Notitie
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen u aan te melden of de directory te wijzigen.
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen de mappen te wijzigen.
Testen helpt ervoor te zorgen dat code naar verwachting wordt uitgevoerd, maar de tijd en moeite om tests te bouwen, kost tijd bij andere taken, zoals het ontwikkelen van functies. Met deze kosten is het belangrijk om de maximale waarde te extraheren uit het testen. In dit artikel worden devOps-testprincipes besproken, waarbij u zich richt op de waarde van eenheidstests en een shift-left-teststrategie.
Toegewijde testers schreven vroeger de meeste tests, en veel productontwikkelaars leerden destijds niet hoe ze eenheidstests moesten schrijven. Het schrijven van tests kan te moeilijk lijken of te veel werk vinden. Er kan scepsis zijn over of een eenheidsteststrategie werkt, slechte ervaringen met slecht geschreven eenheidstests of vrees dat eenheidstests functionele tests vervangen.

Als u een DevOps-teststrategie wilt implementeren, moet u pragmatisch zijn en zich richten op het opbouwen van momentum. Hoewel u kunt aandringen op eenheidstests voor nieuwe code of bestaande code die op een schone manier kunnen worden geherstructureerd, kan het zinvol zijn voor een verouderde codebasis om enige afhankelijkheid toe te staan. Als belangrijke onderdelen van de productcode SQL gebruiken, kunnen eenheidstests afhankelijk zijn van de SQL-resourceprovider in plaats van het simuleren van die laag. Dit kan een kortetermijnbenadering voor de voortgang zijn.
Naarmate DevOps-organisaties volwassen worden, wordt het voor leidinggevenden eenvoudiger om processen te verbeteren. Hoewel er mogelijk enige weerstand is tegen verandering, waarderen Agile-organisaties veranderingen die duidelijk dividend opleveren. Het moet gemakkelijk zijn om de visie van snellere testuitvoeringen met minder fouten te verkopen, omdat het meer tijd betekent om te investeren in het genereren van nieuwe waarde via functieontwikkeling.
DevOps-testtaxonomie
Het definiëren van een testtaxonomie is een belangrijk aspect van het DevOps-testproces. Een DevOps-testtaxonomie classificeert afzonderlijke tests op basis van hun afhankelijkheden en de tijd die nodig is om uit te voeren. Ontwikkelaars moeten de juiste typen tests begrijpen die in verschillende scenario's moeten worden gebruikt en die verschillende onderdelen van het proces testen. De meeste organisaties categoriseren tests op vier niveaus:
- L0 - en L1-tests zijn eenheidstests of tests die afhankelijk zijn van code in de assembly onder test en niets anders. L0 is een brede klasse van snelle, in-memory unittests.
- L2 zijn functionele tests waarvoor de assembly kan zijn vereist plus andere afhankelijkheden, zoals SQL of het bestandssysteem.
- Functionele L3-tests worden uitgevoerd op testbare service-implementaties. Deze testcategorie vereist een service-implementatie, maar kan stubs gebruiken voor belangrijke serviceafhankelijkheden.
- L4-tests zijn een beperkte klasse van integratietests die worden uitgevoerd op basis van productie. L4-tests vereisen een volledige productimplementatie.
Hoewel het ideaal zou zijn dat alle tests altijd draaien, is dat niet haalbaar. Teams kunnen selecteren waar in het DevOps-proces elke test moet worden uitgevoerd en shift-left - of shift-right-strategieën gebruiken om verschillende testtypen eerder of later in het proces te verplaatsen.
De verwachting kan bijvoorbeeld zijn dat ontwikkelaars altijd L2-tests doorlopen voordat ze worden doorgevoerd, een pull-aanvraag mislukt als de L3-testuitvoering mislukt en de implementatie mogelijk wordt geblokkeerd als L4-tests mislukken. De specifieke regels kunnen variëren van organisatie tot organisatie, maar het afdwingen van de verwachtingen voor alle teams binnen een organisatie verplaatst iedereen naar dezelfde kwaliteitsvisiedoelstellingen.
Richtlijnen voor eenheidstests
Stel strikte richtlijnen in voor L0- en L1-eenheidstests. Deze tests moeten zeer snel en betrouwbaar zijn. De gemiddelde uitvoeringstijd per L0-test in een assembly moet bijvoorbeeld kleiner zijn dan 60 milliseconden. De gemiddelde uitvoeringstijd per L1-test in een assembly moet kleiner zijn dan 400 milliseconden. Geen test op dit niveau moet langer zijn dan 2 seconden.
Eén Microsoft-team voert in minder dan zes minuten meer dan 60.000 eenheidstests parallel uit. Hun doel is om deze tijd te verminderen tot minder dan een minuut. Het team houdt de uitvoeringstijd van de eenheidstest bij met hulpprogramma's zoals de volgende grafiek en registreert fouten in tests die de toegestane tijd overschrijden.
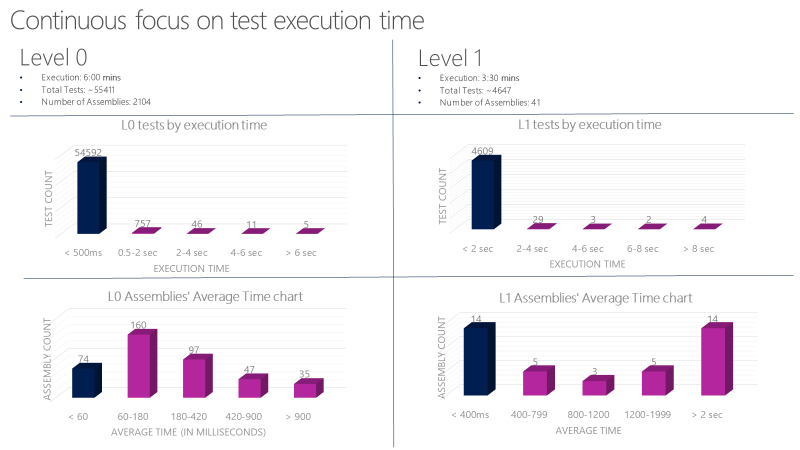
Richtlijnen voor functionele tests
Functionele tests moeten onafhankelijk zijn. Het belangrijkste concept voor L2-tests is isolatie. Correct geïsoleerde tests kunnen betrouwbaar in elke volgorde worden uitgevoerd, omdat ze volledige controle hebben over de omgeving waarin ze worden uitgevoerd. De status moet aan het begin van de test bekend zijn. Als de ene test gegevens heeft gemaakt en deze in de database heeft achtergelaten, kan de uitvoering van een andere test die afhankelijk is van een andere databasestatus, beschadigd raken.
Verouderde tests die een gebruikersidentiteit nodig hebben, kunnen externe verificatieproviders hebben aangeroepen om de identiteit op te halen. In deze praktijk worden verschillende uitdagingen geïntroduceerd. De externe afhankelijkheid kan onbetrouwbaar zijn of tijdelijk niet beschikbaar zijn, waardoor de test wordt onderbroken. Deze praktijk schendt ook het testisolatieprincipe, omdat een test de status van een identiteit kan wijzigen, zoals machtigingen, wat resulteert in een onverwachte standaardstatus voor andere tests. Overweeg deze problemen te voorkomen door te investeren in identiteitsondersteuning binnen het testframework.
DevOps-testprincipes
Om een testportfolio over te brengen naar moderne DevOps-processen, kunt u een kwaliteitsvisie formuleren. Teams moet voldoen aan de volgende testprincipes bij het definiëren en implementeren van een DevOps-teststrategie.
