Notitie
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen u aan te melden of de directory te wijzigen.
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen de mappen te wijzigen.
✔️ Van toepassing op: klassieke SMB- en NFS-bestandsshares die zijn gemaakt met de Microsoft.Storage-resourceprovider
✔️ Van toepassing op: Bestandsshares die zijn aangemaakt met de Microsoft.FileShares-resourceprovider (preview)
Azure Files kan voldoen aan de prestatievereisten voor de meeste toepassingen en gebruiksvoorbeelden. In dit artikel worden de verschillende factoren uitgelegd die van invloed kunnen zijn op de prestaties van bestandsshares en hoe u de prestaties van Azure-bestandsshares voor uw workload kunt optimaliseren.
Woordenlijst voor opslagprestaties
Voordat u dit artikel leest, is het handig om enkele belangrijke termen met betrekking tot opslagprestaties te begrijpen:
I/O-bewerkingen per seconde (IOPS)
IOPS, of invoer-/uitvoerbewerkingen per seconde, meet het aantal bestandssysteembewerkingen per seconde. De term 'IO' is uitwisselbaar met de termen 'operation' en 'transaction' in de Documentatie van Azure Files.
I/O-grootte
I/O-grootte, ook wel blokgrootte genoemd, is de grootte van de aanvraag die een toepassing gebruikt om één I/O-bewerking (Input/Output) uit te voeren in de opslag. Afhankelijk van de toepassing kan de I/O-grootte variëren van kleine grootten, zoals 4 KiB tot grotere maten. I/O-grootte speelt een belangrijke rol bij haalbare doorvoer.
Doorvoer
Doorvoer meet het aantal bits dat is gelezen van of geschreven naar de opslag per seconde en wordt gemeten in mebibytes per seconde (MiB/s). Als u doorvoer wilt berekenen, vermenigvuldigt u IOPS met I/O-grootte. Bijvoorbeeld 10.000 IOPS _ 1 MiB I/O grootte = 10 GiB/s, terwijl 10.000 IOPS _ 4 KiB I/O grootte = 38 MiB/s.
Latentie
Latentie is een synoniem voor vertraging en wordt gemeten in milliseconden (ms). Er zijn twee typen latentie: end-to-end latentie en servicelatentie. Zie Latentie voor meer informatie.
Wachtrijdiepte
De wachtrijdiepte is het aantal in behandeling zijnde I/O-aanvragen dat een opslagresource op elk gewenst moment kan verwerken. Zie Wachtrijdiepte voor meer informatie.
Een medialaag kiezen op basis van gebruikspatronen
Azure Files biedt twee opslagmedialagen waarmee u de prestaties en prijs kunt verdelen: SSD en HDD. U kiest de medialaag van de bestandsshare op het niveau van het opslagaccount en zodra u een opslagaccount in een bepaalde medialaag maakt, kunt u niet naar de andere gaan zonder dat u handmatig naar een nieuwe bestandsshare migreert.
Wanneer u kiest tussen SSD- en HDD-bestandsshares, is het belangrijk om inzicht te hebben in de vereisten van het verwachte gebruikspatroon dat u wilt uitvoeren op Azure Files. Als u grote hoeveelheden IOPS, snelle gegevensoverdrachtsnelheden of lage latentie nodig hebt, moet u SSD-bestandsshares kiezen.
De volgende tabel bevat een overzicht van de verwachte prestatiedoelen tussen SSD- en HDD-bestandsshares. Zie De schaalbaarheids- en prestatiedoelen van Azure Files voor meer informatie.
| Vereisten voor gebruikspatronen | SSD | HDD |
|---|---|---|
| Schrijflatentie (milliseconden met één cijfer) | Ja | Ja |
| Leeslatentie (milliseconden met één cijfer) | Ja | Nee |
SSD-bestandsshares bieden een inrichtingsmodel dat het volgende prestatieprofiel garandeert op basis van de sharegrootte. Zie het geconfigureerde v1-model voor meer informatie.
