Notitie
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen u aan te melden of de directory te wijzigen.
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen de mappen te wijzigen.
Belangrijk
Azure Synapse Analytics Data Explorer (preview) wordt op 7 oktober 2025 buiten gebruik gesteld. Na deze datum worden workloads die worden uitgevoerd in Synapse Data Explorer verwijderd en gaan de bijbehorende toepassingsgegevens verloren. We raden u ten zeerste aan om te migreren naar Eventhouse in Microsoft Fabric.
Het CMF-programma (Microsoft Cloud Migration Factory) is ontworpen om klanten te helpen bij het migreren naar Fabric. Het programma biedt praktische toetsenbordbronnen zonder kosten aan de klant. Deze resources worden gedurende een periode van 6-8 weken toegewezen, met een vooraf gedefinieerd en overeengekomen bereik. Klantnominaties worden geaccepteerd vanuit het Microsoft-accountteam of rechtstreeks door een verzoek om hulp in te dienen bij het CMF-team.
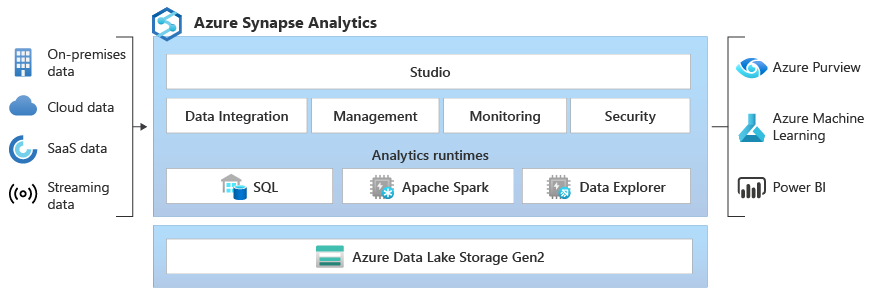
Azure Synapse Data Explorer biedt klanten een interactieve query-ervaring voor het ontgrendelen van inzichten uit logboek- en telemetriegegevens. Om bestaande SQL- en Apache Spark Analytics Runtime-engines aan te vullen, is de Data Explorer-analyseruntime geoptimaliseerd voor efficiënte log analytics met behulp van krachtige indexeringstechnologie om automatisch vrije tekst en semi-gestructureerde gegevens te indexeren die vaak worden gevonden in telemetriegegevens.
Zie de volgende video voor meer informatie:
Wat maakt Azure Synapse Data Explorer uniek?
Eenvoudige opname : Data Explorer biedt ingebouwde integraties voor no-code/low-code, gegevensopname met hoge doorvoer en het opslaan van gegevens uit realtime-bronnen. Gegevens kunnen worden opgenomen uit bronnen zoals Azure Event Hubs, Kafka, Azure Data Lake, opensource-agents zoals Fluentd/Fluent Bit en een groot aantal cloud- en on-premises gegevensbronnen.
Geen complexe gegevensmodellering : met Data Explorer hoeft u geen complexe gegevensmodellen te maken en hoeft u geen complexe scripting uit te voeren om gegevens te transformeren voordat deze worden gebruikt.
Geen indexonderhoud . Onderhoudstaken hoeven geen gegevens te optimaliseren voor queryprestaties en geen indexonderhoud nodig. Met Data Explorer zijn alle onbewerkte gegevens onmiddellijk beschikbaar, zodat u query's met hoge prestaties en hoge gelijktijdigheid kunt uitvoeren op uw streaming- en permanente gegevens. U kunt deze query's gebruiken om bijna realtime dashboards en waarschuwingen te bouwen en operationele analysegegevens te verbinden met de rest van het gegevensanalyseplatform.
Het democratiseren van gegevensanalyse - Data Explorer democratiseert selfservice, big data-analyses met de intuïtieve KQL (Kusto Query Language) die de expressiviteit en kracht van SQL biedt met de eenvoud van Excel. KQL is zeer geoptimaliseerd voor het verkennen van onbewerkte telemetrie- en tijdreeksgegevens door gebruik te maken van de beste indexeringstechnologie van Data Explorer voor efficiënte vrije tekst en regex-zoekopdrachten, en uitgebreide parseringsmogelijkheden voor het uitvoeren van query's op traceringen\tekstgegevens en semi-gestructureerde JSON-gegevens, waaronder matrices en geneste structuren. KQL biedt geavanceerde tijdreeksondersteuning voor het maken, bewerken en analyseren van meerdere tijdreeksen met in-engine Python-uitvoeringsondersteuning voor het scoren van modellen.
Bewezen technologie op petabyteschaal - Data Explorer is een gedistribueerd systeem met rekenresources en opslag die onafhankelijk kunnen worden geschaald, waardoor analyses op gigabytes of petabytes aan gegevens mogelijk zijn.
Geïntegreerd : Azure Synapse Analytics biedt interoperabiliteit tussen Data Explorer-, Apache Spark- en SQL-engines waarmee gegevenstechnici, gegevenswetenschappers en gegevensanalisten eenvoudig en veilig toegang kunnen krijgen tot en samenwerken aan dezelfde gegevens in de data lake.
Wanneer gebruikt u Azure Synapse Data Explorer?
Gebruik Data Explorer als gegevensplatform om bijna real-time log analytics- en IoT-analyseoplossingen te bouwen:
Uw logboeken en gebeurtenisgegevens samenvoegen en correleren in on-premises, cloud- en externe gegevensbronnen.
Versnel uw AI Ops-traject (patroonherkenning, anomaliedetectie, prognose en meer).
Vervang op infrastructuur gebaseerde oplossingen voor zoeken in logboeken om kosten te besparen en de productiviteit te verhogen.
Ontwikkel IoT-analyseoplossingen voor uw IoT-gegevens.
Ontwikkel SaaS-oplossingen voor analyse om services aan uw interne en externe klanten aan te bieden.
Architectuur van Data Explorer-pool
Data Explorer-pools implementeren een uitschaalarchitectuur door de reken- en opslagresources te scheiden. Hierdoor kunt u elke resource onafhankelijk schalen en bijvoorbeeld meerdere alleen-lezen berekeningen uitvoeren op dezelfde gegevens. Data Explorer-pools bestaan uit een set rekenresources waarop de engine wordt uitgevoerd die verantwoordelijk is voor het automatisch indexeren, comprimeren, opslaan in cache en leveren van gedistribueerde query's. Ze hebben ook een tweede set rekenresources waarop de gegevensbeheerservice wordt uitgevoerd die verantwoordelijk is voor achtergrondsysteemtaken en beheerde en in wachtrij geplaatste gegevensopname. Alle gegevens worden opgeslagen in beheerde blobopslagaccounts met behulp van een gecomprimeerde kolomindeling.
Data Explorer-pools ondersteunen een uitgebreid ecosysteem voor het opnemen van gegevens met behulp van connectors, SDK's, REST API's en andere beheerde mogelijkheden. Het biedt verschillende manieren om gegevens te gebruiken voor ad-hocquery's, rapporten, dashboards, waarschuwingen, REST API's en SDK's.
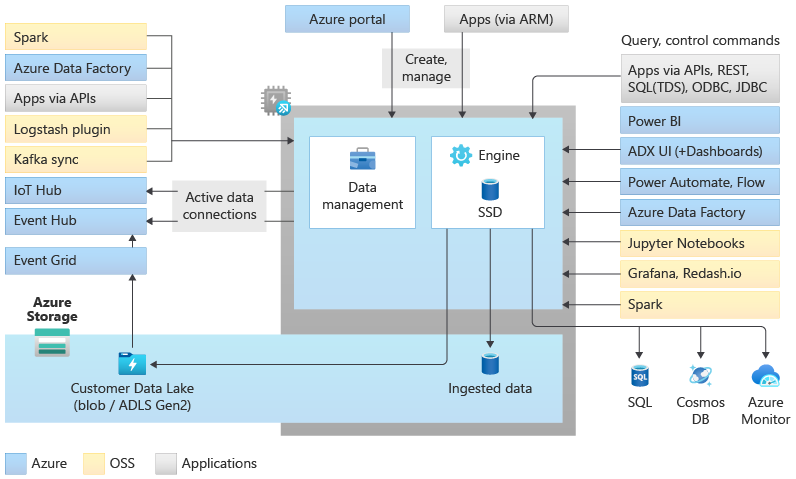
Er zijn veel unieke mogelijkheden waarmee Data Explore de beste analytische engine is voor logboek- en tijdreeksanalyse in Azure.
In de volgende secties worden de belangrijkste onderscheidende kenmerken uitgelicht.
Vrije tekst- en semi-gestructureerde gegevensindexering maakt bijna realtime hoogwaardige prestaties en een hoge mate van gelijktijdige query's mogelijk.
Data Explorer indexeert semi-gestructureerde gegevens (JSON) en ongestructureerde gegevens (vrije tekst), waardoor actieve query's goed presteren op dit type gegevens. Standaard wordt elk veld geïndexeerd tijdens de gegevensopname met de optie om een coderingsbeleid op laag niveau te gebruiken om de index voor specifieke velden te verfijnen of uit te schakelen. Het bereik van de index is één gegevensshard.
De implementatie van de index is afhankelijk van het type veld, als volgt:
| Veldtype | Indexeringsuitvoering |
|---|---|
| Tekenreeks | De engine bouwt een omgekeerde termindex voor tekenreekskolomwaarden. Elke tekenreekswaarde wordt geanalyseerd en opgesplitst in genormaliseerde termen en een geordende lijst met logische posities, met recorddinals, wordt vastgelegd voor elke term. De resulterende gesorteerde lijst met termen en de bijbehorende posities wordt opgeslagen als een onveranderbare B-boomstructuur. |
|
Numeriek Datum/tijd Tijdspanne |
De engine bouwt een eenvoudige, op bereik gebaseerde forward-index. De index registreert de min/max-waarden voor elk blok, voor een groep blokken en voor de hele kolom in de gegevensshard. |
| dynamisch | Het opnameproces bevat alle 'atomische' elementen in de dynamische waarde, zoals eigenschapsnamen, waarden en matrixelementen, en stuurt deze door naar de opbouwfunctie voor indexen. Dynamische velden hebben dezelfde omgekeerde termenindex als tekenreeksvelden. |
Dankzij deze efficiënte indexeringsmogelijkheden kan Data Explore de gegevens in bijna realtime beschikbaar maken voor query's met hoge prestaties en hoge gelijktijdigheid. Het systeem optimaliseert automatisch gegevensshards om de prestaties verder te verbeteren.
Kusto-querytaal
KQL heeft een grote, groeiende community met de snelle acceptatie van Azure Monitor Log Analytics en Application Insights, Microsoft Sentinel, Azure Data Explorer en andere Microsoft-aanbiedingen. De taal is goed ontworpen met een eenvoudig te lezen syntaxis en biedt een soepele overgang van eenvoudige één-liner tot complexe gegevensverwerkingsquery's. Hierdoor kan Data Explorer uitgebreide IntelliSense-ondersteuning en een uitgebreide set taalconstructies en ingebouwde mogelijkheden bieden voor aggregaties, tijdreeksen en gebruikersanalyses die niet beschikbaar zijn in SQL voor snelle verkenning van telemetriegegevens.