Notitie
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen u aan te melden of de directory te wijzigen.
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen de mappen te wijzigen.
Tip
Microsoft Fabric Data Warehouse is een relationeel warehouse op ondernemingsniveau op data lake-basis, met een architectuur die klaar is voor de toekomst, ingebouwde AI en nieuwe functies. Als u nieuw bent in gegevensopslag, begin dan met Fabric Data Warehouse. Bestaande dediceerde SQL-poolworkloads kunnen upgraden naar Fabric voor toegang tot nieuwe mogelijkheden in data science, realtime analyses en rapportage.
Dit artikel bevat aanbevelingen voor het ontwerpen van hash-gedistribueerde en round-robin-gedistribueerde tabellen in toegewijde SQL-pools.
In dit artikel wordt ervan uitgegaan dat u bekend bent met concepten voor gegevensdistributie en gegevensverplaatsing in een toegewezen SQL-pool. Zie de Architectuur van Azure Synapse Analytics voor meer informatie.
Wat is een gedistribueerde tabel?
Een gedistribueerde tabel wordt weergegeven als één tabel, maar de rijen worden in feite opgeslagen in 60 distributies. De rijen worden gedistribueerd met een hash- of round robin-algoritme.
Hash-distributie verbetert de queryprestaties voor grote feitentabellen en is de focus van dit artikel. Round robin-distributie is handig voor het verbeteren van de laadsnelheid. Deze ontwerpkeuzen hebben een aanzienlijk effect op het verbeteren van query- en laadprestaties.
Een andere optie voor tabelopslag is het repliceren van een kleine tabel op alle rekenknooppunten. Zie Ontwerprichtlijnen voor gerepliceerde tabellen voor meer informatie. Als u snel wilt kiezen uit de drie opties, raadpleegt u Gedistribueerde tabellen in het overzicht van tabellen.
Als onderdeel van het tabelontwerp begrijpt u zoveel mogelijk over uw gegevens en hoe de gegevens worden opgevraagd. Denk bijvoorbeeld aan deze vragen:
- Hoe groot is de tabel?
- Hoe vaak wordt de tabel vernieuwd?
- Heb ik feiten- en dimensietabellen in een toegewezen SQL-pool?
Hash verspreid
Een met hash gedistribueerde tabel distribueert tabelrijen over de rekenknooppunten met behulp van een deterministische hash-functie om elke rij toe te wijzen aan één distributie.
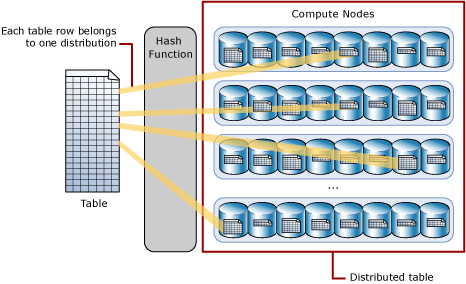
Omdat identieke waarden altijd hashen tot eenzelfde distributie, heeft SQL Analytics ingebouwde kennis van rijlocaties. In een toegewezen SQL-pool wordt deze kennis gebruikt om gegevensverplaatsing tijdens query's te minimaliseren, waardoor de queryprestaties worden verbeterd.
Hash-gedistribueerde tabellen werken goed voor grote feitentabellen in een stervormig schema. Ze kunnen zeer grote aantallen rijen hebben en toch hoge prestaties bereiken. Er zijn enkele ontwerpoverwegingen waarmee u de prestaties kunt verkrijgen die het gedistribueerde systeem biedt. Het kiezen van een goede distributiekolom of -kolommen is een dergelijke overweging die in dit artikel wordt beschreven.
Overweeg het gebruik van een door hash gedistribueerde tabel wanneer:
- De tabelgrootte op schijf is meer dan 2 GB.
- De tabel bevat veelgebruikte invoeg-, update- en verwijderbewerkingen.
Gedistribueerd volgens het round-robin principe
Een gedistribueerde round robin-tabel distribueert tabelrijen gelijkmatig over alle distributies. De toewijzing van rijen aan distributies is willekeurig. In tegenstelling tot door hash gedistribueerde tabellen worden rijen met gelijke waarden niet gegarandeerd toegewezen aan dezelfde distributie.
Als gevolg hiervan moet het systeem soms een bewerking voor gegevensverplaatsing uitvoeren om uw gegevens beter te organiseren voordat een query kan worden opgelost. Deze extra stap kan uw verzoeken vertragen. Het samenvoegen van een round robin-tabel vereist bijvoorbeeld meestal dat de rijen opnieuw worden herordend, wat een prestatieverlies inhoudt.
Overweeg de round robin-distributie voor uw tabel te gebruiken in de volgende scenario's:
- Bij het aan de slag gaan, neem een eenvoudig startpunt aangezien dit de standaardinstelling is.
