Notitie
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen u aan te melden of de directory te wijzigen.
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen de mappen te wijzigen.
Tip
Microsoft Fabric Data Warehouse is een relationeel warehouse op ondernemingsniveau op data lake-basis, met een architectuur die klaar is voor de toekomst, ingebouwde AI en nieuwe functies. Als u nieuw bent in gegevensopslag, begin dan met Fabric Data Warehouse. Bestaande dediceerde SQL-poolworkloads kunnen upgraden naar Fabric voor toegang tot nieuwe mogelijkheden in data science, realtime analyses en rapportage.
In deze sectie leert u hoe u weergaven kunt maken en gebruiken in om query's voor serverloze SQL-pools te verpakken. Met weergaven kunt u deze query's opnieuw gebruiken. Weergaven zijn ook nodig als u hulpprogramma’s, zoals Power BI, wilt gebruiken samen met een serverloze SQL-pool.
Prerequisites
De eerste stap bestaat uit het maken van een database waar de weergave wordt gemaakt, en het initialiseren van de objecten die nodig zijn voor verificatie in Azure Storage door setup script uit te voeren voor deze database. Alle query's in dit artikel worden uitgevoerd op uw voorbeelddatabase.
Weergaven over externe gegevens
U kunt weergaven op dezelfde manier maken als normale SQL Server-weergaven. Met de volgende query wordt een weergave gemaakt die het population.csv-bestand leest.
Notitie
Wijzig de eerste regel in de query, d.w.z. [mydbname], zodat u de database gebruikt die u hebt gemaakt.
USE [mydbname];
GO
DROP VIEW IF EXISTS populationView;
GO
CREATE VIEW populationView AS
SELECT *
FROM OPENROWSET(
BULK 'csv/population/population.csv',
DATA_SOURCE = 'SqlOnDemandDemo',
FORMAT = 'CSV',
FIELDTERMINATOR =',',
ROWTERMINATOR = '\n'
)
WITH (
[country_code] VARCHAR (5) COLLATE Latin1_General_BIN2,
[country_name] VARCHAR (100) COLLATE Latin1_General_BIN2,
[year] smallint,
[population] bigint
) AS [r];
De weergave gebruikt een EXTERNAL DATA SOURCE met een hoofd-URL van uw opslag, als een DATA_SOURCE en voegt een relatief bestandspad toe aan de bestanden.
Delta Lake-uitzichten
Als u de weergaven boven op de Delta Lake-map maakt, moet u de locatie van de hoofdmap opgeven na de optie BULK in plaats van een bestandspad op te geven.
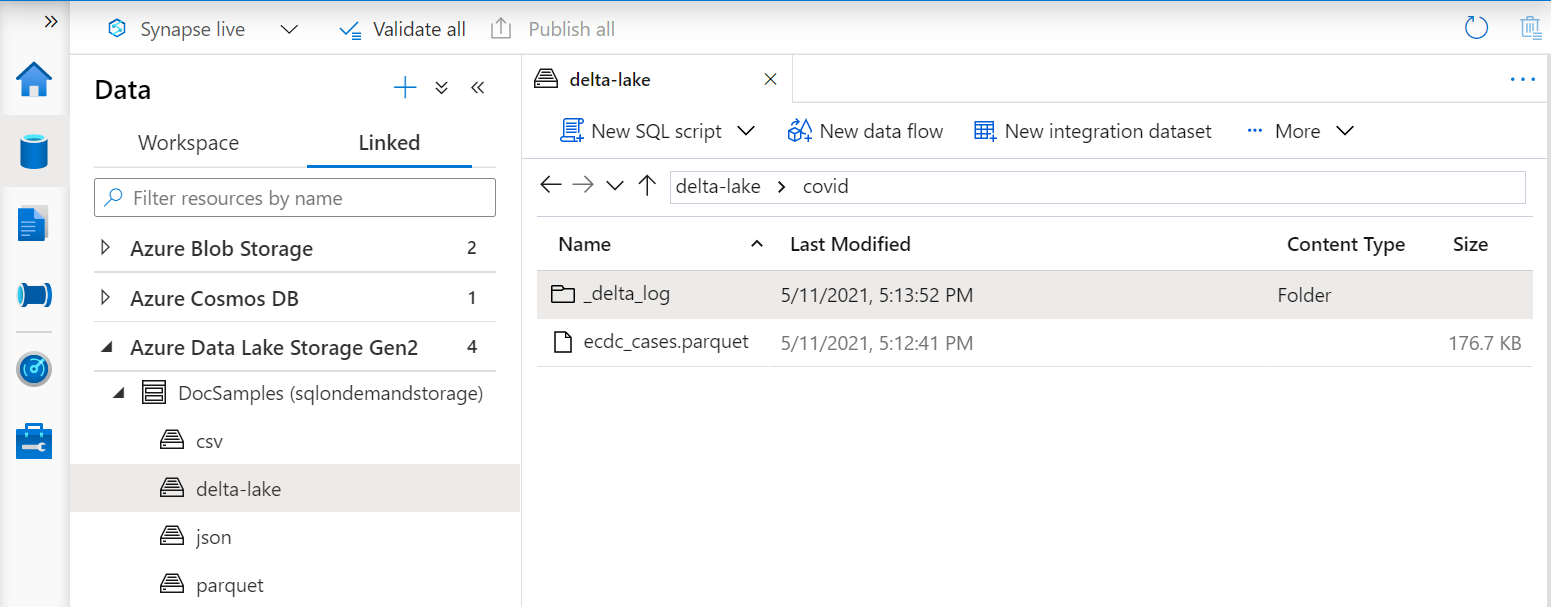
De OPENROWSET functie die gegevens uit de Delta Lake-map leest, onderzoekt de mapstructuur en identificeert automatisch de bestandslocaties.
