Notitie
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen u aan te melden of de directory te wijzigen.
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen de mappen te wijzigen.
Met queryversnelling kunnen toepassingen en analyseframeworks de gegevensverwerking aanzienlijk optimaliseren door alleen de gegevens op te halen die ze nodig hebben om een bepaalde bewerking uit te voeren. Dit vermindert de tijd en verwerkingskracht die nodig is om kritieke inzichten te krijgen in opgeslagen gegevens.
Overzicht
Queryversnelling accepteert filterpredicaten en kolomprojecties, waardoor toepassingen rijen en kolommen kunnen filteren op het moment dat gegevens van schijf worden gelezen. Alleen de gegevens die voldoen aan de voorwaarden van een predicaat, worden via het netwerk overgebracht naar de toepassing. Dit vermindert de netwerklatentie en rekenkosten.
U kunt SQL gebruiken om de rijfilterpredicaten en kolomprojecties op te geven in een queryversnellingsaanvraag. Een aanvraag verwerkt slechts één bestand. Daarom worden geavanceerde relationele functies van SQL, zoals joins en groeperen op aggregaties, niet ondersteund. Queryversnelling ondersteunt csv- en JSON-geformatteerde gegevens als invoer voor elke aanvraag.
De functie queryversnelling is niet beperkt tot Data Lake Storage (opslagaccounts met een ingeschakelde hiërarchische naamruimte). Queryversnelling is compatibel met de blobs in opslagaccounts waarvoor geen hiërarchische naamruimte is ingeschakeld. Dit betekent dat u dezelfde vermindering van de netwerklatentie en rekenkosten kunt bereiken wanneer u gegevens verwerkt die u al hebt opgeslagen als blobs in opslagaccounts.
Zie Gegevens filteren met behulp van Azure Data Lake Storage-queryversnelling voor een voorbeeld van het gebruik van queryversnelling in een clienttoepassing.
Gegevensstroom
In het volgende diagram ziet u hoe een typische toepassing queryversnelling gebruikt om gegevens te verwerken.
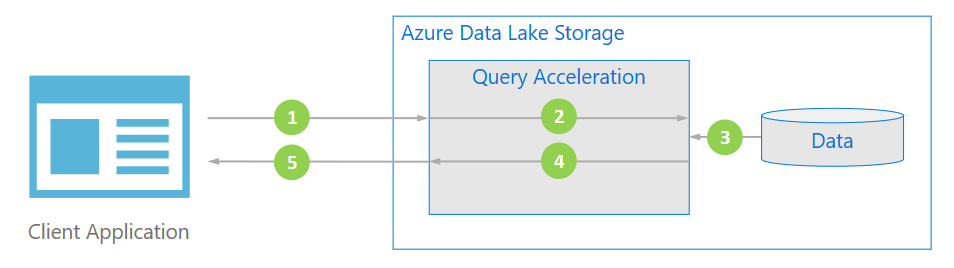
De clienttoepassing vraagt bestandsgegevens aan door predicaten en kolomprojecties op te geven.
Queryversnelling parseert de opgegeven SQL-query en distribueert werk om gegevens te parseren en te filteren.
Processors lezen de gegevens van de schijf, parseren de gegevens met behulp van de juiste indeling en filteren vervolgens gegevens door de opgegeven predicaten en kolomprojecties toe te passen.
Queryversnelling combineert de antwoordshards om terug te streamen naar de clienttoepassing.
De clienttoepassing ontvangt en parseert het gestreamde antwoord. De toepassing hoeft geen andere gegevens te filteren en kan de gewenste berekening of transformatie rechtstreeks toepassen.
Betere prestaties tegen lagere kosten
Queryversnelling optimaliseert de prestaties door de hoeveelheid gegevens te verminderen die door uw toepassing wordt overgedragen en verwerkt.
Voor het berekenen van een geaggregeerde waarde halen toepassingen meestal alle gegevens op uit een bestand en verwerken en filteren ze vervolgens lokaal. Een analyse van de invoer-/uitvoerpatronen voor analyseworkloads laat zien dat toepassingen doorgaans slechts 20% van de gegevens vereisen die ze lezen om een bepaalde berekening uit te voeren. Deze statistiek is waar, zelfs na het toepassen van technieken zoals partition pruning. Dit betekent dat 80% van die gegevens onnodig over het netwerk worden verzonden, geanalyseerd en gefilterd door applicaties. Dit patroon, ontworpen om overbodige gegevens te verwijderen, kost aanzienlijke rekenkosten.
Hoewel Azure beschikt over een toonaangevende netwerk, wat betreft zowel doorvoer als latentie, is het onnodig overdragen van gegevens over dat netwerk nog steeds kostbaar voor de prestaties van toepassingen. Door de ongewenste gegevens tijdens de opslagaanvraag te filteren, elimineert queryversnelling deze kosten.
Bovendien vereist de CPU-belasting die nodig is voor het parseren en filteren van overbodige gegevens uw toepassing om een groter aantal en grotere VM's in te richten om het werk te kunnen uitvoeren. Door deze rekenbelasting over te dragen aan queryversnelling, kunnen toepassingen aanzienlijke kostenbesparingen realiseren.
Toepassingen die kunnen profiteren van versnelling van query's
Queryversnelling is ontworpen voor gedistribueerde analyseframeworks en gegevensverwerkingstoepassingen.
Gedistribueerde analyseframeworks, zoals Apache Spark en Apache Hive, bevatten een opslagabstractielaag binnen het framework. Deze engines omvatten ook queryoptimalisaties die kennis kunnen opnemen van de mogelijkheden van de onderliggende I/O-service bij het bepalen van een optimaal queryplan voor gebruikersquery's. Deze frameworks beginnen queryversnelling te integreren. Als gevolg hiervan zien gebruikers van deze frameworks verbeterde querylatentie en lagere totale eigendomskosten zonder dat ze wijzigingen hoeven aan te brengen in de query's.
Query-acceleratie is ook ontworpen voor gegevensverwerking. Deze typen toepassingen voeren doorgaans grootschalige gegevenstransformaties uit die mogelijk niet rechtstreeks leiden tot analyseinzichten, zodat ze niet altijd gebruikmaken van gevestigde gedistribueerde analyseframeworks. Deze toepassingen hebben vaak een meer directe relatie met de onderliggende opslagservice, zodat ze rechtstreeks kunnen profiteren van functies zoals queryversnelling.
Zie Gegevens filteren met behulp van Azure Data Lake Storage-queryversnelling voor een voorbeeld van hoe een toepassing queryversnelling kan integreren.
Prijzen
Vanwege de toegenomen rekenbelasting binnen de Azure Data Lake Storage-service verschilt het prijsmodel voor het gebruik van queryversnelling van het normale Azure Data Lake Storage-transactiemodel. Queryversnelling brengt kosten in rekening voor de hoeveelheid gescande gegevens en voor de hoeveelheid gegevens die aan de aanroeper worden geretourneerd. Zie prijzen voor Azure Data Lake Storage voor meer informatie.
Ondanks de wijziging in het factureringsmodel is het prijsmodel van Query-acceleratie ontworpen om de totale eigendomskosten voor een workload te verlagen, gezien de vermindering van de veel hogere kosten van VM's.