Notitie
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen u aan te melden of de directory te wijzigen.
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen de mappen te wijzigen.
U kunt machine learning-modellen implementeren als een door de gebruiker gedefinieerde functie (UDF) in uw Azure Stream Analytics-taken om realtime scoren en voorspellingen uit te voeren voor uw streaming-invoergegevens. Met Azure Machine Learning kunt u elk populair opensource-hulpprogramma, zoals TensorFlow, scikit-learn of PyTorch, gebruiken om modellen voor te bereiden, te trainen en te implementeren.
Vereisten
Voer de volgende stappen uit voordat u een machine learning-model als functie toevoegt aan uw Stream Analytics-taak:
Gebruik Azure Machine Learning om uw model als webservice te implementeren.
Uw machine learning-eindpunt moet een gekoppelde swagger hebben waarmee Stream Analytics inzicht krijgt in het schema van de invoer en uitvoer. U kunt deze swagger-voorbeelddefinitie gebruiken als verwijzing om ervoor te zorgen dat u deze juist hebt ingesteld.
Zorg ervoor dat uw webservice geserialiseerde JSON-gegevens accepteert en retourneert.
Implementeer uw model in Azure Kubernetes Service voor grootschalige productie-implementaties. Als de webservice het aantal aanvragen dat afkomstig is van uw taak niet kan verwerken, worden de prestaties van uw Stream Analytics-taak verminderd, wat van invloed is op de latentie. Modellen die zijn geïmplementeerd in Azure Container Instances worden alleen ondersteund wanneer u Azure Portal gebruikt.
Een machine learning-model toevoegen aan uw taak
U kunt Azure Machine Learning-functies rechtstreeks vanuit Azure Portal of Visual Studio Code toevoegen aan uw Stream Analytics-taak.
Azure Portal
Navigeer naar uw Stream Analytics-taak in Azure Portal en selecteer Functies onder Taaktopologie. Selecteer vervolgens Azure Machine Learning Service in het vervolgkeuzemenu + Toevoegen .
Vul het formulier azure Machine Learning Service-functie in met de volgende eigenschapswaarden:
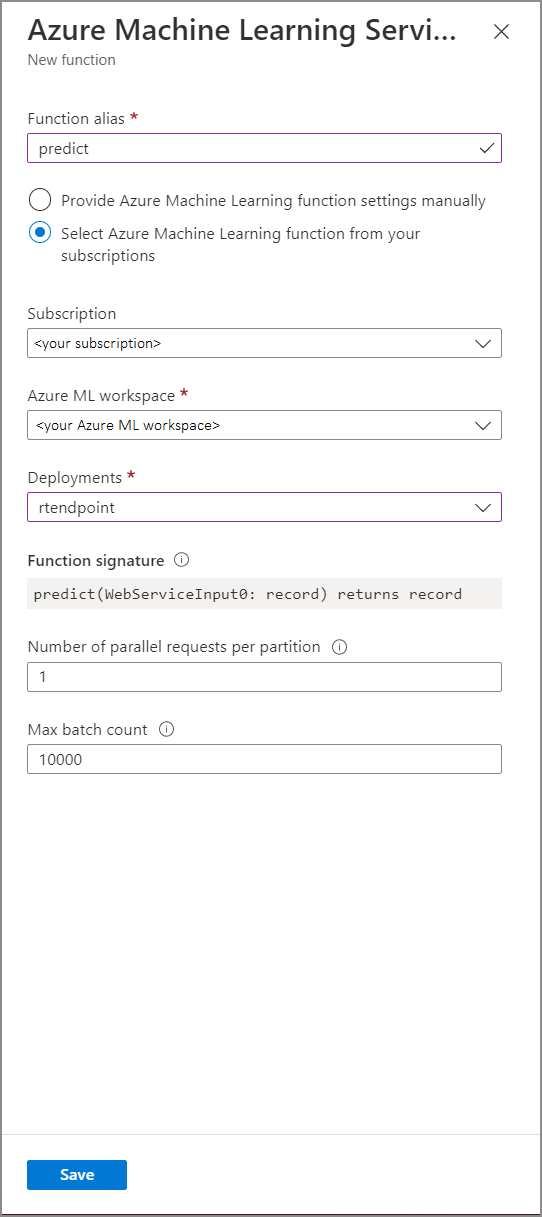
In de volgende tabel wordt elke eigenschap van Azure Machine Learning Service-functies in Stream Analytics beschreven.