- Als er geen duidelijke samenvoegsleutel is
- Als er geen goede kandidaat kolom is voor het hash distribueren van de tabel
- Als de tabel geen algemene joinsleutel met andere tabellen deelt
- Als de verbinding minder belangrijk is dan andere verbindingen in de query
- Wanneer de tabel een tijdelijke faseringstabel is
De zelfstudie New York taxicab-gegevens laden geeft een voorbeeld van het laden van gegevens in een round-robin faseringstabel.
Een distributiekolom kiezen
Een hash-gedistribueerde tabel heeft een distributiekolom of set kolommen die de hashsleutel is. Met de volgende code wordt bijvoorbeeld een hash-gedistribueerde tabel gemaakt met ProductKey als distributiekolom.
CREATE TABLE [dbo].[FactInternetSales]
( [ProductKey] int NOT NULL
, [OrderDateKey] int NOT NULL
, [CustomerKey] int NOT NULL
, [PromotionKey] int NOT NULL
, [SalesOrderNumber] nvarchar(20) NOT NULL
, [OrderQuantity] smallint NOT NULL
, [UnitPrice] money NOT NULL
, [SalesAmount] money NOT NULL
)
WITH
( CLUSTERED COLUMNSTORE INDEX
, DISTRIBUTION = HASH([ProductKey])
);
Hash-distributie kan worden toegepast op meerdere kolommen voor een meer gelijkmatige distributie van de basistabel. Met distributie met meerdere kolommen kunt u maximaal acht kolommen kiezen voor distributie. Dit vermindert niet alleen de scheeftrekken van gegevens in de loop van de tijd, maar verbetert ook de queryprestaties. Bijvoorbeeld:
CREATE TABLE [dbo].[FactInternetSales]
( [ProductKey] int NOT NULL
, [OrderDateKey] int NOT NULL
, [CustomerKey] int NOT NULL
, [PromotionKey] int NOT NULL
, [SalesOrderNumber] nvarchar(20) NOT NULL
, [OrderQuantity] smallint NOT NULL
, [UnitPrice] money NOT NULL
, [SalesAmount] money NOT NULL
)
WITH
( CLUSTERED COLUMNSTORE INDEX
, DISTRIBUTION = HASH([ProductKey], [OrderDateKey], [CustomerKey] , [PromotionKey])
);
Notitie
De distributie met meerdere kolommen in Azure Synapse Analytics kan worden ingeschakeld door het compatibiliteitsniveau van de database te wijzigen naar 50 met deze opdracht.
ALTER DATABASE SCOPED CONFIGURATION SET DW_COMPATIBILITY_LEVEL = 50; Zie ALTER DATABASE SCOPED CONFIGURATION voor meer informatie over het instellen van het databasecompatibiliteitsniveau. Zie CREATE MATERIALIZED VIEW, CREATE TABLE of CREATE TABLE AS SELECT voor meer informatie over distributies met meerdere kolommen.
Gegevens die zijn opgeslagen in de distributiekolommen kunnen worden bijgewerkt. Bijwerken van gegevens in distributiekolommen kan leiden tot een herschikking van gegevens.
Het kiezen van distributiekolommen is een belangrijke ontwerpbeslissing omdat de waarden in de hashkolommen bepalen hoe de rijen worden gedistribueerd. De beste keuze is afhankelijk van verschillende factoren en omvat meestal compromissen. Zodra een distributiekolom of kolomset is gekozen, kunt u deze niet meer wijzigen. Als u de beste kolommen de eerste keer niet hebt gekozen, kunt u CREATE TABLE AS SELECT (CTAS) gebruiken om de tabel opnieuw te maken met de gewenste distributie-hashsleutel.
Kies een distributiekolom met gegevens die gelijkmatig worden gedistribueerd
Voor de beste prestaties moeten alle distributies ongeveer hetzelfde aantal rijen hebben. Wanneer een of meer distributies een onevenredig aantal rijen hebben, voltooien sommige distributies hun gedeelte van een parallelle query voordat andere. Omdat de query pas kan worden voltooid als alle distributies zijn verwerkt, is elke query slechts zo snel als de langzaamste distributie.
- Scheve verdeling van gegevens betekent dat de gegevens niet gelijkmatig over de verschillende verdelingen worden verdeeld.
- Verwerkingsscheefheid betekent dat sommige distributies langer duren dan andere bij het uitvoeren van parallelle query's. Dit kan gebeuren wanneer de gegevens scheef zijn.
Om de parallelle verwerking in balans te brengen, selecteert u een distributiekolom of set kolommen die:
- Heeft veel unieke waarden. Een of meer distributiekolommen kunnen dubbele waarden hebben. Alle rijen met dezelfde waarde worden toegewezen aan dezelfde distributie. Omdat er 60 distributies zijn, kunnen sommige distributies 1 unieke waarden hebben > , terwijl andere kunnen eindigen met nulwaarden.
- Heeft geen NULL's of heeft slechts enkele NULL's. Als alle waarden in de distributiekolommen NULL zijn, worden alle rijen aan dezelfde distributie toegewezen. Als gevolg hiervan wordt queryverwerking scheefgetrokken naar één distributie en profiteert niet van parallelle verwerking.
- Is geen datumkolom. Alle gegevens voor dezelfde datum worden in dezelfde distributie geplaatst of de records worden gegroepeerd op datum. Als meerdere gebruikers allemaal filteren op dezelfde datum (zoals de datum van vandaag), worden alle verwerkingstaken uitgevoerd door slechts 1 van de 60 distributies.
Een distributiekolom kiezen waarmee de gegevensverplaatsing wordt geminimaliseerd
Om de juiste queryresultaten te verkrijgen, kunnen query's gegevens van het ene rekenknooppunt naar het andere verplaatsen. Gegevensverplaatsing vindt meestal plaats wanneer query's koppelingen en aggregaties bij gedistribueerde tabellen hebben. Het kiezen van een distributiekolom of -kolomset waarmee gegevensverplaatsing wordt geminimaliseerd, is een van de belangrijkste strategieën voor het optimaliseren van de prestaties van uw toegewezen SQL-pool.
Als u gegevensverplaatsing wilt minimaliseren, selecteert u een distributiekolom of set kolommen die:
- Wordt gebruikt in
JOIN,GROUP BY,DISTINCT,OVER, enHAVINGcomponenten. Wanneer twee grote feitelijke tabellen frequente joins hebben, worden de queryprestaties verbeterd wanneer u beide tabellen verdeelt over een van de joinkolommen. Wanneer een tabel niet wordt gebruikt in joins, kunt u overwegen om de tabel te verdelen op basis van een kolom of kolom-set die vaak in deGROUP BYclausule staat. - Wordt niet gebruikt in
WHEREclausules. Wanneer de clausule vanWHEREeen query en de distributiekolommen van de tabel op dezelfde kolom zijn, kan de query te maken krijgen met grote gegevensscheeftrekking, waardoor de verwerkingsbelasting op slechts enkele distributies valt. Dit is van invloed op queryprestaties, in het ideale voorbeeld delen veel distributies de verwerkingsbelasting. - Is geen datumkolom.
WHEREclausules filteren vaak op datum. Als dit gebeurt, kan alle verwerking worden uitgevoerd op slechts enkele distributies die van invloed zijn op de queryprestaties. Idealiter delen veel distributies de verwerkingsbelasting.
Zodra u een hash-gedistribueerde tabel ontwerpt, is de volgende stap het laden van gegevens in de tabel. Zie Laadoverzicht voor laadbegeleiding.
Hoe u kunt zien of uw distributie een goede keuze is
Nadat gegevens in een hash-gedistribueerde tabel zijn geladen, controleert u hoe gelijkmatig de rijen worden verdeeld over de 60 distributies. De rijen per distributie kunnen tot 10% variëren zonder merkbare invloed op de prestaties.
Houd rekening met de volgende manieren om uw distributiekolommen te evalueren.
Beoordeel of de tabel gegevensonevenwichtigheid heeft.
Een snelle manier om te controleren op scheeftrekken van gegevens is door DBCC PDW_SHOWSPACEUSED te gebruiken. De volgende SQL-code retourneert het aantal tabelrijen dat is opgeslagen in elk van de 60 distributies. Voor evenwichtige prestaties moeten de rijen in de gedistribueerde tabel gelijkmatig over alle distributies worden verdeeld.
-- Find data skew for a distributed table
DBCC PDW_SHOWSPACEUSED('dbo.FactInternetSales');
Om te bepalen welke tabellen meer dan 10% gegevens scheeftrekken:
- Maak de weergave
dbo.vTableSizesdie in het artikel Tabeloverzicht wordt weergegeven. - Voer de volgende query uit.
select *
from dbo.vTableSizes
where two_part_name in
(
select two_part_name
from dbo.vTableSizes
where row_count > 0
group by two_part_name
having (max(row_count * 1.000) - min(row_count * 1.000))/max(row_count * 1.000) >= .10
)
order by two_part_name, row_count;
Queryplannen voor gegevensverplaatsing controleren
Een goede distributiekolomset zorgt ervoor dat joins en aggregaties minimale gegevensverplaatsing hebben. Dit is van invloed op de manier waarop joins moeten worden geschreven. Eén van de joinkolommen moet zich in de distributiekolom of -kolommen bevinden om minimale gegevensverplaatsing bij een join op twee hash-gedistribueerde tabellen te krijgen. Wanneer twee hash-gedistribueerde tabellen worden samengevoegd op een distributiekolom van hetzelfde gegevenstype, is voor de join geen gegevensverplaatsing vereist. Joins kunnen extra kolommen gebruiken zonder dat gegevens worden verplaatst.
Om gegevensverplaatsing tijdens een join te voorkomen:
- De tabellen die betrokken zijn bij de join, moeten met een hash worden gedistribueerd op een van de kolommen die aan de join deelnemen.
- De gegevenstypen van de joinkolommen moeten overeenkomen tussen beide tabellen.
- De kolommen moeten worden samengevoegd met een gelijkheidsoperator.
- Het verbindingstype kan geen
CROSS JOINzijn.
Als u wilt zien of query's gegevensverplaatsing ondervinden, kunt u het queryplan bekijken.
Een probleem met een distributiekolom oplossen
Het is niet nodig om alle gevallen van scheeftrekken van gegevens op te lossen. Het distribueren van gegevens is een kwestie van het vinden van de juiste balans tussen het minimaliseren van gegevensverschil en gegevensverplaatsing. Het is niet altijd mogelijk om zowel gegevensverschil als gegevensverplaatsing te minimaliseren. Soms kan het voordeel van minimale gegevensverplaatsing opwegen tegen het effect van gegevensscheeftrekking.
Als u wilt bepalen of u gegevensverschil in een tabel moet oplossen, moet u zoveel mogelijk inzicht hebben in de gegevensvolumes en query's in uw workload. U kunt de stappen in het artikel Querybewaking gebruiken om het effect van scheeftrekking op de queryprestaties te bewaken. Zoek met name hoe lang het duurt voordat grote query's zijn voltooid voor afzonderlijke distributies.
Omdat u de distributiekolommen in een bestaande tabel niet kunt wijzigen, is de gebruikelijke manier om gegevens scheefheid op te lossen door de tabel opnieuw te maken met verschillende distributiekolommen.
De tabel opnieuw maken met een nieuwe distributiekolomset
In dit voorbeeld wordt CREATE TABLE AS SELECT gebruikt om een tabel met verschillende hashdistributiekolommen opnieuw te maken.
CREATE TABLE AS SELECT Gebruik (CTAS) eerst de nieuwe tabel met de nieuwe sleutel. Maak vervolgens de statistieken opnieuw en wissel ten slotte de tabellen door de naam ervan te wijzigen.
CREATE TABLE [dbo].[FactInternetSales_CustomerKey]
WITH ( CLUSTERED COLUMNSTORE INDEX
, DISTRIBUTION = HASH([CustomerKey])
, PARTITION ( [OrderDateKey] RANGE RIGHT FOR VALUES ( 20000101, 20010101, 20020101, 20030101
, 20040101, 20050101, 20060101, 20070101
, 20080101, 20090101, 20100101, 20110101
, 20120101, 20130101, 20140101, 20150101
, 20160101, 20170101, 20180101, 20190101
, 20200101, 20210101, 20220101, 20230101
, 20240101, 20250101, 20260101, 20270101
, 20280101, 20290101
)
)
)
AS
SELECT *
FROM [dbo].[FactInternetSales]
OPTION (LABEL = 'CTAS : FactInternetSales_CustomerKey')
;
--Create statistics on new table
CREATE STATISTICS [ProductKey] ON [FactInternetSales_CustomerKey] ([ProductKey]);
CREATE STATISTICS [OrderDateKey] ON [FactInternetSales_CustomerKey] ([OrderDateKey]);
CREATE STATISTICS [CustomerKey] ON [FactInternetSales_CustomerKey] ([CustomerKey]);
CREATE STATISTICS [PromotionKey] ON [FactInternetSales_CustomerKey] ([PromotionKey]);
CREATE STATISTICS [SalesOrderNumber] ON [FactInternetSales_CustomerKey] ([SalesOrderNumber]);
CREATE STATISTICS [OrderQuantity] ON [FactInternetSales_CustomerKey] ([OrderQuantity]);
CREATE STATISTICS [UnitPrice] ON [FactInternetSales_CustomerKey] ([UnitPrice]);
CREATE STATISTICS [SalesAmount] ON [FactInternetSales_CustomerKey] ([SalesAmount]);
--Rename the tables
RENAME OBJECT [dbo].[FactInternetSales] TO [FactInternetSales_ProductKey];
RENAME OBJECT [dbo].[FactInternetSales_CustomerKey] TO [FactInternetSales];
Gerelateerde inhoud
Als u een gedistribueerde tabel wilt maken, gebruikt u een van de volgende instructies: