Capaciteitsplanning voor Service Fabric-toepassingen
In dit document leert u hoe u de hoeveelheid resources (CPU's, RAM, schijfopslag) kunt schatten die u nodig hebt om uw Azure Service Fabric-toepassingen uit te voeren. Het is gebruikelijk dat uw resourcevereisten na verloop van tijd veranderen. Doorgaans hebt u weinig resources nodig tijdens het ontwikkelen/testen van uw service en vervolgens meer resources nodig naarmate u in productie gaat en uw toepassing steeds populairder wordt. Wanneer u uw toepassing ontwerpt, moet u nadenken over de vereisten voor de lange termijn en keuzes maken waarmee uw service kan worden geschaald om te voldoen aan de hoge vraag van de klant.
Wanneer u een Service Fabric-cluster maakt, bepaalt u welke soorten virtuele machines (VM's) deel uitmaken van het cluster. Elke VIRTUELE machine wordt geleverd met een beperkte hoeveelheid resources in de vorm van CPU's (kernen en snelheid), netwerkbandbreedte, RAM- en schijfopslag. Naarmate uw service in de loop van de tijd groeit, kunt u upgraden naar VM's die meer resources bieden en/of meer VM's aan uw cluster toevoegen. Als u dit laatste wilt doen, moet u uw service in eerste instantie ontwerpen, zodat deze kan profiteren van nieuwe VM's die dynamisch worden toegevoegd aan het cluster.
Sommige services beheren weinig tot geen gegevens op de VM's zelf. Daarom moet de capaciteitsplanning voor deze services zich voornamelijk richten op prestaties, wat betekent dat u de juiste CPU's (kernen en snelheid) van de VM's selecteert. Daarnaast moet u rekening houden met de netwerkbandbreedte, inclusief hoe vaak netwerkoverdrachten plaatsvinden en hoeveel gegevens worden overgedragen. Als uw service goed moet presteren als het servicegebruik toeneemt, kunt u meer VM's toevoegen aan het cluster en de netwerkaanvragen verdelen over alle VM's.
Voor services die grote hoeveelheden gegevens op de VM's beheren, moet de capaciteitsplanning zich voornamelijk richten op de grootte. Daarom moet u zorgvuldig rekening houden met de capaciteit van de RAM- en schijfopslag van de VIRTUELE machine. Het beheersysteem voor virtueel geheugen in Windows maakt schijfruimte eruit als RAM-geheugen voor toepassingscode. Bovendien biedt de Service Fabric-runtime slimme paging die alleen dynamische gegevens in het geheugen bewaart en de koude gegevens naar schijf verplaatst. Toepassingen kunnen dus meer geheugen gebruiken dan fysiek beschikbaar is op de VIRTUELE machine. Als u meer RAM-geheugen hebt, worden de prestaties verbeterd, omdat de VIRTUELE machine meer schijfopslag in RAM kan behouden. De vm die u selecteert, moet een schijf groot genoeg hebben om de gewenste gegevens op de virtuele machine op te slaan. Op dezelfde manier moet de VM voldoende RAM-geheugen hebben om u de gewenste prestaties te bieden. Als de gegevens van uw service na verloop van tijd toenemen, kunt u meer VM's toevoegen aan het cluster en de gegevens partitioneren op alle VM's.
Door uw service te partitioneren, kunt u de gegevens van uw service uitschalen. Zie Partitionering Service Fabric voor meer informatie over partitioneren. Elke partitie moet binnen één VIRTUELE machine passen, maar er kunnen meerdere (kleine) partities op één VIRTUELE machine worden geplaatst. Als u dus meer kleine partities hebt, hebt u meer flexibiliteit dan een paar grotere partities. De afweging is dat het gebruik van veel partities de overhead van Service Fabric verhoogt en dat u geen transacties tussen partities kunt uitvoeren. Er is ook meer potentieel netwerkverkeer als uw servicecode vaak toegang nodig heeft tot gegevens die zich in verschillende partities bevinden. Bij het ontwerpen van uw service moet u zorgvuldig rekening houden met deze voor- en nadelen om tot een effectieve partitioneringsstrategie te komen.
Stel dat uw toepassing één stateful service heeft met een winkelgrootte die in een jaar zal toenemen tot DB_Size GB. U bent bereid om meer toepassingen (en partities) toe te voegen naarmate u meer groei na dat jaar ondervindt. De replicatiefactor (RF), waarmee het aantal replica's voor uw service wordt bepaald, is van invloed op het totale DB_Size. Het totale DB_Size voor alle replica's is de replicatiefactor vermenigvuldigd met DB_Size. Node_Size vertegenwoordigt de schijfruimte/RAM per knooppunt dat u wilt gebruiken voor uw service. Voor de beste prestaties moet de DB_Size in het geheugen in het cluster passen en moet er een Node_Size rond het RAM-geheugen van de virtuele machine worden gekozen. Door een Node_Size toe te wijzen die groter is dan de RAM-capaciteit, vertrouwt u op de paging die wordt geleverd door de Service Fabric-runtime. Uw prestaties zijn dus mogelijk niet optimaal als uw volledige gegevens als dynamisch worden beschouwd (aangezien de gegevens worden gepaginad in/uit). Voor veel services waarbij slechts een fractie van de gegevens dynamisch is, is het echter rendabeler.
Het aantal knooppunten dat is vereist voor maximale prestaties, kan als volgt worden berekend:
Number of Nodes = (DB_Size * RF)/Node_Size
Mogelijk wilt u het aantal knooppunten berekenen op basis van de DB_Size waarvan u verwacht dat uw service groeit, naast de DB_Size waarmee u bent begonnen. Vergroot vervolgens het aantal knooppunten naarmate uw service groeit, zodat u het aantal knooppunten niet te veel inricht. Maar het aantal partities moet zijn gebaseerd op het aantal knooppunten dat nodig is wanneer u uw service uitvoert bij maximale groei.
Het is handig om op elk gewenst moment extra machines beschikbaar te hebben, zodat u onverwachte pieken of storingen kunt afhandelen (bijvoorbeeld als een paar VM's uitvallen). Hoewel de extra capaciteit moet worden bepaald door gebruik te maken van uw verwachte pieken, is het uitgangspunt om enkele extra VM's (5-10 procent extra) te reserveren.
In het voorgaande wordt uitgegaan van één stateful service. Als u meer dan één stateful service hebt, moet u de DB_Size die aan de andere services zijn gekoppeld, toevoegen aan de vergelijking. U kunt ook het aantal knooppunten afzonderlijk berekenen voor elke stateful service. Uw service heeft mogelijk replica's of partities die niet in balans zijn. Houd er rekening mee dat partities mogelijk ook meer gegevens hebben dan andere partities. Zie het artikel over partitionering van best practices voor meer informatie over partitionering. De voorgaande vergelijking is echter partitie- en replicaagnostisch, omdat Service Fabric ervoor zorgt dat de replica's op een geoptimaliseerde manier worden verdeeld over de knooppunten.
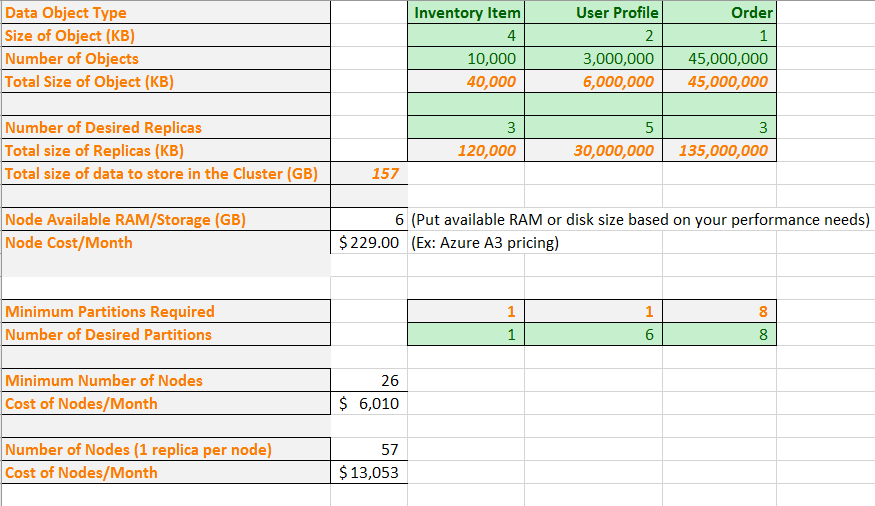
Laten we nu enkele reële getallen in de formule plaatsen. Een voorbeeld van een spreadsheet laat zien hoe u de capaciteit kunt plannen voor een toepassing die drie typen gegevensobjecten bevat. Voor elk object benaderen we de grootte en het aantal objecten dat we verwachten te hebben. We selecteren ook hoeveel replica's we van elk objecttype willen. De spreadsheet berekent de totale hoeveelheid geheugen die in het cluster moet worden opgeslagen.
Vervolgens voeren we een VM-grootte en maandelijkse kosten in. Op basis van de VM-grootte geeft het spreadsheet het minimale aantal partities aan dat u moet gebruiken om uw gegevens te splitsen zodat ze fysiek op de knooppunten passen. Mogelijk wilt u een groter aantal partities om tegemoet te komen aan de specifieke reken- en netwerkverkeersbehoeften van uw toepassing. In het werkblad ziet u het aantal partities dat de gebruikersprofielobjecten beheert, is toegenomen van een tot zes.
Op basis van al deze informatie ziet u in het spreadsheet dat u fysiek alle gegevens met de gewenste partities en replica's op een cluster met 26 knooppunten kunt ophalen. Dit cluster is echter dicht verpakt, dus mogelijk wilt u een aantal extra knooppunten voor knooppuntfouten en upgrades. In het werkblad ziet u ook dat het hebben van meer dan 57 knooppunten geen extra waarde biedt, omdat u lege knooppunten zou hebben. Nogmaals, misschien wilt u toch boven de 57 knooppunten gaan om knooppuntfouten en upgrades aan te kunnen. U kunt het spreadsheet aanpassen aan de specifieke behoeften van uw toepassing.
Bekijk Partitioning Service Fabric-services voor meer informatie over het partitioneren van uw service.