NFS v4.1-volumes in Azure NetApp Files voor SAP HANA
Azure NetApp Files biedt systeemeigen NFS-shares die kunnen worden gebruikt voor /hana/shared, /hana/data en /hana/log-volumes . Voor het gebruik van op ANF gebaseerde NFS-shares voor de /hana/data - en /hana/logboekvolumes is het gebruik van het v4.1 NFS-protocol vereist. Het NFS-protocol v3 wordt niet ondersteund voor het gebruik van /hana/data en /hana/logboekvolumes bij het baseren van de shares op ANF.
Belangrijk
Het NFS v3-protocol dat is geïmplementeerd in Azure NetApp Files, wordt niet ondersteund om te worden gebruikt voor /hana/data en /hana/log. Het gebruik van NFS 4.1 is verplicht voor /hana/data en /hana/logvolumes vanuit een functioneel oogpunt. Terwijl voor het /hana/shared volume het NFS v3- of NFS v4.1-protocol vanuit een functioneel oogpunt kan worden gebruikt.
Belangrijke aandachtspunten
Houd rekening met de volgende belangrijke overwegingen bij het overwegen van Azure NetApp Files voor SAP Netweaver en SAP HANA:
Zie Azure NetApp Files-resourcelimieten voor limieten voor volume- en capaciteitspools.
Op Azure NetApp Files gebaseerde NFS-shares en de virtuele machines die deze shares koppelen, moeten zich in hetzelfde virtuele Azure-netwerk of in gekoppelde virtuele netwerken in dezelfde regio bevinden.
Het geselecteerde virtuele netwerk moet een subnet hebben dat is gedelegeerd aan Azure NetApp Files. Voor SAP-werkbelasting wordt het ten zeerste aanbevolen om een /25-bereik te configureren voor het subnet dat is gedelegeerd aan Azure NetApp Files.
Het is belangrijk om ervoor te zorgen dat de virtuele machines voldoende dicht bij de Azure NetApp-opslag zijn geïmplementeerd voor een lagere latentie, bijvoorbeeld door SAP HANA voor schrijfbewerkingen voor opnieuw uitvoeren van logboeken.
- Azure NetApp Files heeft ondertussen functionaliteit voor het implementeren van NFS-volumes in specifieke Azure Beschikbaarheidszones. Een dergelijke zonegebonden nabijheid is in de meeste gevallen voldoende om een latentie van minder dan 1 milliseconden te bereiken. De functionaliteit bevindt zich in de openbare preview en wordt beschreven in het artikel Plaatsing van het volume van de beschikbaarheidszone beheren voor Azure NetApp Files. Deze functionaliteit vereist geen interactief proces met Microsoft om nabijheid te bereiken tussen uw VIRTUELE machine en de NFS-volumes die u toewijst.
- Om de meest optimale nabijheid te bereiken, is de functionaliteit van toepassingsvolumegroepen beschikbaar. Deze functionaliteit is niet alleen op zoek naar de meest optimale nabijheid, maar voor de meest optimale plaatsing van de NFS-volumes, zodat HANA-gegevens en opnieuw logboekvolumes worden verwerkt door verschillende controllers. Het nadeel is dat deze methode een interactief proces met Microsoft nodig heeft om uw VM's vast te maken.
Zorg ervoor dat de latentie van de databaseserver naar het Azure NetApp Files-volume is gemeten en lager is dan 1 milliseconden
De doorvoer van een Azure NetApp-volume is een functie van het volumequotum en serviceniveau, zoals beschreven in Serviceniveau voor Azure NetApp Files. Wanneer u de grootte van de HANA Azure NetApp-volumes wijzigt, moet u ervoor zorgen dat de resulterende doorvoer voldoet aan de HANA-systeemvereisten. U kunt ook een handmatige QoS-capaciteitspool gebruiken waarbij volumecapaciteit en doorvoer onafhankelijk kunnen worden geconfigureerd en geschaald (SAP HANA-specifieke voorbeelden staan in dit document
Probeer volumes te 'consolideren' om meer prestaties te bereiken in een groter volume, bijvoorbeeld één volume gebruiken voor /sapmnt, /usr/sap/trans, ... indien mogelijk
Azure NetApp Files biedt exportbeleid: u kunt de toegestane clients, het toegangstype (Lezen&Schrijven, Alleen-lezen, enzovoort) beheren.
De gebruikers-id voor sidadm en de groeps-id voor
sapsysop de virtuele machines moeten overeenkomen met de configuratie in Azure NetApp Files.Linux-besturingssysteemparameters implementeren die worden vermeld in SAP-notitie 3024346
Belangrijk
Voor SAP HANA/workloads is lage latentie essentieel. Werk samen met uw Microsoft-vertegenwoordiger om ervoor te zorgen dat de virtuele machines en de Azure NetApp Files-volumes dicht bij elkaar worden geïmplementeerd.
Belangrijk
Als er een onjuiste overeenkomst is tussen de gebruikers-id voor sid adm en de groeps-id voor sapsys tussen de virtuele machine en de Azure NetApp-configuratie, worden de machtigingen voor bestanden op Azure NetApp-volumes, gekoppeld aan de virtuele machine, weergegeven als nobody. Zorg ervoor dat u de juiste gebruikers-id opgeeft voor sidadm en de groeps-id voor sapsys, wanneer u een nieuw systeem instapt naar Azure NetApp Files.
Koppelingsoptie NCONNECT
Nconnect is een koppelingsoptie voor NFS-volumes die worden gehost in Azure NetApp Files waarmee de NFS-client meerdere sessies kan openen op één NFS-volume. Als u verbinding maakt met een waarde die groter is dan 1, wordt de NFS-client ook geactiveerd om meer dan één RPC-sessie aan de clientzijde (in het gastbesturingssystem) te gebruiken om het verkeer tussen het gastbesturingssystem en de gekoppelde NFS-volumes te verwerken. Het gebruik van meerdere sessies die verkeer van één NFS-volume verwerken, maar ook het gebruik van meerdere RPC-sessies kan betrekking hebben op prestatie- en doorvoerscenario's zoals:
- Meerdere door Azure NetApp Files gehoste NFS-volumes koppelen met verschillende serviceniveaus in één VIRTUELE machine
- De maximale schrijfdoorvoer voor een volume en één Linux-sessie is tussen 1.2 en 1,4 GB/s. Als u meerdere sessies hebt voor één NFS-volume dat wordt gehost in Azure NetApp Files, kan de doorvoer worden verhoogd
Voor Linux-besturingssysteemreleases die ondersteuning bieden voor nconnect als koppelingsoptie en enkele belangrijke configuratieoverwegingen voor nconnect, met name met verschillende NFS-servereindpunten, leest u het document over opties voor koppelen van Linux NFS voor aanbevolen procedures voor Azure NetApp Files.
Grootte aanpassen voor HANA-database in Azure NetApp Files
De doorvoer van een Azure NetApp-volume is een functie van de volumegrootte en het serviceniveau, zoals beschreven in serviceniveaus voor Azure NetApp Files.
Belangrijk om te begrijpen is de prestatierelatie de grootte en dat er fysieke limieten zijn voor een opslageindpunt van de service. Elk opslageindpunt wordt dynamisch geïnjecteerd in het gedelegeerde subnet van Azure NetApp Files bij het maken van het volume en het ontvangen van een IP-adres. Azure NetApp Files-volumes kunnen , afhankelijk van de beschikbare capaciteit en implementatielogica, een opslageindpunt delen
In de onderstaande tabel ziet u dat het zinvol is om een groot Standaardvolume te maken voor het opslaan van back-ups en dat het niet zinvol is om een Ultra-volume te maken dat groter is dan 12 TB, omdat de maximale fysieke bandbreedtecapaciteit van één volume wordt overschreden.
Als u meer nodig hebt dan de maximale schrijfdoorvoer voor uw /hana/gegevensvolume dan één Linux-sessie kan bieden, kunt u ook SAP HANA-gegevensvolumepartitionering gebruiken als alternatief. Met partitionering van SAP HANA-gegevensvolumes wordt de I/O-activiteit gestreept tijdens het opnieuw laden van gegevens of HANA-opslagpunten in meerdere HANA-gegevensbestanden die zich op meerdere NFS-shares bevinden. Lees de volgende artikelen voor meer informatie over het stripen van HANA-gegevensvolumes:
- De beheerdershandleiding van HANA
- Blog over SAP HANA - Gegevensvolumes partitioneren
- SAP-notitie #2400005
- SAP-notitie #2700123
| Tekengrootte | Doorvoerstandaard | Doorvoer Premium | Doorvoer Ultra |
|---|---|---|---|
| 1 TB | 16 MB per seconde | 64 MB per seconde | 128 MB per seconde |
| 2 TB | 32 MB per seconde | 128 MB per seconde | 256 MB per seconde |
| 4 TB | 64 MB per seconde | 256 MB per seconde | 512 MB per seconde |
| 10 TB | 160 MB per seconde | 640 MB per seconde | 1.280 MB per seconde |
| 15 TB | 240 MB per seconde | 960 MB per seconde | 1400 MB per seconde1 |
| 20 TB | 320 MB per seconde | 1.280 MB per seconde | 1400 MB per seconde1 |
| 40 TB | 640 MB per seconde | 1400 MB per seconde1 | 1400 MB per seconde1 |
1: doorvoerlimieten voor schrijven of één sessie lezen (in het geval NFS-koppelingsoptie nconnect niet wordt gebruikt)
Het is belangrijk om te begrijpen dat de gegevens naar dezelfdeHD's in de back-end van de opslag worden geschreven. Het prestatiequotum van de capaciteitspool is gemaakt om de omgeving te kunnen beheren. De STORAGE-KPI's zijn gelijk aan alle HANA-databasegrootten. In bijna alle gevallen weerspiegelt deze veronderstelling niet de realiteit en de verwachtingen van de klant. De grootte van HANA-systemen betekent niet noodzakelijkerwijs dat een klein systeem een lage opslagdoorvoer vereist. Voor een groot systeem is een hoge opslagdoorvoer vereist. Maar over het algemeen kunnen we hogere doorvoervereisten verwachten voor grotere HANA-database-exemplaren. Als gevolg van de grootteregels van SAP voor de onderliggende hardware, zoals grotere HANA-exemplaren, bieden ook meer CPU-resources en een hogere parallelle uitvoering in taken, zoals het laden van gegevens nadat een exemplaar opnieuw is opgestart. Als gevolg hiervan moeten de volumegrootten worden aangenomen aan de verwachtingen en vereisten van de klant. En niet alleen aangestuurd door pure capaciteitsvereisten.
Wanneer u de infrastructuur voor SAP in Azure ontwerpt, moet u rekening houden met enkele minimale vereisten voor opslagdoorvoer (voor productiesystemen) door SAP. Deze vereisten worden omgezet in minimale doorvoerkenmerken van:
| Volumetype en I/O-type | Minimale KPI die door SAP wordt gevraagd | Premium-serviceniveau | Ultraserviceniveau |
|---|---|---|---|
| Logboekvolume schrijven | 250 MB/sec | 4 TB | 2 TB |
| Gegevensvolume schrijven | 250 MB/sec | 4 TB | 2 TB |
| Gegevensvolume gelezen | 400 MB per seconde | 6,3 TB | 3,2 TB |
Omdat alle drie de KPI's worden gevraagd, moet het /hana/gegevensvolume worden aangepast aan de grotere capaciteit om te voldoen aan de minimale leesvereisten. Als u handmatige QoS-capaciteitspools gebruikt, kan de grootte en doorvoer van de volumes onafhankelijk worden gedefinieerd. Omdat zowel de capaciteit als de doorvoer worden opgehaald uit dezelfde capaciteitspool, moet het serviceniveau en de grootte van de pool groot genoeg zijn om de totale prestaties te leveren (zie hier het voorbeeld)
Voor HANA-systemen die geen hoge bandbreedte vereisen, kan de doorvoer van het Azure NetApp Files-volume worden verlaagd door een kleinere volumegrootte of door handmatig QoS te gebruiken door de doorvoer rechtstreeks aan te passen. En als een HANA-systeem meer doorvoer vereist, kan het volume worden aangepast door het formaat van de capaciteit online te wijzigen. Er zijn geen KPI's gedefinieerd voor back-upvolumes. De doorvoer van het back-upvolume is echter essentieel voor een goed presterende omgeving. Logboek- en gegevensvolumeprestaties moeten zijn ontworpen volgens de verwachtingen van de klant.
Belangrijk
Onafhankelijk van de capaciteit die u implementeert op één NFS-volume, wordt verwacht dat de doorvoer in één sessie de bandbreedte van 1,2-1,4 GB per seconde bereikt die door een consument wordt gebruikt. Dit heeft te maken met de onderliggende architectuur van de Azure NetApp Files-aanbieding en gerelateerde Linux-sessielimieten rond NFS. De prestatie- en doorvoernummers zoals beschreven in het artikel Prestatiebenchmark-testresultaten voor Azure NetApp Files zijn uitgevoerd op één gedeeld NFS-volume met meerdere client-VM's en als gevolg hiervan met meerdere sessies. Dit scenario verschilt van het scenario dat we meten in SAP, waarbij we de doorvoer van één VIRTUELE machine meten ten opzichte van een NFS-volume dat wordt gehost in Azure NetApp Files.
Om te voldoen aan de minimale SAP-doorvoervereisten voor gegevens en logboeken, en volgens de richtlijnen voor /hana/gedeeld, zien de aanbevolen grootten er als volgt uit:
| Volume | Tekengrootte Premium Storage-laag |
Tekengrootte Ultra Storage-laag |
Ondersteund NFS-protocol |
|---|---|---|---|
| /hana/log/ | 4 TiB | 2 TiB | v4.1 |
| /hana/data | 6.3 TiB | 3.2 TiB | v4.1 |
| /hana/shared scale-up | Min(1 TB, 1 x RAM) | Min(1 TB, 1 x RAM) | v3 of v4.1 |
| /hana/shared scale-out | 1 x RAM van werkknooppunt per vier werkknooppunten |
1 x RAM van werkknooppunt per vier werkknooppunten |
v3 of v4.1 |
| /hana/logbackup | 3 x RAM | 3 x RAM | v3 of v4.1 |
| /hana/back-up | 2 x RAM | 2 x RAM | v3 of v4.1 |
Voor alle volumes wordt NFS v4.1 ten zeerste aanbevolen.
Bekijk zorgvuldig de overwegingen voor het aanpassen van de grootte /hana/gedeeld, zoals de juiste grootte /hana/gedeeld volume bijdraagt aan de stabiliteit van het systeem.
De grootten voor de back-upvolumes zijn schattingen. Er moeten exacte vereisten worden gedefinieerd op basis van workload- en bewerkingsprocessen. Voor back-ups kunt u veel volumes voor verschillende SAP HANA-exemplaren samenvoegen tot één (of twee) grotere volumes, die een lager serviceniveau van Azure NetApp Files kunnen hebben.
Notitie
De Azure NetApp Files, aanbevelingen voor het aanpassen van de grootte die in dit document worden vermeld, zijn gericht op de minimale vereisten die SAP naar hun infrastructuurproviders uitdrukt. In echte klantimplementaties en workloadscenario's is dat mogelijk niet voldoende. Gebruik deze aanbevelingen als uitgangspunt en pas deze aan op basis van de vereisten van uw specifieke workload.
Daarom kunt u overwegen om vergelijkbare doorvoer te implementeren voor de Azure NetApp Files-volumes zoals vermeld voor Ultra Disk Storage al. Overweeg ook de grootten voor de grootten die worden vermeld voor de volumes voor de verschillende VM-SKU's, zoals gedaan in de Ultra-schijftabellen al.
Tip
U kunt De grootte van Azure NetApp Files-volumes dynamisch wijzigen zonder dat de volumes nodig zijn unmount , de virtuele machines stoppen of SAP HANA stoppen. Dit maakt flexibiliteit mogelijk om te voldoen aan de verwachte en onvoorziene doorvoervereisten van uw toepassing.
Documentatie over het implementeren van een sap HANA-uitschaalconfiguratie met stand-byknooppunt met behulp van NFS v4.1-volumes op basis van Azure NetApp Files wordt gepubliceerd in sap HANA scale-out met stand-byknooppunt op Virtuele Azure-machines met Azure NetApp Files op SUSE Linux Enterprise Server.
Linux-kernelinstellingen
Als u SAP HANA in Azure NetApp Files wilt implementeren, moeten linux-kernelinstellingen worden geïmplementeerd volgens SAP-opmerking 3024346.
Voor systemen met hoge beschikbaarheid (HA) met pacemaker en Azure Load Balancer moeten de volgende instellingen worden geïmplementeerd in bestand /etc/sysctl.d/91-NetApp-HANA.conf
net.core.rmem_max = 16777216
net.core.wmem_max = 16777216
net.ipv4.tcp_rmem = 4096 131072 16777216
net.ipv4.tcp_wmem = 4096 16384 16777216
net.core.netdev_max_backlog = 300000
net.ipv4.tcp_slow_start_after_idle=0
net.ipv4.tcp_no_metrics_save = 1
net.ipv4.tcp_moderate_rcvbuf = 1
net.ipv4.tcp_window_scaling = 1
net.ipv4.tcp_timestamps = 0
net.ipv4.tcp_sack = 1
Systemen die worden uitgevoerd zonder pacemaker en Azure Load Balancer moeten deze instellingen implementeren in /etc/sysctl.d/91-NetApp-HANA.conf
net.core.rmem_max = 16777216
net.core.wmem_max = 16777216
net.ipv4.tcp_rmem = 4096 131072 16777216
net.ipv4.tcp_wmem = 4096 16384 16777216
net.core.netdev_max_backlog = 300000
net.ipv4.tcp_slow_start_after_idle=0
net.ipv4.tcp_no_metrics_save = 1
net.ipv4.tcp_moderate_rcvbuf = 1
net.ipv4.tcp_window_scaling = 1
net.ipv4.tcp_timestamps = 1
net.ipv4.tcp_sack = 1
Implementatie met zonegebonden nabijheid
Als u een zonegebonden nabijheid van uw NFS-volumes en VM's wilt krijgen, kunt u de instructies volgen zoals beschreven in De plaatsing van het volume van de beschikbaarheidszone beheren voor Azure NetApp Files. Met deze methode bevinden de VM's en de NFS-volumes zich in dezelfde Azure-beschikbaarheidszone. In de meeste Azure-regio's moet dit type nabijheid voldoende zijn om een latentie van minder dan 1 milliseconden te bereiken voor de kleinere schrijfbewerkingen voor het opnieuw uitvoeren van logboeken voor SAP HANA. Voor deze methode is geen interactief werk met Microsoft vereist om VM's in een specifiek datacenter te plaatsen en vast te maken. Als gevolg hiervan bent u flexibel met het wijzigen van VM-grootten en -families binnen alle VM-typen en -families die worden aangeboden in de beschikbaarheidszone die u hebt geïmplementeerd. Zodat u flexibel kunt reageren op chanign-omstandigheden of sneller kunt overstappen op kostenefficiënte VM-grootten of -families. We raden deze methode aan voor niet-productiesystemen en productiesystemen die kunnen werken met latenties voor opnieuw logboeken die dichter bij 1 milliseconden liggen. De functionaliteit is momenteel beschikbaar als openbare preview.
Implementatie via azure NetApp Files-toepassingsvolumegroep voor SAP HANA (AVG)
Voor het implementeren van Azure NetApp Files-volumes met nabijheid tot uw VIRTUELE machine, is een nieuwe functionaliteit met de naam Azure NetApp Files-toepassingsvolumegroep voor SAP HANA (AVG) ontwikkeld. Er is een reeks artikelen die de functionaliteit documenteer. Het beste is om te beginnen met het artikel Understand Azure NetApp Files application volume group for SAP HANA. Terwijl u de artikelen leest, wordt het duidelijk dat het gebruik van AVG's ook betrekking heeft op het gebruik van azure-nabijheidsplaatsingsgroepen. Nabijheidsplaatsingsgroepen worden gebruikt door de nieuwe functionaliteit om verbinding te maken met de volumes die worden gemaakt. Om ervoor te zorgen dat de VM's gedurende de levensduur van het HANA-systeem niet van de Azure NetApp Files-volumes worden verplaatst, raden we u aan een combinatie van Avset/PPG te gebruiken voor elk van de zones die u implementeert. De volgorde van de implementatie ziet er als volgt uit:
- Met behulp van het formulier moet u een pincode van de lege AvSet aanvragen voor een reken-HW om ervoor te zorgen dat VM's niet worden verplaatst
- Een PPG toewijzen aan de beschikbaarheidsset en een VIRTUELE machine starten die is toegewezen aan deze beschikbaarheidsset
- Azure NetApp Files-toepassingsvolumegroep gebruiken voor SAP HANA-functionaliteit om uw HANA-volumes te implementeren
De configuratie van de nabijheidsplaatsingsgroep om AVG's op een optimale manier te gebruiken, ziet er als volgt uit:
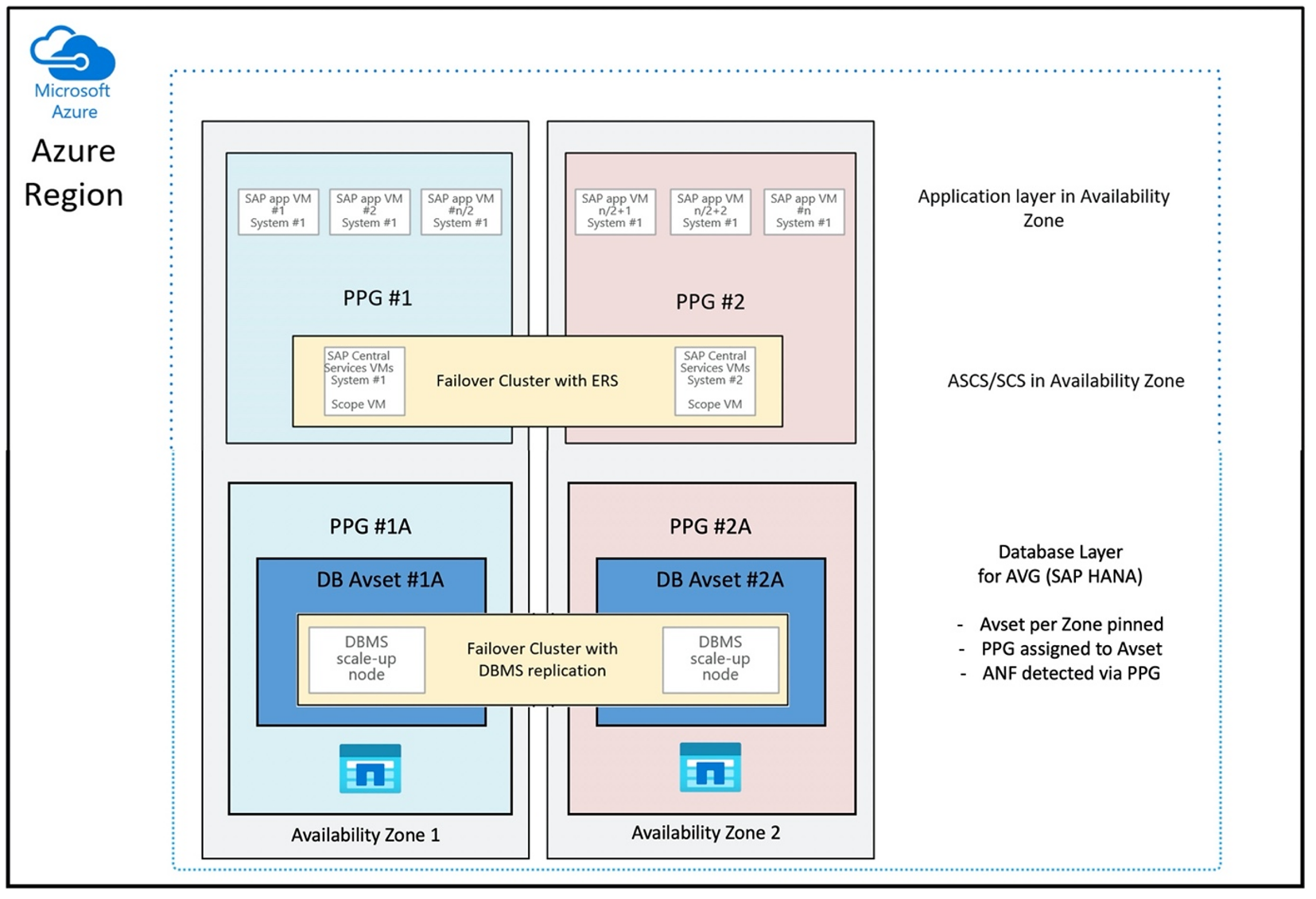
In het diagram ziet u dat u een Azure-nabijheidsplaatsingsgroep gaat gebruiken voor de DBMS-laag. Dus, dat het samen met AVG's kan worden gebruikt. U kunt het beste alleen de VM's opnemen waarop de HANA-exemplaren in de nabijheidsplaatsingsgroep worden uitgevoerd. De nabijheidsplaatsingsgroep is nodig, zelfs als er slechts één VM met één HANA-exemplaar wordt gebruikt, zodat de AVG de dichtstbijzijnde nabijheid van de Azure NetApp Files-hardware kan identificeren. En om het NFS-volume op Azure NetApp Files zo dicht mogelijk toe te wijzen aan de VM('s) die gebruikmaken van de NFS-volumes.
Met deze methode worden de meest optimale resultaten gegenereerd, omdat deze betrekking heeft op lage latentie. Niet alleen door de NFS-volumes en VM's zo dicht mogelijk bij elkaar te krijgen. Er wordt echter ook rekening gehouden met overwegingen voor het plaatsen van de gegevens en het opnieuw uitvoeren van logboekvolumes op verschillende controllers in de NetApp-back-end. Het nadeel is echter dat uw VM-implementatie is vastgemaakt aan één datacenter. Hierdoor verliest u flexibiliteit bij het wijzigen van VM-typen en -families. Als gevolg hiervan moet u deze methode beperken tot de systemen die absoluut een dergelijke lage opslaglatentie vereisen. Voor alle andere systemen moet u de implementatie proberen met een traditionele zonegebonden implementatie van de VIRTUELE machine en Azure NetApp Files. In de meeste gevallen is dit voldoende in termen van lage latentie. Dit zorgt ook voor eenvoudig onderhoud en beheer van de VM en Azure NetApp Files.
Beschikbaarheid
ANF-systeemupdates en -upgrades worden toegepast zonder dat dit van invloed is op de klantomgeving. De gedefinieerde SLA is 99,99%.
Volumes en IP-adressen en capaciteitspools
Met ANF is het belangrijk om te begrijpen hoe de onderliggende infrastructuur wordt gebouwd. Een capaciteitspool is slechts een constructie, die een capaciteits- en prestatiebudget en factureringseenheid biedt op basis van het serviceniveau van de capaciteitspool. Een capaciteitspool heeft geen fysieke relatie met de onderliggende infrastructuur. Wanneer u een volume op de service maakt, wordt er een opslageindpunt gemaakt. Er wordt één IP-adres toegewezen aan dit opslageindpunt om gegevenstoegang tot het volume te bieden. Als u meerdere volumes maakt, worden alle volumes verdeeld over de onderliggende bare-metal fleet, gekoppeld aan dit opslageindpunt. ANF heeft een logica waarmee klantworkloads automatisch worden gedistribueerd zodra de volumes of/en capaciteit van de geconfigureerde opslag een intern vooraf gedefinieerd niveau bereikt. U ziet dergelijke gevallen mogelijk omdat een nieuw opslageindpunt, met een nieuw IP-adres, automatisch wordt gemaakt voor toegang tot de volumes. De ANF-service biedt geen klantcontrole over deze distributielogica.
Logboekvolume en logboekback-upvolume
Het 'logboekvolume' (/hana/log) wordt gebruikt om het online opnieuw logboek te schrijven. Er zijn dus geopende bestanden op dit volume en het is niet logisch om een momentopname van dit volume te maken. Online opnieuw logboekbestanden worden gearchiveerd of een back-up gemaakt van het back-upvolume van het logboek zodra het online opnieuw logboekbestand vol is of een back-up van een opnieuw logboek wordt uitgevoerd. Om redelijke back-upprestaties te bieden, vereist het back-upvolume van het logboek een goede doorvoer. Om de opslagkosten te optimaliseren, is het zinvol om het logboekback-upvolume van meerdere HANA-exemplaren samen te voegen. Zodat meerdere HANA-exemplaren hetzelfde volume gebruiken en hun back-ups naar verschillende mappen schrijven. Als u een dergelijke samenvoeging gebruikt, krijgt u meer doorvoer omdat u het volume iets groter moet maken.
Hetzelfde geldt voor het volume waarop u volledige HANA-databaseback-ups schrijft.
Backup
Naast het streamen van back-ups en Azure Back-service voor het maken van back-ups van SAP HANA-databases, zoals beschreven in het artikel Backup guide for SAP HANA on Azure Virtual Machines, opent Azure NetApp Files de mogelijkheid om back-ups van momentopnamen op basis van opslag uit te voeren.
SAP HANA ondersteunt:
- Ondersteuning voor back-ups van momentopnamen op basis van opslag voor één containersysteem met SAP HANA 1.0 SPS7 en hoger
- Ondersteuning voor back-ups van momentopnamen op basis van opslag voor MDC-omgevingen (Multi Database Container) met één tenant met SAP HANA 2.0 SPS1 en hoger
- Back-upondersteuning voor momentopnamen op basis van opslag voor MDC-omgevingen (Multi Database Container) met meerdere tenants met SAP HANA 2.0 SPS4 en hoger
Het maken van back-ups van momentopnamen op basis van opslag is een eenvoudige procedure in vier stappen.
- Een momentopname van een HANA-database maken (intern): een activiteit die u of hulpprogramma's moet uitvoeren
- SAP HANA schrijft gegevens naar de gegevensbestanden om een consistente status in de opslag te maken- HANA voert deze stap uit als gevolg van het maken van een HANA-momentopname
- Maak een momentopname op het /hana/gegevensvolume in de opslag: een stap die u of hulpprogramma's moet uitvoeren. U hoeft geen momentopname uit te voeren op het volume /hana/log
- De momentopname van de HANA-database (interne) verwijderen en de normale bewerking hervatten: een stap die u of hulpprogramma's moeten uitvoeren
Waarschuwing
Het ontbreken van de laatste stap of het niet uitvoeren van de laatste stap heeft ernstige gevolgen voor de geheugenvraag van SAP HANA en kan leiden tot een halt van SAP HANA
BACKUP DATA FOR FULL SYSTEM CREATE SNAPSHOT COMMENT 'SNAPSHOT-2019-03-18:11:00';

az netappfiles snapshot create -g mygroup --account-name myaccname --pool-name mypoolname --volume-name myvolname --name mysnapname
BACKUP DATA FOR FULL SYSTEM CLOSE SNAPSHOT BACKUP_ID 47110815 SUCCESSFUL SNAPSHOT-2020-08-18:11:00';
Deze back-upprocedure voor momentopnamen kan op verschillende manieren worden beheerd met behulp van verschillende hulpprogramma's. Een voorbeeld is het Python-script 'ntaphana_azure.py' dat beschikbaar is op GitHub https://github.com/netapp/ntaphana . Dit is voorbeeldcode, geleverd 'as-is' zonder onderhoud of ondersteuning.
Let op
Een momentopname op zichzelf is geen beveiligde back-up, omdat deze zich op dezelfde fysieke opslag bevindt als het volume waarvan u zojuist een momentopname hebt gemaakt. Het is verplicht om ten minste één momentopname per dag te beveiligen op een andere locatie. Dit kan worden gedaan in dezelfde omgeving, in een externe Azure-regio of in Azure Blob Storage.
Beschikbare oplossingen voor toepassingsconsistente back-up op basis van opslagmomentopnamen:
- Microsoft What is Azure-toepassing Consistent Snapshot tool is een opdrachtregelprogramma waarmee gegevensbeveiliging voor databases van derden mogelijk is. Hiermee wordt alle indeling verwerkt die nodig is om de databases in een toepassingsconsistente status te plaatsen voordat u een momentopname van de opslag maakt. Nadat de momentopname van de opslag is gemaakt, retourneert het hulpprogramma de databases naar een operationele status. AzAcSnap ondersteunt back-ups op basis van momentopnamen voor HANA Large Instance en Azure NetApp Files. Lees het artikel Wat is Azure-toepassing hulpprogramma Voor consistente momentopnamen voor meer informatie
- Voor gebruikers van Commvault-back-upproducten is een andere optie Commvault IntelliSnap V.11.21 en hoger. Deze of latere versies van Commvault bieden ondersteuning voor momentopnamen van Azure NetApp Files. Het artikel Commvault IntelliSnap 11.21 biedt meer informatie.
Een back-up maken van de momentopname met behulp van Azure Blob Storage
Back-ups maken naar Azure Blob Storage is een rendabele en snelle methode om back-ups van op ANF gebaseerde HANA-databaseopslagmomentopnamen op te slaan. Als u de momentopnamen wilt opslaan in Azure Blob Storage, heeft het AzCopy-hulpprogramma de voorkeur. Download de nieuwste versie van dit hulpprogramma en installeer deze, bijvoorbeeld in de bin-map waarin het Python-script van GitHub is geïnstalleerd. Download het nieuwste AzCopy-hulpprogramma:
root # wget -O azcopy_v10.tar.gz https://aka.ms/downloadazcopy-v10-linux && tar -xf azcopy_v10.tar.gz --strip-components=1
Saving to: ‘azcopy_v10.tar.gz’
De meest geavanceerde functie is de synchronisatieoptie. Als u de optie SYNCHRONISEREN gebruikt, worden de bron en de doelmap gesynchroniseerd door azcopy. Het gebruik van de parameter --delete-destination is belangrijk. Zonder deze parameter verwijdert azcopy geen bestanden op de doelsite en wordt het ruimtegebruik aan de doelzijde groter. Maak een blok-blobcontainer in uw Azure-opslagaccount. Maak vervolgens de SAS-sleutel voor de blobcontainer en synchroniseer de map momentopname met de Azure Blob-container.
Als bijvoorbeeld een dagelijkse momentopname moet worden gesynchroniseerd met de Azure Blob-container om de gegevens te beveiligen. En slechts die momentopname moet worden bewaard, de onderstaande opdracht kan worden gebruikt.
root # > azcopy sync '/hana/data/SID/mnt00001/.snapshot' 'https://azacsnaptmytestblob01.blob.core.windows.net/abc?sv=2021-02-02&ss=bfqt&srt=sco&sp=rwdlacup&se=2021-02-04T08:25:26Z&st=2021-02-04T00:25:26Z&spr=https&sig=abcdefghijklmnopqrstuvwxyz' --recursive=true --delete-destination=true
Volgende stappen
Het artikel lezen: