Over herstelplannen
Dit artikel bevat een overzicht van herstelplannen in Azure Site Recovery.
Met een herstelplan worden computers in herstelgroepen verzameld met het doel een failover uit te voeren. Met een herstelplan kunt u een systematisch herstelproces definiëren door kleine onafhankelijke eenheden te maken waarvoor u een failover kunt uitvoeren. Een eenheid vertegenwoordigt doorgaans een app in uw omgeving.
- Een herstelplan definieert hoe machines een failover uitvoeren en de volgorde waarin deze na een failover worden gestart.
- Herstelplannen kunnen worden gebruikt voor zowel failover naar als failback vanuit Azure.
- Maximaal 100 beveiligde exemplaren kunnen worden toegevoegd aan één herstelplan.
- U kunt een plan aanpassen door er order, instructies en taken aan toe te voegen.
- Nadat een plan is gedefinieerd, kunt u er een failover op uitvoeren.
- Machines kunnen worden verwezen in meerdere herstelplannen, waarin volgende plannen de implementatie/het opstarten van een machine overslaan als deze eerder is geïmplementeerd met behulp van een ander herstelplan.
Waarom een herstelplan gebruiken?
Herstelplannen gebruiken om:
- Modelleer een app rond de afhankelijkheden.
- Automatiseer hersteltaken om de beoogde hersteltijd (RTO) te verminderen.
- Controleer of u voorbereid bent op migratie of herstel na noodgevallen door ervoor te zorgen dat uw apps deel uitmaken van een herstelplan.
- Voer testfailovers uit voor herstelplannen om ervoor te zorgen dat herstel na noodgevallen of migratie werkt zoals verwacht.
Model-apps
U kunt een herstelgroep plannen en maken om app-specifieke eigenschappen vast te leggen. Laten we eens kijken naar een typische toepassing met drie lagen met een BACK-end van SQL Server, middleware en een webfront-end. Normaal gesproken past u het herstelplan aan zodat machines in elke laag na een failover in de juiste volgorde worden gestart.
- De SQL-back-end moet eerst beginnen, de middleware hierna en ten slotte de webfront-end.
- Deze beginvolgorde zorgt ervoor dat de app werkt op het moment dat de laatste machine wordt gestart.
- Deze volgorde zorgt ervoor dat wanneer de middleware wordt gestart en verbinding probeert te maken met de SQL Server-laag, de SQL Server-laag al wordt uitgevoerd.
- Deze volgorde zorgt er ook voor dat de front-endserver voor het laatst wordt gestart, zodat eindgebruikers geen verbinding maken met de app-URL voordat alle onderdelen actief zijn en de app klaar is om aanvragen te accepteren.
Als u deze volgorde wilt maken, voegt u groepen toe aan de herstelgroep en voegt u machines toe aan de groepen.
Wanneer volgorde is opgegeven, wordt sequentiëren gebruikt. Acties worden zo nodig parallel uitgevoerd om de RTO voor toepassingsherstel te verbeteren.
Machines in één groepsoverschakeling worden parallel uitgevoerd.
Machines in verschillende groepen voeren een failover uit in groepsvolgorde, zodat groep 2-machines hun failover pas starten nadat alle machines in groep 1 een failover hebben uitgevoerd en gestart.
