Configuraties en bewerkingen van SAP HANA-infrastructuur in Azure
Dit document bevat richtlijnen voor het configureren van de Azure-infrastructuur en het uitvoeren van SAP HANA-systemen die zijn geïmplementeerd op systeemeigen virtuele Azure-machines (VM's). Het document bevat ook configuratiegegevens voor sap HANA-uitschalen voor de M128s VM-SKU. Dit document is niet bedoeld om de standaard SAP-documentatie te vervangen, die de volgende inhoud bevat:
Vereisten
Als u deze handleiding wilt gebruiken, hebt u basiskennis nodig van de volgende Azure-onderdelen:
Zie de sectie SAP op Azure in Azure voor meer informatie over SAP NetWeaver en andere SAP-onderdelen in Azure.
Basisoverwegingen voor het instellen
In de volgende secties worden basisoverwegingen beschreven voor het implementeren van SAP HANA-systemen op Azure-VM's.
Verbinding maken met virtuele Azure-machines
Zoals beschreven in de planningshandleiding voor virtuele Azure-machines, zijn er twee basismethoden voor het maken van verbinding met Azure-VM's:
- Maak verbinding via internet en openbare eindpunten op een Jump-VM of op de VM waarop SAP HANA wordt uitgevoerd.
- Verbinding maken via een VPN of Azure ExpressRoute.
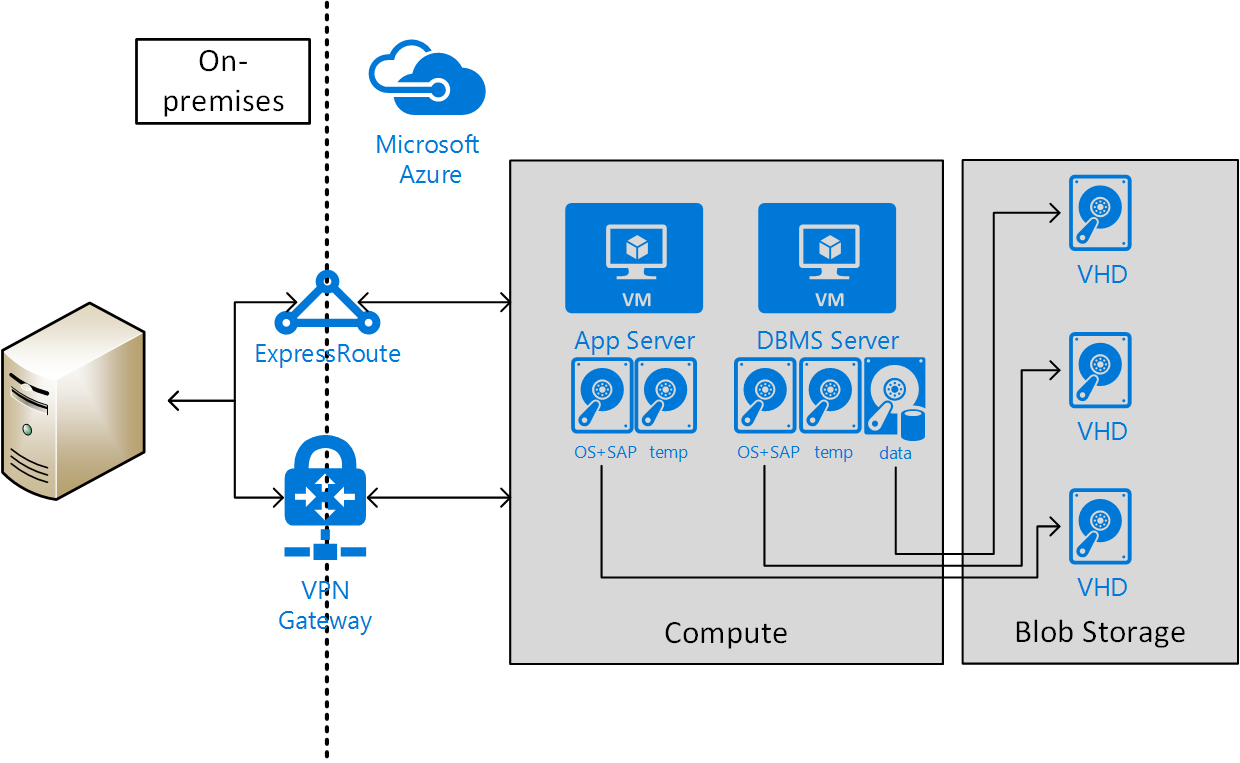
Site-naar-site-connectiviteit via VPN of ExpressRoute is nodig voor productiescenario's. Dit type verbinding is ook nodig voor niet-productiescenario's die worden ingevoerd in productiescenario's waarin SAP-software wordt gebruikt. In de volgende afbeelding ziet u een voorbeeld van connectiviteit tussen sites:
Azure VM-typen kiezen
SAP vermeldt welke typen Azure-VM's u kunt gebruiken voor productiescenario's. Voor niet-productiescenario's is een grotere verscheidenheid aan systeemeigen Azure VM-typen beschikbaar.
Notitie
Voor niet-productiescenario's gebruikt u de VM-typen die worden vermeld in de SAP-opmerking #1928533. Voor het gebruik van Azure-VM's voor productiescenario's controleert u op gecertificeerde SAP HANA-VM's in de gepubliceerde lijst met gecertificeerde IaaS-platformen van SAP.
Implementeer de VM's in Azure met behulp van:
- De Azure Portal.
- Azure PowerShell-cmdlets.
- De Azure CLI.
U kunt ook een volledig geïnstalleerd SAP HANA-platform implementeren op de Azure VM-services via het SAP Cloud-platform. Het installatieproces wordt beschreven in SAP S/4HANA of BW/4HANA implementeren in Azure.
Belangrijk
Als u M208xx_v2 VM's wilt gebruiken, moet u zorgvuldig uw Linux-installatiekopieën selecteren. Zie voor meer informatie de grootten van virtuele machines die zijn geoptimaliseerd voor geheugen.
Opslagconfiguratie voor SAP HANA
Lees het document over opslagconfiguraties en opslagtypen die moeten worden gebruikt met SAP HANA in Azure
Virtuele Netwerken van Azure instellen
Wanneer u een site-naar-site-verbinding met Azure hebt via VPN of ExpressRoute, moet u ten minste één virtueel Azure-netwerk hebben dat is verbonden via een virtuele gateway met het VPN- of ExpressRoute-circuit. In eenvoudige implementaties kan de virtuele gateway ook worden geïmplementeerd in een subnet van het virtuele Azure-netwerk (VNet) dat als host fungeert voor de SAP HANA-exemplaren. Als u SAP HANA wilt installeren, maakt u nog twee subnetten in het virtuele Azure-netwerk. Eén subnet fungeert als host voor de VM's om de SAP HANA-exemplaren uit te voeren. Het andere subnet voert Jumpbox- of beheer-VM's uit om SAP HANA Studio, andere beheersoftware of uw toepassingssoftware te hosten.
