Notitie
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen u aan te melden of de directory te wijzigen.
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen de mappen te wijzigen.
Tip
Microsoft Fabric Data Warehouse is een relationeel warehouse op ondernemingsniveau op data lake-basis, met een architectuur die klaar is voor de toekomst, ingebouwde AI en nieuwe functies. Als u nieuw bent in gegevensopslag, begin dan met Fabric Data Warehouse. Bestaande dediceerde SQL-poolworkloads kunnen upgraden naar Fabric voor toegang tot nieuwe mogelijkheden in data science, realtime analyses en rapportage.
In dit artikel wordt uitgelegd hoe u kosten voor een serverloze SQL-pool in Azure Synapse Analytics kunt schatten en beheren:
- Geschatte hoeveelheid gegevens die worden verwerkt voordat een query wordt uitgegeven
- Kostenbeheerfunctie gebruiken om het budget in te stellen
Begrijp dat de kosten voor een serverloze SQL-pool in Azure Synapse Analytics slechts een deel van de maandelijkse kosten in uw Azure-factuur zijn. Als u andere Azure-services gebruikt, wordt u gefactureerd voor alle Azure-services en -resources die worden gebruikt in uw Azure-abonnement, inclusief de services van derden. In dit artikel wordt uitgelegd hoe u kosten voor een serverloze SQL-pool in Azure Synapse Analytics plant en beheert.
Verwerkte gegevens
Gegevens die worden verwerkt , zijn de hoeveelheid gegevens die het systeem tijdelijk opslaat terwijl een query wordt uitgevoerd. De verwerkte gegevens bestaan uit de volgende hoeveelheden:
- Hoeveelheid gegevens die uit de opslag worden gelezen. Dit bedrag omvat:
- Gegevens die worden gelezen tijdens het lezen van gegevens.
- Gegevens die worden gelezen tijdens het lezen van metagegevens (voor bestandsindelingen die metagegevens bevatten, zoals Parquet).
- Hoeveelheid gegevens in tussenliggende resultaten. Deze gegevens worden overgebracht tussen knooppunten terwijl de query wordt uitgevoerd. Het bevat de gegevensoverdracht naar uw eindpunt, in een niet-gecomprimeerde indeling.
- Hoeveelheid gegevens die naar de opslag zijn geschreven. Als u CETAS gebruikt om uw resultatenset te exporteren naar de opslag, wordt de hoeveelheid gegevens die wordt weggeschreven, toegevoegd aan de hoeveelheid gegevens die voor het SELECT-gedeelte van CETAS wordt verwerkt.
Het lezen van bestanden uit opslag is zeer geoptimaliseerd. Het proces maakt gebruik van:
- Prefetching, wat wat overhead kan toevoegen aan de hoeveelheid data die gelezen wordt. Als een query een heel bestand leest, is er geen overhead. Als een bestand gedeeltelijk wordt gelezen, zoals in TOP N-query's, wordt er iets meer gegevens gelezen door gebruik te maken van prefetching.
- Een geoptimaliseerde parser voor door komma's gescheiden waarden (CSV). Als u PARSER_VERSION='2.0' gebruikt om CSV-bestanden te lezen, nemen de hoeveelheden gegevens die uit de opslag zijn gelezen enigszins toe. Een geoptimaliseerde CSV-parser leest bestanden parallel, in segmenten van gelijke grootte. Segmenten bevatten niet noodzakelijkerwijs hele rijen. Om ervoor te zorgen dat alle rijen worden geparseerd, leest de geoptimaliseerde CSV-parser ook kleine fragmenten van aangrenzende segmenten. Dit proces voegt een kleine hoeveelheid overhead toe.
Statistiek
De queryoptimalisatie voor serverloze SQL-pools is afhankelijk van statistieken om optimale uitvoeringsplannen voor query's te genereren. U kunt handmatig statistieken maken. Anders worden deze automatisch door een serverloze SQL-pool gemaakt. In beide gevallen worden statistieken gemaakt door een afzonderlijke query uit te voeren die een specifieke kolom retourneert met een opgegeven steekproeffrequentie. Deze query heeft een gekoppelde hoeveelheid verwerkte gegevens.
Als u dezelfde of een andere query uitvoert die zou profiteren van gemaakte statistieken, worden statistieken indien mogelijk opnieuw gebruikt. Er zijn geen aanvullende gegevens verwerkt voor het maken van statistieken.
Wanneer statistieken worden gemaakt voor een Parquet-kolom, wordt alleen de relevante kolom gelezen uit bestanden. Wanneer statistieken worden gemaakt voor een CSV-kolom, worden hele bestanden gelezen en geparseerd.
Rounding
De hoeveelheid verwerkte gegevens wordt afgerond naar de dichtstbijzijnde MB per query. Elke query heeft minimaal 10 MB aan verwerkte gegevens.
Wat niet inbegrepen is in de verwerkte gegevens
- Metagegevens op serverniveau (zoals aanmeldingen, functies en referenties op serverniveau).
