Notitie
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen u aan te melden of de directory te wijzigen.
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen de mappen te wijzigen.
Azure Stream Analytics ondersteunt het partitioneren van aangepaste blob-uitvoer met aangepaste velden of kenmerken en aangepaste DateTime padpatronen.
Aangepast veld of kenmerken
Aangepaste veld- of invoerkenmerken verbeteren downstreamgegevensverwerkings- en rapportagewerkstromen door meer controle over de uitvoer mogelijk te maken.
Opties voor partitiesleutels
De partitiesleutel of kolomnaam die wordt gebruikt voor het partitioneren van invoergegevens, kan elk teken bevatten dat wordt geaccepteerd voor blobnamen. Het is niet mogelijk geneste velden als partitiesleutel te gebruiken, tenzij ze samen met aliassen worden gebruikt. U kunt echter bepaalde tekens gebruiken om een hiërarchie van bestanden te maken. Als u bijvoorbeeld een kolom wilt maken waarin gegevens uit twee andere kolommen worden gecombineerd om een unieke partitiesleutel te maken, kunt u de volgende query gebruiken:
SELECT name, id, CONCAT(name, "/", id) AS nameid
De partitiesleutel moet een compatibiliteitsniveau FLOATBIGINTvan 1,2 of BIT hoger zijnNVARCHAR(MAX). De DateTimetypen , Arrayen Records typen worden niet ondersteund, maar kunnen worden gebruikt als partitiesleutels als ze worden geconverteerd naar tekenreeksen. Zie Azure Stream Analytics-gegevenstypen voor meer informatie.
Opmerking
Stel dat een taak invoergegevens gebruikt van livegebruikerssessies die zijn verbonden met een externe videogameservice waarbij opgenomen gegevens een kolom client_id bevatten om de sessies te identificeren. Als u de gegevens client_idwilt partitioneren, stelt u het patroonveld blobpad in om een partitietoken {client_id} op te nemen in de uitvoereigenschappen van de blob wanneer u een taak maakt. Als gegevens met verschillende client_id waarden door de Stream Analytics-taak stromen, worden de uitvoergegevens opgeslagen in afzonderlijke mappen op basis van één client_id waarde per map.

Als de taakinvoer sensorgegevens was van miljoenen sensoren waar elke sensor een sensor_idhad, zou het padpatroon zijn {sensor_id} om elke sensorgegevens te partitioneren naar verschillende mappen.
Wanneer u de REST API gebruikt, kan de uitvoersectie van een JSON-bestand dat voor die aanvraag wordt gebruikt, eruitzien als de volgende afbeelding:

Nadat de taak is uitgevoerd, kan de clients container er als volgt uitzien:

Elke map kan meerdere blobs bevatten waarbij elke blob een of meer records bevat. In het voorgaande voorbeeld bevindt zich één blob in een map met "06000000" de volgende inhoud:

