Notitie
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen u aan te melden of de directory te wijzigen.
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen de mappen te wijzigen.
In dit artikel worden enkele patronen beschreven die geschikt zijn voor gebruik met Table Service-oplossingen. Ook ziet u hoe u praktisch enkele van de problemen en afwegingen kunt oplossen die worden besproken in andere artikelen over tabelopslagontwerp. In het volgende diagram ziet u een overzicht van de relaties tussen de verschillende patronen:
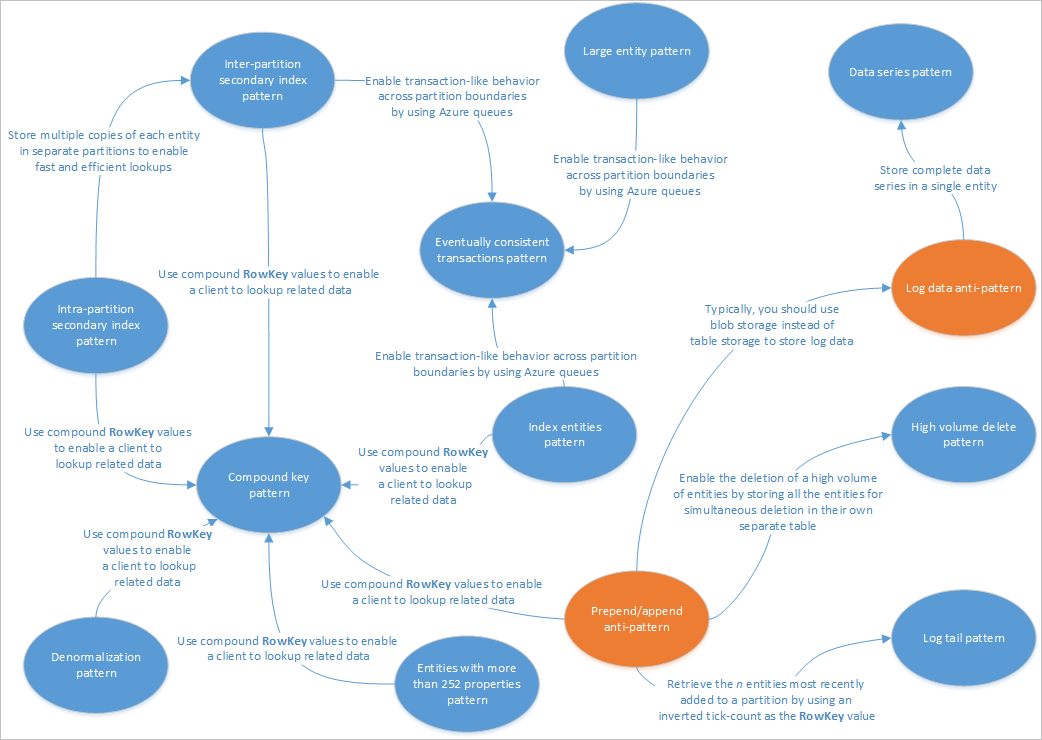
In de bovenstaande patroonkaart worden enkele relaties tussen patronen (blauw) en antipatronen (oranje) gemarkeerd die in deze handleiding worden beschreven. Er zijn veel andere patronen die de moeite waard zijn om rekening mee te houden. Een van de belangrijkste scenario's voor Table Service is bijvoorbeeld het gerealiseerde weergavepatroon van het CQRS-patroon (Command Query Responsibility Segregation) gebruiken.
Secundair indexpatroon tussen partities
Sla meerdere kopieën van elke entiteit op met behulp van verschillende RowKey-waarden (in dezelfde partitie) om snelle en efficiënte opzoekacties en alternatieve sorteervolgordes mogelijk te maken met behulp van verschillende RowKey-waarden . Updates tussen kopieën kunnen consistent worden gehouden met entiteitsgroeptransacties (EGT's).
Context en probleem
De Table-service indexeert automatisch entiteiten met behulp van de waarden PartitionKey en RowKey . Hierdoor kan een clienttoepassing een entiteit efficiënt ophalen met behulp van deze waarden. Met behulp van de onderstaande tabelstructuur kan een clienttoepassing bijvoorbeeld een puntquery gebruiken om een afzonderlijke werknemerentiteit op te halen met behulp van de afdelingsnaam en de werknemers-id (de waarden PartitionKey en RowKey ). Een client kan ook entiteiten ophalen die zijn gesorteerd op werknemer-id binnen elke afdeling.
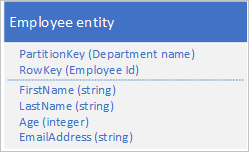
Als u ook een werknemerentiteit wilt kunnen vinden op basis van de waarde van een andere eigenschap, zoals e-mailadres, moet u een minder efficiënte partitiescan gebruiken om een overeenkomst te vinden. Dit komt doordat de tabelservice geen secundaire indexen biedt. Daarnaast is er geen optie om een lijst met werknemers aan te vragen die in een andere volgorde zijn gesorteerd dan RowKey-volgorde .
Oplossing
Als u het ontbreken van secundaire indexen wilt omzeilen, kunt u meerdere exemplaren van elke entiteit met elke kopie opslaan met behulp van een andere RowKey-waarde . Als u een entiteit opslaat met de onderstaande structuren, kunt u efficiënt werknemersentiteiten ophalen op basis van e-mailadres of werknemer-id. Met de voorvoegselwaarden voor rowkey, 'empid_' en 'email_' kunt u een query uitvoeren voor één werknemer of een bereik van werknemers met behulp van een reeks e-mailadressen of werknemer-id's.

De volgende twee filtercriteria (één die wordt opgezoekd op werknemer-id en één opzoekt op e-mailadres) geven beide puntquery's op:
- $filter=(PartitionKey eq 'Sales') en (RowKey eq 'empid_000223')
- $filter=(PartitionKey eq 'Sales') en (RowKey eq 'email_jonesj@contoso.com')
Als u een query uitvoert op een bereik van werknemersentiteiten, kunt u een bereik opgeven dat is gesorteerd in de volgorde van de werknemer-id of een bereik dat is gesorteerd in de e-mailadresvolgorde door een query uit te voeren op entiteiten met het juiste voorvoegsel in RowKey.
Als u alle werknemers in de verkoopafdeling wilt zoeken met een werknemers-id in het bereik 000100 om te 000199 gebruiken: $filter=(PartitionKey eq 'Sales') en (RowKey ge 'empid_000100') en (RowKey le 'empid_000199')
Als u alle werknemers in de afdeling Verkoop wilt zoeken met een e-mailadres dat begint met de letter 'a' gebruikt: $filter=(PartitionKey eq 'Sales') en (RowKey ge 'email_a') en (RowKey lt 'email_b')
De filtersyntaxis die in de bovenstaande voorbeelden wordt gebruikt, is afkomstig uit de REST API van de Table-service. Zie Query-entiteiten voor meer informatie.
Problemen en overwegingen
Beschouw de volgende punten als u besluit hoe u dit patroon wilt implementeren:
Tabelopslag is relatief goedkoop om te gebruiken, dus de kostenoverhead voor het opslaan van dubbele gegevens mag geen grote zorg zijn. U moet echter altijd de kosten van uw ontwerp evalueren op basis van uw verwachte opslagvereisten en alleen dubbele entiteiten toevoegen ter ondersteuning van de query's die door uw clienttoepassing worden uitgevoerd.
Omdat de secundaire indexentiteiten worden opgeslagen in dezelfde partitie als de oorspronkelijke entiteiten, moet u ervoor zorgen dat u de schaalbaarheidsdoelen voor een afzonderlijke partitie niet overschrijdt.
U kunt uw dubbele entiteiten consistent met elkaar houden door EGT's te gebruiken om de twee kopieën van de entiteit atomisch bij te werken. Dit impliceert dat u alle kopieën van een entiteit in dezelfde partitie moet opslaan. Zie de sectie Entiteitsgroeptransacties gebruiken voor meer informatie.
De waarde die voor de RowKey wordt gebruikt, moet uniek zijn voor elke entiteit. Overweeg het gebruik van samengestelde sleutelwaarden.
Als u numerieke waarden opvult in rowkey (bijvoorbeeld de werknemer-id 000223), kunt u sorteren en filteren op basis van boven- en ondergrenzen.
U hoeft niet noodzakelijkerwijs alle eigenschappen van uw entiteit te dupliceren. Als de query's die de entiteiten opzoeken met behulp van het e-mailadres in RowKey bijvoorbeeld nooit de leeftijd van de werknemer nodig hebben, kunnen deze entiteiten de volgende structuur hebben:
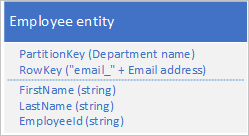
Het is meestal beter om dubbele gegevens op te slaan en ervoor te zorgen dat u alle benodigde gegevens met één query kunt ophalen, dan dat u één query gebruikt om een entiteit en een andere te zoeken om de vereiste gegevens op te zoeken.
Wanneer dit patroon gebruiken
Gebruik dit patroon wanneer uw clienttoepassing entiteiten moet ophalen met behulp van verschillende sleutels, wanneer uw client entiteiten in verschillende sorteervolgordes moet ophalen en waar u elke entiteit kunt identificeren met een verscheidenheid aan unieke waarden. U moet er echter zeker van zijn dat u de schaalbaarheidslimieten voor partities niet overschrijdt wanneer u entiteitszoekacties uitvoert met behulp van de verschillende RowKey-waarden .
Gerelateerde patronen en richtlijnen
De volgende patronen en richtlijnen zijn mogelijk ook relevant bij de implementatie van dit patroon:
- Secundair indexpatroon tussen partities
- Patroon samengestelde sleutel
- Entiteitsgroeptransacties
- Werken met heterogene entiteitstypen
Secundair indexpatroon tussen partities
Sla meerdere kopieën van elke entiteit op met behulp van verschillende RowKey-waarden in afzonderlijke partities of in afzonderlijke tabellen om snelle en efficiënte opzoekacties en alternatieve sorteervolgordes mogelijk te maken met behulp van verschillende RowKey-waarden .