- Databases die u in uw eindpunt maakt. Deze databases bevatten alleen metagegevens (zoals gebruikers, rollen, schema's, weergaven, inline tabelwaardefuncties [TVF's], opgeslagen procedures, referenties met databasebereik, externe gegevensbronnen, externe bestandsindelingen en externe tabellen).
- Als u schemadeductie gebruikt, worden bestandsfragmenten gelezen om kolomnamen en gegevenstypen af te leiden en wordt de hoeveelheid gegevensgelezen toegevoegd aan de hoeveelheid verwerkte gegevens.
- DDL-instructies (Data Definition Language), met uitzondering van de instructie CREATE STATISTICS omdat er gegevens uit de opslag worden verwerkt op basis van het opgegeven steekproefpercentage.
- Query's met alleen metagegevens.
De hoeveelheid verwerkte gegevens verminderen
U kunt de hoeveelheid verwerkte gegevens per query optimaliseren en de prestaties verbeteren door uw gegevens te partitioneren en te converteren naar een gecomprimeerde indeling op basis van kolommen, zoals Parquet.
Voorbeelden
Stel dat er drie tabellen zijn.
- De population_csv tabel wordt ondersteund door 5 TB CSV-bestanden. De bestanden zijn ingedeeld in vijf kolommen met gelijke grootte.
- De population_parquet tabel bevat dezelfde gegevens als de population_csv tabel. Het wordt ondersteund door 1 TB Parquet-bestanden. Deze tabel is kleiner dan de vorige tabel omdat gegevens worden gecomprimeerd in Parquet-indeling.
- De very_small_csv tabel wordt ondersteund door 100 kB CSV-bestanden.
Query 1: SELECT SUM(population) FROM population_csv
Met deze query worden hele bestanden gelezen en geparseerd om waarden op te halen voor de populatiekolom. Knooppunten verwerken fragmenten van deze tabel en de populatiesom voor elk fragment wordt overgedragen tussen knooppunten. De uiteindelijke som wordt overgebracht naar uw eindpunt.
Deze query verwerkt 5 TB aan gegevens plus een kleine overhead voor het overdracht van fragmentensommen.
Query 2: SELECT SUM(population) FROM population_parquet
Wanneer u een query uitvoert op gecomprimeerde en kolomgebaseerde formaten zoals Parquet, worden er minder gegevens gelezen dan in query 1. U ziet dit resultaat omdat een serverloze SQL-pool één gecomprimeerde kolom leest in plaats van het hele bestand. In dit geval wordt 0,2 TB gelezen. (Vijf kolommen met gelijke grootte zijn elk 0,2 TB.) Knooppunten verwerken fragmenten van deze tabel en de populatiesom voor elk fragment wordt overgedragen tussen knooppunten. De uiteindelijke som wordt overgebracht naar uw eindpunt.
Deze query verwerkt 0,2 TB plus een kleine hoeveelheid overhead voor het overdragen van sommen van fragmenten.
Query 3: SELECT * FROM population_parquet
Deze query leest alle kolommen en draagt alle gegevens over in een niet-gecomprimeerde indeling. Als de compressie-indeling 5:1 is, verwerkt de query 6 TB omdat deze 1 TB leest en 5 TB aan niet-gecomprimeerde gegevens overdraagt.
Query 4: SELECT COUNT(*) FROM very_small_csv
Met deze query worden hele bestanden gelezen. De totale grootte van bestanden in opslag voor deze tabel is 100 kB. Knooppunten verwerken fragmenten van deze tabel en de som voor elk fragment wordt overgebracht tussen knooppunten. De uiteindelijke som wordt overgebracht naar uw eindpunt.
Deze query verwerkt iets meer dan 100 kB aan gegevens. De hoeveelheid gegevens die voor deze query worden verwerkt, wordt afgerond op 10 MB, zoals opgegeven in de sectie Afronding van dit artikel.
Kostenbeheer
Met de functie Kostenbeheer in een serverloze SQL-pool kunt u het budget instellen voor de hoeveelheid verwerkte gegevens. U kunt het budget instellen in TB aan gegevens die verwerkt zijn voor een dag, week en maand. Tegelijkertijd kunt u een of meer budgetten instellen. Als u kostenbeheer wilt configureren voor een serverloze SQL-pool, kunt u Synapse Studio of T-SQL gebruiken.
Kostenbeheer configureren voor een serverloze SQL-pool in Synapse Studio
Als u kostenbeheer wilt configureren voor een serverloze SQL-pool in Synapse Studio, gaat u naar het item Beheren in het menu aan de linkerkant en selecteert u het SQL-poolitem onder Analytics-pools. Wanneer u de muisaanwijzer over een serverloze SQL-pool beweegt, ziet u een pictogram voor kostenbeheer. Klik op dit pictogram.