Beste praktijken voor prestatievermogen
Of u nu prestatievereisten voor een nieuwe of bestaande workload beoordeelt, inzicht in uw gebruikspatronen helpt u voorspelbare prestaties te bereiken.
Latentiegevoeligheid: Workloads die gevoelig zijn voor leeslatentie en hoge zichtbaarheid hebben voor eindgebruikers, zijn geschikter voor SSD-bestandsshares, die latentie van één milliseconde kunnen bieden voor zowel lees- als schrijfbewerkingen (< 2 ms voor kleine I/O-grootte).
IOPS- en doorvoervereisten: SSD-bestandsshares ondersteunen grotere IOPS- en doorvoerlimieten dan HDD-bestandsshares. Zie schaaldoelen voor bestandsshares voor meer informatie.
Duur en frequentie van werkbelasting: Korte (minuten) en onregelmatige (uurlijkse) werkbelastingen bereiken minder waarschijnlijk de hoogste prestatielimieten van HDD-bestandsshares ten opzichte van langlopende, vaak voorkomende workloads. Op SSD-bestandsshares is de duur van de werkbelasting handig bij het bepalen van het juiste prestatieprofiel dat moet worden gebruikt op basis van de ingerichte opslag, IOPS en doorvoer. Een veelvoorkomende fout is het uitvoeren van prestatietests voor slechts een paar minuten, wat vaak misleidend is. Als u een realistisch beeld wilt krijgen van de prestaties, moet u testen met een voldoende hoge frequentie en duur.
Parallellisatie van werkbelasting: Voor workloads die gelijktijdig bewerkingen uitvoeren, zoals via meerdere threads, processen of toepassingsexemplaren op dezelfde client, bieden SSD-bestandsshares een duidelijk voordeel ten opzichte van HDD-bestandsshares: SMB Meerdere kanalen. Zie Prestaties van SMB Azure-bestandsshares verbeteren voor meer informatie.
Distributie van API-bewerkingen: zware werkbelastingen voor metagegevens, zoals workloads die leesbewerkingen uitvoeren op een groot aantal bestanden, zijn beter geschikt voor SSD-bestandsshares. Zie werkbelasting met zware metagegevens of naamruimte.
Zonegebonden plaatsing: gebruik zonegebonden plaatsing om de specifieke beschikbaarheidszone te selecteren waarin uw opslagaccount zich bevindt. Hierdoor kunt u uw VM's in dezelfde beschikbaarheidszone plaatsen als uw opslag, waardoor de latentie met maximaal 30 procent kan worden verminderd. Deze functie is momenteel alleen beschikbaar voor SSD-opslagaccounts die lokaal redundante opslag (LRS) gebruiken in ondersteunde regio's.
Latentie
Wanneer u nadenkt over latentie, is het belangrijk om eerst te begrijpen hoe latentie wordt bepaald met Azure Files. De meest voorkomende metingen zijn de latentie die is gekoppeld aan end-to-end latentie en metrische gegevens over servicelatentie . Door deze metrische gegevens over transacties te gebruiken, kunt u latentie- en/of netwerkproblemen aan de clientzijde identificeren door te bepalen hoeveel tijd uw toepassingsverkeer in transit naar en van de client besteedt.
End-to-end latentie (SuccessE2ELatency) is de totale tijd die nodig is voor een transactie om een volledige rondreis van de client, via het netwerk, naar de Azure Files-service en terug naar de client.
Servicelatentie (SuccessServerLatency) is de tijd die het kost om een transactie alleen binnen Azure Files te afronden. Dit omvat geen client- of netwerklatentie.