Context en probleem
De Table-service indexeert automatisch entiteiten met behulp van de waarden PartitionKey en RowKey . Hierdoor kan een clienttoepassing een entiteit efficiënt ophalen met behulp van deze waarden. Met behulp van de onderstaande tabelstructuur kan een clienttoepassing bijvoorbeeld een puntquery gebruiken om een afzonderlijke werknemerentiteit op te halen met behulp van de afdelingsnaam en de werknemers-id (de waarden PartitionKey en RowKey ). Een client kan ook entiteiten ophalen die zijn gesorteerd op werknemer-id binnen elke afdeling.
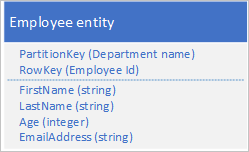
Als u ook een werknemerentiteit wilt kunnen vinden op basis van de waarde van een andere eigenschap, zoals e-mailadres, moet u een minder efficiënte partitiescan gebruiken om een overeenkomst te vinden. Dit komt doordat de tabelservice geen secundaire indexen biedt. Daarnaast is er geen optie om een lijst met werknemers aan te vragen die in een andere volgorde zijn gesorteerd dan RowKey-volgorde .
U verwacht een groot aantal transacties op basis van deze entiteiten en wilt het risico van de Table-service beperken van uw client minimaliseren.
Oplossing
Als u het ontbreken van secundaire indexen wilt omzeilen, kunt u meerdere kopieën van elke entiteit met elke kopie opslaan met behulp van verschillende PartitionKey - en RowKey-waarden . Als u een entiteit opslaat met de onderstaande structuren, kunt u efficiënt werknemersentiteiten ophalen op basis van e-mailadres of werknemer-id. Met de voorvoegselwaarden voor de PartitionKey, 'empid_' en 'email_' kunt u bepalen welke index u voor een query wilt gebruiken.

De volgende twee filtercriteria (één die wordt opgezoekd op werknemer-id en één opzoekt op e-mailadres) geven beide puntquery's op:
- $filter=(PartitionKey eq 'empid_Sales') en (RowKey eq '000223')
- $filter=(PartitionKey eq 'email_Sales') en (RowKey eq 'jonesj@contoso.com')
Als u een query uitvoert op een bereik van werknemersentiteiten, kunt u een bereik opgeven dat is gesorteerd in de volgorde van de werknemer-id of een bereik dat is gesorteerd in de e-mailadresvolgorde door een query uit te voeren op entiteiten met het juiste voorvoegsel in RowKey.
- Als u alle werknemers in de verkoopafdeling wilt zoeken met een werknemer-id in het bereik 000100 om te 000199 gesorteerd in de volgorde van werknemers-id's: $filter=(PartitionKey eq 'empid_Sales') en (RowKey ge '000100') en (RowKey le '000199')
- Als u wilt zoeken naar alle werknemers op de afdeling Verkoop met een e-mailadres dat begint met 'a' gesorteerd in e-mailadresvolgorde, gebruikt u: $filter=(PartitionKey eq 'email_Sales') en (RowKey ge 'a') en (RowKey lt 'b')
De filtersyntaxis die in de bovenstaande voorbeelden wordt gebruikt, is afkomstig uit de REST API van de Table-service. Zie Query-entiteiten voor meer informatie.
Problemen en overwegingen
Beschouw de volgende punten als u besluit hoe u dit patroon wilt implementeren:
U kunt uw dubbele entiteiten uiteindelijk consistent met elkaar houden met behulp van het patroon Uiteindelijk consistente transacties om de primaire en secundaire indexentiteiten te onderhouden.
Tabelopslag is relatief goedkoop om te gebruiken, dus de kostenoverhead voor het opslaan van dubbele gegevens mag geen grote zorg zijn. U moet echter altijd de kosten van uw ontwerp evalueren op basis van uw verwachte opslagvereisten en alleen dubbele entiteiten toevoegen ter ondersteuning van de query's die door uw clienttoepassing worden uitgevoerd.
De waarde die voor de RowKey wordt gebruikt, moet uniek zijn voor elke entiteit. Overweeg het gebruik van samengestelde sleutelwaarden.
Als u numerieke waarden opvult in rowkey (bijvoorbeeld de werknemer-id 000223), kunt u sorteren en filteren op basis van boven- en ondergrenzen.
U hoeft niet noodzakelijkerwijs alle eigenschappen van uw entiteit te dupliceren. Als de query's die de entiteiten opzoeken met behulp van het e-mailadres in RowKey bijvoorbeeld nooit de leeftijd van de werknemer nodig hebben, kunnen deze entiteiten de volgende structuur hebben:
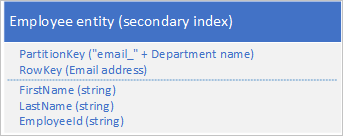
Het is doorgaans beter om dubbele gegevens op te slaan en ervoor te zorgen dat u alle gegevens die u nodig hebt met één query kunt ophalen dan één query te gebruiken om een entiteit te zoeken met behulp van de secundaire index en een andere om de vereiste gegevens in de primaire index op te zoeken.
Wanneer dit patroon gebruiken
Gebruik dit patroon wanneer uw clienttoepassing entiteiten moet ophalen met behulp van verschillende sleutels, wanneer uw client entiteiten in verschillende sorteervolgordes moet ophalen en waar u elke entiteit kunt identificeren met een verscheidenheid aan unieke waarden. Gebruik dit patroon als u wilt voorkomen dat de schaalbaarheidslimieten voor partities worden overschreden wanneer u entiteitszoekacties uitvoert met behulp van de verschillende RowKey-waarden .
Gerelateerde patronen en richtlijnen
De volgende patronen en richtlijnen zijn mogelijk ook relevant bij de implementatie van dit patroon:
- Uiteindelijk consistent transactiepatroon
- Secundair indexpatroon tussen partities
- Patroon samengestelde sleutel
- Entiteitsgroeptransacties
- Werken met heterogene entiteitstypen
Uiteindelijk consistent transactiepatroon
Schakel uiteindelijk consistent gedrag binnen partitiegrenzen of opslagsysteemgrenzen in met behulp van Azure-wachtrijen.
Context en probleem
EGT's maken atomische transacties mogelijk voor meerdere entiteiten die dezelfde partitiesleutel delen. Om prestatie- en schaalbaarheidsredenen kunt u besluiten entiteiten op te slaan die consistentievereisten hebben in afzonderlijke partities of in een afzonderlijk opslagsysteem: in een dergelijk scenario kunt u GEEN EGT's gebruiken om consistentie te behouden. U hebt bijvoorbeeld een vereiste om uiteindelijke consistentie te behouden tussen:
- Entiteiten die zijn opgeslagen in twee verschillende partities in dezelfde tabel, in verschillende tabellen of in verschillende opslagaccounts.
- Een entiteit die is opgeslagen in de Tabelservice en een blob die is opgeslagen in de Blob-service.
- Een entiteit die is opgeslagen in de Tabelservice en een bestand in een bestandssysteem.
- Een entiteit die is opgeslagen in de Table-service die nog is geïndexeerd met behulp van de Azure Cognitive Search-service.
Oplossing
Met behulp van Azure-wachtrijen kunt u een oplossing implementeren die uiteindelijke consistentie biedt voor twee of meer partities of opslagsystemen. Als u deze benadering wilt illustreren, moet u ervoor kiezen om oude werknemersentiteiten te kunnen archiveren. Oude werknemersentiteiten worden zelden opgevraagd en moeten worden uitgesloten van activiteiten die omgaan met huidige werknemers. Als u deze vereiste wilt implementeren, slaat u actieve werknemers op in de huidige tabel en oude werknemers in de tabel Archief. Voor het archiveren van een werknemer moet u de entiteit uit de huidige tabel verwijderen en de entiteit toevoegen aan de archieftabel , maar u kunt geen EGT gebruiken om deze twee bewerkingen uit te voeren. Om het risico te voorkomen dat een fout ertoe leidt dat een entiteit in beide of geen van beide tabellen wordt weergegeven, moet de archiefbewerking uiteindelijk consistent zijn. In het volgende sequentiediagram worden de stappen in deze bewerking beschreven. Meer details vindt u in de volgende tekst voor uitzonderingspaden.
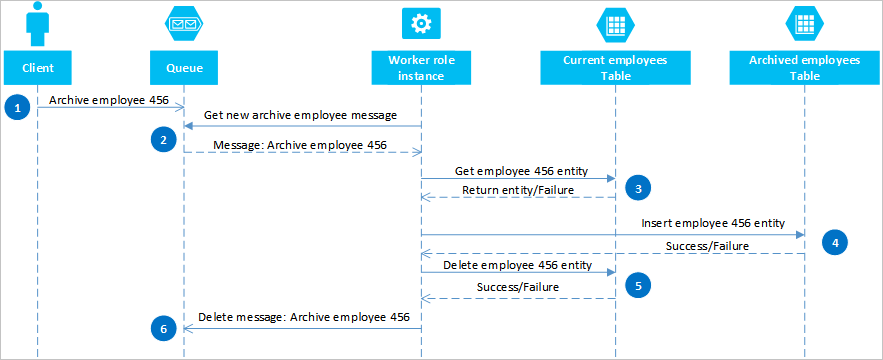
Een client initieert de archiefbewerking door een bericht in een Azure-wachtrij te plaatsen, in dit voorbeeld om werknemer #456 te archiveren. Een werkrol peilt de wachtrij voor nieuwe berichten; wanneer er een wordt gevonden, wordt het bericht gelezen en wordt er een verborgen kopie in de wachtrij achter geslagen. De werkrol haalt vervolgens een kopie van de entiteit op uit de huidige tabel, voegt een kopie in de tabel Archief in en verwijdert vervolgens het origineel uit de huidige tabel. Als er ten slotte geen fouten zijn opgetreden uit de vorige stappen, verwijdert de werkrol het verborgen bericht uit de wachtrij.
In dit voorbeeld voegt stap 4 de werknemer in de tabel Archief in. Het kan de werknemer toevoegen aan een blob in de Blob-service of een bestand in een bestandssysteem.