Belangrijk
Onvoldoende functionaliteit, maar belangrijker vanwege prestatieredenen, wordt niet ondersteund om virtuele Azure-netwerkapparaten te configureren in het communicatiepad tussen de SAP-toepassing en de DBMS-laag van een SAP NetWeaver-, Hybris- of S/4HANA-systeem. De communicatie tussen de SAP-toepassingslaag en de DBMS-laag moet direct zijn. De beperking omvat geen Azure ASG- en NSG-regels zolang deze ASG- en NSG-regels directe communicatie toestaan. Verdere scenario's waarbij NVA's niet worden ondersteund, bevinden zich in communicatiepaden tussen Azure-VM's die Linux Pacemaker-clusterknooppunten en SBD-apparaten vertegenwoordigen, zoals beschreven in Hoge beschikbaarheid voor SAP NetWeaver op Azure-VM's op SUSE Linux Enterprise Server voor SAP-toepassingen. Of in communicatiepaden tussen Azure-VM's en Windows Server SOFS ingesteld zoals beschreven in Cluster an SAP ASCS/SCS instance on a Windows failover cluster by using a file share in Azure. NVA's in communicatiepaden kunnen eenvoudig de netwerklatentie tussen twee communicatiepartners verdubbelen, kunnen de doorvoer in kritieke paden tussen de SAP-toepassingslaag en de DBMS-laag beperken. In sommige scenario's die worden waargenomen met klanten, kunnen NVA's ertoe leiden dat Pacemaker Linux-clusters mislukken in gevallen waarin communicatie tussen de Linux Pacemaker-clusterknooppunten via een NVA met hun SBD-apparaat moet communiceren.
Belangrijk
Een ander ontwerp dat NIET wordt ondersteund, is de scheiding van de SAP-toepassingslaag en de DBMS-laag in verschillende virtuele Azure-netwerken die niet met elkaar zijn gekoppeld. Het wordt aanbevolen om de SAP-toepassingslaag en DBMS-laag te scheiden met behulp van subnetten binnen een virtueel Azure-netwerk in plaats van verschillende virtuele Azure-netwerken te gebruiken. Als u besluit de aanbeveling niet te volgen en in plaats daarvan de twee lagen in verschillende virtuele netwerken te scheiden, moeten de twee virtuele netwerken worden gekoppeld. Houd er rekening mee dat netwerkverkeer tussen twee gekoppelde virtuele Azure-netwerken onderhevig zijn aan overdrachtskosten. Met het enorme gegevensvolume in veel Terabytes dat is uitgewisseld tussen de SAP-toepassingslaag en de DBMS-laag, kunnen aanzienlijke kosten worden verzameld als de SAP-toepassingslaag en DBMS-laag worden gescheiden tussen twee gekoppelde virtuele Azure-netwerken.
Als u Jumpbox- of beheer-VM's in een afzonderlijk subnet hebt geïmplementeerd, kunt u meerdere virtuele netwerkinterfacekaarten (vNIC's) definiëren voor de HANA-VM, waarbij elke vNIC is toegewezen aan een ander subnet. Met de mogelijkheid om meerdere vNIC's te hebben, kunt u indien nodig netwerkverkeersscheiding instellen. Clientverkeer kan bijvoorbeeld worden gerouteerd via de primaire vNIC en beheerdersverkeer wordt gerouteerd via een tweede vNIC.
U wijst ook statische privé-IP-adressen toe die zijn geïmplementeerd voor beide virtuele NIC's.
Notitie
U moet statische IP-adressen via Azure toewijzen aan afzonderlijke vNIC's. Wijs geen statische IP-adressen binnen het gastbesturingssystemen toe aan een vNIC. Sommige Azure-services zoals Azure Backup Service zijn afhankelijk van het feit dat ten minste de primaire vNIC is ingesteld op DHCP en niet op statische IP-adressen. Zie ook het document Problemen met back-ups van virtuele Azure-machines oplossen. Als u meerdere statische IP-adressen aan een virtuele machine wilt toewijzen, moet u meerdere vNIC's toewijzen aan een virtuele machine.
Voor implementaties die blijvend zijn, moet u echter een netwerkarchitectuur voor een virtueel datacenter maken in Azure. Deze architectuur raadt de scheiding aan van de Azure VNet-gateway die verbinding maakt met on-premises in een afzonderlijk Azure-VNet. Dit afzonderlijke VNet moet alle verkeer hosten dat on-premises of internet verlaat. Met deze aanpak kunt u software implementeren voor controle- en logboekregistratieverkeer dat het virtuele datacenter in Azure binnenkomt in dit afzonderlijke hub-VNet. U hebt dus één VNet dat als host fungeert voor alle software en configuraties die betrekking hebben op in- en uitgaand verkeer naar uw Azure-implementatie.
De artikelen Over Azure Virtual Datacenter: A Network Perspective en Azure Virtual Datacenter en het Enterprise Control Plane geven meer informatie over de benadering van het virtuele datacenter en het bijbehorende Azure VNet-ontwerp.
Notitie
Verkeer dat tussen een hub-VNet en spoke-VNet stroomt met behulp van Azure VNet-peering , is onderhevig aan extra kosten. Op basis van deze kosten moet u overwegen om compromissen te maken tussen het uitvoeren van een strikt hub- en spoke-netwerkontwerp en het uitvoeren van meerdere Azure ExpressRoute-gateways die u verbindt met spokes om VNet-peering te omzeilen. Azure ExpressRoute-gateways brengen echter ook extra kosten met zich mee. U kunt ook extra kosten ondervinden voor software van derden die u gebruikt voor logboekregistratie, controle en bewaking van netwerkverkeer. Afhankelijk van de kosten voor gegevensuitwisseling via VNet-peering aan de ene kant en de kosten die zijn gemaakt door extra Azure ExpressRoute-gateways en extra softwarelicenties, kunt u binnen één VNet kiezen voor microsegmentatie door subnetten als isolatie-eenheid te gebruiken in plaats van VNets.
Zie IP-adrestypen en toewijzingsmethoden in Azure voor een overzicht van de verschillende methoden voor het toewijzen van IP-adressen.
Voor VM's met SAP HANA moet u werken met vaste IP-adressen die zijn toegewezen. Reden is dat sommige configuratiekenmerken voor HANA-referentie-IP-adressen.
Azure-netwerkbeveiligingsgroepen (NSG's) worden gebruikt om verkeer te leiden dat wordt doorgestuurd naar het SAP HANA-exemplaar of de jumpbox. De NSG's en uiteindelijk toepassingsbeveiligingsgroepen zijn gekoppeld aan het SAP HANA-subnet en het beheersubnet.
Als u SAP HANA in Azure wilt implementeren zonder een site-naar-site-verbinding, wilt u het SAP HANA-exemplaar nog steeds afschermen van het openbare internet en deze verbergen achter een doorstuurproxy. In dit basisscenario is de implementatie afhankelijk van ingebouwde DNS-services van Azure om hostnamen op te lossen. In een complexere implementatie waarbij openbare IP-adressen worden gebruikt, zijn ingebouwde DNS-services van Azure vooral belangrijk. Gebruik Azure NSG's en Azure NVA's om de routering van internet naar uw Azure VNet-architectuur in Azure te controleren. In de volgende afbeelding ziet u een ruw schema voor het implementeren van SAP HANA zonder site-naar-site-verbinding in een hub- en spoke-VNet-architectuur:
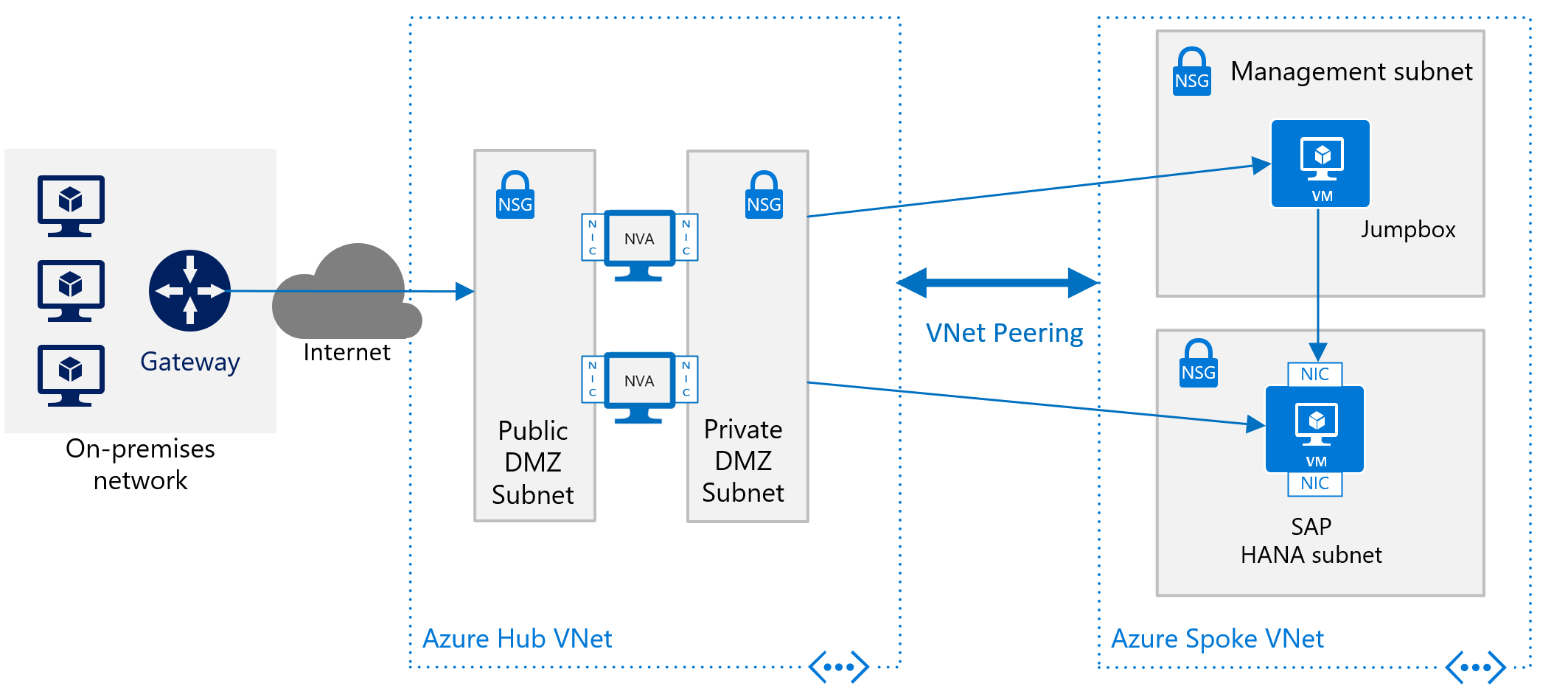
Een andere beschrijving over het gebruik van Azure NVA's voor het beheren en bewaken van toegang vanaf internet zonder de hub- en spoke-VNet-architectuur vindt u in het artikel Maximaal beschikbare virtuele netwerkapparaten implementeren.
Klokbronopties in Virtuele Azure-machines
SAP HANA vereist betrouwbare en nauwkeurige tijdsinformatie om optimaal te kunnen presteren. Traditioneel gebruikt Azure-VM's die worden uitgevoerd op azure-hypervisor alleen Hyper-V TSC-pagina als standaard klokbron. Technologieverbeteringen in hardware, hostbesturingssystemen en Linux-gastbesturingssystemen maakten het mogelijk om 'Invariant TSC' te bieden als een klokbronoptie op sommige Azure VM-SKU's.
Hyper-V TSC-pagina (hyperv_clocksource_tsc_page) wordt ondersteund op alle Virtuele Azure-machines als klokbron.
Als de onderliggende hardware, hypervisor en gastbesturingssystemen linux kernel ondersteunen Invariant TSC, tsc wordt aangeboden als beschikbaar en ondersteunde klokbron in het gastbesturingssystemen op Virtuele Azure-machines.
Azure-infrastructuur configureren voor uitschalen van SAP HANA
Raadpleeg de SAP HANA-hardwaremap om de azure-VM-typen te achterhalen die zijn gecertificeerd voor OLAP-uitschalen of S/4HANA-uitschalen. Een vinkje in de kolom Clustering geeft ondersteuning voor uitschalen aan. Toepassingstype geeft aan of uitschalen van OLAP of S/4HANA wordt ondersteund. Raadpleeg de vermelding voor een specifieke VM-SKU die wordt vermeld in de SAP HANA-hardwaremap voor meer informatie over knooppunten die zijn gecertificeerd in uitschalen.
De minimale versie van het besturingssysteem voor het implementeren van uitschaalconfiguraties in Azure-VM's, controleert u de details van de vermeldingen in de specifieke VM-SKU die wordt vermeld in de SAP HANA-hardwaremap. Van een OLAP-uitschaalconfiguratie n-knooppunt fungeert één knooppunt als het hoofdknooppunt. De andere knooppunten tot aan de limiet van de certificering fungeren als werkknooppunt. Meer stand-byknooppunten tellen niet mee in het aantal gecertificeerde knooppunten
Notitie
Uitschaalimplementaties van AZURE VM's van SAP HANA met stand-byknooppunt zijn alleen mogelijk met behulp van de Azure NetApp Files-opslag . Geen andere door SAP HANA gecertificeerde Azure-opslag staat de configuratie van SAP HANA stand-byknooppunten toe
Voor /hana/shared raden we het gebruik van Azure NetApp Files of Azure Files aan.
Een typisch basisontwerp voor één knooppunt in een uitschaalconfiguratie, met /hana/shared geïmplementeerd in Azure NetApp Files, ziet er als volgt uit:
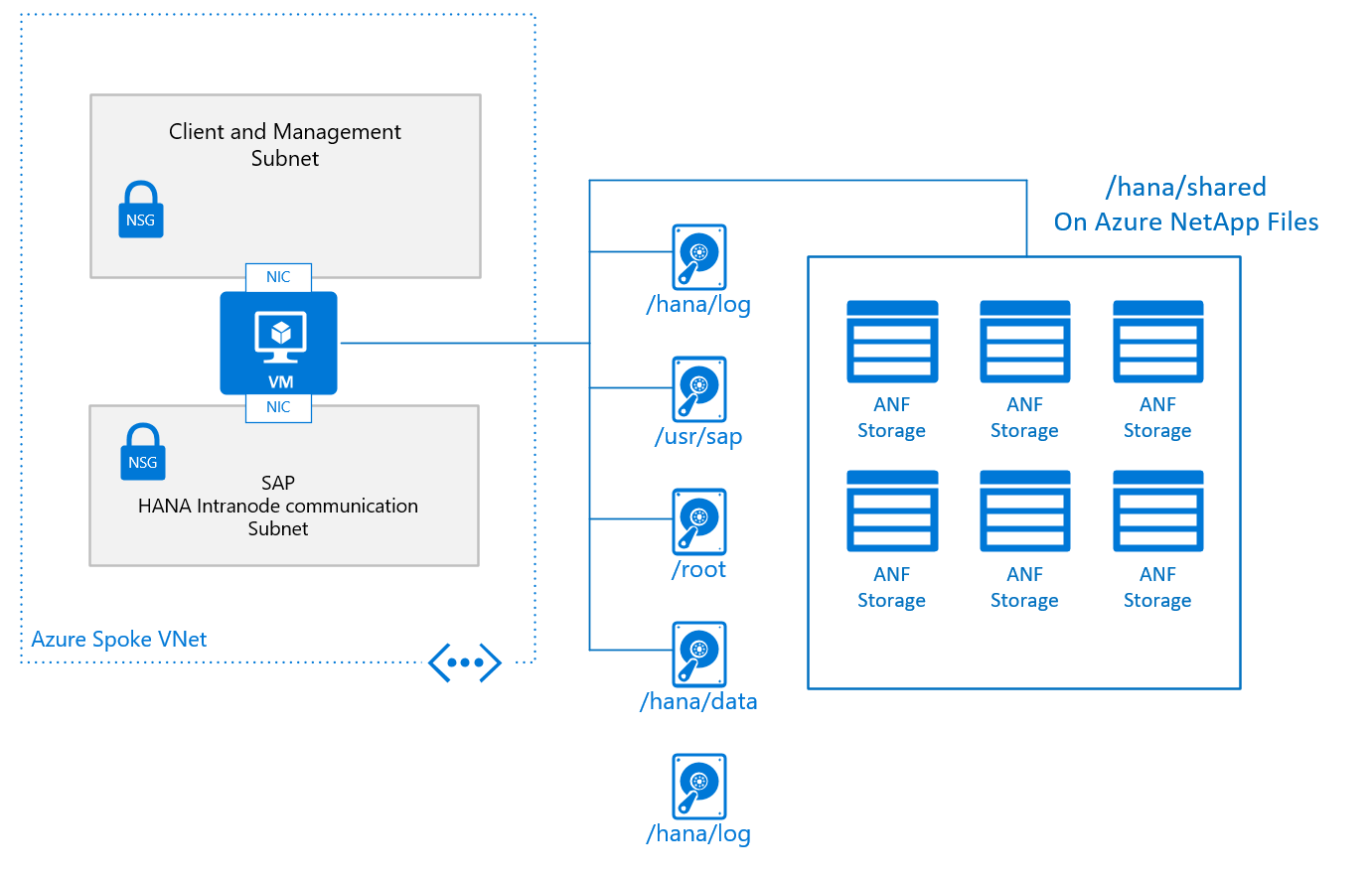
De basisconfiguratie van een VM-knooppunt voor SAP HANA-uitschalen ziet er als volgt uit:
- Voor /hana/shared gebruikt u de systeemeigen NFS-service die wordt geleverd via Azure NetApp Files of Azure Files.
- Alle andere schijfvolumes worden niet gedeeld tussen de verschillende knooppunten en zijn niet gebaseerd op NFS. Installatieconfiguraties en stappen voor het uitschalen van HANA-installaties met niet-gedeelde /hana/data en /hana/log vindt u verderop in dit document. Voor gecertificeerde HANA-opslag die kan worden gebruikt, raadpleegt u het artikel SAP HANA Azure Virtual Machine Storage-configuraties.
Als u de grootte van de volumes of schijven wilt aanpassen, moet u het document controleren op de OPSLAGvereisten voor SAP HANA TDI voor de grootte die afhankelijk is van het aantal werkknooppunten. In het document wordt een formule uitgebracht die u moet toepassen om de vereiste capaciteit van het volume te verkrijgen
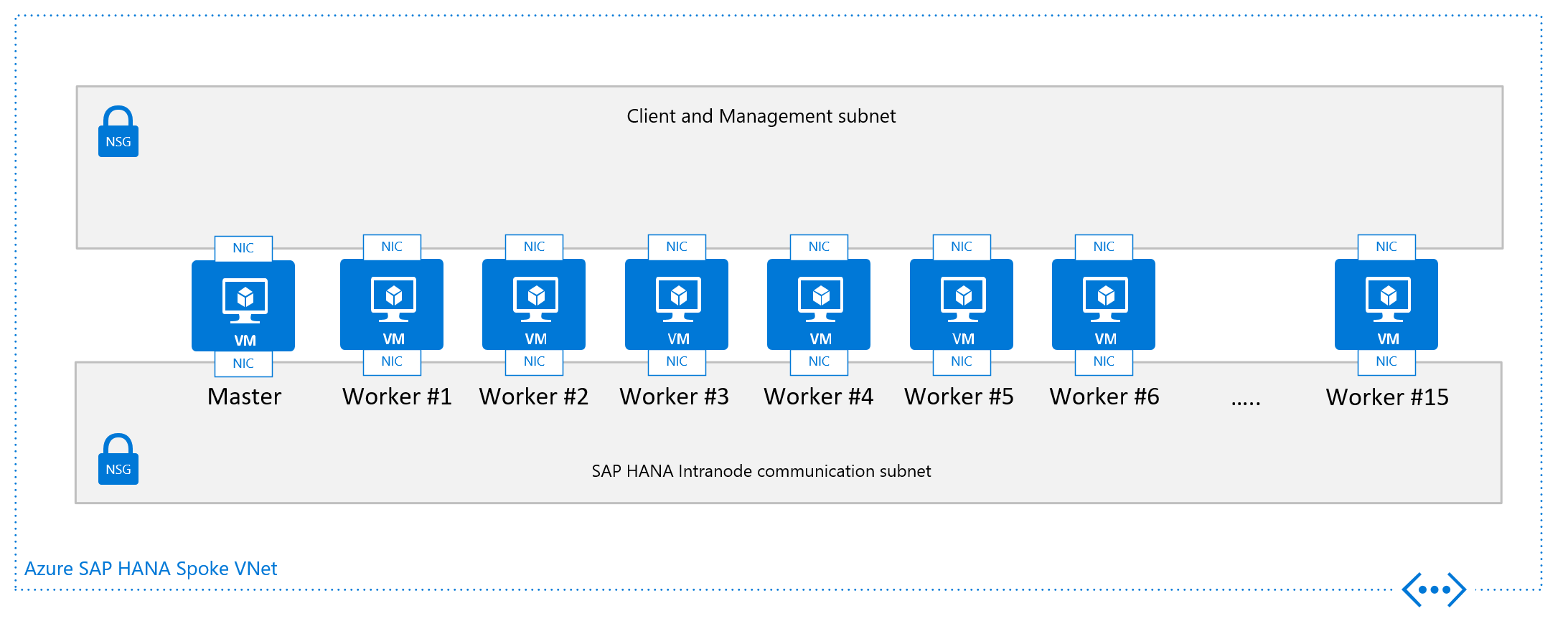
De andere ontwerpcriteria die worden weergegeven in de afbeeldingen van de configuratie van één knooppunt voor een uitschaalbare SAP HANA-VM, is het VNet of beter de subnetconfiguratie. SAP raadt ten zeerste een scheiding aan van het client-/toepassingsverkeer van de communicatie tussen de HANA-knooppunten. Zoals wordt weergegeven in de afbeeldingen, wordt dit doel bereikt door twee verschillende vNIC's aan de virtuele machine te koppelen. Beide vNIC's bevinden zich in verschillende subnetten en hebben twee verschillende IP-adressen. Vervolgens beheert u de verkeersstroom met routeringsregels met behulp van NSG's of door de gebruiker gedefinieerde routes.
In het bijzonder in Azure zijn er geen middelen en methoden voor het afdwingen van de kwaliteit van de service en quota op specifieke vNIC's. Als gevolg hiervan opent de scheiding van client-/toepassingsgerichte communicatie en communicatie tussen knooppunten geen mogelijkheden om prioriteit te geven aan één verkeersstroom boven de andere. In plaats daarvan blijft de scheiding een maateenheid voor beveiliging bij het afschermen van de communicatie tussen knooppunten van de uitschaalconfiguraties.
Notitie
SAP raadt aan netwerkverkeer te scheiden van client-/toepassings- en intraknooppuntverkeer, zoals beschreven in dit document. Daarom wordt aanbevolen om een architectuur op de plaats te plaatsen, zoals wordt weergegeven in de laatste afbeeldingen. Raadpleeg ook uw beveiligings- en complianceteam voor vereisten die afwijken van de aanbeveling
Vanuit een netwerkpunt zou de minimaal vereiste netwerkarchitectuur er als volgt uitzien:
SAP HANA scale-out n Azure installeren
Als u een uitschaalbare SAP-configuratie installeert, moet u ruwe stappen uitvoeren van:
- Een bestaande Azure VNet-infrastructuur implementeren of aanpassen
- De nieuwe VM's implementeren met Azure Managed Premium Storage, Ultra Disk-volumes en/of NFS-volumes op basis van ANF
-
- Pas netwerkroutering aan om ervoor te zorgen dat bijvoorbeeld intraknooppuntcommunicatie tussen VM's niet wordt gerouteerd via een NVA.
- Installeer het hoofdknooppunt van SAP HANA.
- Configuratieparameters van het hoofdknooppunt van SAP HANA aanpassen
- Doorgaan met de installatie van de SAP HANA-werkknooppunten
Installatie van SAP HANA in scale-outconfiguratie
Wanneer uw Azure VM-infrastructuur wordt geïmplementeerd en alle andere voorbereidingen worden uitgevoerd, moet u de uitschaalconfiguraties van SAP HANA installeren in deze stappen:
- Installeer het hoofdknooppunt van SAP HANA volgens de documentatie van SAP
- Wanneer u Azure Premium Storage of Ultra Disk Storage gebruikt met niet-gedeelde schijven van
/hana/dataen/hana/log, voegt u de parameterbasepath_shared = notoe aan hetglobal.inibestand. Met deze parameter kan SAP HANA worden uitgevoerd in uitschalen zonder gedeelde/hana/datavolumes tussen/hana/logde knooppunten. Details worden beschreven in SAP Note #2080991. Als u NFS-volumes gebruikt op basis van ANF voor /hana/data en /hana/log, hoeft u deze wijziging niet aan te brengen - Nadat de uiteindelijke wijziging in de parameter global.ini, start u het SAP HANA-exemplaar opnieuw op
- Voeg meer werkknooppunten toe. Zie Hosts toevoegen met behulp van de opdrachtregelinterface voor meer informatie. Geef het interne netwerk op voor communicatie tussen SAP HANA-knooppunten tijdens de installatie of later met behulp van bijvoorbeeld de lokale hdblcm. Zie SAP Note #2183363 voor meer gedetailleerde documentatie.
Als u een SAP HANA-scale-outsysteem wilt instellen met een stand-byknooppunt, raadpleegt u de instructies voor de implementatie van SUSE Linux of de instructies voor de Red Hat-implementatie.
SAP HANA Dynamic Tiering 2.0 voor virtuele Azure-machines
Naast de SAP HANA-certificeringen op vm's uit de Azure M-serie wordt SAP HANA Dynamic Tiering 2.0 ook ondersteund in Microsoft Azure. Zie koppelingen naar DT 2.0-documentatie voor meer informatie. Er is geen verschil in het installeren of gebruiken van het product. U kunt bijvoorbeeld SAP HANA Cockpit installeren in een Virtuele Azure-machine. Er zijn echter enkele verplichte vereisten, zoals beschreven in de volgende sectie, voor officiële ondersteuning in Azure. In het hele artikel wordt de afkorting 'DT 2.0' gebruikt in plaats van de volledige naam Dynamic Tiering 2.0.
Dynamische laaging van SAP HANA 2.0 wordt niet ondersteund door SAP BW of S4HANA. De belangrijkste use cases zijn nu systeemeigen HANA-toepassingen.
Overzicht
In de onderstaande afbeelding ziet u een overzicht van DT 2.0-ondersteuning op Microsoft Azure. Er is een reeks verplichte vereisten die moeten worden gevolgd om te voldoen aan de officiële certificering:
- DT 2.0 moet zijn geïnstalleerd op een toegewezen Azure-VM. Het wordt mogelijk niet uitgevoerd op dezelfde VM waarop SAP HANA wordt uitgevoerd
- SAP HANA- en DT 2.0-VM's moeten worden geïmplementeerd binnen hetzelfde Azure-Vnet
- De SAP HANA- en DT 2.0-VM's moeten worden geïmplementeerd met versneld netwerken van Azure ingeschakeld
- Opslagtype voor de DT 2.0-VM's moet Azure Premium Storage zijn
- Er moeten meerdere Azure-schijven worden gekoppeld aan de DT 2.0-VM
- Het is vereist om een software raid/striped volume te maken (via lvm of mdadm) met behulp van striping over de Azure-schijven
Meer informatie wordt uitgelegd in de volgende secties.
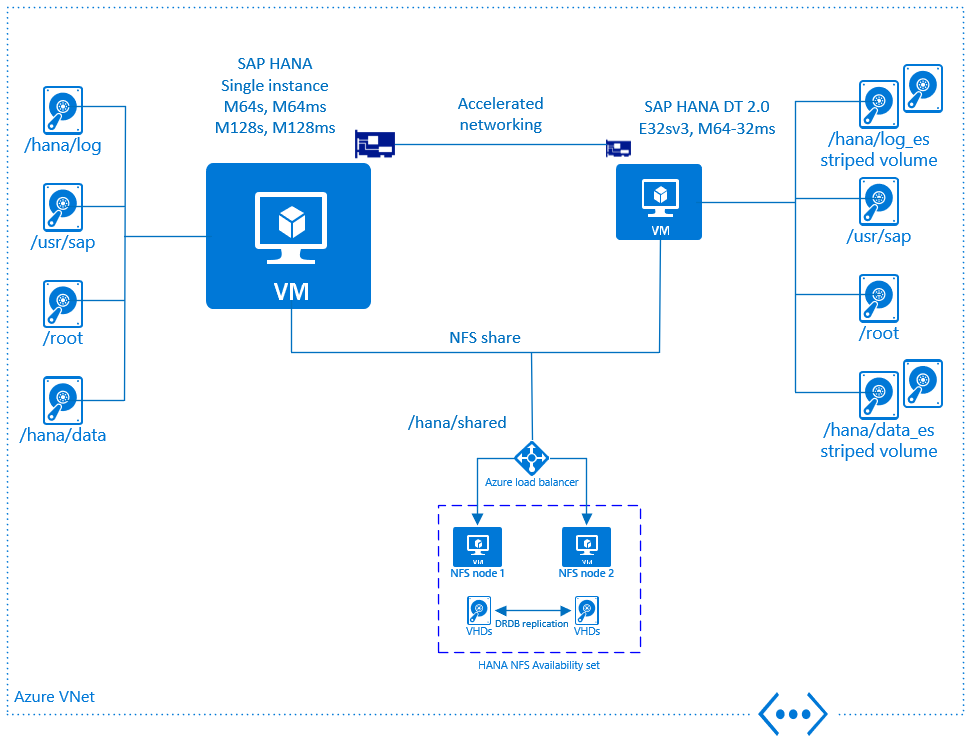
Toegewezen Azure-VM voor SAP HANA DT 2.0
Op Azure IaaS wordt DT 2.0 alleen ondersteund op een toegewezen VM. Het is niet toegestaan om DT 2.0 uit te voeren op dezelfde Azure-VM waarop het HANA-exemplaar wordt uitgevoerd. In eerste instantie kunnen twee VM-typen worden gebruikt om SAP HANA DT 2.0 uit te voeren:
- M64-32ms
- E32sv3
Zie Azure VM-grootten - Geheugen voor meer informatie over de beschrijving van het VM-type
Gezien het basisidee van DT 2.0, dat gaat over het offloaden van 'warme' gegevens om kosten te besparen, is het zinvol om overeenkomstige VM-grootten te gebruiken. Er is echter geen strikte regel met betrekking tot de mogelijke combinaties. Dit is afhankelijk van de specifieke workload van de klant.
Aanbevolen configuraties zijn:
| TYPE SAP HANA-VM | DT 2.0 VM-type |
|---|---|
| M128ms | M64-32ms |
| M128s | M64-32ms |
| M64ms | E32sv3 |
| M64s | E32sv3 |
Alle combinaties van door SAP HANA gecertificeerde VM's uit de M-serie met ondersteunde DT 2.0-VM's (M64-32ms en E32sv3) zijn mogelijk.
Azure-netwerken en SAP HANA DT 2.0
Voor het installeren van DT 2.0 op een toegewezen VM is netwerkdoorvoer vereist tussen de DT 2.0-VM en de SAP HANA-VM van minimaal 10 Gb. Daarom is het verplicht om alle VM's binnen hetzelfde Azure-Vnet te plaatsen en versnelde Netwerken van Azure in te schakelen.
Zie aanvullende informatie over versnelde Azure-netwerken Een Azure-VM maken met versneld netwerken met behulp van Azure CLI
VM-opslag voor SAP HANA DT 2.0
Volgens de best practice voor DT 2.0 moet de io-doorvoer van de schijf minimaal 50 MB per fysieke kern zijn.
Volgens de specificaties voor de twee Azure VM-typen, die worden ondersteund voor DT 2.0, ziet de maximale doorvoerlimiet voor schijf-IO voor de VIRTUELE machine er als volgt uit:
- E32sv3: 768 MB per seconde (niet in cache) wat een verhouding van 48 MB per fysieke kern betekent
- M64-32 ms: 1000 MB per seconde (niet in cache) wat een verhouding van 62,5 MB per fysieke kern betekent
Het is vereist om meerdere Azure-schijven te koppelen aan de DT 2.0-VM en een software-raid (striping) te maken op besturingssysteemniveau om de maximale limiet voor schijfdoorvoer per VM te bereiken. Op één Azure-schijf kan de doorvoer niet worden opgegeven om de maximale VM-limiet in dit opzicht te bereiken. Azure Premium Storage is verplicht om DT 2.0 uit te voeren.
- Meer informatie over beschikbare Azure-schijftypen vindt u op de pagina Een schijftype selecteren voor Azure IaaS-VM's - beheerde schijven
- Meer informatie over het maken van software raid via mdadm vindt u op de pagina Software RAID configureren op een Linux-VM-pagina
- Meer informatie over het configureren van LVM voor het maken van een gestreept volume voor maximale doorvoer vindt u op de pagina LVM configureren op een virtuele machine waarop Linux wordt uitgevoerd
Afhankelijk van de groottevereisten zijn er verschillende opties om de maximale doorvoer van een VIRTUELE machine te bereiken. Hier volgen mogelijke configuraties voor gegevensvolumeschijven voor elk type DT 2.0-VM om de maximale doorvoerlimiet voor vm's te bereiken. De VIRTUELE machine E32sv3 moet worden beschouwd als invoerniveau voor kleinere workloads. Als het zou moeten blijken dat het niet snel genoeg is, kan het nodig zijn om het formaat van de VIRTUELE machine te wijzigen in M64-32 ms. Omdat de VM M64-32 ms veel geheugen heeft, bereikt de IO-belasting mogelijk niet de limiet, met name voor leesintensieve workloads. Daarom kunnen er minder schijven in de stripeset voldoende zijn, afhankelijk van de specifieke workload van de klant. Maar om aan de veilige kant te zijn de onderstaande schijfconfiguraties gekozen om de maximale doorvoer te garanderen:
| VM-SKU | Schijfconfiguratie 1 | Schijfconfiguratie 2 | Schijfconfiguratie 3 | Schijfconfiguratie 4 | Schijfconfiguratie 5 |
|---|---|---|---|---|---|
| M64-32ms | 4 x P50 -> 16 TB | 4 x P40 -> 8 TB | 5 x P30 -> 5 TB | 7 x P20 -> 3,5 TB | 8 x P15 -> 2 TB |
| E32sv3 | 3 x P50 -> 12 TB | 3 x P40 -> 6 TB | 4 x P30 -> 4 TB | 5 x P20 -> 2,5 TB | 6 x P15 -> 1,5 TB |
Vooral in het geval dat de workload leesintensieve is, kan het io-prestaties verbeteren om de Azure-hostcache 'alleen-lezen' in te schakelen, zoals wordt aanbevolen voor de gegevensvolumes van databasesoftware. Terwijl voor het transactielogboek azure-hostschijfcache 'geen' moet zijn.
Wat betreft de grootte van het logboekvolume is een aanbevolen uitgangspunt een heuristiek van 15% van de gegevensgrootte. Het maken van het logboekvolume kan worden uitgevoerd met behulp van verschillende Azure-schijftypen, afhankelijk van de kosten- en doorvoervereisten. Voor het logboekvolume is een hoge I/O-doorvoer vereist.
Wanneer u het VM-type M64-32 ms gebruikt, is het verplicht om Write Accelerator in te schakelen. Azure Write Accelerator biedt optimale schijfschrijflatentie voor het transactielogboek (alleen beschikbaar voor M-serie). Er zijn enkele items om rekening mee te houden, zoals het maximum aantal schijven per VM-type. Meer informatie over Write Accelerator vindt u op de pagina Azure Write Accelerator
Hier volgen enkele voorbeelden van het wijzigen van de grootte van het logboekvolume:
| grootte van gegevensvolume en schijftype | configuratie van logboekvolume en schijftype 1 | logboekvolume en schijftype config 2 |
|---|---|---|
| 4 x P50 -> 16 TB | 5 x P20 -> 2,5 TB | 3 x P30 -> 3 TB |
| 6 x P15 -> 1,5 TB | 4 x P6 -> 256 GB | 1 x P15 -> 256 GB |
Net als bij het uitschalen van SAP HANA moet de map /hana/shared worden gedeeld tussen de SAP HANA-VM en de DT 2.0-VM. Dezelfde architectuur als voor HET uitschalen van SAP HANA met behulp van toegewezen VM's, die fungeren als een maximaal beschikbare NFS-server, wordt aanbevolen. Om een gedeeld back-upvolume te bieden, kan het identieke ontwerp worden gebruikt. Maar het is aan de klant als hoge beschikbaarheid nodig is of als het voldoende is om een toegewezen VM met voldoende opslagcapaciteit te gebruiken om als back-upserver te fungeren.
Koppelingen naar DT 2.0-documentatie
- Installatie- en updatehandleiding voor dynamische lagen voor SAP HANA
- Zelfstudies en resources voor dynamische lagen voor SAP HANA
- SAP HANA Dynamic Tiering PoC
- Verbeteringen in dynamische lagen van SAP HANA 2.0 SPS 02
Bewerkingen voor het implementeren van SAP HANA op Azure-VM's
In de volgende secties worden enkele bewerkingen beschreven die betrekking hebben op het implementeren van SAP HANA-systemen op Azure-VM's.
Back-up- en herstelbewerkingen maken op Virtuele Azure-machines
In de volgende documenten wordt beschreven hoe u een back-up maakt van uw SAP HANA-implementatie en deze herstelt:
- Overzicht van back-ups van SAP HANA
- Back-up op SAP HANA-bestandsniveau
- Benchmark voor sap HANA-opslagmomentopnamen
VM's starten en opnieuw starten die SAP HANA bevatten
Een prominente functie van de openbare Azure-cloud is dat er alleen kosten in rekening worden gebracht voor uw rekenminuten. Wanneer u bijvoorbeeld een VIRTUELE machine afsluit waarop SAP HANA wordt uitgevoerd, wordt u alleen gefactureerd voor de opslagkosten gedurende die tijd. Er is een andere functie beschikbaar wanneer u statische IP-adressen opgeeft voor uw VM's in de eerste implementatie. Wanneer u een VIRTUELE machine met SAP HANA opnieuw opstart, wordt de VIRTUELE machine opnieuw opgestart met de eerdere IP-adressen.
SAProuter gebruiken voor externe SAP-ondersteuning
Als u een site-naar-site-verbinding hebt tussen uw on-premises locaties en Azure en u SAP-onderdelen uitvoert, gebruikt u waarschijnlijk al SAProuter. In dit geval voltooit u de volgende items voor externe ondersteuning:
- Onderhoud het privé- en statische IP-adres van de VIRTUELE machine die als host fungeert voor SAP HANA in de SAProuter-configuratie.
- Configureer de NSG van het subnet dat als host fungeert voor de HANA-VM om verkeer via TCP/IP-poort 3299 toe te staan.
Als u via internet verbinding maakt met Azure en u geen SAP-router voor de VIRTUELE machine hebt met SAP HANA, moet u het onderdeel installeren. Installeer SAProuter in een afzonderlijke VM in het beheersubnet. In de volgende afbeelding ziet u een ruw schema voor het implementeren van SAP HANA zonder site-naar-site-verbinding en met SAProuter:
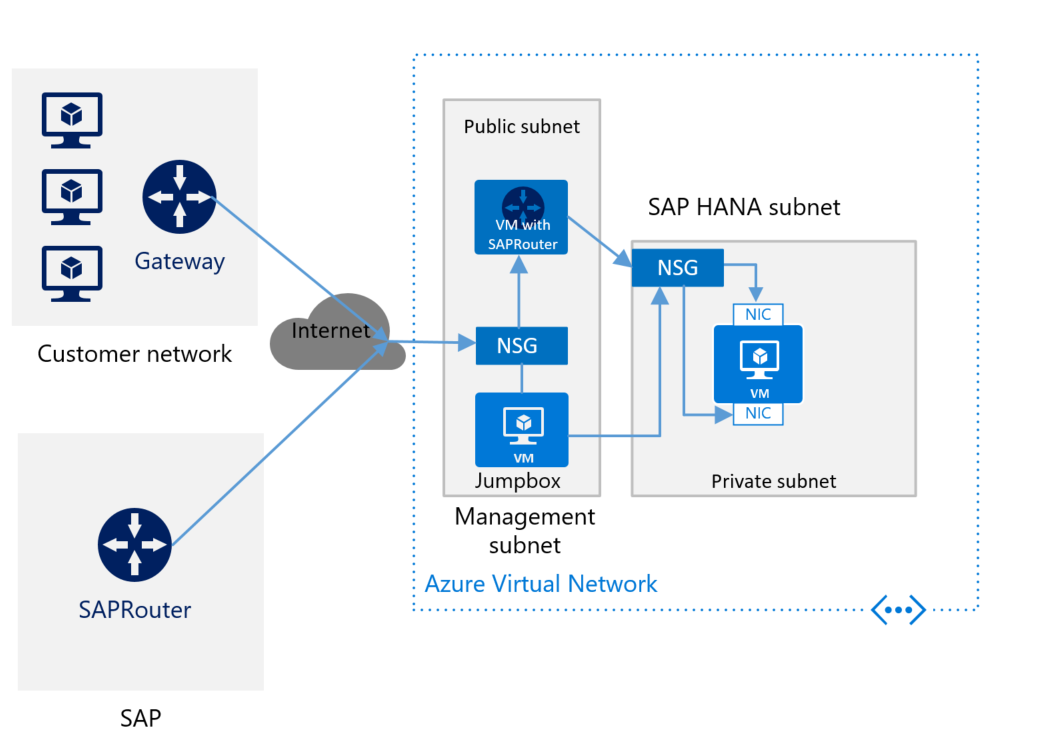
Zorg ervoor dat u SAProuter installeert in een afzonderlijke VM en niet in uw Jumpbox-VM. De afzonderlijke VM moet een statisch IP-adres hebben. Als u uw SAProuter wilt verbinden met de SAProuter die wordt gehost door SAP, neemt u contact op met SAP voor een IP-adres. (De SAProuter die wordt gehost door SAP is de tegenhanger van het SAProuter-exemplaar dat u op uw VM installeert.) Gebruik het IP-adres van SAP om uw SAProuter-exemplaar te configureren. In de configuratie-instellingen is de enige benodigde poort TCP-poort 3299.
Zie de SAP-documentatie voor meer informatie over het instellen en onderhouden van externe ondersteuningsverbindingen via SAProuter.
Hoge beschikbaarheid met SAP HANA op systeemeigen Azure-VM's
Als u SUSE Linux Enterprise Server of Red Hat uitvoert, kunt u een Pacemaker-cluster opzetten met fencing-apparaten. U kunt de apparaten gebruiken om een SAP HANA-configuratie in te stellen die gebruikmaakt van synchrone replicatie met HANA-systeemreplicatie en automatische failover. Zie de sectie Volgende stappen voor meer informatie.
Volgende stappen
Vertrouwd raken met de artikelen zoals vermeld
- Opslagconfiguraties voor virtuele AZURE-machines in SAP HANA
- Een SAP HANA-uitschaalsysteem met stand-byknooppunt implementeren op Azure-VM's met behulp van Azure NetApp Files in SUSE Linux Enterprise Server
- Een SAP HANA-uitschaalsysteem met stand-byknooppunt implementeren op Azure-VM's met behulp van Azure NetApp Files in Red Hat Enterprise Linux
- Een SAP HANA-uitschaalsysteem implementeren met HSR en Pacemaker op Azure-VM's op SUSE Linux Enterprise Server
- Een SAP HANA-scale-outsysteem implementeren met HSR en PAcemaker op Azure-VM's op Red Hat Enterprise Linux
- Hoge beschikbaarheid van SAP HANA in Azure-VM's in SUSE Linux Enterprise Server
- hoge beschikbaarheid van SAP HANA in Azure-VM's in Red Hat Enterprise Linux