| Eigenschap | Beschrijving |
|---|---|
| Functiealias | Voer een naam in om de functie in uw query aan te roepen. |
| Abonnement | Uw Azure-abonnement. |
| Azure Machine Learning-werkruimte | De Azure Machine Learning-werkruimte die u hebt gebruikt om uw model als webservice te implementeren. |
| Eindpunt | De webservice die als host fungeert voor uw model. |
| Functiesignatuur | De handtekening van uw webservice die is afgeleid van de schemaspecificatie van de API. Als de handtekening niet kan worden geladen, controleert u of u voorbeeldinvoer en uitvoer hebt opgegeven in uw scorescript om het schema automatisch te genereren. |
| Aantal parallelle aanvragen per partitie | Dit is een geavanceerde configuratie om de doorvoer op grote schaal te optimaliseren. Dit getal vertegenwoordigt de gelijktijdige aanvragen die vanuit elke partitie van uw taak naar de webservice worden verzonden. Taken met zes streamingeenheden (SU) en lager hebben één partitie. Taken met 12 SUs hebben twee partities, 18 SUs hebben drie partities enzovoort. Als uw taak bijvoorbeeld twee partities heeft en u deze parameter instelt op vier, zijn er acht gelijktijdige aanvragen van uw taak naar uw webservice. |
| Maximaal aantal batches | Dit is een geavanceerde configuratie voor het optimaliseren van doorvoer op grote schaal. Dit nummer vertegenwoordigt het maximum aantal gebeurtenissen dat gebundeld wordt in één verzoek naar uw webservice. |
Machine Learning-eindpunt aanroepen vanuit uw query
Wanneer uw Stream Analytics-query een Azure Machine Learning UDF aanroept, maakt de taak een geserialiseerde JSON-aanvraag voor de webservice. De aanvraag is gebaseerd op een modelspecifiek schema dat door Stream Analytics wordt afgeleid van de swagger-specificatie van het eindpunt.
Waarschuwing
Machine Learning-eindpunten worden niet aangeroepen wanneer u test met de Azure Portal-queryeditor omdat de taak niet wordt uitgevoerd. Als u de eindpuntoproep vanuit de portal wilt testen, moet de Stream Analytics-taak worden uitgevoerd.
De volgende Stream Analytics-query is een voorbeeld van het aanroepen van een Azure Machine Learning UDF:
SELECT udf.score(<model-specific-data-structure>)
INTO output
FROM input
WHERE <model-specific-data-structure> is not null
Als uw invoergegevens die naar de ML UDF worden verzonden, inconsistent zijn met het schema dat wordt verwacht, retourneert het eindpunt een antwoord met foutcode 400, waardoor uw Stream Analytics-taak de status Mislukt krijgt. Het is raadzaam om resourcelogboeken voor uw taak in te schakelen, zodat u eenvoudig fouten kunt opsporen en dergelijke problemen kunt oplossen. Daarom is het raadzaam om het volgende te doen:
- Controleer of de invoer voor uw ML-UDF niet null (leeg) is
- Valideer het type van elk veld dat een invoer is voor uw ML-UDF om ervoor te zorgen dat het overeenkomt met wat het eindpunt verwacht
Notitie
ML UDF's worden geëvalueerd voor elke rij van een bepaalde querystap, zelfs wanneer ze worden aangeroepen via een voorwaardelijke expressie (dat wil zeggen CASE WHEN [A] IS NOT NULL THEN udf.score(A) ELSE '' END). Als dat nodig is, gebruikt u de WITH-component om afwijkende paden te maken, waarbij u de ML-UDF alleen indien nodig aanroept, voordat u UNION gebruikt om paden opnieuw samen te voegen.
Meerdere invoerparameters doorgeven aan de UDF
De meest voorkomende voorbeelden van invoer in machine learning-modellen zijn numpy matrices en DataFrames. U kunt een matrix maken met behulp van een JavaScript UDF en een JSON-geserialiseerd DataFrame maken met behulp van de WITH component.