Herstellen van fouten
Het is belangrijk dat de bewerkingen in stap 4 en 5 idempotent moeten zijn voor het geval de werkrol de archiefbewerking opnieuw moet starten. Als u de Tabelservice gebruikt, moet u voor stap 4 een bewerking invoegen of vervangen gebruiken. Voor stap 5 moet u een bewerking verwijderen gebruiken in de clientbibliotheek die u gebruikt. Als u een ander opslagsysteem gebruikt, moet u een geschikte idempotente bewerking gebruiken.
Als de werkrol nooit stap 6 heeft voltooid, wordt het bericht na een time-out opnieuw weergegeven in de wachtrij, zodat de werkrol het opnieuw kan verwerken. De werkrol kan controleren hoe vaak een bericht in de wachtrij is gelezen en, indien nodig, een vlag toevoegen aan een 'gif'-bericht voor onderzoek door het te verzenden naar een afzonderlijke wachtrij. Zie Berichten ophalen voor meer informatie over het lezen van wachtrijberichten en het controleren van het aantal wachtrijen.
Sommige fouten van de tabel- en wachtrijservices zijn tijdelijke fouten en uw clienttoepassing moet geschikte logica voor opnieuw proberen bevatten om deze te verwerken.
Problemen en overwegingen
Beschouw de volgende punten als u besluit hoe u dit patroon wilt implementeren:
- Deze oplossing biedt geen transactieisolatie. Een client kan bijvoorbeeld de huidige en archieftabellen lezen wanneer de werkrol tussen stap 4 en 5 lag en een inconsistente weergave van de gegevens zien. De gegevens zijn uiteindelijk consistent.
- U moet ervoor zorgen dat stap 4 en 5 idempotent zijn om uiteindelijke consistentie te garanderen.
- U kunt de oplossing schalen met behulp van meerdere wachtrijen en werkrolinstanties.
Wanneer dit patroon gebruiken
Gebruik dit patroon als u uiteindelijke consistentie wilt garanderen tussen entiteiten die zich in verschillende partities of tabellen bevinden. U kunt dit patroon uitbreiden om uiteindelijke consistentie te garanderen voor bewerkingen in de Table-service en de Blob-service en andere niet-Azure Storage-gegevensbronnen, zoals een database of het bestandssysteem.
Gerelateerde patronen en richtlijnen
De volgende patronen en richtlijnen zijn mogelijk ook relevant bij de implementatie van dit patroon:
- Entiteitsgroeptransacties
- Samenvoegen of vervangen
Notitie
Als transactieisolatie belangrijk is voor uw oplossing, moet u overwegen om uw tabellen opnieuw te ontwerpen zodat u EGT's kunt gebruiken.
Patroon indexentiteiten
Onderhoud indexentiteiten om efficiënte zoekopdrachten mogelijk te maken die lijsten met entiteiten retourneren.
Context en probleem
De Table-service indexeert automatisch entiteiten met behulp van de waarden PartitionKey en RowKey . Hierdoor kan een clienttoepassing een entiteit efficiënt ophalen met behulp van een puntquery. Met behulp van de onderstaande tabelstructuur kan een clienttoepassing bijvoorbeeld efficiënt een afzonderlijke werknemerentiteit ophalen met behulp van de afdelingsnaam en de werknemer-id (de PartitionKey en RowKey).

Als u ook een lijst met werknemersentiteiten wilt kunnen ophalen op basis van de waarde van een andere niet-unieke eigenschap, zoals de achternaam, moet u een minder efficiënte partitiescan gebruiken om overeenkomsten te vinden in plaats van een index te gebruiken om ze rechtstreeks op te zoeken. Dit komt doordat de tabelservice geen secundaire indexen biedt.
Oplossing
Als u zoeken op achternaam wilt inschakelen met de entiteitsstructuur die hierboven wordt weergegeven, moet u lijsten met werknemer-id's onderhouden. Als u de werknemersentiteiten met een bepaalde achternaam wilt ophalen, zoals Jones, moet u eerst de lijst met werknemer-id's voor werknemers met Jones zoeken als achternaam en vervolgens die werknemersentiteiten ophalen. Er zijn drie hoofdopties voor het opslaan van de lijsten met werknemer-id's:
- Gebruik blobopslag.
- Indexentiteiten maken in dezelfde partitie als de werknemersentiteiten.
- Indexentiteiten maken in een afzonderlijke partitie of tabel.
Optie 1: Blob Storage gebruiken
Voor de eerste optie maakt u een blob voor elke unieke achternaam en slaat u in elke blob een lijst op met de waarden PartitionKey (afdeling) en RowKey (werknemer-id) voor werknemers met die achternaam. Wanneer u een werknemer toevoegt of verwijdert, moet u ervoor zorgen dat de inhoud van de relevante blob uiteindelijk consistent is met de werknemersentiteiten.
Optie 2: Indexentiteiten maken in dezelfde partitie
Gebruik voor de tweede optie indexentiteiten die de volgende gegevens opslaan:
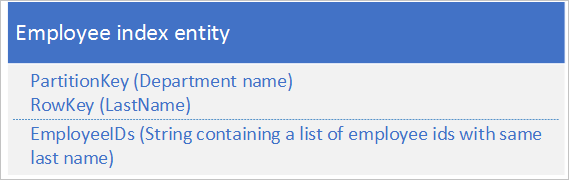
De eigenschap EmployeeIDs bevat een lijst met werknemer-id's voor werknemers met de achternaam die is opgeslagen in RowKey.
In de volgende stappen wordt het proces beschreven dat u moet volgen wanneer u een nieuwe werknemer toevoegt als u de tweede optie gebruikt. In dit voorbeeld voegen we een werknemer toe met id-000152 en een achternaam Jones in de afdeling Verkoop:
- Haal de indexentiteit op met een PartitionKey-waarde 'Sales' en de RowKey-waarde 'Jones'. Sla de ETag van deze entiteit op die u in stap 2 wilt gebruiken.
- Maak een entiteitsgroeptransactie (dat wil gezegd een batchbewerking) die de nieuwe werknemerentiteit invoegt (PartitionKey-waarde 'Verkoop' en RowKey-waarde '000152'), en werkt de indexentiteit (PartitionKey-waarde 'Verkoop' en RowKey-waarde 'Jones' bij door de nieuwe werknemer-id's toe te voegen aan de lijst in het veld EmployeeIDs. Zie Entiteitsgroeptransacties voor meer informatie over entiteitsgroeptransacties.
- Als de transactie van de entiteitsgroep mislukt vanwege een optimistische gelijktijdigheidsfout (iemand anders heeft de indexentiteit zojuist gewijzigd), moet u opnieuw beginnen bij stap 1.
U kunt een vergelijkbare methode gebruiken om een werknemer te verwijderen als u de tweede optie gebruikt. Het wijzigen van de achternaam van een werknemer is iets complexer omdat u een entiteitsgroeptransactie moet uitvoeren waarmee drie entiteiten worden bijgewerkt: de werknemerentiteit, de indexentiteit voor de oude achternaam en de indexentiteit voor de nieuwe achternaam. U moet elke entiteit ophalen voordat u wijzigingen aanbrengt om de ETag-waarden op te halen die u vervolgens kunt gebruiken om de updates uit te voeren met optimistische gelijktijdigheid.
In de volgende stappen wordt het proces beschreven dat u moet volgen wanneer u alle werknemers met een bepaalde achternaam in een afdeling moet opzoeken als u de tweede optie gebruikt. In dit voorbeeld zoeken we alle werknemers op met achternaam Jones op de afdeling Verkoop:
- Haal de indexentiteit op met een PartitionKey-waarde 'Sales' en de RowKey-waarde 'Jones'.
- Parseert de lijst met werknemer-id's in het veld Werknemer-id's.
- Als u aanvullende informatie nodig hebt over elk van deze werknemers (zoals hun e-mailadressen), haalt u elk van de werknemersentiteiten op met behulp van partitionKey-waarde Verkoop en RowKey-waarden uit de lijst met werknemers die u in stap 2 hebt verkregen.
Optie 3: Indexentiteiten maken in een afzonderlijke partitie of tabel
Gebruik voor de derde optie indexentiteiten die de volgende gegevens opslaan:

De eigenschap EmployeeDetails bevat een lijst met werknemer-id's en afdelingsnaamparen voor werknemers met de achternaam die is opgeslagen in de RowKey.
Met de derde optie kunt u GEEN EGT's gebruiken om consistentie te behouden, omdat de indexentiteiten zich in een afzonderlijke partitie bevinden van de werknemersentiteiten. Zorg ervoor dat de indexentiteiten uiteindelijk consistent zijn met de werknemersentiteiten.
Problemen en overwegingen
Beschouw de volgende punten als u besluit hoe u dit patroon wilt implementeren:
- Voor deze oplossing zijn ten minste twee query's vereist om overeenkomende entiteiten op te halen: één om een query uit te voeren op de indexentiteiten om de lijst met RowKey-waarden op te halen en vervolgens query's uit te voeren om elke entiteit in de lijst op te halen.
- Aangezien een afzonderlijke entiteit een maximale grootte van 1 MB heeft, gaan optie 2 en optie 3 in de oplossing ervan uit dat de lijst met werknemer-id's voor een bepaalde achternaam nooit groter is dan 1 MB. Als de lijst met werknemer-id's waarschijnlijk groter is dan 1 MB, gebruikt u optie 1 en slaat u de indexgegevens op in blobopslag.
- Als u optie 2 gebruikt (met BEHULP van EGT's voor het afhandelen van het toevoegen en verwijderen van werknemers en het wijzigen van de achternaam van een werknemer), moet u evalueren of het volume van transacties de schaalbaarheidslimieten in een bepaalde partitie nadert. Als dit het geval is, moet u een uiteindelijk consistente oplossing (optie 1 of optie 3) overwegen die gebruikmaakt van wachtrijen om de updateaanvragen af te handelen en waarmee u uw indexentiteiten in een afzonderlijke partitie kunt opslaan van de werknemersentiteiten.
