Beschikbaarheid van SAP HANA in Azure-regio's
In dit artikel worden scenario's beschreven met betrekking tot de beschikbaarheid van SAP HANA in verschillende Azure-regio's. Vanwege de afstand tussen Azure-regio's omvat het instellen van sap HANA-beschikbaarheid in meerdere Azure-regio's speciale overwegingen.
Waarom implementeren in meerdere Azure-regio's
Azure-regio's worden vaak gescheiden door grote afstanden. Afhankelijk van de geopolitieke regio kan de afstand tussen Azure-regio's honderden kilometers of zelfs enkele duizenden mijlen zijn, zoals in de Verenigde Staten. Vanwege de afstand ondervindt netwerkverkeer tussen assets die zijn geïmplementeerd in twee verschillende Azure-regio's een aanzienlijke latentie van het netwerkrondje. De latentie is aanzienlijk genoeg om synchrone gegevensuitwisseling tussen twee SAP HANA-exemplaren onder typische SAP-workloads uit te sluiten.
Aan de andere kant hebben organisaties vaak een afstandsvereiste tussen de locatie van het primaire datacenter en een secundair datacenter. Een afstandsvereiste helpt beschikbaarheid te bieden als er zich een natuurramp voordoet op een bredere geografische locatie. Voorbeelden zijn de orkanen die in september en oktober 2017 het Caribisch gebied en Florida raken. Uw organisatie heeft mogelijk ten minste een minimale vereiste voor afstand. Voor de meeste Azure-klanten moet u een minimale afstandsdefinitie ontwerpen voor beschikbaarheid in Azure-regio's. Omdat de afstand tussen twee Azure-regio's te groot is om de synchrone replicatiemodus van HANA te gebruiken, kunnen RTO- en RPO-vereisten u dwingen om beschikbaarheidsconfiguraties in één regio te implementeren en vervolgens aanvullende implementaties in een tweede regio aan te vullen.
Een ander aspect dat u in dit scenario kunt overwegen, is failover en clientomleiding. De veronderstelling is dat een failover tussen SAP HANA-exemplaren in twee verschillende Azure-regio's altijd een handmatige failover is. Omdat de replicatiemodus van SAP HANA-systeemreplicatie is ingesteld op asynchroon, is er een potentieel dat gegevens die zijn doorgevoerd in het primaire HANA-exemplaar nog niet naar het secundaire HANA-exemplaar zijn gebracht. Daarom is automatische failover geen optie voor configuraties waarbij de replicatie asynchroon is. Zelfs met handmatig beheerde failover moet u, net als in een failover-oefening, maatregelen nemen om ervoor te zorgen dat alle vastgelegde gegevens aan de primaire zijde deze naar het secundaire exemplaar hebben gemaakt voordat u handmatig naar de andere Azure-regio gaat.
Azure Virtual Network maakt gebruik van een ander IP-adresbereik. De IP-adressen worden geïmplementeerd in de tweede Azure-regio. U moet dus de SAP HANA-clientconfiguratie wijzigen of bij voorkeur stappen maken om de naamomzetting te wijzigen. Op deze manier worden de clients omgeleid naar het IP-adres van de server van de nieuwe secundaire site. Zie het SAP-artikel Clientverbindingsherstel na overname voor meer informatie.
Eenvoudige beschikbaarheid tussen twee Azure-regio's
U kunt ervoor kiezen om geen beschikbaarheidsconfiguratie in één regio in te stellen, maar u hebt nog steeds de vraag om de workload te laten uitvoeren als er zich een noodgeval voordoet. Typische gevallen voor dergelijke scenario's zijn niet-productiesystemen. Hoewel het systeem een halve dag of zelfs een dag uitvalt, kunt u niet toestaan dat het systeem 48 uur of langer niet beschikbaar is. Als u de installatie goedkoper wilt maken, voert u een ander systeem uit dat nog minder belangrijk is in de virtuele machine. Het andere systeem functioneert als een bestemming. U kunt de VM in de secundaire regio ook kleiner maken en ervoor kiezen om de gegevens niet vooraf te laden. Omdat de failover handmatig is en veel meer stappen omvat om een failover uit te voeren voor de volledige toepassingsstack, is de extra tijd om de VM af te sluiten, de grootte ervan te wijzigen en vervolgens de VIRTUELE machine opnieuw op te starten acceptabel.
Als u het scenario gebruikt voor het delen van het DR-doel met een QA-systeem in één virtuele machine, moet u rekening houden met deze overwegingen:
- Er zijn twee bewerkingsmodi met delta_datashipping en logreplay, die beschikbaar zijn voor een dergelijk scenario
- Beide bewerkingsmodi hebben verschillende geheugenvereisten zonder gegevens vooraf te laden
- Delta_datashipping mogelijk drastisch minder geheugen nodig heeft zonder de optie voor vooraf laden dan logreplay zou kunnen vereisen. Zie hoofdstuk 4.3 van het SAP-document Systeemreplicatie uitvoeren voor SAP HANA
- De geheugenvereiste van de logreplay-bewerkingsmodus zonder vooraf laden is niet deterministisch en is afhankelijk van de columnstore-structuren die zijn geladen. In extreme gevallen hebt u mogelijk 50% van het geheugen van het primaire exemplaar nodig. Het geheugen voor de logreplay-bewerkingsmodus is onafhankelijk van of u ervoor kiest om de vooraf geladen gegevens in te stellen.

Notitie
In deze configuratie kunt u geen RPO=0 opgeven omdat de replicatiemodus van uw HANA-systeem asynchroon is. Als u een RPO=0 moet opgeven, is deze configuratie niet de gewenste configuratie.
Een kleine wijziging die u in de configuratie kunt aanbrengen, kan het zijn dat u gegevens configureert als vooraf laden. Gezien de handmatige aard van failover en het feit dat toepassingslagen ook naar de tweede regio moeten worden verplaatst, is het mogelijk niet zinvol om gegevens vooraf te laden.
Beschikbaarheid combineren binnen één regio en tussen regio's
Een combinatie van beschikbaarheid binnen en tussen regio's kan worden aangestuurd door deze factoren:
- Een vereiste van RPO=0 binnen een Azure-regio.
- De organisatie is niet bereid om wereldwijde activiteiten te laten beïnvloeden door een grote natuurramp die van invloed is op een grotere regio. Dit was het geval voor enkele orkanen die de afgelopen jaren het Caribisch gebied raakten.
- Voorschriften die afstanden eisen tussen primaire en secundaire sites die duidelijk verder gaan dan wat Azure-beschikbaarheidszones kunnen bieden.
In deze gevallen kunt u instellen wat SAP een SAP HANA-replicatieconfiguratie met meerdere lagen aanroept met behulp van HANA-systeemreplicatie. De architectuur ziet er als volgt uit:
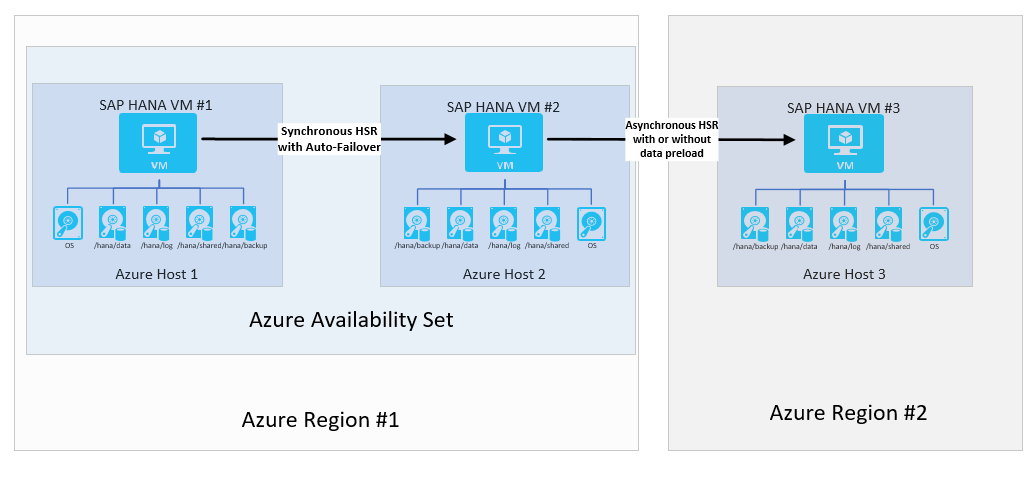
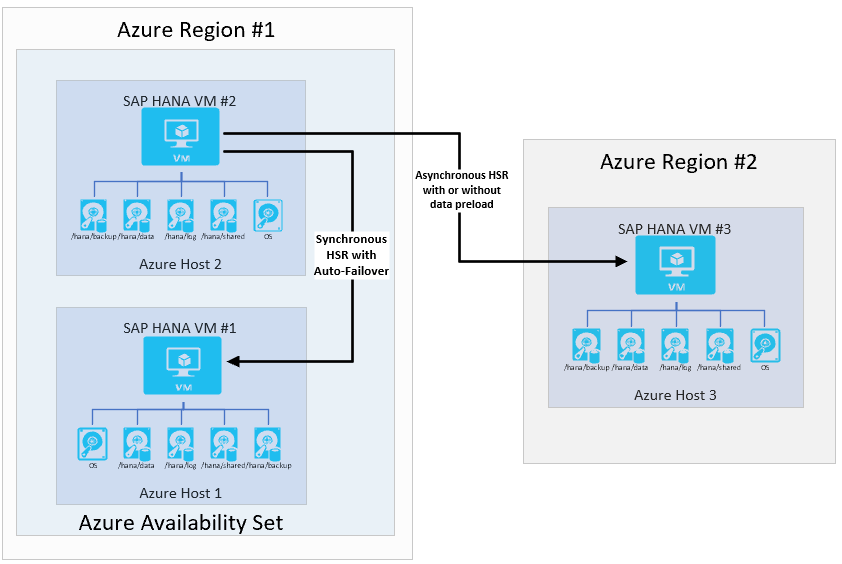
SAP heeft multi-doelsysteemreplicatie geïntroduceerd met HANA 2.0 SPS3. Replicatie van meerdere doelsystemen biedt enkele voordelen in updatescenario's. De DR-site (regio 2) wordt bijvoorbeeld niet beïnvloed wanneer de secundaire ha-site niet beschikbaar is voor onderhoud of updates. Meer informatie over HANA-systeemreplicatie met meerdere doelen vindt u in de SAP Help-portal. Mogelijke architectuur met replicatie met meerdere doelen ziet er als volgt uit:
Als de organisatie vereisten heeft voor gereedheid voor hoge beschikbaarheid in de tweede (DR) Azure-regio, ziet de architectuur er als volgt uit:
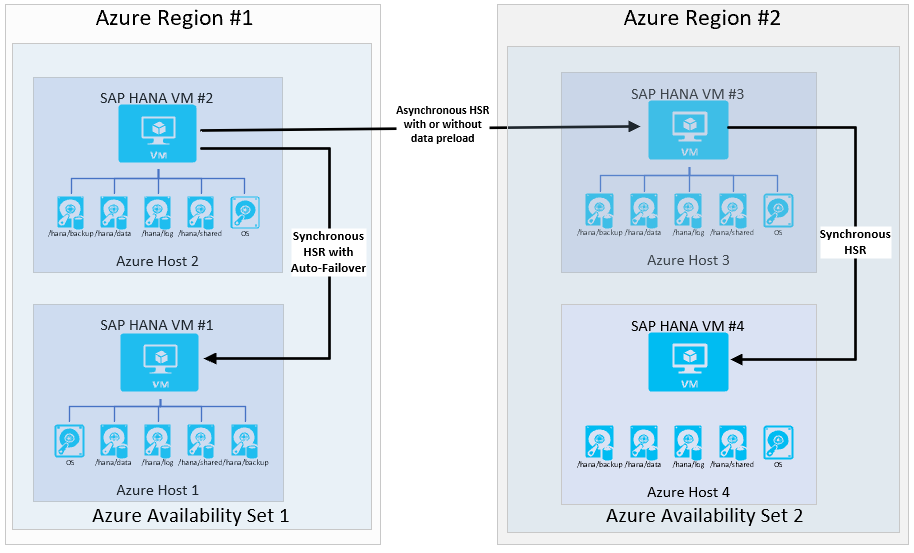
Als u logreplay als bewerkingsmodus gebruikt, biedt deze configuratie een RPO=0, met lage RTO, binnen de primaire regio. De configuratie biedt ook fatsoenlijke RPO als er een overstap naar de tweede regio is betrokken. De RTO-tijden in de tweede regio zijn afhankelijk van of gegevens vooraf worden geladen. Veel klanten gebruiken de VIRTUELE machine in de secundaire regio om een testsysteem uit te voeren. In dat geval kunnen de gegevens niet vooraf worden geladen.
Belangrijk
De bewerkingsmodi tussen de verschillende lagen moeten homogeen zijn. U kunt logreplay niet gebruiken als bewerkingsmodus tussen laag 1 en laag 2 en delta_datashipping om laag 3 op te geven. U kunt alleen de ene of de andere bewerkingsmodus kiezen die consistent moet zijn voor alle lagen. Aangezien delta_datashipping niet geschikt is om u een RPO=0 te geven, blijft de enige redelijke werkingsmodus voor een dergelijke configuratie met meerdere lagen logreplay. Zie het SAP-artikel Bewerkingsmodi voor SAP HANA-systeemreplicatie voor meer informatie over bewerkingsmodi en enkele beperkingen.
Volgende stappen
Zie voor stapsgewijze instructies voor het instellen van deze configuraties in Azure: