Notitie
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen u aan te melden of de directory te wijzigen.
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen de mappen te wijzigen.
Van toepassing op: ✔️ Linux-VM's ✔️ Windows-VM's ✔️ Flexibele schaalsets ✔️ Uniforme schaalsets
Prestatietests zijn uitgevoerd op meerdere VM's uit de HBv2-serie . De volgende tabel bevat een overzicht van de belangrijkste bevindingen van deze tests.
| Werklast | HBv2 |
|---|---|
| STREAM Triad | 350 GB/s (21-23 GB/s per CCX) |
| High Performance Linpack (HPL) | 4 TeraFLOPS (Rpeak, FP64), 8 TeraFLOPS (Rmax, FP32) |
| RDMA-latentie en bandbreedte | 1,2 microseconden, 190 Gb/s |
| FIO op lokale NVMe SSD | 2,7 GB/s leesbewerkingen, 1,1 GB/s schrijfbewerkingen; 102k IOPS-leesbewerkingen, 115 IOPS-schrijfbewerkingen |
| IOR op 8 * Azure Premium SSD (P40 beheerde schijven, RAID0)** | 1,3 GB/s leesbewerkingen, 2,5 GB/schrijfbewerkingen; 101k IOPS-leesbewerkingen, 105.000 IOPS-schrijfbewerkingen |
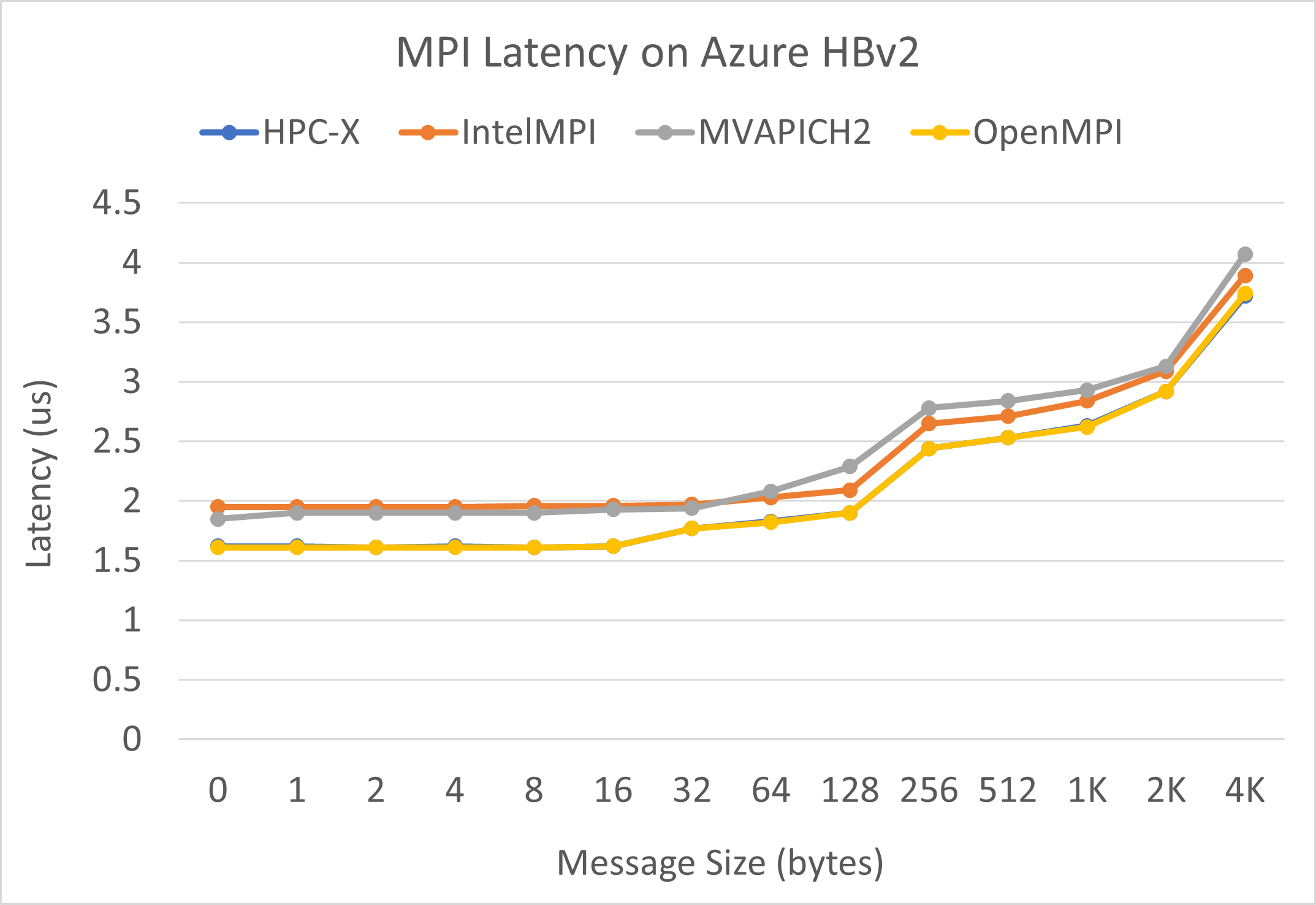
MPI-latentie
MPI-latentietest vanuit de OMB-suite (OSU Micro-Benchmark) wordt uitgevoerd. Voorbeeldscripts bevinden zich op GitHub.
./bin/mpirun_rsh -np 2 -hostfile ~/hostfile MV2_CPU_MAPPING=[INSERT CORE #] ./osu_latency
MPI-bandbreedte
MPI-bandbreedtetest van de OSU microbenchmark suite wordt uitgevoerd. Voorbeeldscripts bevinden zich op GitHub.
./mvapich2-2.3.install/bin/mpirun_rsh -np 2 -hostfile ~/hostfile MV2_CPU_MAPPING=[INSERT CORE #] ./mvapich2-2.3/osu_benchmarks/mpi/pt2pt/osu_bw
Schermopname van MPI-bandbreedte.
Mellanox Perftest
Het Mellanox Perftest-pakket heeft veel InfiniBand-tests, zoals latentie (ib_send_lat) en bandbreedte (ib_send_bw). De volgende opdracht fungeert als voorbeeld.
numactl --physcpubind=[INSERT CORE #] ib_send_lat -a
Volgende stappen
- Lees meer over de nieuwste aankondigingen, voorbeelden van HPC-werkbelastingen en prestatieresultaten in de Blogs van de Azure Compute Tech Community.
- Zie High Performance Computing (HPC) in Azure voor een architectuurweergave op een hoger niveau van het uitvoeren van HPC-workloads.