Prestaties afstemmen met gerealiseerde weergaven met behulp van een toegewezen SQL-pool in Azure Synapse Analytics
In een toegewezen SQL-pool bieden gerealiseerde weergaven een onderhoudsarme methode voor complexe analytische query's om snelle prestaties te krijgen zonder querywijziging. In dit artikel worden de algemene richtlijnen voor het gebruik van gerealiseerde weergaven besproken.
Gerealiseerde weergaven versus standaardweergaven
SQL-pool ondersteunt zowel standaardweergaven als gerealiseerde weergaven. Beide zijn virtuele tabellen die zijn gemaakt met SELECT-expressies en aan query's worden gepresenteerd als logische tabellen. Weergaven onthullen de complexiteit van algemene gegevensberekeningen en voegen een abstractielaag toe aan rekenwijzigingen, zodat het niet nodig is om query's te herschrijven.
Een standaardweergave berekent de gegevens telkens wanneer de weergave wordt gebruikt. Er zijn geen gegevens opgeslagen op schijf. Mensen gebruiken doorgaans standaardweergaven als een hulpprogramma waarmee u de logische objecten en query's in een database kunt ordenen. Als u een standaardweergave wilt gebruiken, moet een query er rechtstreeks naar verwijzen.
In een gerealiseerde weergave worden de gegevens vooraf berekend, opgeslagen en onderhouden in een toegewezen SQL-pool, net als in een tabel. Hercomputatie is niet nodig telkens wanneer een gerealiseerde weergave wordt gebruikt. Daarom kunnen query's die gebruikmaken van alle of een subset van de gegevens in gerealiseerde weergaven sneller presteren. Nog beter, query's kunnen een gerealiseerde weergave gebruiken zonder er rechtstreeks naar te verwijzen, zodat u de toepassingscode niet hoeft te wijzigen.
De meeste standaardweergavevereisten zijn nog steeds van toepassing op een gerealiseerde weergave. Raadpleeg CREATE MATERIALIZED VIEW AS SELECT voor meer informatie over de syntaxis van de gerealiseerde weergave en andere vereisten.
| Vergelijking | Weergave | Gerealiseerde weergave |
|---|---|---|
| Definitie weergeven | Opgeslagen in Azure-datawarehouse. | Opgeslagen in Azure-datawarehouse. |
| Inhoud weergeven | Elke keer gegenereerd wanneer de weergave wordt gebruikt. | Voorverwerkt en opgeslagen in Azure-datawarehouse tijdens het maken van de weergave. Bijgewerkt wanneer gegevens worden toegevoegd aan de onderliggende tabellen. |
| Gegevens vernieuwen | Altijd bijgewerkt | Altijd bijgewerkt |
| Snelheid voor het ophalen van weergavegegevens uit complexe query's | Langzaam | Snel |
| Extra opslag | Nee | Ja |
| Syntax | CREATE VIEW | GEREALISEERDE WEERGAVE MAKEN ALS SELECTEREN |
Voordelen van gerealiseerde weergaven
Een goed ontworpen gerealiseerde weergave biedt de volgende voordelen:
Kortere uitvoeringstijd voor complexe query's met JOIN's en statistische functies. Hoe complexer de query, hoe hoger de kans op uitvoeringstijdbesparing. Het meeste voordeel wordt behaald wanneer de rekenkosten van een query hoog zijn en de resulterende gegevensset klein is.
Het queryoptimalisatieprogramma in een toegewezen SQL-pool kan automatisch geïmplementeerde gerealiseerde weergaven gebruiken om queryuitvoeringsplannen te verbeteren. Dit proces is transparant voor gebruikers die snellere queryprestaties bieden en vereist geen directe verwijzing naar de gerealiseerde weergaven.