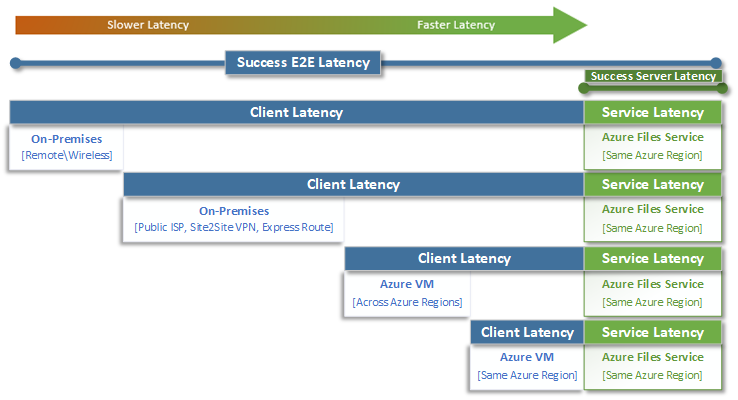
Het verschil tussen successE2ELatency- en SuccessServerLatency-waarden is de latentie die waarschijnlijk wordt veroorzaakt door het netwerk en/of de client.
Het is gebruikelijk om clientlatentie te verwarren met servicelatentie (in dit geval prestaties van Azure Files). Als de servicelatentie bijvoorbeeld een lage latentie rapporteert en de end-to-end zeer hoge latentie rapporteert voor aanvragen, betekent dit dat alle tijd wordt besteed aan transit naar en van de client en niet in de Azure Files-service.
Bovendien, zoals in het diagram wordt geïllustreerd, hoe verder u zich niet bij de service bevindt, hoe trager de latentie-ervaring is en hoe moeilijker het is om prestatieschaallimieten te bereiken met elke cloudservice. Dit geldt met name voor toegang tot Azure Files vanaf on-premises. Hoewel opties zoals ExpressRoute ideaal zijn voor on-premises, komen ze nog steeds niet overeen met de prestaties van een toepassing (compute en opslag) die exclusief in dezelfde Azure-regio worden uitgevoerd.
Suggestie
Het gebruik van een virtuele machine in Azure om de prestaties van de verbinding tussen de lokale infrastructuur en Azure te testen, is een effectieve en praktische manier om de netwerkmogelijkheden van de verbinding met Azure vast te stellen. Ondersized of onjuist gerouteerde ExpressRoute-circuits of VPN-gateways kunnen Azure Files-werkbelastingen aanzienlijk vertragen.
Wachtrijdiepte
De wachtrijdiepte is het aantal openstaande I/O-aanvragen dat een opslagresource kan verwerken. Naarmate de schijven die door opslagsystemen worden gebruikt, zijn ontwikkeld van HDD-spindles (IDE, SATA, SAS) naar ssd-, NVMe-apparaten (SSD, NVMe), hebben ze zich ook ontwikkeld ter ondersteuning van een hogere wachtrijdiepte. Een workload die bestaat uit één client die serieel interactie heeft met één bestand in een grote gegevensset, is een voorbeeld van een lage wachtrijdiepte. Een workload die ondersteuning biedt voor parallelle uitvoering met meerdere threads en meerdere bestanden, kan daarentegen eenvoudig een hoge wachtrijdiepte bereiken. Omdat Azure Files een gedistribueerde bestandsservice is die duizenden Azure-clusterknooppunten omvat en is ontworpen om workloads op schaal uit te voeren, raden we u aan workloads met een hoge wachtrijdiepte te bouwen en te testen.
Een hoge wachtrijdiepte kan op verschillende manieren worden bereikt in combinatie met clients, bestanden en threads. Als u de wachtrijdiepte voor uw workload wilt bepalen, vermenigvuldigt u het aantal clients met het aantal bestanden met het aantal threads (clients _ bestanden _ threads = wachtrijdiepte).
In de onderstaande tabel ziet u de verschillende combinaties die u kunt gebruiken om een hogere wachtrijdiepte te bereiken. Hoewel u de optimale wachtrijdiepte van 64 kunt overschrijden, raden we dit niet aan. Als u dit doet, ziet u geen prestatieverbeteringen en loopt u het risico dat de latentie toeneemt vanwege TCP-verzadiging.
| Cliënten | Bestanden | Discussies | Wachtrijdiepte |
|---|---|---|---|
| 1 | 1 | 1 | 1 |
| 1 | 1 | 2 | 2 |
| 1 | 2 | 2 | 4 |
| 2 | 2 | 2 | 8 |
| 2 | 2 | 4 | 16 |
| 2 | 4 | 4 | 32 |
| 1 | 8 | 8 | 64 |
| 4 | 4 | 2 | 64 |
Suggestie
Als u hogere prestatielimieten wilt bereiken, moet u ervoor zorgen dat uw workload- of benchmarkingtest meerdere threads met meerdere bestanden bevat.
Toepassingen met één versus meerdere threads
Azure Files is het meest geschikt voor toepassingen met meerdere threads. De eenvoudigste manier om inzicht te hebben in de invloed van meerdere threads op een workload, is door het scenario per I/O te doorlopen. In het volgende voorbeeld hebben we een workload die zo snel mogelijk 10.000 kleine bestanden moet kopiëren naar of van een Azure-bestandsshare.
Deze tabel bevat de benodigde tijd (in milliseconden) voor het maken van één KiB-bestand op een Azure-bestandsshare, op basis van een toepassing met één thread die in vier KiB-blokgrootten schrijft.
| I/O-bewerking | Maken | 4 KB schrijven | 4 KB schrijven | 4 KB schrijven | 4 KB schrijven | Sluiten | Totaal |
|---|---|---|---|---|---|---|---|
| Thread 1 | 3 ms | 2 ms | 2 ms | 2 ms | 2 ms | 3 ms | 14 ms |
In dit voorbeeld duurt het ongeveer 14 ms om één KiB-bestand van 16 kiB te maken op basis van de zes bewerkingen. Als een toepassing met één thread 10.000 bestanden naar een Azure-bestandsshare wil verplaatsen, wordt dit omgezet in 140.000 ms (14 ms * 10.000) of 140 seconden, omdat elk bestand sequentieel één voor één wordt verplaatst. Houd er rekening mee dat de tijd die nodig is om elke aanvraag te verwerken, voornamelijk wordt bepaald door hoe dicht de rekenkracht en opslag zich bij elkaar bevinden, zoals besproken in de vorige sectie.
Door acht threads te gebruiken in plaats van één, kan de bovenstaande workload worden verminderd van 140.000 ms (140 seconden) tot 17.500 ms (17,5 seconden). Zoals in de onderstaande tabel wordt weergegeven, kunt u, wanneer u acht bestanden tegelijk verplaatst in plaats van één bestand tegelijk, dezelfde hoeveelheid gegevens in minder dan 87,5% minder tijd verplaatsen.
| I/O-bewerking | Maken | 4 KB schrijven | 4 KB schrijven | 4 KB schrijven | 4 KB schrijven | Sluiten | Totaal |
|---|---|---|---|---|---|---|---|
| Thread 1 | 3 ms | 2 ms | 2 ms | 2 ms | 2 ms | 3 ms | 14 ms |
| Thread 2 | 3 ms | 2 ms | 2 ms | 2 ms | 2 ms | 3 ms | 14 ms |
| Thread 3 | 3 ms | 2 ms | 2 ms | 2 ms | 2 ms | 3 ms | 14 ms |
| Thread 4 | 3 ms | 2 ms | 2 ms | 2 ms | 2 ms | 3 ms | 14 ms |
| Thread 5 | 3 ms | 2 ms | 2 ms | 2 ms | 2 ms | 3 ms | 14 ms |
| Thread 6 | 3 ms | 2 ms | 2 ms | 2 ms | 2 ms | 3 ms | 14 ms |
| Thread 7 | 3 ms | 2 ms | 2 ms | 2 ms | 2 ms | 3 ms | 14 ms |
| Thread 8 | 3 ms | 2 ms | 2 ms | 2 ms | 2 ms | 3 ms | 14 ms |