Notitie
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen u aan te melden of de directory te wijzigen.
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen de mappen te wijzigen.
Apache Spark is een framework voor parallelle verwerking dat ondersteuning biedt voor in-memory verwerking om de prestaties van toepassingen voor de analyse van big data te verbeteren. Apache Spark in Azure Synapse Analytics is een van de implementaties van Apache Spark van Microsoft in de cloud. Met Azure Synapse kunt u eenvoudig een serverloze Apache Spark-pool maken en configureren in Azure. Spark-pools in Azure Synapse zijn compatibel met opslag van de tweede generatie in Azure Storage en Azure Data Lake. Dit betekent dat u Spark-pools kunt gebruiken om gegevens te verwerken die zijn opgeslagen in Azure.
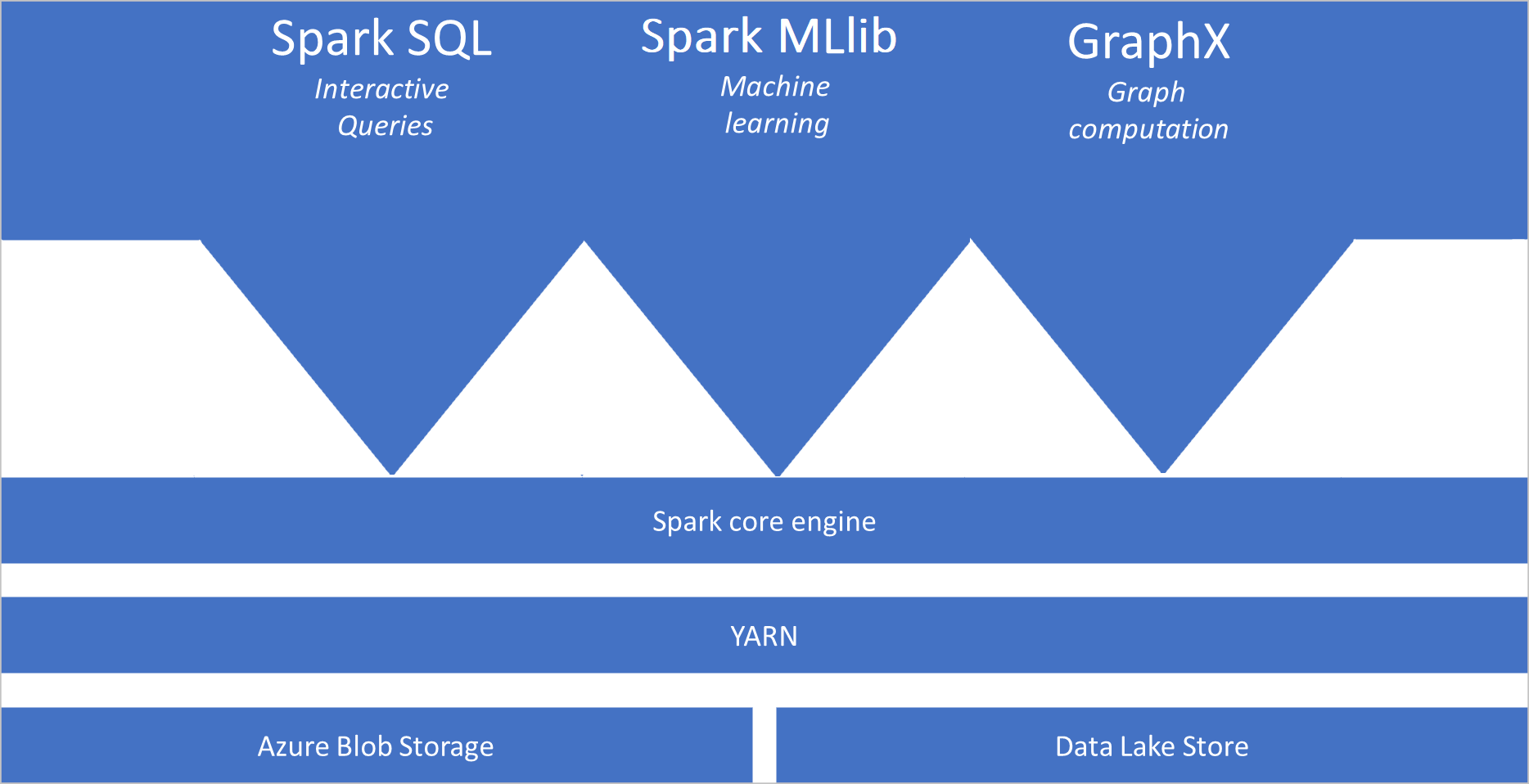
Wat is Apache Spark?
Apache Spark biedt primitieve typen voor in-memory clustercomputing. Een Spark-taak kan gegevens laden en in het geheugen cachen en er herhaaldelijk query’s op uitvoeren. In-memory computing is sneller dan toepassingen op basis van schijven. Apache Spark kan ook worden geïntegreerd met meerdere programmeertalen, zodat u gedistribueerde gegevenssets zoals lokale verzamelingen kunt bewerken. Het is niet nodig om alles te structureren als toewijzings- en verminderingsbewerkingen. Meer informatie vindt u in de Video van Apache Spark voor Synapse.
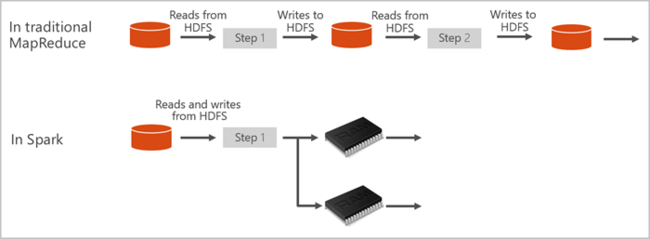
Spark-pools in Azure Synapse bieden een volledig beheerde Spark-service. De voordelen van het maken van een Spark-pool in Azure Synapse Analytics worden hier beschreven.
| Functie | Beschrijving |
|---|---|
| Snelheid en efficiëntie | Spark-exemplaren starten in ongeveer 2 minuten voor minder dan 60 knooppunten en in ongeveer 5 minuten voor meer dan 60 knooppunten. Het exemplaar wordt standaard vijf minuten na uitvoering van de laatste taak afgesloten, tenzij deze actief wordt gehouden door een notebookverbinding. |
| Eenvoudig te maken | U kunt binnen enkele minuten een nieuwe Spark-pool in Azure Synapse maken met de Azure-portal, Azure PowerShell of de .NET-SDK voor Synapse Analytics. Zie Get started with Spark pools in Azure Synapse Analytics (Aan de slag met Spark-pools in Azure Synapse Analytics). |
| Gebruiksgemak | Synapse Analytics bevat een aangepast notebook dat is afgeleid van nteract. U kunt deze notebooks gebruiken voor interactieve gegevensverwerking en visualisatie. |
| REST-API's | Apache Spark in Azure Synapse Analytics bevat Apache Livy, een op REST API gebaseerde Apache Spark-taakserver om op afstand taken te verzenden en te controleren. |
| Ondersteuning voor Azure Data Lake Storage, tweede generatie | Spark-pools in Azure Synapse kunnen Gebruikmaken van Azure Data Lake Storage Generation 2 en BLOB Storage. Zie Overzicht van Azure Data Lake Storage voor meer informatie over Data Lake Storage |
| Integratie met IDE's van derden | Azure Synapse biedt een IDE-invoegtoepassing voor JetBrains' IntelliJ IDEA die nuttig is om toepassingen te maken en in te dienen bij een Spark-pool. |
| Vooraf geladen Anaconda-bibliotheken | Spark-pools in Azure Synapse worden geleverd met Vooraf geïnstalleerde Anaconda-bibliotheken. Anaconda biedt bijna 200 bibliotheken voor machine learning, gegevensanalyse, visualisatie en andere technologieën. |
| Schaalbaarheid | Apache Spark-pools in Azure Synapse kunnen automatisch schalen, als u deze functie inschakelt, zodat pools naar wens omhoog en omlaag kunnen worden geschaald door knooppunten toe te voegen of te verwijderen. Bovendien kunnen Spark-pools zonder gegevensverlies worden afgesloten, omdat alle gegevens zijn opgeslagen in Azure Storage of Data Lake Storage. |
Spark-pools in Azure Synapse bevatten de volgende onderdelen die standaard beschikbaar zijn in de pools:
- Spark Core. Omvat Spark Core, Spark SQL, GraphX en MLlib.
- Anaconda
- Apache Livy
- nteract notebook
Architectuur van Spark-pool
Spark-toepassingen worden uitgevoerd als onafhankelijke sets processen in een pool, gecoördineerd door het SparkContext object in uw hoofdprogramma, het stuurprogrammaprogramma genoemd.
De SparkContext kan verbinding maken met de clusterbeheerder, die resources toewijst aan toepassingen. De clusterbeheerder is Apache Hadoop YARN. Als er verbinding is, verkrijgt Spark executors op knooppunten in de pool. Dit zijn processen die berekeningen uitvoeren en gegevens opslaan voor uw toepassing. Vervolgens wordt uw toepassingscode, gedefinieerd door JAR- of Python-bestanden, verzonden naar SparkContextde uitvoerders. Ten slotte SparkContext worden taken naar de uitvoerders verzonden om uit te voeren.
De SparkContext hoofdfunctie van de gebruiker wordt uitgevoerd en voert de verschillende parallelle bewerkingen op de knooppunten uit. SparkContext Vervolgens worden de resultaten van de bewerkingen verzameld. De knooppunten lezen en schrijven gegevens van en naar het bestandssysteem. De knooppunten plaatsen getransformeerde gegevens ook in het geheugen als RDD's (Resilient Distributed Datasets).
De SparkContext verbinding maakt met de Spark-pool en is verantwoordelijk voor het converteren van een toepassing naar een gerichte acyclische grafiek (DAG). De grafiek bestaat uit afzonderlijke taken die worden uitgevoerd binnen een uitvoerproces op de knooppunten. Elke toepassing krijgt zijn eigen executorprocessen, die actief blijven tijdens de hele toepassing en taken uitvoeren in meerdere threads.
Gebruiksvoorbeelden van Apache Spark in Azure Synapse Analytics
Apache Spark-pools in Azure Synapse Analytics maken de volgende belangrijke scenario's mogelijk:
- Data engineering/gegevensvoorbereiding
Apache Spark bevat veel taalfuncties die het voorbereiden en verwerken van grote hoeveelheden gegevens ondersteunen, zodat er waarde aan kan worden toegevoegd en de gegevens vervolgens kunnen worden verwerkt door andere services binnen Azure Synapse Analytics. Dit wordt mogelijk gemaakt door meerdere talen (C#, Scala, PySpark, Spark SQL) en meegeleverde bibliotheken voor de verwerking en connectiviteit.
- Machine Learning
Apache Spark wordt geleverd met MLlib, een bibliotheek voor machine learning die boven op Apache Spark is gebouwd. U kunt deze bibliotheek gebruiken vanuit een Apache Spark-pool in Azure Synapse Analytics. Spark-pools in Azure Synapse Analytics bevatten ook Anaconda, een Python-distributie met verschillende pakketten voor gegevenswetenschap, waaronder machine learning. Gecombineerd met ingebouwde ondersteuning voor notebooks beschikt u hiermee over een omgeving voor het maken van machine learning-toepassingen.
- Streaminggegevens
Synapse Spark biedt ondersteuning voor gestructureerd streamen van Spark zolang u een ondersteunde versie van de Azure Synapse Spark-runtimerelease uitvoert. Alle taken worden gedurende zeven dagen ondersteund. Dit is van toepassing op zowel batch- als streamingtaken, en over het algemeen automatiseren klanten het proces voor opnieuw opstarten met behulp van Azure Functions.
Gerelateerde inhoud
Raadpleeg de volgende artikelen voor meer informatie over Apache Spark in Azure Synapse Analytics:
- Quickstart: Een Spark-pool maken in Azure Synapse
- Quickstart: Een Apache Spark-notebook maken
- Zelfstudie: Machine learning met Apache Spark
Notitie
Sommige van de officiële Apache Spark documentatie is gebaseerd op het gebruik van de Spark-console, die echter niet beschikbaar is in Azure Synapse Spark. Gebruik in plaats daarvan de ervaring met notebooks of IntelliJ.