U ziet dat elke record in de blob een client_id kolom bevat die overeenkomt met de mapnaam omdat de kolom die wordt gebruikt om de uitvoer in het uitvoerpad te partitioneren, is client_id.
Beperkingen
Er is slechts één aangepaste partitiesleutel toegestaan in de uitvoereigenschap padpatroonblob. Alle volgende padpatronen zijn geldig:
cluster1/{date}/{aFieldInMyData}cluster1/{time}/{aFieldInMyData}cluster1/{aFieldInMyData}cluster1/{date}/{time}/{aFieldInMyData}
Als klanten meer dan één invoerveld willen gebruiken, kunnen ze een samengestelde sleutel maken in query voor aangepaste padpartitie in blobuitvoer met behulp van
CONCAT. Een voorbeeld isselect concat (col1, col2) as compositeColumn into blobOutput from input. Vervolgens kunnen ze opgevencompositeColumnals het aangepaste pad in Azure Blob Storage.Partitiesleutels zijn niet hoofdlettergevoelig, dus partitiesleutels zoals
Johnenjohnzijn gelijkwaardig. Expressies kunnen ook niet worden gebruikt als partitiesleutels. Werkt bijvoorbeeld{columnA + columnB}niet.Wanneer een invoerstroom bestaat uit records met een partitiesleutelkardinaliteit onder 8000, worden de records toegevoegd aan bestaande blobs. Ze maken alleen nieuwe blobs wanneer dat nodig is. Als de kardinaliteit meer dan 8.000 is, is er geen garantie dat bestaande blobs naar worden geschreven. Er worden geen nieuwe blobs gemaakt voor een willekeurig aantal records met dezelfde partitiesleutel.
Als de blob-uitvoer is geconfigureerd als onveranderbaar, maakt Stream Analytics telkens wanneer gegevens worden verzonden een nieuwe blob.
Aangepaste patronen voor datum/tijd-pad
Met aangepaste DateTime padpatronen kunt u een uitvoerindeling opgeven die overeenkomt met Hive Streaming-conventies, waardoor Stream Analytics de mogelijkheid biedt om gegevens te verzenden naar Azure HDInsight en Azure Databricks voor downstreamverwerking. Aangepaste DateTime padpatronen worden eenvoudig geïmplementeerd met behulp van het datetime trefwoord in het veld Padvoorvoegsel van de blobuitvoer, samen met de indelingsaanduiding. Een voorbeeld is {datetime:yyyy}.
Ondersteunde tokens
De volgende notatieaanduidingstokens kunnen alleen of in combinatie worden gebruikt om aangepaste DateTime indelingen te bereiken.
| Opmaakaanduiding | Beschrijving | Resultaten op voorbeeldtijd 2018-01-02T10:06:08 |
|---|---|---|
| {datetime:yyyy} | Het jaar als een getal van vier cijfers | 2018 |
| {datum/tijd:MM} | Maand van 01 tot 12 | 01 |
| {datum/tijd:M} | Maand van 1 tot 12 | 1 |
| {datetime:dd} | Dag van 01 tot 31 | 02 |
| {datum/tijd:d} | Dag van 1 tot 31 | 2 |
| {datetime:HH} | Uur met de indeling van 24 uur, van 00 tot 23 | 10 |
| {datum/tijd:mm} | Minuten van 00 tot 60 | 06 |
| {datum/tijd:m} | Minuten van 0 tot 60 | 6 |
| {datetime:ss} | Seconden van 00 tot 60 | 08 |
Als u geen aangepaste DateTime patronen wilt gebruiken, kunt u het {date} en/of {time} token toevoegen aan het veld Padvoorvoegsel om een vervolgkeuzelijst met ingebouwde DateTime indelingen te genereren.

Uitbreidbaarheid en beperkingen
U kunt zoveel tokens () gebruiken als{datetime:<specifier>} u wilt in het padpatroon totdat u de tekenlimiet voor het padvoorvoegsel bereikt. Opmaakaanduidingen kunnen niet worden gecombineerd binnen één token buiten de combinaties die al worden vermeld in de vervolgkeuzelijsten datum en tijd.
Voor een padpartitie van logs/MM/dd:
| Geldige expressie | Ongeldige expressie |
|---|---|
logs/{datetime:MM}/{datetime:dd} |
logs/{datetime:MM/dd} |
U kunt dezelfde opmaakaanduiding meerdere keren gebruiken in het padvoorvoegsel. Het token moet elke keer worden herhaald.
Hive Streaming-conventies
Aangepaste padpatronen voor Blob Storage kunnen worden gebruikt met de Hive Streaming-conventie, waarin wordt verwacht dat mappen worden gelabeld met column= de mapnaam.
Een voorbeeld is year={datetime:yyyy}/month={datetime:MM}/day={datetime:dd}/hour={datetime:HH}.
Aangepaste uitvoer elimineert het wijzigen van tabellen en het handmatig toevoegen van partities aan poortgegevens tussen Stream Analytics en Hive. In plaats daarvan kunnen veel mappen automatisch worden toegevoegd met behulp van:
MSCK REPAIR TABLE while hive.exec.dynamic.partition true
Opmerking
Maak een opslagaccount, een resourcegroep, een Stream Analytics-taak en een invoerbron volgens de quickstart van De Azure-portal van Stream Analytics. Gebruik dezelfde voorbeeldgegevens die in de quickstart worden gebruikt. Voorbeeldgegevens zijn ook beschikbaar in GitHub.
Maak een blob-uitvoersink met de volgende configuratie:

Het volledige padpatroon is:
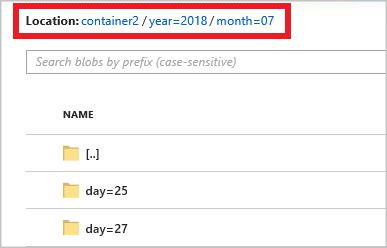
year={datetime:yyyy}/month={datetime:MM}/day={datetime:dd}
Wanneer u de taak start, wordt er een mapstructuur gemaakt op basis van het padpatroon in uw blobcontainer. U kunt inzoomen op het dagniveau.