Vereist weinig onderhoud voor de weergaven. In een gerealiseerde weergave worden gegevens op twee plaatsen opgeslagen: een geclusterde columnstore-index voor de eerste gegevens tijdens het maken van de weergave en een deltaopslag voor de incrementele gegevenswijzigingen. Alle gegevenswijzigingen uit de basistabellen worden automatisch op een synchrone manier toegevoegd aan het Delta-archief. Een achtergrondproces (tuple mover) verplaatst de gegevens periodiek van het Delta-archief naar de columnstore-index van de weergave. Dit ontwerp maakt het mogelijk om query's uit te voeren op gerealiseerde weergaven om dezelfde gegevens te retourneren als het rechtstreeks uitvoeren van query's op de basistabellen.
De gegevens in een gerealiseerde weergave kunnen anders worden verdeeld dan de basistabellen.
Gegevens in gerealiseerde weergaven krijgen dezelfde hoge beschikbaarheids- en tolerantievoordelen als gegevens in normale tabellen.
In vergelijking met andere datawarehouseproviders bieden de gerealiseerde weergaven die zijn geïmplementeerd in een toegewezen SQL-pool ook de volgende extra voordelen:
- Automatisch en synchroon vernieuwen van gegevens met gegevenswijzigingen in basistabellen. De gebruiker hoeft verder niets te doen.
- Brede ondersteuning voor statistische functies. Zie CREATE MATERIALIZED VIEW AS SELECT (Transact-SQL).
- De ondersteuning voor queryspecifieke gerealiseerde weergaveaanbeveling. Zie EXPLAIN (Transact-SQL).
Algemene scenario's
Gerealiseerde weergaven worden doorgaans gebruikt in de volgende scenario's:
De prestaties van complexe analytische query's op grote gegevens moeten worden verbeterd
Complexe analytische query's maken doorgaans gebruik van meer aggregatiefuncties en tabelkoppelingen, waardoor er meer rekenintensieve bewerkingen worden veroorzaakt, zoals willekeurige willekeurige bewerkingen en joins bij het uitvoeren van query's. Daarom duurt het langer voordat deze query's zijn voltooid, met name in grote tabellen.
Gebruikers kunnen gerealiseerde weergaven maken voor de gegevens die worden geretourneerd door de algemene berekeningen van query's, zodat er geen hercomputatie nodig is wanneer deze gegevens nodig zijn voor query's, waardoor de rekenkosten lager zijn en query's sneller reageren.
Snellere prestaties nodig zonder of minimale querywijzigingen
Schema- en querywijzigingen in datawarehouses worden doorgaans tot een minimum beperkt om reguliere ETL-bewerkingen en -rapportage te ondersteunen. Mensen kunt gerealiseerde weergaven gebruiken voor het afstemmen van queryprestaties als de kosten van de weergaven kunnen worden gecompenseerd door de verbeterde queryprestaties.
In vergelijking met andere afstemmingsopties, zoals schalen en statistiekenbeheer, is het een veel minder impactvolle productiewijziging om een gerealiseerde weergave te maken en te onderhouden en is de potentiële prestatieverbetering ook hoger.
- Het maken of onderhouden van gerealiseerde weergaven heeft geen invloed op de query's die worden uitgevoerd op de basistabellen.
- Het queryoptimalisatieprogramma kan automatisch de geïmplementeerde gerealiseerde weergaven gebruiken zonder directe weergavereferentie in een query. Deze mogelijkheid vermindert de noodzaak om query's te wijzigen bij het afstemmen van prestaties.
Er is een andere strategie voor gegevensdistributie nodig voor snellere queryprestaties
Azure Data Warehouse is een gedistribueerd mpp-systeem (massively parallel processing).
Synapse SQL is een gedistribueerd querysysteem waarmee ondernemingen datawarehousing en gegevensvirtualisatie-scenario's kunnen implementeren met behulp van standaard T-SQL-ervaringen die bekend zijn bij data engineers. Ook worden de mogelijkheden van SQL uitgebreid om scenario's wat betreft streaming- en machine learning aan te pakken. Gegevens in een datawarehousetabel worden verdeeld over 60 knooppunten met behulp van een van de drie distributiestrategieën (hash, round_robin of gerepliceerd).
De gegevensdistributie wordt opgegeven tijdens het maken van de tabel en blijft ongewijzigd totdat de tabel wordt verwijderd. Gerealiseerde weergave die een virtuele tabel op schijf is, ondersteunt hash- en round_robin-gegevensdistributies. Gebruikers kunnen een gegevensdistributie kiezen die verschilt van de basistabellen, maar die optimaal is voor de prestaties van query's die vaak gebruikmaken van de weergaven.
Ontwerprichtlijnen
Hier volgen de algemene richtlijnen voor het gebruik van gerealiseerde weergaven om de queryprestaties te verbeteren:
Ontwerpen voor uw workload
Voordat u begint met het maken van gerealiseerde weergaven, is het belangrijk dat u een goed begrip hebt van uw workload in termen van querypatronen, urgentie, frequentie en de grootte van de resulterende gegevens.
Gebruikers kunnen EXPLAIN WITH_RECOMMENDATIONS <SQL_statement> uitvoeren voor de gerealiseerde weergaven die worden aanbevolen door het queryoptimalisatieprogramma. Omdat deze aanbevelingen queryspecifiek zijn, is een gerealiseerde weergave die voordelen biedt voor één query mogelijk niet optimaal voor andere query's in dezelfde workload.
Evalueer deze aanbevelingen met uw workloadbehoeften in gedachten. De ideale gerealiseerde weergaven zijn weergaven die de prestaties van de workload ten goede komen.
Houd rekening met de afweging tussen snellere query's en de kosten
Voor elke gerealiseerde weergave zijn er kosten voor gegevensopslag en kosten voor het onderhouden van de weergave. Naarmate gegevens in de basistabellen veranderen, neemt de grootte van de gerealiseerde weergave toe en verandert ook de fysieke structuur.
Om te voorkomen dat de prestaties van query's afnemen, wordt elke gerealiseerde weergave afzonderlijk onderhouden door de datawarehouse-engine, waaronder het verplaatsen van rijen van deltaopslag naar de columnstore-indexsegmenten en het consolideren van gegevenswijzigingen.
De onderhoudsworkload stijgt hoger wanneer het aantal gerealiseerde weergaven en wijzigingen in de basistabel toeneemt. Gebruikers moeten controleren of de kosten van alle gerealiseerde weergaven kunnen worden gecompenseerd door de prestatieverbetering van de query.
U kunt deze query uitvoeren voor de lijst met gerealiseerde weergaven in een database:
SELECT V.name as materialized_view, V.object_id
FROM sys.views V
JOIN sys.indexes I ON V.object_id= I.object_id AND I.index_id < 2;
Opties om het aantal gerealiseerde weergaven te verminderen:
Identificeer algemene gegevenssets die vaak worden gebruikt door de complexe query's in uw workload. Maak gerealiseerde weergaven om deze gegevenssets op te slaan, zodat het optimalisatieprogramma deze als bouwstenen kan gebruiken bij het maken van uitvoeringsplannen.
Verwijder de gerealiseerde weergaven die weinig worden gebruikt of die niet meer nodig zijn. Een uitgeschakelde gerealiseerde weergave wordt niet onderhouden, maar er worden wel opslagkosten in rekening gebracht.
Combineer gerealiseerde weergaven die zijn gemaakt op dezelfde of vergelijkbare basistabellen, zelfs als de gegevens elkaar niet overlappen. Het combineren van gerealiseerde weergaven kan leiden tot een grotere weergave dan de som van de afzonderlijke weergaven, maar de onderhoudskosten van de weergave moeten afnemen. Bijvoorbeeld:
-- Query 1 would benefit from having a materialized view created with this SELECT statement
SELECT A, SUM(B)
FROM T
GROUP BY A
-- Query 2 would benefit from having a materialized view created with this SELECT statement
SELECT C, SUM(D)
FROM T
GROUP BY C
-- You could create a single mateiralized view of this form
SELECT A, C, SUM(B), SUM(D)
FROM T
GROUP BY A, C
Niet alle prestaties afstemmen vereist querywijziging
De optimalisatiefunctie voor datawarehouses kan automatisch geïmplementeerde gerealiseerde weergaven gebruiken om de queryprestaties te verbeteren. Deze ondersteuning wordt transparant toegepast op query's die niet verwijzen naar de weergaven en op query's die gebruikmaken van aggregaties die niet worden ondersteund bij het maken van gerealiseerde weergaven. Er is geen querywijziging nodig. U kunt het geschatte uitvoeringsplan van een query controleren om te controleren of een gerealiseerde weergave wordt gebruikt.
- Zie De workload van uw toegewezen SQL-pool voor Azure Synapse Analytics bewaken met dmv's voor meer informatie over het ophalen van het werkelijke uitvoeringsplan.
- U kunt een geschat uitvoeringsplan ophalen via SQL Server Management Studio (SSMS) of SET SHOWPLAN_XML.
Gerealiseerde weergaven bewaken
Een gerealiseerde weergave wordt opgeslagen in het datawarehouse, net als een tabel met een geclusterde columnstore-index (CCI). Het lezen van gegevens uit een gerealiseerde weergave omvat het scannen van de index en het toepassen van wijzigingen uit het Delta-archief. Wanneer het aantal rijen in het Delta-archief te hoog is, kan het oplossen van een query vanuit een gerealiseerde weergave langer duren dan het rechtstreeks uitvoeren van query's op de basistabellen.
Om te voorkomen dat de queryprestaties afnemen, is het een goede gewoonte om DBCC PDW_SHOWMATERIALIZEDVIEWOVERHEAD uit te voeren om de overhead_ratio (total_rows/base_view_row) van de weergave te bewaken. Als de overhead_ratio te hoog is, kunt u overwegen de gerealiseerde weergave opnieuw op te bouwen, zodat alle rijen in het Delta-archief worden verplaatst naar de columnstore-index.
Gerealiseerde weergave en resultatenset opslaan in cache
Deze twee functies worden rond dezelfde tijd geïntroduceerd in een toegewezen SQL-pool voor het afstemmen van queryprestaties. Caching van resultatensets wordt gebruikt voor het bereiken van hoge gelijktijdigheid en snelle reactietijden van herhaalde query's op statische gegevens.
Als u het resultaat in de cache wilt gebruiken, moet de vorm van de query voor het aanvragen van de cache overeenkomen met de query die de cache heeft geproduceerd. Bovendien moet het resultaat in de cache van toepassing zijn op de hele query.
Gerealiseerde weergaven staan gegevenswijzigingen in de basistabellen toe. Gegevens in gerealiseerde weergaven kunnen worden toegepast op een deel van een query. Dankzij deze ondersteuning kunnen dezelfde gerealiseerde weergaven worden gebruikt door verschillende query's die berekeningen delen voor snellere prestaties.
Voorbeeld
In dit voorbeeld wordt een TPCDS-achtige query gebruikt waarmee klanten worden gevonden die meer geld uitgeven via de catalogus dan in winkels. Het identificeert ook de voorkeursklanten en hun land/regio van herkomst. De query omvat het selecteren van TOP 100-records uit de UNION van drie sub-SELECT-instructies met betrekking tot SUM() en GROUP BY.
WITH year_total AS (
SELECT c_customer_id customer_id
,c_first_name customer_first_name
,c_last_name customer_last_name
,c_preferred_cust_flag customer_preferred_cust_flag
,c_birth_country customer_birth_country
,c_login customer_login
,c_email_address customer_email_address
,d_year dyear
,sum(isnull(ss_ext_list_price-ss_ext_wholesale_cost-ss_ext_discount_amt+ss_ext_sales_price, 0)/2) year_total
,'s' sale_type
FROM customer
,store_sales
,date_dim
WHERE c_customer_sk = ss_customer_sk
AND ss_sold_date_sk = d_date_sk
GROUP BY c_customer_id
,c_first_name
,c_last_name
,c_preferred_cust_flag
,c_birth_country
,c_login
,c_email_address
,d_year
UNION ALL
SELECT c_customer_id customer_id
,c_first_name customer_first_name
,c_last_name customer_last_name
,c_preferred_cust_flag customer_preferred_cust_flag
,c_birth_country customer_birth_country
,c_login customer_login
,c_email_address customer_email_address
,d_year dyear
,sum(isnull(cs_ext_list_price-cs_ext_wholesale_cost-cs_ext_discount_amt+cs_ext_sales_price, 0)/2) year_total
,'c' sale_type
FROM customer
,catalog_sales
,date_dim
WHERE c_customer_sk = cs_bill_customer_sk
AND cs_sold_date_sk = d_date_sk
GROUP BY c_customer_id
,c_first_name
,c_last_name
,c_preferred_cust_flag
,c_birth_country
,c_login
,c_email_address
,d_year
UNION ALL
SELECT c_customer_id customer_id
,c_first_name customer_first_name
,c_last_name customer_last_name
,c_preferred_cust_flag customer_preferred_cust_flag
,c_birth_country customer_birth_country
,c_login customer_login
,c_email_address customer_email_address
,d_year dyear
,sum(isnull(ws_ext_list_price-ws_ext_wholesale_cost-ws_ext_discount_amt+ws_ext_sales_price, 0)/2) year_total
,'w' sale_type
FROM customer
,web_sales
,date_dim
WHERE c_customer_sk = ws_bill_customer_sk
AND ws_sold_date_sk = d_date_sk
GROUP BY c_customer_id
,c_first_name
,c_last_name
,c_preferred_cust_flag
,c_birth_country
,c_login
,c_email_address
,d_year
)
SELECT TOP 100
t_s_secyear.customer_id
,t_s_secyear.customer_first_name
,t_s_secyear.customer_last_name
,t_s_secyear.customer_birth_country
FROM year_total t_s_firstyear
,year_total t_s_secyear
,year_total t_c_firstyear
,year_total t_c_secyear
,year_total t_w_firstyear
,year_total t_w_secyear
WHERE t_s_secyear.customer_id = t_s_firstyear.customer_id
AND t_s_firstyear.customer_id = t_c_secyear.customer_id
AND t_s_firstyear.customer_id = t_c_firstyear.customer_id
AND t_s_firstyear.customer_id = t_w_firstyear.customer_id
AND t_s_firstyear.customer_id = t_w_secyear.customer_id
AND t_s_firstyear.sale_type = 's'
AND t_c_firstyear.sale_type = 'c'
AND t_w_firstyear.sale_type = 'w'
AND t_s_secyear.sale_type = 's'
AND t_c_secyear.sale_type = 'c'
AND t_w_secyear.sale_type = 'w'
AND t_s_firstyear.dyear+0 = 1999
AND t_s_secyear.dyear+0 = 1999+1
AND t_c_firstyear.dyear+0 = 1999
AND t_c_secyear.dyear+0 = 1999+1
AND t_w_firstyear.dyear+0 = 1999
AND t_w_secyear.dyear+0 = 1999+1
AND t_s_firstyear.year_total > 0
AND t_c_firstyear.year_total > 0
AND t_w_firstyear.year_total > 0
AND CASE WHEN t_c_firstyear.year_total > 0 THEN t_c_secyear.year_total / t_c_firstyear.year_total ELSE NULL END
> CASE WHEN t_s_firstyear.year_total > 0 THEN t_s_secyear.year_total / t_s_firstyear.year_total ELSE NULL END
AND CASE WHEN t_c_firstyear.year_total > 0 THEN t_c_secyear.year_total / t_c_firstyear.year_total ELSE NULL END
> CASE WHEN t_w_firstyear.year_total > 0 THEN t_w_secyear.year_total / t_w_firstyear.year_total ELSE NULL END
ORDER BY t_s_secyear.customer_id
,t_s_secyear.customer_first_name
,t_s_secyear.customer_last_name
,t_s_secyear.customer_birth_country
OPTION ( LABEL = 'Query04-af359846-253-3');
Controleer het geschatte uitvoeringsplan van de query. Er zijn 18 shuffles en 17 joins-bewerkingen, die meer tijd in beslag nemen om uit te voeren.
Nu gaan we één gerealiseerde weergave maken voor elk van de drie sub-SELECT-instructies.
CREATE materialized view nbViewSS WITH (DISTRIBUTION=HASH(customer_id)) AS
SELECT c_customer_id customer_id
,c_first_name customer_first_name
,c_last_name customer_last_name
,c_preferred_cust_flag customer_preferred_cust_flag
,c_birth_country customer_birth_country
,c_login customer_login
,c_email_address customer_email_address
,d_year dyear
,sum(isnull(ss_ext_list_price-ss_ext_wholesale_cost-ss_ext_discount_amt+ss_ext_sales_price, 0)/2) year_total
, count_big(*) AS cb
FROM dbo.customer
,dbo.store_sales
,dbo.date_dim
WHERE c_customer_sk = ss_customer_sk
AND ss_sold_date_sk = d_date_sk
GROUP BY c_customer_id
,c_first_name
,c_last_name
,c_preferred_cust_flag
,c_birth_country
,c_login
,c_email_address
,d_year
GO
CREATE materialized view nbViewCS WITH (DISTRIBUTION=HASH(customer_id)) AS
SELECT c_customer_id customer_id
,c_first_name customer_first_name
,c_last_name customer_last_name
,c_preferred_cust_flag customer_preferred_cust_flag
,c_birth_country customer_birth_country
,c_login customer_login
,c_email_address customer_email_address
,d_year dyear
,sum(isnull(cs_ext_list_price-cs_ext_wholesale_cost-cs_ext_discount_amt+cs_ext_sales_price, 0)/2) year_total
, count_big(*) as cb
FROM dbo.customer
,dbo.catalog_sales
,dbo.date_dim
WHERE c_customer_sk = cs_bill_customer_sk
AND cs_sold_date_sk = d_date_sk
GROUP BY c_customer_id
,c_first_name
,c_last_name
,c_preferred_cust_flag
,c_birth_country
,c_login
,c_email_address
,d_year
GO
CREATE materialized view nbViewWS WITH (DISTRIBUTION=HASH(customer_id)) AS
SELECT c_customer_id customer_id
,c_first_name customer_first_name
,c_last_name customer_last_name
,c_preferred_cust_flag customer_preferred_cust_flag
,c_birth_country customer_birth_country
,c_login customer_login
,c_email_address customer_email_address
,d_year dyear
,sum(isnull(ws_ext_list_price-ws_ext_wholesale_cost-ws_ext_discount_amt+ws_ext_sales_price, 0)/2) year_total
, count_big(*) AS cb
FROM dbo.customer
,dbo.web_sales
,dbo.date_dim
WHERE c_customer_sk = ws_bill_customer_sk
AND ws_sold_date_sk = d_date_sk
GROUP BY c_customer_id
,c_first_name
,c_last_name
,c_preferred_cust_flag
,c_birth_country
,c_login
,c_email_address
,d_year
Controleer het uitvoeringsplan van de oorspronkelijke query opnieuw. Nu verandert het aantal joins van 17 naar 5 en is er geen willekeurige volgorde meer. Selecteer het pictogram Filterbewerking in het plan. De uitvoerlijst laat zien dat de gegevens worden gelezen uit de gerealiseerde weergaven in plaats van uit basistabellen.
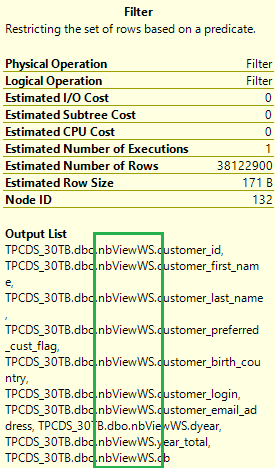
Met gerealiseerde weergaven wordt dezelfde query veel sneller uitgevoerd zonder codewijziging.
Volgende stappen
Zie Overzicht van Synapse SQL-ontwikkeling voor meer tips voor ontwikkeling.
Feedback
Binnenkort beschikbaar: In de loop van 2024 zullen we GitHub-problemen geleidelijk uitfaseren als het feedbackmechanisme voor inhoud en deze vervangen door een nieuw feedbacksysteem. Zie voor meer informatie: https://aka.ms/ContentUserFeedback.
Feedback verzenden en weergeven voor