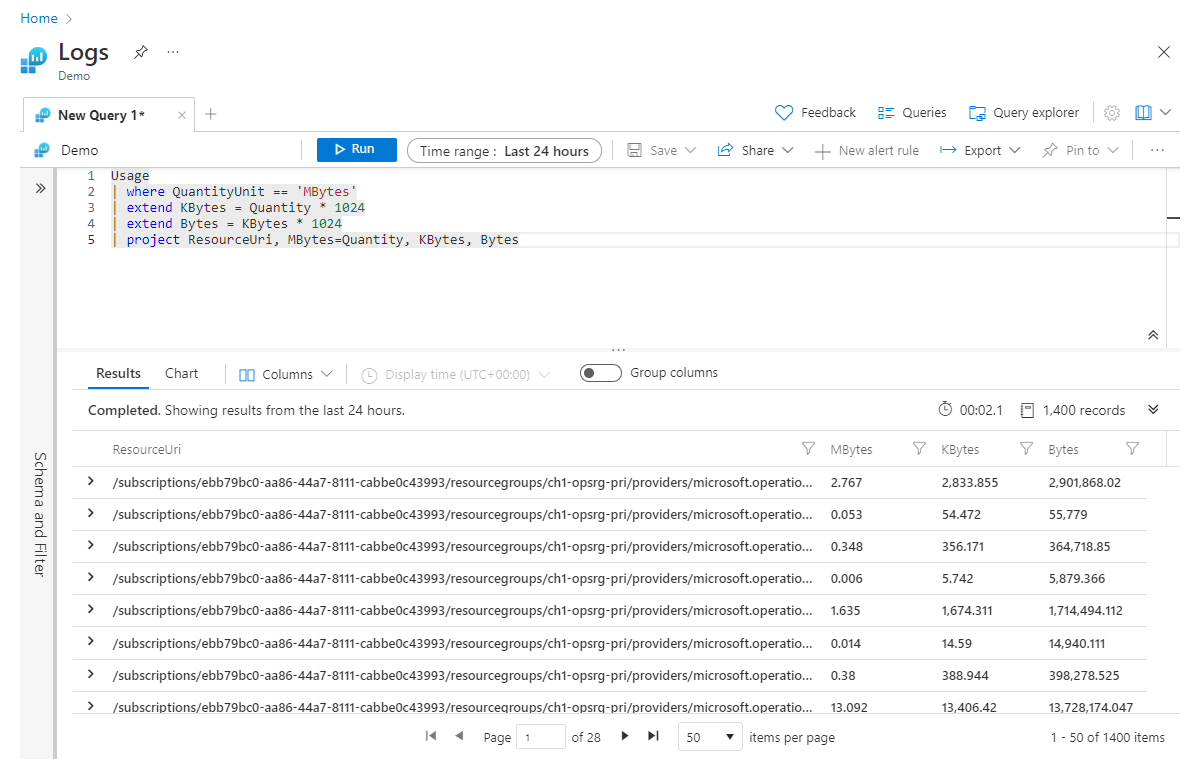
Het is de moeite waard om te noteren dat extend ook werkt met al berekende kolommen. We kunnen bijvoorbeeld nog een kolom met de naam Bytes toevoegen die wordt berekend op basis van Kbytes:
Usage
| where QuantityUnit == 'MBytes'
| extend KBytes = Quantity * 1024
| extend Bytes = KBytes * 1024
| project ResourceUri, MBytes=Quantity, KBytes, Bytes
Tabellen samenvoegen
Veel van uw werk in Microsoft Sentinel kan worden uitgevoerd met één logboektype, maar er zijn momenten waarop u gegevens wilt correleren of een zoekactie wilt uitvoeren op een andere set gegevens. Net als bij de meeste querytalen biedt Kusto-querytaal enkele operators die worden gebruikt om verschillende typen joins uit te voeren. In deze sectie bekijken we de meest gebruikte operators en union join.
Unie
Union gebruikt gewoon twee of meer tabellen en retourneert alle rijen. Bijvoorbeeld:
OfficeActivity
| union SecurityEvent
Hiermee worden alle rijen uit de tabellen OfficeActivity en SecurityEvent geretourneerd. Union biedt enkele parameters die kunnen worden gebruikt om aan te passen hoe de samenvoeging zich gedraagt. Twee van de nuttigste zijn metsource en soort:
OfficeActivity
| union withsource = SourceTable kind = inner SecurityEvent
Met de parameter withsource kunt u de naam opgeven van een nieuwe kolom waarvan de waarde in een bepaalde rij de naam is van de tabel waaruit de rij is gekomen. In het bovenstaande voorbeeld hebben we de kolom SourceTable genoemd. Afhankelijk van de rij is de waarde OfficeActivity of SecurityEvent.
De andere parameter die we hebben opgegeven, was vriendelijk, die twee opties heeft: inner of outer. In het bovenstaande voorbeeld hebben we inner opgegeven, wat betekent dat de enige kolommen die tijdens de samenvoeging worden bewaard, de kolommen zijn die in beide tabellen aanwezig zijn. Als we ook buiten hebben opgegeven (de standaardwaarde), worden alle kolommen uit beide tabellen geretourneerd.
Join
Join werkt op dezelfde manier unionals , behalve in plaats van tabellen samen te voegen om een nieuwe tabel te maken, voegen we rijen samen om een nieuwe tabel te maken. Net als bij de meeste databasetalen zijn er meerdere typen joins die u kunt uitvoeren. De algemene syntaxis voor een join is:
T1
| join kind = <join type>
(
T2
) on $left.<T1Column> == $right.<T2Column>
Na de join operator geven we het type join op dat we willen uitvoeren, gevolgd door een open haakje. Binnen de haakjes geeft u de tabel op die u wilt samenvoegen, evenals eventuele andere queryinstructies voor die tabel die u wilt toevoegen. Na het haakje sluiten gebruiken we het trefwoord gevolgd door links ($left).<columnName-trefwoord> ) en rechts ($right.<columnName>) kolommen gescheiden door de operator ==. Hier volgt een voorbeeld van een inner join:
OfficeActivity
| where TimeGenerated >= ago(1d)
and LogonUserSid != ''
| join kind = inner (
SecurityEvent
| where TimeGenerated >= ago(1d)
and SubjectUserSid != ''
) on $left.LogonUserSid == $right.SubjectUserSid
Notitie
Als beide tabellen dezelfde naam hebben voor de kolommen waarop u een join uitvoert, hoeft u in plaats daarvan niet $left en $right te gebruiken. In plaats daarvan kunt u gewoon de kolomnaam opgeven. Het gebruik van $left en $right is echter explicieter en wordt over het algemeen beschouwd als een goede gewoonte.
Ter referentie bevat de volgende tabel een lijst met beschikbare typen joins.
Typen joins
| Jointype | Omschrijving |
|---|---|
inner |
Retourneert één voor elke combinatie van overeenkomende rijen uit beide tabellen. |
innerunique |
Retourneert rijen uit de linkertabel met afzonderlijke waarden in gekoppeld veld die een overeenkomst hebben in de rechtertabel. Dit is het standaard niet-opgegeven jointype. |
leftsemi |
Retourneert alle records uit de linkertabel met een overeenkomst in de rechtertabel. Alleen kolommen uit de linkertabel worden geretourneerd. |
rightsemi |
Retourneert alle records uit de rechtertabel die een overeenkomst hebben in de linkertabel. Alleen kolommen uit de rechtertabel worden geretourneerd. |
leftanti/leftantisemi |
Retourneert alle records uit de linkertabel die geen overeenkomst hebben in de rechtertabel. Alleen kolommen uit de linkertabel worden geretourneerd. |
rightanti/rightantisemi |
Retourneert alle records uit de rechtertabel die geen overeenkomst hebben in de linkertabel. Alleen kolommen uit de rechtertabel worden geretourneerd. |
leftouter |
Retourneert alle records uit de linkertabel. Voor records die geen overeenkomst hebben in de rechtertabel, zijn celwaarden null. |
rightouter |
Retourneert alle records uit de juiste tabel. Voor records die geen overeenkomst hebben in de linkertabel, zijn celwaarden null. |
fullouter |
Retourneert alle records uit zowel linker- als rechtertabellen, overeenkomende of niet. Niet-overeenkomende waarden zijn null. |
Fooi
Het is een best practice om uw kleinste tafel aan de linkerkant te hebben. In sommige gevallen kan het volgen van deze regel u enorme prestatievoordelen bieden, afhankelijk van de typen joins die u uitvoert en de grootte van de tabellen.
Evalueren
U herinnert zich misschien dat we in het eerste voorbeeld de evaluatieoperator op een van de regels hebben gezien. De evaluate operator wordt minder vaak gebruikt dan de operatoren die we eerder hebben aangeraakt. Maar weten hoe de evaluate operator werkt, is uw tijd waard. Nogmaals, hier is die eerste query, waar u op de tweede regel ziet evaluate .
SigninLogs
| evaluate bag_unpack(LocationDetails)
| where RiskLevelDuringSignIn == 'none'
and TimeGenerated >= ago(7d)
| summarize Count = count() by city
| sort by Count desc
| take 5
Met deze operator kunt u beschikbare invoegtoepassingen aanroepen (in principe ingebouwde functies). Veel van deze invoegtoepassingen zijn gericht op gegevenswetenschap, zoals autoclusters, diffpatterns en sequence_detect, zodat u geavanceerde analyses kunt uitvoeren en statistische afwijkingen en uitbijters kunt detecteren.
De invoegtoepassing die in het bovenstaande voorbeeld werd gebruikt, werd bag_unpack genoemd en het maakt het heel eenvoudig om een segment van dynamische gegevens te nemen en te converteren naar kolommen. Houd er rekening mee dat dynamische gegevens een gegevenstype zijn dat er vergelijkbaar is met JSON, zoals wordt weergegeven in dit voorbeeld:
{
"countryOrRegion":"US",
"geoCoordinates": {
"longitude":-122.12094116210936,
"latitude":47.68050003051758
},
"state":"Washington",
"city":"Redmond"
}
In dit geval willen we de gegevens samenvatten op plaats, maar plaats is opgenomen als een eigenschap in de kolom LocationDetails . Als u de eigenschap Plaats in de query wilt gebruiken, moesten we deze eerst converteren naar een kolom met behulp van bag_unpack.
Als we teruggaan naar onze oorspronkelijke pijplijnstappen, hebben we dit gezien:
Get Data | Filter | Summarize | Sort | Select
Nu we de evaluate operator hebben overwogen, kunnen we zien dat deze een nieuwe fase in de pijplijn vertegenwoordigt. Deze ziet er nu als volgt uit:
Get Data | Parse | Filter | Summarize | Sort | Select
Er zijn veel andere voorbeelden van operators en functies die kunnen worden gebruikt om gegevensbronnen te parseren in een beter leesbare en bemanbare indeling. In de volledige documentatie en in de werkmap vindt u hier meer informatie over en de rest van de Kusto-querytaal.
Let-instructies
Nu we veel van de belangrijkste operators en gegevenstypen hebben behandeld, gaan we de let-instructie inpakken. Dit is een uitstekende manier om uw query's gemakkelijker te lezen, te bewerken en te onderhouden.
Hiermee kunt u een variabele maken en instellen of een naam toewijzen aan een expressie. Deze expressie kan één waarde zijn, maar kan ook een hele query zijn. Hier volgt een eenvoudig voorbeeld:
let aWeekAgo = ago(7d);
SigninLogs
| where TimeGenerated >= aWeekAgo
Hier hebben we een naam van aWeekAgo opgegeven en ingesteld dat deze gelijk is aan de uitvoer van een tijdspannefunctie , die een datum/tijd-waarde retourneert. Vervolgens beëindigen we de let-instructie met een puntkomma. Nu hebben we een nieuwe variabele genaamd aWeekAgo die overal in onze query kan worden gebruikt.
Zoals we net hebben gezegd, kunt u een let-instructie gebruiken om een hele query te maken en het resultaat een naam te geven. Omdat queryresultaten in tabelvorm kunnen worden gebruikt als invoer van query's, kunt u dit benoemde resultaat behandelen als een tabel voor het uitvoeren van een andere query. Hier volgt een kleine wijziging in het vorige voorbeeld:
let aWeekAgo = ago(7d);
let getSignins = SigninLogs
| where TimeGenerated >= aWeekAgo;
getSignins
In dit geval hebben we een tweede let-instructie gemaakt, waarbij we onze hele query hebben verpakt in een nieuwe variabele met de naam getSignins. Net als voorheen beëindigen we de tweede let-instructie met een puntkomma. Vervolgens roepen we de variabele aan op de laatste regel, waarmee de query wordt uitgevoerd. U ziet dat we aWeekAgo in de tweede let-instructie konden gebruiken. Dit komt doordat we deze op de vorige regel hebben opgegeven; Als we de let-instructies zouden verwisselen zodat getSignins eerst kwam, krijgen we een foutmelding.
Nu kunnen we getSignins gebruiken als basis van een andere query (in hetzelfde venster):
let aWeekAgo = ago(7d);
let getSignins = SigninLogs
| where TimeGenerated >= aWeekAgo;
getSignins
| where level >= 3
| project IPAddress, UserDisplayName, Level
Laat instructies u meer kracht en flexibiliteit bieden bij het organiseren van uw query's. Laten we scalaire en tabellaire waarden definiëren en door de gebruiker gedefinieerde functies maken. Ze zijn echt handig wanneer u complexere query's organiseert die meerdere joins kunnen uitvoeren.
Volgende stappen
Hoewel dit artikel nauwelijks het oppervlak heeft bekrast, hebt u nu de benodigde basis en we hebben de onderdelen behandeld die u het vaakst gebruikt om uw werk gedaan te krijgen in Microsoft Sentinel.
Geavanceerde KQL voor Microsoft Sentinel-werkmap
Profiteer van een Kusto-querytaal werkmap rechtstreeks in Microsoft Sentinel zelf: de geavanceerde KQL voor Microsoft Sentinel-werkmap. Het biedt u stapsgewijze hulp en voorbeelden voor veel van de situaties die u waarschijnlijk zult tegenkomen tijdens uw dagelijkse beveiligingsbewerkingen en verwijst u ook naar veel kant-en-klare voorbeelden van analyseregels, werkmappen, opsporingsregels en meer elementen die Kusto-query's gebruiken. Start deze werkmap vanaf de blade Werkmappen in Microsoft Sentinel.
Geavanceerde KQL Framework-werkmap: u kunt KQL-savvy worden, is een uitstekend blogbericht waarin wordt uitgelegd hoe u deze werkmap kunt gebruiken.
Meer resources
Bekijk deze verzameling leer-, trainings- en vaardigheidsbronnen voor het uitbreiden en verdiepen van uw kennis van Kusto-querytaal.
Feedback
Binnenkort beschikbaar: In de loop van 2024 zullen we GitHub-problemen geleidelijk uitfaseren als het feedbackmechanisme voor inhoud en deze vervangen door een nieuw feedbacksysteem. Zie voor meer informatie: https://aka.ms/ContentUserFeedback.
Feedback verzenden en weergeven voor