Een invoermatrix maken
U kunt een JavaScript UDF maken die N aantal invoer accepteert en een matrix maakt die kan worden gebruikt als invoer voor uw Azure Machine Learning UDF.
function createArray(vendorid, weekday, pickuphour, passenger, distance) {
'use strict';
var array = [vendorid, weekday, pickuphour, passenger, distance]
return array;
}
Nadat u de JavaScript UDF aan uw taak hebt toegevoegd, kunt u uw Azure Machine Learning UDF aanroepen met behulp van de volgende query:
WITH
ModelInput AS (
#use JavaScript UDF to construct array that will be used as input to ML UDF
SELECT udf.createArray(vendorid, weekday, pickuphour, passenger, distance) as inputArray
FROM input
)
SELECT udf.score(inputArray)
INTO output
FROM ModelInput
#validate inputArray is not null before passing it to ML UDF to prevent job from failing
WHERE inputArray is not null
De volgende JSON is een voorbeeldaanvraag:
{
"Inputs": {
"WebServiceInput0": [
["1","Mon","12","1","5.8"],
["2","Wed","10","2","10"]
]
}
}
Een Pandas- of PySpark-dataframe maken
U kunt de WITH component gebruiken om een met JSON geserialiseerd DataFrame te maken dat als invoer kan worden doorgegeven aan uw Azure Machine Learning UDF, zoals hieronder wordt weergegeven.
Met de volgende query wordt een DataFrame gemaakt door de benodigde velden te selecteren en het DataFrame te gebruiken als invoer voor de Azure Machine Learning UDF.
WITH
Dataframe AS (
SELECT vendorid, weekday, pickuphour, passenger, distance
FROM input
)
SELECT udf.score(Dataframe)
INTO output
FROM Dataframe
WHERE Dataframe is not null
De volgende JSON is een voorbeeld van een aanvraag uit de vorige query:
{
"Inputs": {
"WebServiceInput0": [
{
"vendorid": "1",
"weekday": "Mon",
"pickuphour": "12",
"passenger": "1",
"distance": "5.8"
},
{
"vendorid": "2",
"weekday": "Tue",
"pickuphour": "10",
"passenger": "2",
"distance": "10"
}]
}
}
De prestaties optimaliseren voor Azure Machine Learning UDF's
Wanneer u uw model implementeert in Azure Kubernetes Service, kunt u uw model profileeren om het resourcegebruik te bepalen. U kunt App Insights ook inschakelen voor uw implementaties om inzicht te krijgen in aanvraagpercentages, reactietijden en foutpercentages .
Als u een scenario hebt met een hoge doorvoer van gebeurtenissen, moet u mogelijk de volgende parameters in Stream Analytics wijzigen om optimale prestaties te bereiken met lage end-to-end latenties:
- Maximum aantal batches.
- Aantal parallelle aanvragen per partitie.
De juiste batchgrootte bepalen
Nadat u uw webservice hebt geïmplementeerd, verzendt u een voorbeeldaanvraag met verschillende batchgrootten vanaf 50 en verhoogt u deze in volgorde van honderden. Bijvoorbeeld 200, 500, 1000, 2000 enzovoort. U ziet dat na een bepaalde batchgrootte de latentie van het antwoord toeneemt. Het punt waarna de latentie van de reactie toeneemt, moet het maximale aantal batches voor uw taak zijn.
Het aantal parallelle aanvragen per partitie bepalen
Bij optimale schaalaanpassing moet uw Stream Analytics-taak meerdere parallelle aanvragen naar uw webservice kunnen verzenden en binnen enkele milliseconden een antwoord kunnen krijgen. De latentie van het antwoord van de webservice kan rechtstreeks van invloed zijn op de latentie en prestaties van uw Stream Analytics-taak. Als de aanroep van uw taak naar de webservice lang duurt, ziet u waarschijnlijk een toename van de watermerkvertraging en mogelijk ook een toename in het aantal achterstallige invoergebeurtenissen.
U kunt lage latentie bereiken door ervoor te zorgen dat uw AKS-cluster (Azure Kubernetes Service) is ingericht met het juiste aantal knooppunten en replica's. Het is essentieel dat uw webservice maximaal beschikbaar is en geslaagde antwoorden retourneert. Als uw taak een fout ontvangt die opnieuw kan worden geprobeerd, zoals het antwoord dat de service niet beschikbaar is (503), wordt het automatisch opnieuw geprobeerd met exponentieel uitstel. Als uw taak een van deze fouten ontvangt als reactie van het eindpunt, wordt de taak naar een mislukte status verzonden.
- Foute aanvraag (400)
- Conflict (409)
- Niet gevonden (404)
- Niet-gemachtigd (401)
Beperkingen
Als u een azure ML Managed Endpoint-service gebruikt, heeft Stream Analytics momenteel alleen toegang tot eindpunten waarvoor openbare netwerktoegang is ingeschakeld. Meer informatie hierover vindt u op de pagina over privé-eindpunten van Azure ML.