create or alter view CovidDeltaLake
as
select *
from openrowset(
bulk 'covid',
data_source = 'DeltaLakeStorage',
format = 'delta'
) with (
date_rep date,
cases int,
geo_id varchar(6)
) as rows
Raadpleeg de zelfhulppagina van synapse-serverloze SQL-pools en bekende problemen met Azure Synapse Analytics voor meer informatie.
Gepartitioneerde weergaven
Als u een set bestanden hebt die is gepartitioneerd in de hiërarchische mapstructuur, kunt u het partitiepatroon beschrijven met behulp van de jokertekens in het bestandspad. Gebruik de FILEPATH functie om delen van het mappad beschikbaar te maken als partitioneringskolommen.
CREATE VIEW TaxiView
AS SELECT *, nyc.filepath(1) AS [year], nyc.filepath(2) AS [month]
FROM
OPENROWSET(
BULK 'parquet/taxi/year=*/month=*/*.parquet',
DATA_SOURCE = 'sqlondemanddemo',
FORMAT='PARQUET'
) AS nyc
Gepartitioneerde weergaven kunnen de prestaties van uw query's verbeteren door partitie-verwijdering uit te voeren wanneer u query's uitvoert met filters op de partitioneringskolommen. Niet alle query's ondersteunen echter partitioneliminatie, dus het is belangrijk om enkele best practices te volgen.
Vermijd het gebruik van subquery's in filters om partities te verwijderen, omdat ze de mogelijkheid kunnen verstoren om partities te elimineren. Geef in plaats daarvan het resultaat van de subquery door als een variabele aan het filter.
Wanneer u JOIN's in SQL-query's gebruikt, declareert u het filterpredicaat als NVARCHAR om de complexiteit van het queryplan te verminderen en de kans op de juiste partitieverwijdering te vergroten. Partitiekolommen worden doorgaans afgeleid als NVARCHAR(1024), dus als u hetzelfde type voor het predicaat gebruikt, voorkomt u dat er een impliciete cast nodig is, waardoor de complexiteit van het queryplan kan toenemen.
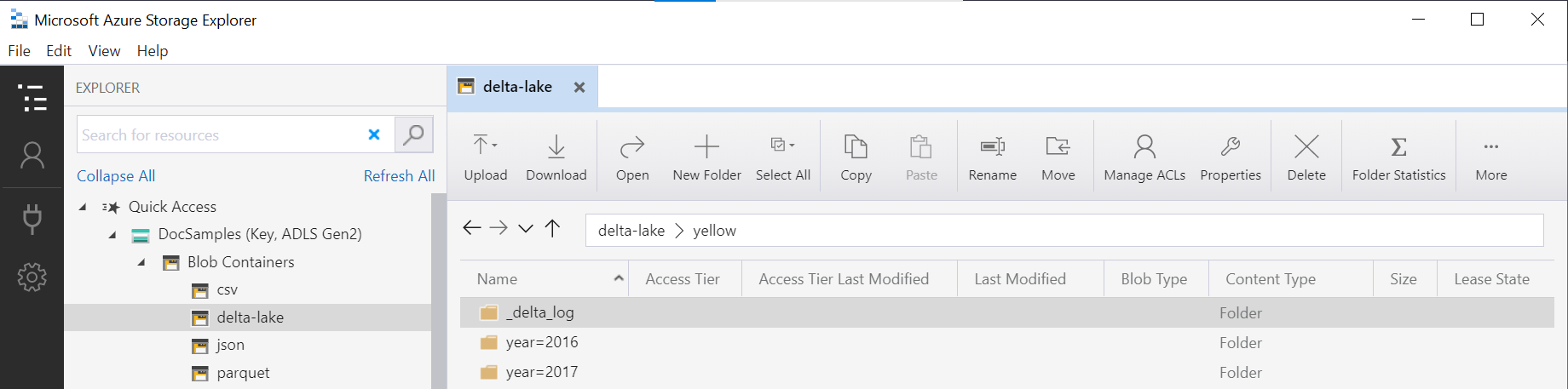
Gepartitioneerde Delta Lake-weergaven
Als u de gepartitioneerde weergaven boven op Delta Lake-opslag maakt, kunt u alleen een hoofdmap van Delta Lake opgeven en hoeft u de partitioneringskolommen niet expliciet beschikbaar te maken met behulp van de FILEPATH functie:
CREATE OR ALTER VIEW YellowTaxiView
AS SELECT *
FROM
OPENROWSET(
BULK 'yellow',
DATA_SOURCE = 'DeltaLakeStorage',
FORMAT='DELTA'
) nyc
Met OPENROWSET de functie wordt de structuur van de onderliggende Delta Lake-map onderzocht en worden de partitioneringskolommen automatisch geïdentificeerd en weergegeven. De partitie-eliminatie wordt automatisch uitgevoerd als u de partitioneringskolom in de WHERE clausule van een query plaatst.