- Bij optie 2 in deze oplossing wordt ervan uitgegaan dat u wilt opzoeken op achternaam binnen een afdeling: u wilt bijvoorbeeld een lijst met werknemers met een achternaam Jones in de afdeling Verkoop ophalen. Als u alle werknemers wilt kunnen opzoeken met een achternaam Jones in de hele organisatie, gebruikt u optie 1 of optie 3.
- U kunt een oplossing op basis van een wachtrij implementeren die uiteindelijke consistentie biedt (zie het patroon Uiteindelijk consistente transacties voor meer informatie).
Wanneer dit patroon gebruiken
Gebruik dit patroon als u een set entiteiten wilt opzoeken die allemaal een gemeenschappelijke eigenschapswaarde delen, zoals alle werknemers met de achternaam Jones.
Gerelateerde patronen en richtlijnen
De volgende patronen en richtlijnen zijn mogelijk ook relevant bij de implementatie van dit patroon:
- Patroon samengestelde sleutel
- Uiteindelijk consistent transactiepatroon
- Entiteitsgroeptransacties
- Werken met heterogene entiteitstypen
Denormalisatiepatroon
Combineer gerelateerde gegevens in één entiteit zodat u alle gegevens kunt ophalen die u nodig hebt met een enkele puntquery.
Context en probleem
In een relationele database normaliseert u doorgaans gegevens om duplicatie te verwijderen, wat resulteert in query's die gegevens uit meerdere tabellen ophalen. Als u uw gegevens in Azure-tabellen normaliseert, moet u meerdere retouren van de client naar de server maken om uw gerelateerde gegevens op te halen. Met de tabelstructuur die hieronder wordt weergegeven, hebt u bijvoorbeeld twee retouren nodig om de details voor een afdeling op te halen: een om de afdelingsentiteit op te halen die de id van de manager bevat en vervolgens een andere aanvraag om de details van de manager op te halen in een werknemersentiteit.

Oplossing
In plaats van de gegevens in twee afzonderlijke entiteiten op te slaan, denormaliseert u de gegevens en bewaart u een kopie van de details van de manager in de afdelingsentiteit. Voorbeeld:
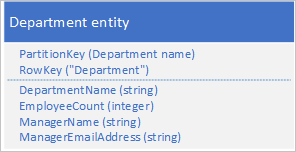
Met afdelingsentiteiten die met deze eigenschappen zijn opgeslagen, kunt u nu alle details ophalen die u nodig hebt over een afdeling met behulp van een puntquery.
Problemen en overwegingen
Beschouw de volgende punten als u besluit hoe u dit patroon wilt implementeren:
- Er is wat kostenoverhead verbonden aan het opslaan van enkele gegevens twee keer. Het prestatievoordeel (als gevolg van minder aanvragen voor de opslagservice) weegt doorgaans op tegen de marginale toename van de opslagkosten (en deze kosten worden gedeeltelijk gecompenseerd door een vermindering van het aantal transacties dat u nodig hebt om de details van een afdeling op te halen).
- U moet de consistentie behouden van de twee entiteiten die informatie over managers opslaan. U kunt het consistentieprobleem afhandelen met behulp van EGT's om meerdere entiteiten in één atomische transactie bij te werken: in dit geval worden de afdelingsentiteit en de werknemersentiteit voor de afdelingsmanager opgeslagen in dezelfde partitie.
Wanneer dit patroon gebruiken
Gebruik dit patroon wanneer u regelmatig gerelateerde informatie moet opzoeken. Dit patroon vermindert het aantal query's dat uw client moet maken om de benodigde gegevens op te halen.
Gerelateerde patronen en richtlijnen
De volgende patronen en richtlijnen zijn mogelijk ook relevant bij de implementatie van dit patroon:
- Patroon samengestelde sleutel
- Entiteitsgroeptransacties
- Werken met heterogene entiteitstypen
Patroon samengestelde sleutel
Gebruik samengestelde RowKey-waarden om een client in staat te stellen gerelateerde gegevens op te zoeken met één puntquery.
Context en probleem
In een relationele database is het natuurlijk om joins in query's te gebruiken om gerelateerde gegevens te retourneren aan de client in één query. U kunt bijvoorbeeld de werknemers-id gebruiken om een lijst met gerelateerde entiteiten op te zoeken die prestaties bevatten en gegevens voor die werknemer controleren.
Stel dat u werknemersentiteiten opslaat in de Tabelservice met behulp van de volgende structuur:
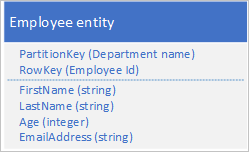
U moet ook historische gegevens opslaan met betrekking tot beoordelingen en prestaties voor elk jaar dat de werknemer heeft gewerkt voor uw organisatie en u moet toegang hebben tot deze informatie per jaar. Een optie is om een andere tabel te maken waarin entiteiten met de volgende structuur worden opgeslagen:
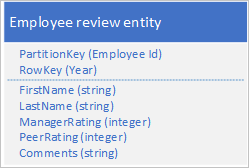
U kunt met deze benadering besluiten om bepaalde gegevens (zoals voornaam en achternaam) in de nieuwe entiteit te dupliceren, zodat u uw gegevens met één aanvraag kunt ophalen. U kunt echter geen sterke consistentie behouden omdat u geen EGT kunt gebruiken om de twee entiteiten atomisch bij te werken.
Oplossing
Sla een nieuw entiteitstype op in de oorspronkelijke tabel met behulp van entiteiten met de volgende structuur:
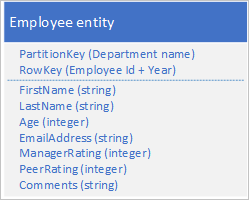
U ziet dat RowKey nu een samengestelde sleutel is die bestaat uit de werknemers-id en het jaar van de beoordelingsgegevens waarmee u de prestaties van de werknemer kunt ophalen en gegevens kunt controleren met één aanvraag voor één entiteit.
In het volgende voorbeeld ziet u hoe u alle beoordelingsgegevens voor een bepaalde werknemer kunt ophalen (zoals werknemers 000123 in de verkoopafdeling):
$filter=(PartitionKey eq 'Sales') en (RowKey ge 'empid_000123') en (RowKey lt '000123_2012')&$select=RowKey,Manager Rating,Peer Rating,Comments
Problemen en overwegingen
Beschouw de volgende punten als u besluit hoe u dit patroon wilt implementeren:
- U moet een geschikt scheidingsteken gebruiken waarmee u de rowkey-waarde eenvoudig kunt parseren, bijvoorbeeld 000123_2012.
- U slaat deze entiteit ook op in dezelfde partitie als andere entiteiten die gerelateerde gegevens voor dezelfde werknemer bevatten. Dit betekent dat u EGT's kunt gebruiken om sterke consistentie te behouden.
- U moet overwegen hoe vaak u de gegevens opvraagt om te bepalen of dit patroon geschikt is. Als u bijvoorbeeld regelmatig toegang krijgt tot de controlegegevens en de belangrijkste werknemersgegevens, moet u ze vaak als afzonderlijke entiteiten bewaren.
Wanneer dit patroon gebruiken
Gebruik dit patroon wanneer u een of meer gerelateerde entiteiten wilt opslaan die u regelmatig opvraagt.
Gerelateerde patronen en richtlijnen
De volgende patronen en richtlijnen zijn mogelijk ook relevant bij de implementatie van dit patroon:
- Entiteitsgroeptransacties
- Werken met heterogene entiteitstypen
- Uiteindelijk consistent transactiepatroon
Logboekstaartpatroon
Haal de n entiteiten op die het laatst aan een partitie zijn toegevoegd met behulp van een RowKey-waarde die in omgekeerde datum- en tijdvolgorde sorteert.
Context en probleem
Een veelvoorkomende vereiste is het ophalen van de laatst gemaakte entiteiten, bijvoorbeeld de 10 meest recente onkostenclaims die door een werknemer zijn ingediend. Tabelquery's ondersteunen een $top querybewerking om de eerste n entiteiten uit een set te retourneren: er is geen equivalente querybewerking om de laatste n entiteiten in een set te retourneren.
Oplossing
Sla de entiteiten op met behulp van een RowKey die op natuurlijke wijze in omgekeerde datum-/tijdvolgorde sorteert, zodat het meest recente item altijd de eerste in de tabel is.
Als u bijvoorbeeld de 10 meest recente onkostenclaims wilt ophalen die door een werknemer zijn ingediend, kunt u een omgekeerde maatstreepwaarde gebruiken die is afgeleid van de huidige datum/tijd. In het volgende C#-codevoorbeeld ziet u een manier om een geschikte 'omgekeerde maatstreepjes' te maken voor een RowKey die van de meest recente naar de oudste sorteert:
string invertedTicks = string.Format("{0:D19}", DateTime.MaxValue.Ticks - DateTime.UtcNow.Ticks);
U kunt teruggaan naar de datum/tijd-waarde met behulp van de volgende code:
DateTime dt = new DateTime(DateTime.MaxValue.Ticks - Int64.Parse(invertedTicks));
De tabelquery ziet er als volgt uit:
https://myaccount.table.core.windows.net/EmployeeExpense(PartitionKey='empid')?$top=10
Problemen en overwegingen
Beschouw de volgende punten als u besluit hoe u dit patroon wilt implementeren:
- U moet de waarde voor omgekeerde maatstreepjes met voorloopnullen instellen om ervoor te zorgen dat de tekenreekswaarde naar verwachting wordt gesorteerd.
- U moet rekening houden met de schaalbaarheidsdoelen op het niveau van een partitie. Wees voorzichtig met het maken van hot spot-partities.
Wanneer dit patroon gebruiken
Gebruik dit patroon wanneer u toegang nodig hebt tot entiteiten in volgorde van omgekeerde datum/tijd of wanneer u toegang nodig hebt tot de laatst toegevoegde entiteiten.
Gerelateerde patronen en richtlijnen
De volgende patronen en richtlijnen zijn mogelijk ook relevant bij de implementatie van dit patroon:
Patroon voor verwijderen van hoog volume
Schakel het verwijderen van een groot aantal entiteiten in door alle entiteiten op te slaan voor gelijktijdige verwijdering in hun eigen afzonderlijke tabel; u de entiteiten verwijdert door de tabel te verwijderen.
Context en probleem
Veel toepassingen verwijderen oude gegevens die niet meer beschikbaar hoeven te zijn voor een clienttoepassing of die de toepassing heeft gearchiveerd op een ander opslagmedium. U identificeert dergelijke gegevens meestal op een datum: u hebt bijvoorbeeld een vereiste om records te verwijderen van alle aanmeldingsaanvragen die meer dan 60 dagen oud zijn.
Een mogelijk ontwerp is het gebruik van de datum en tijd van de aanmeldingsaanvraag in de RowKey:
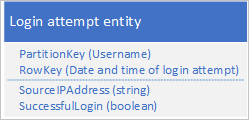
Deze aanpak voorkomt partitie-hotspots omdat de toepassing aanmeldingsentiteiten voor elke gebruiker in een afzonderlijke partitie kan invoegen en verwijderen. Deze aanpak kan echter kostbaar en tijdrovend zijn als u een groot aantal entiteiten hebt, omdat u eerst een tabelscan moet uitvoeren om alle entiteiten te identificeren die moeten worden verwijderd. Vervolgens moet u elke oude entiteit verwijderen. U kunt het aantal retouren naar de server beperken dat nodig is om de oude entiteiten te verwijderen door meerdere verwijderaanvragen in EGT's te batcheren.
Oplossing
Gebruik een afzonderlijke tabel voor elke dag van aanmeldingspogingen. U kunt het bovenstaande entiteitsontwerp gebruiken om hotspots te voorkomen wanneer u entiteiten invoegt, en het verwijderen van oude entiteiten is nu gewoon een kwestie van het elke dag verwijderen van één tabel (één opslagbewerking) in plaats van honderden en duizenden afzonderlijke aanmeldingsentiteiten elke dag te zoeken en te verwijderen.
Problemen en overwegingen
Beschouw de volgende punten als u besluit hoe u dit patroon wilt implementeren:
- Ondersteunt uw ontwerp andere manieren waarop uw toepassing de gegevens gebruikt, zoals het opzoeken van specifieke entiteiten, het koppelen met andere gegevens of het genereren van geaggregeerde informatie?
- Voorkomt uw ontwerp hotspots wanneer u nieuwe entiteiten invoegt?
- Verwacht een vertraging als u dezelfde tabelnaam opnieuw wilt gebruiken nadat u deze hebt verwijderd. Het is beter om altijd unieke tabelnamen te gebruiken.
- Verwacht enige beperking wanneer u voor het eerst een nieuwe tabel gebruikt terwijl de Table-service de toegangspatronen leert en de partities over knooppunten distribueert. U moet overwegen hoe vaak u nieuwe tabellen moet maken.
Wanneer dit patroon gebruiken
Gebruik dit patroon wanneer u een groot aantal entiteiten hebt die u tegelijkertijd moet verwijderen.
Gerelateerde patronen en richtlijnen
De volgende patronen en richtlijnen zijn mogelijk ook relevant bij de implementatie van dit patroon:
- Entiteitsgroeptransacties
- Entiteiten wijzigen
Patroon gegevensreeks
Sla volledige gegevensreeksen op in één entiteit om het aantal aanvragen dat u doet te minimaliseren.
Context en probleem
Een veelvoorkomend scenario is dat een toepassing een reeks gegevens opslaat die doorgaans in één keer moeten worden opgehaald. Uw toepassing kan bijvoorbeeld vastleggen hoeveel chatberichten elke werknemer elk uur verzendt en vervolgens deze informatie gebruiken om te tekenen hoeveel berichten elke gebruiker heeft verzonden gedurende de voorgaande 24 uur. Eén ontwerp kan zijn om 24 entiteiten op te slaan voor elke werknemer:
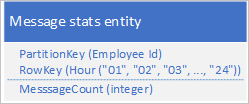
Met dit ontwerp kunt u de entiteit eenvoudig vinden en bijwerken om bij te werken voor elke werknemer wanneer de toepassing de waarde van het aantal berichten moet bijwerken. Als u echter de informatie wilt ophalen om een grafiek van de activiteit voor de voorgaande 24 uur te tekenen, moet u 24 entiteiten ophalen.
Oplossing
Gebruik het volgende ontwerp met een afzonderlijke eigenschap om het aantal berichten voor elk uur op te slaan:
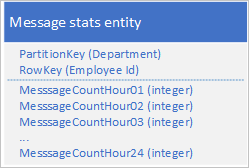
Met dit ontwerp kunt u een samenvoegbewerking gebruiken om het aantal berichten voor een werknemer voor een bepaald uur bij te werken. U kunt nu alle informatie ophalen die u nodig hebt om de grafiek uit te zetten met behulp van een aanvraag voor één entiteit.
Problemen en overwegingen
Beschouw de volgende punten als u besluit hoe u dit patroon wilt implementeren:
- Als uw volledige gegevensreeks niet in één entiteit past (een entiteit kan maximaal 252 eigenschappen hebben), gebruikt u een alternatief gegevensarchief, zoals een blob.
- Als u meerdere clients tegelijk een entiteit bijwerkt, moet u de ETag gebruiken om optimistische gelijktijdigheid te implementeren. Als u veel klanten hebt, ondervindt u mogelijk veel conflicten.
Wanneer dit patroon gebruiken
Gebruik dit patroon wanneer u een gegevensreeks moet bijwerken en ophalen die is gekoppeld aan een afzonderlijke entiteit.
Gerelateerde patronen en richtlijnen
De volgende patronen en richtlijnen zijn mogelijk ook relevant bij de implementatie van dit patroon:
- Patroon grote entiteiten
- Samenvoegen of vervangen
- Uiteindelijk consistent transactiepatroon (als u de gegevensreeks opslaat in een blob)
Patroon brede entiteiten
Gebruik meerdere fysieke entiteiten om logische entiteiten met meer dan 252 eigenschappen op te slaan.
Context en probleem
Een afzonderlijke entiteit mag niet meer dan 252 eigenschappen hebben (met uitzondering van de verplichte systeemeigenschappen) en mag in totaal niet meer dan 1 MB aan gegevens opslaan. In een relationele database krijgt u doorgaans alle limieten voor de grootte van een rij door een nieuwe tabel toe te voegen en een 1-op-1-relatie ertussen af te dwingen.
Oplossing
Met de Table-service kunt u meerdere entiteiten opslaan om één groot bedrijfsobject met meer dan 252 eigenschappen weer te geven. Als u bijvoorbeeld het aantal chatberichten wilt opslaan dat de afgelopen 365 dagen door elke werknemer is verzonden, kunt u het volgende ontwerp gebruiken dat gebruikmaakt van twee entiteiten met verschillende schema's:
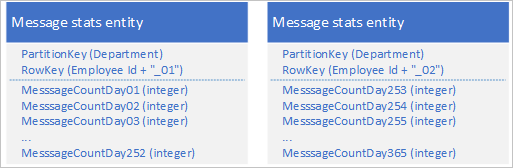
Als u een wijziging wilt aanbrengen die vereist dat beide entiteiten worden bijgewerkt om ze gesynchroniseerd met elkaar te houden, kunt u een EGT gebruiken. Anders kunt u één samenvoegbewerking gebruiken om het aantal berichten voor een specifieke dag bij te werken. Als u alle gegevens voor een afzonderlijke werknemer wilt ophalen, moet u beide entiteiten ophalen, wat u kunt doen met twee efficiënte aanvragen die zowel een PartitionKey - als een RowKey-waarde gebruiken.
Problemen en overwegingen
Beschouw de volgende punten als u besluit hoe u dit patroon wilt implementeren:
- Het ophalen van een volledige logische entiteit omvat ten minste twee opslagtransacties: één om elke fysieke entiteit op te halen.
Wanneer dit patroon gebruiken
Gebruik dit patroon wanneer u entiteiten wilt opslaan waarvan de grootte of het aantal eigenschappen de limieten voor een afzonderlijke entiteit in de Tabelservice overschrijdt.
Gerelateerde patronen en richtlijnen
De volgende patronen en richtlijnen zijn mogelijk ook relevant bij de implementatie van dit patroon:
- Entiteitsgroeptransacties
- Samenvoegen of vervangen
Patroon grote entiteiten
Gebruik blobopslag om grote eigenschapswaarden op te slaan.
Context en probleem
Een afzonderlijke entiteit kan in totaal niet meer dan 1 MB aan gegevens opslaan. Als een of meer van uw eigenschappen waarden opslaan die ervoor zorgen dat de totale grootte van uw entiteit deze waarde overschrijdt, kunt u de hele entiteit niet opslaan in de tabelservice.
Oplossing
Als uw entiteit groter is dan 1 MB omdat een of meer eigenschappen een grote hoeveelheid gegevens bevatten, kunt u gegevens opslaan in de Blob-service en vervolgens het adres van de blob opslaan in een eigenschap in de entiteit. U kunt bijvoorbeeld de foto van een werknemer opslaan in blobopslag en een koppeling naar de foto opslaan in de eigenschap Foto van uw werknemersentiteit:
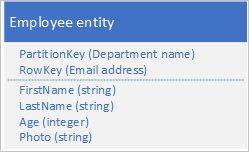
Problemen en overwegingen
Beschouw de volgende punten als u besluit hoe u dit patroon wilt implementeren:
- Als u de uiteindelijke consistentie tussen de entiteit in de Tabelservice en de gegevens in de Blob-service wilt behouden, gebruikt u het patroon Uiteindelijk consistente transacties om uw entiteiten te onderhouden.
- Het ophalen van een volledige entiteit omvat ten minste twee opslagtransacties: één om de entiteit op te halen en één om de blobgegevens op te halen.
Wanneer dit patroon gebruiken
Gebruik dit patroon wanneer u entiteiten wilt opslaan waarvan de grootte groter is dan de limieten voor een afzonderlijke entiteit in de Tabelservice.
Gerelateerde patronen en richtlijnen
De volgende patronen en richtlijnen zijn mogelijk ook relevant bij de implementatie van dit patroon:
Antipatroon voorbereiden/toevoegen
Verhoog de schaalbaarheid wanneer u een groot aantal invoegingen hebt door de invoegingen over meerdere partities te spreiden.
Context en probleem
Het vooraf toewijzen of toevoegen van entiteiten aan uw opgeslagen entiteiten resulteert doorgaans in het toevoegen van nieuwe entiteiten aan de eerste of laatste partitie van een reeks partities. In dit geval vinden alle invoegingen op een bepaald moment plaats in dezelfde partitie, waardoor een hotspot wordt gemaakt die voorkomt dat de tabelservice taakverdeling op meerdere knooppunten invoegt en waardoor uw toepassing de schaalbaarheidsdoelen voor partities kan bereiken. Als u bijvoorbeeld een toepassing hebt die netwerk- en resourcetoegang registreert door werknemers, kan een entiteitsstructuur, zoals hieronder wordt weergegeven, ertoe leiden dat de partitie van het huidige uur een hotspot wordt als het volume van transacties het schaalbaarheidsdoel voor een afzonderlijke partitie bereikt:

Oplossing
De volgende alternatieve entiteitsstructuur voorkomt een hotspot op een bepaalde partitie, omdat de toepassing gebeurtenissen registreert:
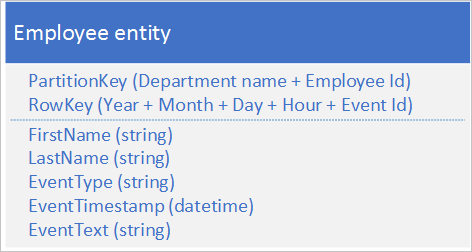
In dit voorbeeld ziet u hoe zowel PartitionKey als RowKey samengestelde sleutels zijn. De PartitionKey gebruikt zowel de afdelings- als werknemers-id om de logboekregistratie over meerdere partities te verdelen.
Problemen en overwegingen
Beschouw de volgende punten als u besluit hoe u dit patroon wilt implementeren:
- Ondersteunt de alternatieve sleutelstructuur die het maken van dynamische partities op invoegingen op efficiënte wijze ondersteunt de query's die uw clienttoepassing maakt?
- Betekent het verwachte volume van transacties dat u waarschijnlijk de schaalbaarheidsdoelen voor een afzonderlijke partitie bereikt en wordt beperkt door de opslagservice?
Wanneer dit patroon gebruiken
Vermijd het antipatroon voor prepend/append wanneer uw volume van transacties waarschijnlijk leidt tot beperking door de opslagservice wanneer u toegang hebt tot een dynamische partitie.
Gerelateerde patronen en richtlijnen
De volgende patronen en richtlijnen zijn mogelijk ook relevant bij de implementatie van dit patroon:
Antipatroon logboekgegevens
Normaal gesproken moet u de Blob-service gebruiken in plaats van de Table-service om logboekgegevens op te slaan.
Context en probleem
Een veelvoorkomend gebruiksvoorbeeld voor logboekgegevens is het ophalen van een selectie logboekvermeldingen voor een specifiek datum-/tijdbereik: u wilt bijvoorbeeld alle foutberichten en kritieke berichten vinden die uw toepassing heeft geregistreerd tussen 15:04 en 15:06 op een specifieke datum. U wilt de datum en tijd van het logboekbericht niet gebruiken om de partitie te bepalen waarin u logboekentiteiten opslaat: dit resulteert in een dynamische partitie, omdat alle logboekentiteiten op een bepaald moment dezelfde PartitionKey-waarde delen (zie de sectie Prepend/append anti-patroon). Het volgende entiteitsschema voor een logboekbericht resulteert bijvoorbeeld in een dynamische partitie omdat de toepassing alle logboekberichten naar de partitie schrijft voor de huidige datum en het huidige uur:
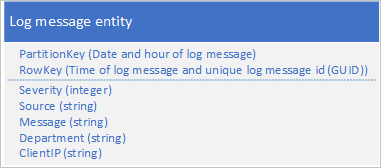
In dit voorbeeld bevat RowKey de datum en tijd van het logboekbericht om ervoor te zorgen dat logboekberichten worden opgeslagen in datum-/tijdvolgorde en een bericht-id bevat voor het geval meerdere logboekberichten dezelfde datum en tijd delen.
Een andere benadering is het gebruik van een PartitionKey die ervoor zorgt dat de toepassing berichten schrijft over een bereik van partities. Als de bron van het logboekbericht bijvoorbeeld een manier biedt om berichten over veel partities te distribueren, kunt u het volgende entiteitsschema gebruiken:
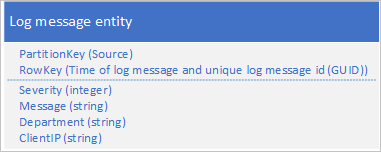
Het probleem met dit schema is echter dat u alle logboekberichten voor een bepaalde periode wilt ophalen, u elke partitie in de tabel moet doorzoeken.
Oplossing
In de vorige sectie is het probleem gemarkeerd van het gebruik van de Tabelservice voor het opslaan van logboekvermeldingen en voorgestelde twee, onbevredigende ontwerpen. Eén oplossing leidde tot een dynamische partitie met het risico van slechte prestaties bij het schrijven van logboekberichten; de andere oplossing resulteerde in slechte queryprestaties vanwege de vereiste om elke partitie in de tabel te scannen om logboekberichten voor een bepaalde periode op te halen. Blob Storage biedt een betere oplossing voor dit type scenario en dit is hoe Azure Opslaganalyse de logboekgegevens opslaat die worden verzameld.
In deze sectie wordt beschreven hoe Opslaganalyse logboekgegevens opslaat in blobopslag als illustratie van deze benadering voor het opslaan van gegevens die u doorgaans op bereik uitvoert.
Opslaganalyse slaat logboekberichten op in een gescheiden indeling in meerdere blobs. De indeling met scheidingstekens maakt het eenvoudig voor een clienttoepassing om de gegevens in het logboekbericht te parseren.
Opslaganalyse gebruikt een naamconventie voor blobs waarmee u de blob (of blobs) kunt vinden die de logboekberichten bevatten waarnaar u zoekt. Een blob met de naam 'queue/2014/07/31/1800/000001.log' bevat logboekberichten die betrekking hebben op de wachtrijservice voor het uur vanaf 18:00 uur op 31 juli 2014. De 000001 geeft aan dat dit het eerste logboekbestand voor deze periode is. Opslaganalyse registreert ook de tijdstempels van de eerste en laatste logboekberichten die zijn opgeslagen in het bestand als onderdeel van de metagegevens van de blob. Met de API voor blobopslag kunt u blobs in een container vinden op basis van een naamvoorvoegsel: om alle blobs te zoeken die logboekgegevens van de wachtrij bevatten voor het uur vanaf 18:00 uur, kunt u het voorvoegsel 'queue/2014/07/31/1800' gebruiken.
Opslaganalyse buffert logboekberichten intern en werkt vervolgens periodiek de juiste blob bij of maakt een nieuwe met de nieuwste batch logboekvermeldingen. Dit vermindert het aantal schrijfbewerkingen dat moet worden uitgevoerd naar de blobservice.
Als u een vergelijkbare oplossing in uw eigen toepassing implementeert, moet u rekening houden met het beheren van de afweging tussen betrouwbaarheid (het schrijven van elke logboekvermelding naar blobopslag als dit gebeurt) en kosten en schaalbaarheid (updates in uw toepassing bufferen en schrijven naar blob-opslag in batches).
Problemen en overwegingen
Houd rekening met de volgende punten bij het bepalen hoe logboekgegevens moeten worden opgeslagen:
- Als u een tabelontwerp maakt dat potentiële dynamische partities vermijdt, is het mogelijk dat u geen toegang hebt tot uw logboekgegevens.
- Voor het verwerken van logboekgegevens moet een client vaak veel records laden.
- Hoewel logboekgegevens vaak gestructureerd zijn, is blobopslag mogelijk een betere oplossing.
Implementatieoverwegingen
In deze sectie worden enkele overwegingen besproken waarmee u rekening moet houden wanneer u de patronen implementeert die in de vorige secties worden beschreven. In de meeste secties worden voorbeelden gebruikt die zijn geschreven in C# die gebruikmaken van de Storage-clientbibliotheek (versie 4.3.0 op het moment van schrijven).
Entiteiten ophalen
Zoals besproken in de sectie Ontwerpen voor het uitvoeren van query's, is de meest efficiënte query een puntquery. In sommige scenario's moet u echter mogelijk meerdere entiteiten ophalen. In deze sectie worden enkele algemene benaderingen beschreven voor het ophalen van entiteiten met behulp van de Storage-clientbibliotheek.
Een puntquery uitvoeren met behulp van de Storage-clientbibliotheek
De eenvoudigste manier om een puntquery uit te voeren, is door de GetEntityAsync-methode te gebruiken, zoals wordt weergegeven in het volgende C#-codefragment waarmee een entiteit wordt opgehaald met een PartitionKey van waarde 'Sales' en een RowKey van waarde '212':
EmployeeEntity employee = await employeeTable.GetEntityAsync<EmployeeEntity>("Sales", "212");
U ziet hoe in dit voorbeeld wordt verwacht dat de entiteit die wordt opgehaald van het type EmployeeEntity is.
Meerdere entiteiten ophalen met LINQ
U kunt LINQ gebruiken om meerdere entiteiten op te halen uit de Table-service wanneer u werkt met de Standaardbibliotheek van Microsoft Azure Cosmos DB Table.
dotnet add package Azure.Data.Tables
Als u de onderstaande voorbeelden wilt laten werken, moet u naamruimten opnemen:
using System.Linq;
using Azure.Data.Tables
Het ophalen van meerdere entiteiten kan worden bereikt door een query met een filtercomponent op te geven. Als u een tabelscan wilt voorkomen, moet u altijd de PartitionKey-waarde in de filtercomponent opnemen en zo mogelijk de RowKey-waarde om tabel- en partitiescans te voorkomen. De tabelservice ondersteunt een beperkte set vergelijkingsoperatoren (groter dan, groter dan of gelijk aan, kleiner dan of gelijk aan, gelijk aan en niet gelijk) die in de filtercomponent moeten worden gebruikt.
In het volgende voorbeeld employeeTable is een TableClient-object . In dit voorbeeld worden alle werknemers gevonden waarvan de achternaam begint met 'B' (ervan uitgaande dat de RowKey de achternaam opslaat) in de verkoopafdeling (ervan uitgaande dat de PartitionKey de afdelingsnaam opslaat):
var employees = employeeTable.Query<EmployeeEntity>(e => (e.PartitionKey == "Sales" && e.RowKey.CompareTo("B") >= 0 && e.RowKey.CompareTo("C") < 0));
U ziet hoe de query zowel een RowKey als een PartitionKey opgeeft om betere prestaties te garanderen.
Het volgende codevoorbeeld toont equivalente functionaliteit zonder LINQ-syntaxis te gebruiken:
var employees = employeeTable.Query<EmployeeEntity>(filter: $"PartitionKey eq 'Sales' and RowKey ge 'B' and RowKey lt 'C'");
Notitie
De voorbeeldquerymethoden bevatten de drie filtervoorwaarden.
Grote aantallen entiteiten ophalen uit een query
Een optimale query retourneert een afzonderlijke entiteit op basis van een PartitionKey-waarde en een RowKey-waarde . In sommige scenario's hebt u echter mogelijk een vereiste om veel entiteiten van dezelfde partitie of zelfs van veel partities te retourneren.
In dergelijke scenario's moet u altijd de prestaties van uw toepassing volledig testen.
Een query voor de tabelservice kan maximaal 1000 entiteiten tegelijk retourneren en maximaal vijf seconden worden uitgevoerd. Als de resultatenset meer dan 1000 entiteiten bevat, als de query niet binnen vijf seconden is voltooid of als de query de partitiegrens overschrijdt, retourneert de Table-service een vervolgtoken om de clienttoepassing in staat te stellen de volgende set entiteiten aan te vragen. Zie Time-out en paginering van query's voor meer informatie over de werking van vervolgtokens.
Als u de Azure Tables-clientbibliotheek gebruikt, kan deze automatisch vervolgtokens voor u verwerken terwijl entiteiten uit de Table-service worden geretourneerd. In het volgende C#-codevoorbeeld met behulp van de clientbibliotheek worden vervolgtokens automatisch verwerkt als de tabelservice deze retourneert in een antwoord:
var employees = employeeTable.Query<EmployeeEntity>("PartitionKey eq 'Sales'")
foreach (var emp in employees)
{
// ...
}
U kunt ook het maximum aantal entiteiten opgeven dat per pagina wordt geretourneerd. In het volgende voorbeeld ziet u hoe u query's uitvoert op entiteiten met maxPerPage:
var employees = employeeTable.Query<EmployeeEntity>(maxPerPage: 10);
// Iterate the Pageable object by page
foreach (var page in employees.AsPages())
{
// Iterate the entities returned for this page
foreach (var emp in page.Values)
{
// ...
}
}
In geavanceerdere scenario's wilt u mogelijk het vervolgtoken opslaan dat wordt geretourneerd door de service, zodat uw code precies bepaalt wanneer de volgende pagina's worden opgehaald. In het volgende voorbeeld ziet u een basisscenario van hoe het token kan worden opgehaald en toegepast op gepagineerde resultaten:
string continuationToken = null;
bool moreResultsAvailable = true;
while (moreResultsAvailable)
{
var page = employeeTable
.Query<EmployeeEntity>()
.AsPages(continuationToken, pageSizeHint: 10)
.FirstOrDefault(); // pageSizeHint limits the number of results in a single page, so we only enumerate the first page
if (page == null)
break;
// Get the continuation token from the page
// Note: This value can be stored so that the next page query can be executed later
continuationToken = page.ContinuationToken;
var pageResults = page.Values;
moreResultsAvailable = pageResults.Any() && continuationToken != null;
// Iterate the results for this page
foreach (var result in pageResults)
{
// ...
}
}
Als u vervolgtokens expliciet gebruikt, kunt u bepalen wanneer uw toepassing het volgende gegevenssegment ophaalt. Als uw clienttoepassing bijvoorbeeld gebruikers in staat stelt om door de entiteiten te bladeren die zijn opgeslagen in een tabel, kan een gebruiker besluiten niet door alle entiteiten te bladeren die door de query zijn opgehaald, zodat uw toepassing alleen een vervolgtoken zou gebruiken om het volgende segment op te halen wanneer de gebruiker klaar was met pagineren via alle entiteiten in het huidige segment. Deze aanpak heeft verschillende voordelen:
- Hiermee kunt u de hoeveelheid gegevens beperken die u uit de Table-service kunt ophalen en die u via het netwerk verplaatst.
- Hiermee kunt u asynchrone IO uitvoeren in .NET.
- Hiermee kunt u het vervolgtoken serialiseren naar permanente opslag, zodat u kunt doorgaan in het geval van een crash van een toepassing.
Notitie
Een vervolgtoken retourneert doorgaans een segment met 1000 entiteiten, hoewel dit mogelijk minder is. Dit is ook het geval als u het aantal vermeldingen beperkt dat een query retourneert met behulp van Take om de eerste n entiteiten te retourneren die voldoen aan uw opzoekcriteria: de tabelservice kan een segment retourneren dat minder dan n entiteiten bevat, samen met een vervolgtoken, zodat u de resterende entiteiten kunt ophalen.
Projectie aan de serverzijde
Eén entiteit kan maximaal 255 eigenschappen hebben en maximaal 1 MB groot zijn. Wanneer u een query uitvoert op de tabel en entiteiten ophaalt, hebt u mogelijk niet alle eigenschappen nodig en kunt u voorkomen dat gegevens onnodig worden overgebracht (om de latentie en kosten te verminderen). U kunt projectie aan de serverzijde gebruiken om alleen de eigenschappen over te dragen die u nodig hebt. In het volgende voorbeeld wordt alleen de eigenschap E-mail opgehaald (samen met PartitionKey, RowKey, Timestamp en ETag) uit de entiteiten die door de query zijn geselecteerd.
var subsetResults = query{
for employee in employeeTable.Query<EmployeeEntity>("PartitionKey eq 'Sales'") do
select employee.Email
}
foreach (var e in subsetResults)
{
Console.WriteLine("RowKey: {0}, EmployeeEmail: {1}", e.RowKey, e.Email);
}
U ziet hoe de rowkey-waarde beschikbaar is, ook al is deze niet opgenomen in de lijst met eigenschappen die moeten worden opgehaald.
Entiteiten wijzigen
Met de Storage-clientbibliotheek kunt u uw entiteiten wijzigen die zijn opgeslagen in de tabelservice door entiteiten in te voegen, te verwijderen en bij te werken. U kunt EGT's gebruiken om meerdere invoegbewerkingen te batcheren, bij te werken en te verwijderen om het aantal benodigde retouren te verminderen en de prestaties van uw oplossing te verbeteren.
Uitzonderingen die optreden wanneer de Storage-clientbibliotheek een EGT uitvoert, bevatten doorgaans de index van de entiteit waardoor de batch is mislukt. Dit is handig wanneer u foutopsporingscode gebruikt die GEBRUIKMAAKT van EGT's.
U moet ook overwegen hoe uw ontwerp van invloed is op de manier waarop uw clienttoepassing gelijktijdigheids- en updatebewerkingen verwerkt.
Gelijktijdigheid beheren
De tabelservice implementeert standaard optimistische gelijktijdigheidscontroles op het niveau van afzonderlijke entiteiten voor invoeg-, samenvoeg- en verwijderbewerkingen , hoewel het mogelijk is dat een client de tabelservice dwingt om deze controles te omzeilen. Zie Gelijktijdigheid beheren in Microsoft Azure Storage voor meer informatie over hoe de tabelservice gelijktijdigheid beheert.
Samenvoegen of vervangen
De methode Replace van de klasse TableOperation vervangt altijd de volledige entiteit in de Table-service. Als u geen eigenschap in de aanvraag opneemt wanneer die eigenschap in de opgeslagen entiteit bestaat, wordt die eigenschap uit de opgeslagen entiteit verwijderd. Tenzij u een eigenschap expliciet uit een opgeslagen entiteit wilt verwijderen, moet u elke eigenschap in de aanvraag opnemen.
U kunt de samenvoegmethode van de klasse TableOperation gebruiken om de hoeveelheid gegevens die u naar de Tabelservice verzendt, te verminderen wanneer u een entiteit wilt bijwerken. De samenvoegmethode vervangt alle eigenschappen in de opgeslagen entiteit door eigenschapswaarden van de entiteit die is opgenomen in de aanvraag, maar laat alle eigenschappen in de opgeslagen entiteit intact die niet zijn opgenomen in de aanvraag. Dit is handig als u grote entiteiten hebt en slechts een klein aantal eigenschappen in een aanvraag hoeft bij te werken.
Notitie
De methoden Vervangen en samenvoegen mislukken als de entiteit niet bestaat. Als alternatief kunt u de methoden InsertOrReplace en InsertOrMerge gebruiken waarmee een nieuwe entiteit wordt gemaakt als deze niet bestaat.
Werken met heterogene entiteitstypen
De Table-service is een tabelopslag met schemaloze gegevens, wat betekent dat één tabel entiteiten van meerdere typen kan opslaan, wat een grote flexibiliteit biedt in uw ontwerp. In het volgende voorbeeld ziet u een tabel met zowel werknemers- als afdelingsentiteiten:
| PartitionKey | RowKey | Tijdstempel | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| |||||||||||
| |||||||||||
|
|||||||||||
|
Elke entiteit moet nog steeds de waarden PartitionKey, RowKey en Timestamp hebben, maar mogelijk een set eigenschappen hebben. Verder is er niets om het type entiteit aan te geven, tenzij u ervoor kiest om die informatie ergens op te slaan. Er zijn twee opties voor het identificeren van het entiteitstype:
- Geef het entiteitstype vooraf aan de RowKey (of mogelijk de PartitionKey). Bijvoorbeeld EMPLOYEE_000123 of DEPARTMENT_SALES als RowKey-waarden .
- Gebruik een afzonderlijke eigenschap om het entiteitstype vast te leggen, zoals wordt weergegeven in de onderstaande tabel.
| PartitionKey | RowKey | Tijdstempel | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| |||||||||||||
| |||||||||||||
|
|||||||||||||
|
De eerste optie, waarbij het entiteitstype wordt voorbereid op RowKey, is handig als er een mogelijkheid is dat twee entiteiten van verschillende typen dezelfde sleutelwaarde hebben. Ook worden entiteiten van hetzelfde type gegroepeerd in de partitie.
De technieken die in deze sectie worden besproken, zijn vooral relevant voor de discussieovernamerelaties eerder in deze handleiding in het artikel Modelleringsrelaties.
Notitie
U moet overwegen een versienummer op te nemen in de waarde van het entiteitstype om clienttoepassingen in staat te stellen POCO-objecten te ontwikkelen en met verschillende versies te werken.
In de rest van deze sectie worden enkele van de functies in de Storage-clientbibliotheek beschreven die het werken met meerdere entiteitstypen in dezelfde tabel vergemakkelijken.
Heterogene entiteitstypen ophalen
Als u de tabelclientbibliotheek gebruikt, hebt u drie opties voor het werken met meerdere entiteitstypen.
Als u weet welk type entiteit is opgeslagen met een specifieke RowKey - en PartitionKey-waarden , kunt u het entiteitstype opgeven wanneer u de entiteit ophaalt zoals wordt weergegeven in de vorige twee voorbeelden waarmee entiteiten van het type EmployeeEntity worden opgehaald: Een puntquery uitvoeren met behulp van de Storage-clientbibliotheek en meerdere entiteiten ophalen met LINQ.
De tweede optie is het gebruik van het type TableEntity (een eigenschapszak) in plaats van een concreet POCO-entiteitstype (deze optie kan ook de prestaties verbeteren omdat het niet nodig is om de entiteit te serialiseren en deserialiseren naar .NET-typen). De volgende C#-code haalt mogelijk meerdere entiteiten van verschillende typen op uit de tabel, maar retourneert alle entiteiten als TableEntity-exemplaren . Vervolgens wordt de eigenschap EntityType gebruikt om het type van elke entiteit te bepalen:
Pageable<TableEntity> entities = employeeTable.Query<TableEntity>(x =>
x.PartitionKey == "Sales" && x.RowKey.CompareTo("B") >= 0 && x.RowKey.CompareTo("F") <= 0)
foreach (var entity in entities)
{
if (entity.GetString("EntityType") == "Employee")
{
// use entityTypeProperty, RowKey, PartitionKey, Etag, and Timestamp
}
}
Als u andere eigenschappen wilt ophalen, moet u de Methode GetString gebruiken op de entiteit van de klasse TableEntity .
Heterogene entiteitstypen wijzigen
U hoeft niet te weten welk type entiteit u wilt verwijderen en u weet altijd het type entiteit wanneer u deze invoegt. U kunt echter het type TableEntity gebruiken om een entiteit bij te werken zonder het type ervan te kennen en zonder een POCO-entiteitsklasse te gebruiken. Het volgende codevoorbeeld haalt één entiteit op en controleert of de eigenschap EmployeeCount bestaat voordat deze wordt bijgewerkt.
var result = employeeTable.GetEntity<TableEntity>(partitionKey, rowKey);
TableEntity department = result.Value;
if (department.GetInt32("EmployeeCount") == null)
{
throw new InvalidOperationException("Invalid entity, EmployeeCount property not found.");
}
employeeTable.UpdateEntity(department, ETag.All, TableUpdateMode.Merge);
Toegang beheren met Shared Access Signatures
U kunt SAS-tokens (Shared Access Signature) gebruiken om clienttoepassingen in staat te stellen om tabelentiteiten te wijzigen (en query's uit te voeren) zonder dat u uw opslagaccountsleutel hoeft op te nemen in uw code. Normaal gesproken zijn er drie belangrijke voordelen voor het gebruik van SAS in uw toepassing:
- U hoeft uw opslagaccountsleutel niet te distribueren naar een onveilig platform (zoals een mobiel apparaat) om dat apparaat toegang te geven tot entiteiten in de Table-service en deze te wijzigen.
- U kunt een deel van het werk dat web- en werkrollen uitvoeren, offloaden bij het beheren van uw entiteiten naar clientapparaten, zoals computers van eindgebruikers en mobiele apparaten.
- U kunt een beperkte set machtigingen en tijdsbeperkingen toewijzen aan een client (zoals het toestaan van alleen-lezentoegang tot specifieke resources).
Zie Shared Access Signatures (SAS) gebruiken voor meer informatie over het gebruik van SAS-tokens met de Table-service.
U moet echter nog steeds de SAS-tokens genereren die een clienttoepassing verlenen aan de entiteiten in de tabelservice: u moet dit doen in een omgeving die beveiligde toegang heeft tot uw opslagaccountsleutels. Normaal gesproken gebruikt u een web- of werkrol om de SAS-tokens te genereren en deze te leveren aan de clienttoepassingen die toegang nodig hebben tot uw entiteiten. Omdat er nog steeds sprake is van overhead bij het genereren en leveren van SAS-tokens aan clients, moet u overwegen hoe u deze overhead het beste kunt verminderen, met name in scenario's met grote volumes.
Het is mogelijk om een SAS-token te genereren dat toegang verleent tot een subset van de entiteiten in een tabel. Standaard maakt u een SAS-token voor een hele tabel, maar u kunt ook opgeven dat het SAS-token toegang verleent tot een bereik van PartitionKey-waarden of een bereik van PartitionKey- en RowKey-waarden. U kunt ervoor kiezen om SAS-tokens te genereren voor afzonderlijke gebruikers van uw systeem, zodat het SAS-token van elke gebruiker alleen toegang heeft tot hun eigen entiteiten in de tabelservice.
Asynchrone en parallelle bewerkingen
Op voorwaarde dat u uw aanvragen over meerdere partities verspreidt, kunt u de doorvoer en reactiesnelheid van de client verbeteren met behulp van asynchrone of parallelle query's. U hebt bijvoorbeeld twee of meer exemplaren van werkrollen die gelijktijdig toegang hebben tot uw tabellen. U kunt afzonderlijke werkrollen hebben die verantwoordelijk zijn voor bepaalde sets partities, of gewoon meerdere exemplaren van werkrol hebben, die elk toegang hebben tot alle partities in een tabel.
Binnen een clientexemplaren kunt u de doorvoer verbeteren door opslagbewerkingen asynchroon uit te voeren. Met de Storage-clientbibliotheek kunt u eenvoudig asynchrone query's en wijzigingen schrijven. U kunt bijvoorbeeld beginnen met de synchrone methode waarmee alle entiteiten in een partitie worden opgehaald, zoals wordt weergegeven in de volgende C#-code:
private static void ManyEntitiesQuery(TableClient employeeTable, string department)
{
TableContinuationToken continuationToken = null;
do
{
var employees = employeeTable.Query<EmployeeEntity>($"PartitionKey eq {department}");
foreach (var emp in employees.AsPages())
{
// ...
continuationToken = emp.ContinuationToken;
}
} while (continuationToken != null);
}
U kunt deze code eenvoudig wijzigen zodat de query asynchroon wordt uitgevoerd:
private static async Task ManyEntitiesQueryAsync(TableClient employeeTable, string department)
{
TableContinuationToken continuationToken = null;
do
{
var employees = await employeeTable.QueryAsync<EmployeeEntity>($"PartitionKey eq {department}");
foreach (var emp in employees.AsPages())
{
// ...
continuationToken = emp.ContinuationToken;
}
} while (continuationToken != null);
}
In dit asynchrone voorbeeld ziet u de volgende wijzigingen van de synchrone versie:
- De methodehandtekening bevat nu de asynchrone wijziging en retourneert een taakexemplaren .
- In plaats van de querymethode aan te roepen om resultaten op te halen, roept de methode Nu de Methode QueryAsync aan en wordt de await modifier gebruikt om resultaten asynchroon op te halen.
De clienttoepassing kan deze methode meerdere keren aanroepen (met verschillende waarden voor de afdelingsparameter ) en elke query wordt uitgevoerd op een afzonderlijke thread.
U kunt entiteiten ook asynchroon invoegen, bijwerken en verwijderen. In het volgende C#-voorbeeld ziet u een eenvoudige, synchrone methode voor het invoegen of vervangen van een werknemerentiteit:
private static void SimpleEmployeeUpsert(
TableClient employeeTable,
EmployeeEntity employee)
{
var result = employeeTable.UpdateEntity(employee, Azure.ETag.All, TableUpdateMode.Replace);
Console.WriteLine("HTTP Status: {0}", result.Status);
}
U kunt deze code eenvoudig als volgt wijzigen, zodat de update asynchroon wordt uitgevoerd:
private static async Task SimpleEmployeeUpsertAsync(
TableClient employeeTable,
EmployeeEntity employee)
{
var result = await employeeTable.UpdateEntityAsync(employee, Azure.ETag.All, TableUpdateMode.Replace);
Console.WriteLine("HTTP Status: {0}", result.Result.Status);
}
In dit asynchrone voorbeeld ziet u de volgende wijzigingen van de synchrone versie:
- De methodehandtekening bevat nu de asynchrone wijziging en retourneert een taakexemplaren .
- In plaats van de execute-methode aan te roepen om de entiteit bij te werken, roept de methode ExecuteAsync nu aan en wordt de await-modifier gebruikt om asynchroon resultaten op te halen.
De clienttoepassing kan meerdere asynchrone methoden zoals deze aanroepen aanroepen. Elke methodeaanroep wordt uitgevoerd op een afzonderlijke thread.