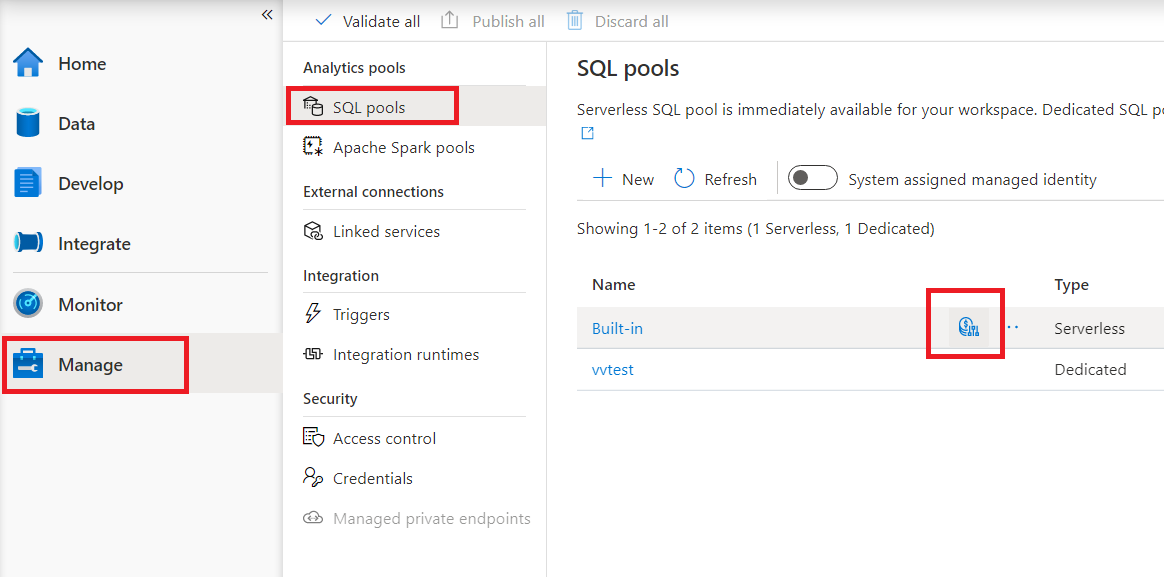
Zodra u op het pictogram kostenbeheer klikt, wordt er een zijbalk weergegeven:
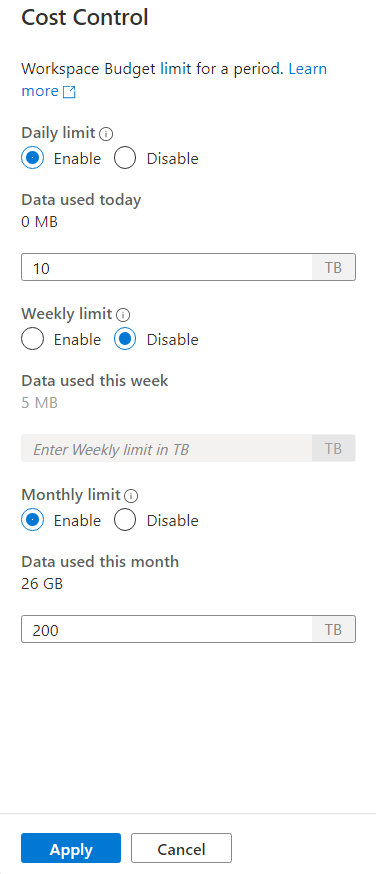
Als u een of meer budgetten wilt instellen, klikt u eerst op keuzerondje Inschakelen voor een budget dat u wilt instellen, dan voert u de waarde voor het gehele getal in het tekstvak in. Eenheid voor de waarde is TB's. Zodra u de budgetten hebt geconfigureerd die u wilde, klikt u onderaan de zijbalk op de knop Toepassen. Dat is het, je budget is nu ingesteld.
Kostenbeheer configureren voor een serverloze SQL-pool in T-SQL
Als u kostenbeheer wilt configureren voor een serverloze SQL-pool in T-SQL, moet u een of meer van de volgende opgeslagen procedures uitvoeren.
sp_set_data_processed_limit
@type = N'daily',
@limit_tb = 1
sp_set_data_processed_limit
@type= N'weekly',
@limit_tb = 2
sp_set_data_processed_limit
@type= N'monthly',
@limit_tb = 3334
Voer de volgende T-SQL-instructie uit om de huidige configuratie te zien:
SELECT * FROM sys.configurations
WHERE name like 'Data processed %';
Voer de volgende T-SQL-instructie uit om te zien hoeveel gegevens er zijn verwerkt tijdens de huidige dag, week of maand:
SELECT * FROM sys.dm_external_data_processed
De limieten overschrijden die zijn gedefinieerd in het kostenbeheer
Als een limiet wordt overschreden tijdens de uitvoering van de query, wordt de query niet beëindigd.
Wanneer de limiet wordt overschreden, wordt nieuwe query geweigerd met het foutbericht met details over de periode, gedefinieerde limiet voor die periode en gegevens die voor die periode worden verwerkt. Als er bijvoorbeeld een nieuwe query wordt uitgevoerd, waarbij de wekelijkse limiet is ingesteld op 1 TB en deze is overschreden, wordt het foutbericht weergegeven:
Query is rejected because SQL Serverless budget limit for a period is exceeded. (Period = Weekly: Limit = 1 TB, Data processed = 1 TB))
Volgende stappen
Zie Best practices voor serverloze SQL-pools voor meer informatie over het optimaliseren van uw query's voor betere prestaties.