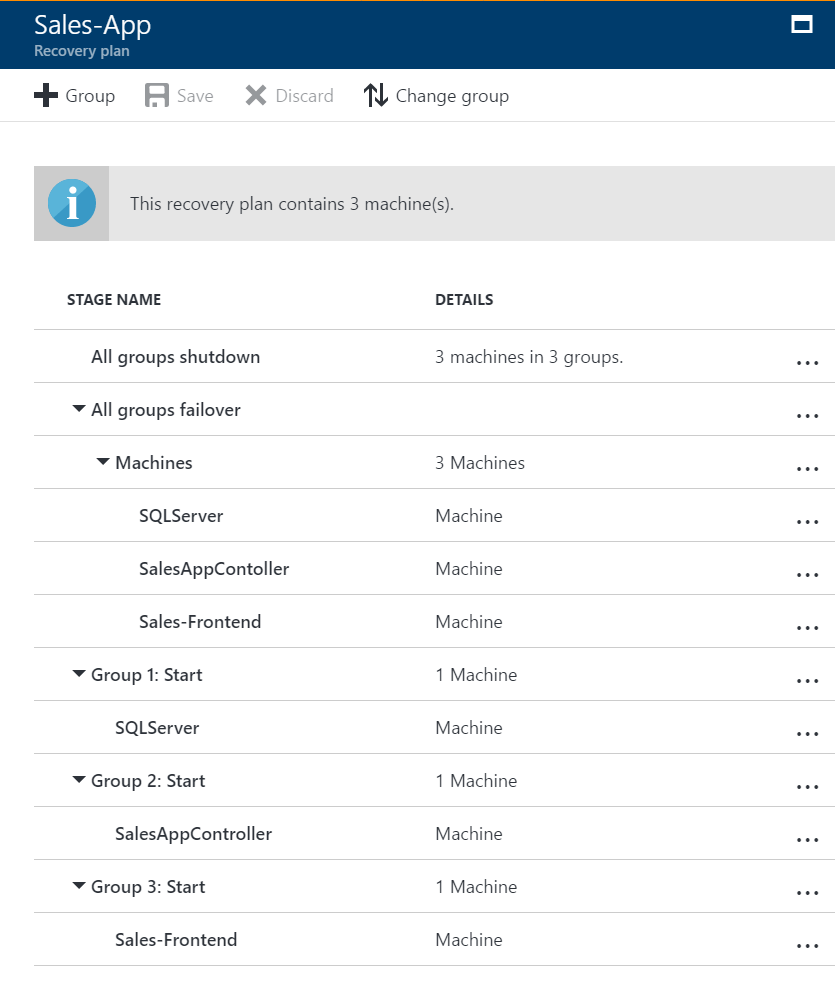
Met deze aanpassing gebeurt het volgende wanneer u een failover uitvoert in het herstelplan:
- Een afsluitstap probeert de on-premises machines uit te schakelen. De uitzondering is als u een testfailover uitvoert. In dat geval blijft de primaire site actief.
- Het afsluiten activeert een parallelle failover van alle machines in het herstelplan.
- Met de failover worden schijven van virtuele machines voorbereid met behulp van gerepliceerde gegevens.
- De opstartgroepen worden op volgorde uitgevoerd en starten de machines in elke groep. Eerst wordt Groep 1 uitgevoerd, vervolgens Groep 2 en ten slotte Groep 3. Als er meer dan één computer in een groep is, worden alle computers parallel gestart.
Taken in herstelplannen automatiseren
Het herstellen van grote toepassingen kan een complexe taak zijn. Handmatige stappen maken het proces gevoelig voor fouten en de persoon die de failover uitvoert, is mogelijk niet op de hoogte van alle app-complexiteit. U kunt een herstelplan gebruiken om volgorde op te leggen en de acties die nodig zijn voor elke stap te automatiseren, met behulp van Azure Automation-runbooks voor failover naar Azure of scripts. Voor taken die niet kunnen worden geautomatiseerd, kunt u pauzes invoegen voor handmatige acties in herstelplannen. Er zijn een aantal typen taken die u kunt configureren:
- Taken op de Virtuele Azure-machine na een failover: wanneer u een failover naar Azure uitvoert, moet u doorgaans acties uitvoeren, zodat u na een failover verbinding kunt maken met de virtuele machine. Bijvoorbeeld:
- Maak een openbaar IP-adres op de Azure-VM.
- Wijs een netwerkbeveiligingsgroep toe aan de netwerkadapter van de Virtuele Azure-machine.
- Voeg een load balancer toe aan een beschikbaarheidsset.
- Taken binnen de VM na een failover: met deze taken wordt de app die op de computer wordt uitgevoerd, doorgaans opnieuw geconfigureerd, zodat deze correct blijft werken in de nieuwe omgeving. Bijvoorbeeld:
- Wijzig de database verbindingsreeks op de computer.
- Wijzig de webserverconfiguratie of -regels.
Een testfailover uitvoeren op herstelplannen
U kunt een herstelplan gebruiken om een testfailover te activeren. Gebruik de volgende aanbevolen procedures:
Voltooi altijd een testfailover op een app voordat u een volledige failover uitvoert. Testfailovers helpen u te controleren of de app op de herstelsite wordt weergegeven.
Als u merkt dat u iets hebt gemist, activeert u een opschoonbewerking en voert u de testfailover opnieuw uit.
Voer een testfailover meerdere keren uit totdat u zeker weet dat de app probleemloos wordt hersteld.
Omdat elke app uniek is, moet u herstelplannen bouwen die zijn aangepast voor elke toepassing en een testfailover uitvoeren op elke toepassing.
Apps en hun afhankelijkheden veranderen regelmatig. Voer elk kwartaal een testfailover uit voor elke app om ervoor te zorgen dat herstelplannen up-to-date zijn.
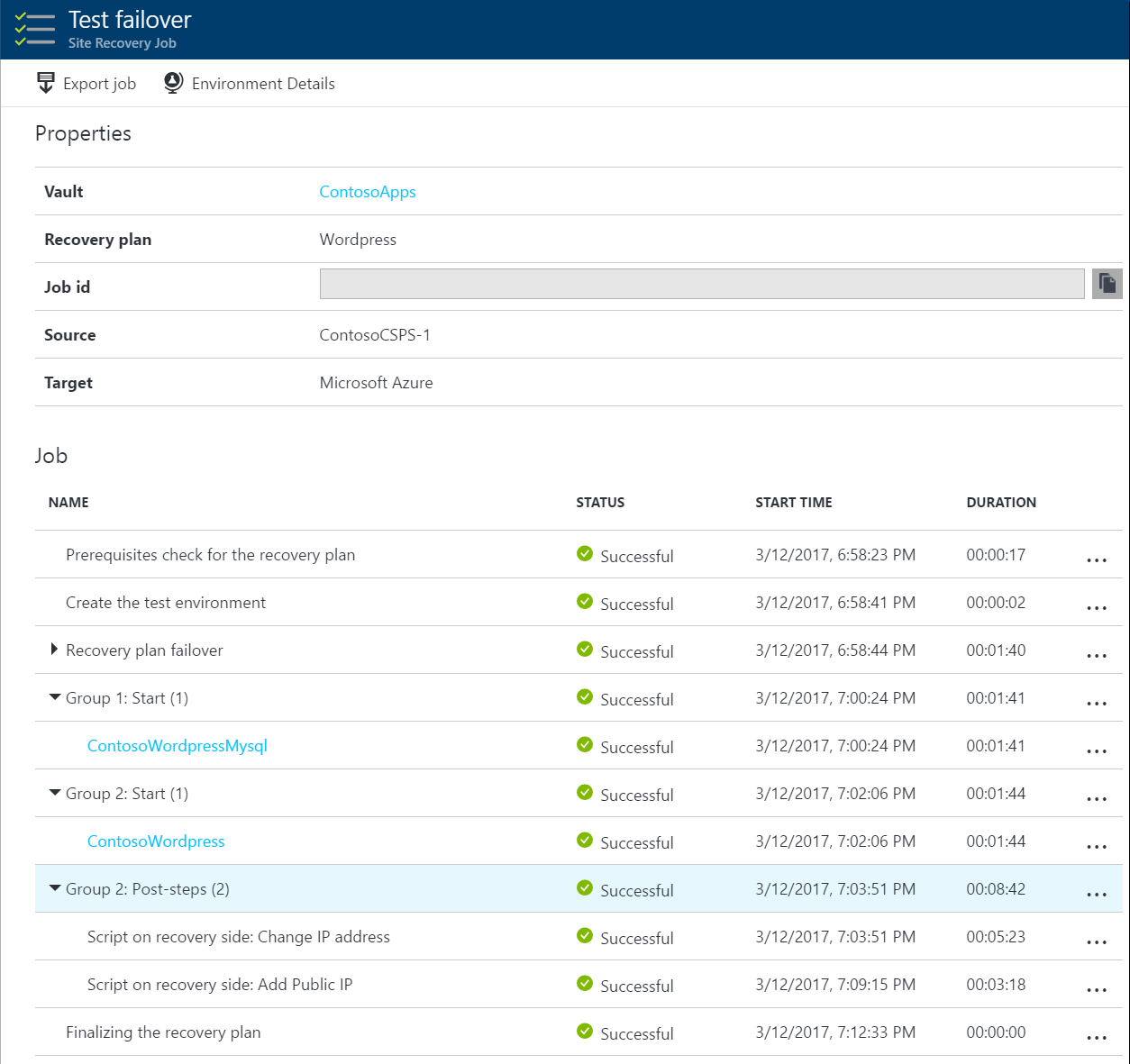
Bekijk een video over een herstelplan
Bekijk een korte voorbeeldvideo met een on-click-failover voor een herstelplan voor een WordPress-app met twee lagen.
Volgende stappen
- Maak een herstelplan.
- Failovers uitvoeren .