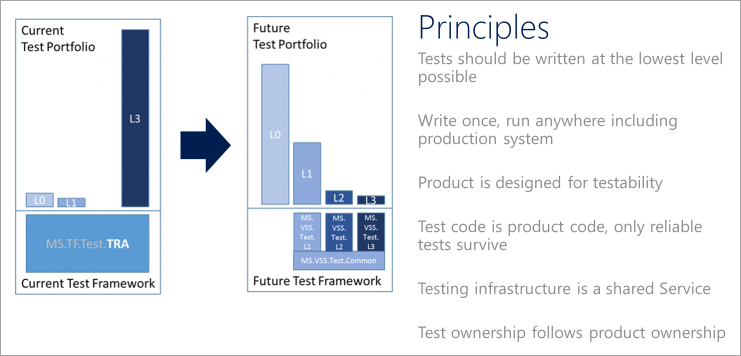
Naar links gaan om eerder te testen
Het kan lang duren voordat tests worden uitgevoerd. Naarmate projecten worden geschaald, groeien testnummers en typen aanzienlijk. Wanneer testsuites uren of dagen in beslag nemen, worden ze steeds verder uitgesteld totdat ze op het laatste moment worden uitgevoerd. De voordelen van de codekwaliteit van testen worden pas lang nadat de code is doorgevoerd, gerealiseerd.
Langdurige tests kunnen ook fouten opleveren die tijdrovend zijn om te onderzoeken. Teams kunnen een tolerantie voor fouten bouwen, met name vroeg in sprints. Deze tolerantie ondermijnen de waarde van testen als inzicht in codebasiskwaliteit. Langdurige, last-minute tests voegen ook onvoorspelbaarheid toe aan de verwachtingen van het einde van de sprint, omdat een onbekend bedrag aan technische schulden moet worden betaald om de code te kunnen verzenden.
Het doel van het verplaatsen van testen naar links is om de kwaliteit upstream te verplaatsen door eerder in de pijplijn testtaken uit te voeren. Door een combinatie van test- en procesverbeteringen vermindert het verschuiven naar links zowel de tijd die nodig is om tests uit te voeren als de impact van fouten later in de cyclus. Als u naar links schuift, zorgt u ervoor dat de meeste tests zijn voltooid voordat een wijziging wordt samengevoegd in de hoofdvertakking.
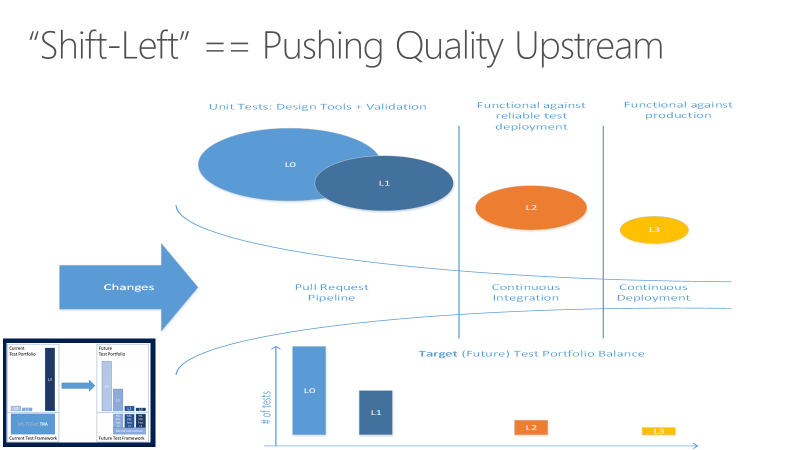
Naast het verschuiven van bepaalde testverantwoordelijkheden om de codekwaliteit te verbeteren, kunnen teams andere testaspecten naar rechts of later in de DevOps-cyclus verplaatsen om het eindproduct te verbeteren. Zie Shift naar rechts om te testen in productie voor meer informatie.
Schrijf tests op het laagst mogelijke niveau
Schrijf meer eenheidstests. Geef de voorkeur aan tests met zo min mogelijk externe afhankelijkheid en focus vooral op het uitvoeren van de meeste tests als onderdeel van de build. Overweeg een parallel buildsysteem waarmee eenheidstests voor een assembly kunnen worden uitgevoerd zodra de assembly en de bijbehorende tests worden verwijderd. Het is niet haalbaar om elk aspect van een service op dit niveau te testen, maar het principe is het gebruik van lichtere eenheidstests als ze dezelfde resultaten kunnen produceren als zwaardere functionele tests.
Streven naar testbetrouwbaarheid
Een onbetrouwbare test is organisatorisch duur om te onderhouden. Een dergelijke test werkt rechtstreeks tegen het doel van de engineeringefficiëntie door het moeilijk te maken om met vertrouwen wijzigingen aan te brengen. Ontwikkelaars moeten overal wijzigingen kunnen aanbrengen en snel vertrouwen krijgen dat er niets is verbroken. Handhaaf een hoog niveau van betrouwbaarheid. Ontmoedig het gebruik van UI-tests, omdat ze meestal onbetrouwbaar zijn.
Functionele tests schrijven die overal kunnen worden uitgevoerd
Tests kunnen gebruikmaken van gespecialiseerde integratiepunten die speciaal zijn ontworpen om testen mogelijk te maken. Een van de redenen voor deze praktijk is een gebrek aan testbaarheid in het product zelf. Helaas zijn tests zoals deze vaak afhankelijk van interne kennis en gebruiken implementatiedetails die niet van belang zijn vanuit het perspectief van een functionele test. Deze tests zijn beperkt tot omgevingen met de geheimen en configuratie die nodig zijn om de tests uit te voeren, waardoor productie-implementaties over het algemeen worden uitgesloten. Functionele tests mogen alleen de openbare API van het product gebruiken.
Producten ontwerpen voor testbaarheid
Organisaties in een ontwikkelend DevOps-proces bekijken wat het betekent om een kwaliteitsproduct op een cloudritme te leveren. Als u het evenwicht sterk verschuift ten gunste van eenheidstests ten opzichte van functionele tests, moeten teams ontwerp- en implementatiekeuzen maken die testbaarheid ondersteunen. Er zijn verschillende ideeën over wat goed ontworpen en goed geïmplementeerde code is voor testbaarheid, net zoals er verschillende coderingsstijlen zijn. Het principe is dat ontwerpen voor testbaarheid een belangrijk onderdeel van de discussie over ontwerp- en codekwaliteit moet worden.
Testcode behandelen als productcode
Expliciet aangeven dat testcode productcode is, maakt het duidelijk dat de kwaliteit van de testcode net zo belangrijk is voor verzending als die van productcode. Teams moeten testcode op dezelfde manier behandelen als productcode en hetzelfde zorgniveau toepassen op het ontwerp en de implementatie van tests en testframeworks. Deze inspanning is vergelijkbaar met het beheren van configuratie en infrastructuur als code. Om te zijn voltooid, moet een codebeoordeling rekening houden met de testcode en deze op dezelfde kwaliteitsbalk houden als de productcode.
Gedeelde testinfrastructuur gebruiken
Verlaag de drempel voor het gebruik van de testinfrastructuur om vertrouwde kwaliteitsindicatoren te genereren. Het testen weergeven als een gedeelde service voor het hele team. Bewaar eenheidstestcode naast productcode en bouw deze samen met het product. Tests die worden uitgevoerd als onderdeel van het buildproces, moeten ook worden uitgevoerd onder ontwikkelhulpprogramma's zoals Azure DevOps. Als tests in elke omgeving kunnen worden uitgevoerd vanuit lokale ontwikkeling via productie, hebben ze dezelfde betrouwbaarheid als de productcode.
Code-eigenaren verantwoordelijk maken voor het testen
Testcode moet zich naast de productcode in een opslagplaats bevinden. Als u code wilt testen op een onderdeelgrens, pusht u de verantwoordelijkheid voor het testen naar de persoon die de onderdeelcode schrijft. Vertrouw niet op anderen om het onderdeel te testen.
Casestudy: Shift links met eenheidstests
Een Microsoft-team heeft besloten om hun verouderde testsuites te vervangen door moderne DevOps-eenheidstests en een shift-left-proces. Het team heeft de voortgang bijgehouden in drieweekse sprints, zoals wordt weergegeven in de volgende grafiek. De grafiek omvat sprints 78-120, die 42 sprints gedurende 126 weken vertegenwoordigt, of ongeveer twee en een half jaar inspanning.
Het team begon met 27K legacy-tests in sprint 78 en bereikte nul legacy-tests bij S120. Een reeks L0- en L1-eenheidstests vervangt de meeste van de oude functionele tests. Nieuwe L2-tests vervangen enkele van de tests en veel van de oude tests zijn verwijderd.