De mapnaam in de OPENROWSET functie (yellowin dit voorbeeld) die is samengevoegd met de URI die is gedefinieerd in LOCATION de DeltaLakeStorage gegevensbron, moet verwijzen naar de hoofdmap delta lake die een submap bevat met de naam _delta_log.
Raadpleeg de zelfhulppagina van synapse-serverloze SQL-pools en bekende problemen met Azure Synapse Analytics voor meer informatie.
JSON-weergaven
De weergaven zijn de goede keuze als u extra verwerking wilt uitvoeren boven op de resultatenset die uit de bestanden wordt opgehaald. Een voorbeeld hiervan is het parseren van JSON-bestanden waarbij we de JSON-functies moeten toepassen om de waarden uit de JSON-documenten te extraheren:
CREATE OR ALTER VIEW CovidCases
AS
select
*
from openrowset(
bulk 'latest/ecdc_cases.jsonl',
data_source = 'covid',
format = 'csv',
fieldterminator ='0x0b',
fieldquote = '0x0b'
) with (doc nvarchar(max)) as rows
cross apply openjson (doc)
with ( date_rep datetime2,
cases int,
fatal int '$.deaths',
country varchar(100) '$.countries_and_territories')
De OPENJSON functie parseert elke regel uit het JSONL-bestand met één JSON-document per regel in tekstindeling.
Azure Cosmos DB overzichten van containers
De weergaven kunnen worden gemaakt op basis van de Azure Cosmos DB-containers als de Azure Cosmos DB analytische opslag is ingeschakeld voor de containers. De naam van het Azure Cosmos DB-account, de databasenaam en de containernaam moeten worden toegevoegd als onderdeel van de weergave, en de alleen-lezen-toegangssleutel moet worden geplaatst in de database-scope referentie waarnaar de weergave verwijst.
In dit voorbeeldscript worden een database en container gebruikt die u kunt instellen door deze instructies te volgen.
Belangrijk
Vervang deze waarden in het script door uw eigen waarden:
- your-cosmosdb - de naam van uw Cosmos DB-account
- toegangssleutel - uw Cosmos DB-accountsleutel
CREATE DATABASE SCOPED CREDENTIAL MyCosmosDbAccountCredential
WITH IDENTITY = 'SHARED ACCESS SIGNATURE', SECRET = 'access-key';
GO
CREATE OR ALTER VIEW Ecdc
AS SELECT *
FROM OPENROWSET(
PROVIDER = 'CosmosDB',
CONNECTION = 'Account=your-cosmosdb;Database=covid',
OBJECT = 'Ecdc',
CREDENTIAL = 'MyCosmosDbAccountCredential'
) with ( date_rep varchar(20), cases bigint, geo_id varchar(6) ) as rows
Zie Query's uitvoeren op Azure Cosmos DB-gegevens met een serverloze SQL-pool in Azure Synapse Link voor meer informatie.
Een weergave gebruiken
U kunt weergaven in uw query's op dezelfde manier gebruiken als weergaven in SQL Server-query's.
Met de volgende query wordt het gebruik van de weergave population_csv gedemonstreerd die we hebben gemaakt in Een weergave maken. Deze tabel retourneert de namen van landen/regio's met hun populatie in 2019 in aflopende volgorde.
Notitie
Wijzig de eerste regel in de query, d.w.z. [mydbname], zodat u de database gebruikt die u hebt gemaakt.
USE [mydbname];
GO
SELECT
country_name, population
FROM populationView
WHERE
[year] = 2019
ORDER BY
[population] DESC;
Wanneer u een query op de weergave uitvoert, kunnen er fouten of onverwachte resultaten optreden. Dit betekent waarschijnlijk dat de weergave verwijst naar kolommen of objecten die zijn gewijzigd of die niet meer bestaan. U moet de weergavedefinitie handmatig aanpassen om af te stemmen op de onderliggende schemawijzigingen.
Gerelateerde inhoud
Raadpleeg voor informatie over het uitvoeren van een query op verschillende bestandstypen de artikelen Query's uitvoeren op één CSV-bestand, Query uitvoeren op Parquet-bestandenen Query's uitvoeren op JSON-bestanden.