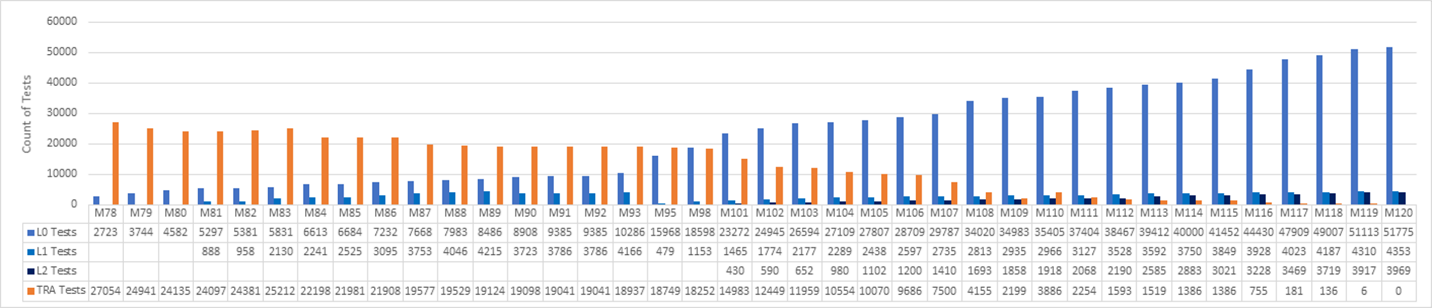
Tijdens een softwaretraject dat meer dan twee jaar in beslag neemt, is er veel te leren van het proces zelf. Over het algemeen was de inspanning om het testsysteem over twee jaar volledig opnieuw uit te proberen, een enorme investering. Niet elk functieteam heeft het werk tegelijkertijd gedaan. Veel teams in de hele organisatie hebben tijd geïnvesteerd in elke sprint en in sommige sprints was het het grootste deel van wat het team deed. Hoewel het moeilijk is om de kosten van de dienst te meten, was het een niet-onderhandelbare vereiste voor de kwaliteits- en prestatiedoelstellingen van het team.
Aan de slag
Aan het begin liet het team de oude functionele tests, TRA-tests genoemd, met rust. Het team wilde dat ontwikkelaars zich verdiepen in het idee van het schrijven van eenheidstests, met name voor nieuwe functies. De focus lag op het zo gemakkelijk mogelijk maken van L0- en L1-tests. Het team moest die mogelijkheid eerst ontwikkelen en momentum opbouwen.
In de voorgaande grafiek ziet u het aantal unittests vroeg beginnen toe te nemen, omdat het team het voordeel van het opstellen van unittests heeft gezien. Eenheidstests waren eenvoudiger te onderhouden, sneller uit te voeren en hadden minder fouten. Het was eenvoudig om ondersteuning te krijgen voor het uitvoeren van alle eenheidstests in de pull-aanvraagstroom.
Het team richtte zich niet op het schrijven van nieuwe L2-tests tot sprint 101. Ondertussen daalde het aantal TRA-tests van 27.000 tot 14.000 van Sprint 78 naar Sprint 101. Nieuwe eenheidstests hebben enkele TRA-tests vervangen, maar veel zijn gewoon verwijderd, op basis van teamanalyse van hun nut.
De TRA-tests sprongen van 2100 naar 3800 in sprint 110 omdat er meer tests zijn gedetecteerd in de bronstructuur en aan de grafiek zijn toegevoegd. Het bleek dat de tests altijd werden uitgevoerd, maar niet goed werden bijgehouden. Dit was geen crisis, maar het was belangrijk om eerlijk te zijn en waar nodig opnieuw te beoordelen.
Sneller
Zodra het team een ci-signaal (continue integratie) had dat zeer snel en betrouwbaar was, werd het een vertrouwde indicator voor productkwaliteit. In de volgende schermopname ziet u de pull-aanvraag en CI-pijplijn in actie en de tijd die nodig is om verschillende fasen te doorlopen.
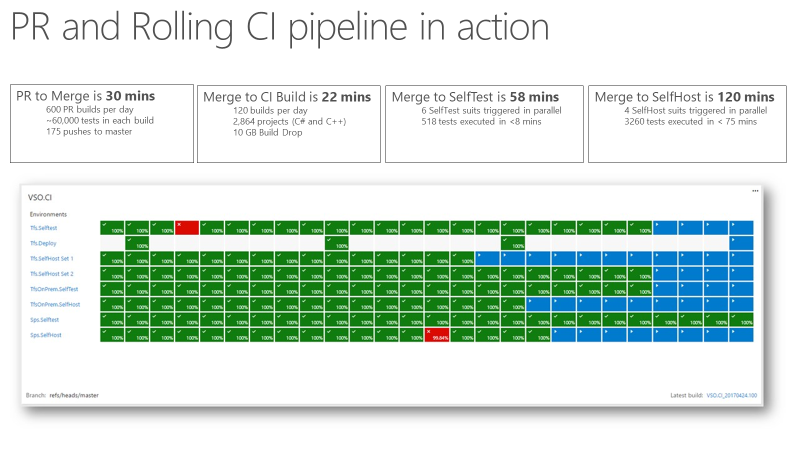
Het duurt ongeveer 30 minuten om van pull request naar samenvoegen te gaan, waaronder het uitvoeren van 60.000 eenheidstests. Het samenvoegen van code naar CI-build duurt ongeveer 22 minuten. Het eerste kwaliteitssignaal van CI, SelfTest, komt na ongeveer een uur. Vervolgens wordt het grootste deel van het product getest met de voorgestelde wijziging. Binnen twee uur van Merge naar SelfHost wordt het hele product getest en is de wijziging gereed om in productie te gaan.
Metrische gegevens gebruiken
Het team houdt een scorecard bij zoals in het volgende voorbeeld. Op een overzichtelijk niveau houdt de scorecard twee soorten metrics bij: Gezondheid en schuld, en snelheid.
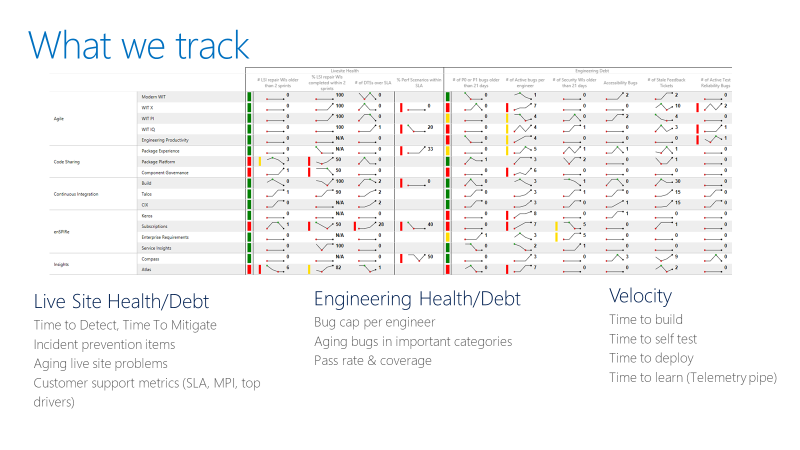
Voor de gezondheidsmetingen van live sites houdt het team de tijd bij om te detecteren, de tijd om in te perken, en hoeveel herstelpunten een team heeft. Een reparatie-item is werk dat door het team wordt geïdentificeerd in een live-site retrospectief om te voorkomen dat soortgelijke incidenten terugkeren. De scorecard houdt ook bij of teams de reparatie-items binnen een redelijk tijdsbestek sluiten.
Voor gezondheidsmetriek voor engineering volgt het team actieve bugs per ontwikkelaar. Als een team meer dan vijf bugs per ontwikkelaar heeft, moet het team prioriteit geven aan het oplossen van deze bugs voordat nieuwe functies worden ontwikkeld. Het team houdt ook verouderde bugs bij in speciale categorieën, zoals beveiliging.
Metrische meetwaarden voor engineeringsnelheid meten snelheid in verschillende onderdelen van de CI/CD-pijplijn (continue integratie en continue levering). Het algemene doel is om de snelheid van de DevOps-pijplijn te verhogen: beginnen met een idee, het ophalen van de code in productie en het ontvangen van gegevens van klanten.