Notitie
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen u aan te melden of de directory te wijzigen.
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen de mappen te wijzigen.
Aanbeveling
Deze inhoud is een fragment uit het eBook, Cloud Native .NET Applications for Azure ontwerpen, beschikbaar op .NET Docs of als een gratis downloadbare PDF die offline kan worden gelezen.

De favoriete mantra van softwareconsultants is om "Dat hangt ervan af" op elke gestelde vraag te antwoorden. Het is niet omdat software consultants graag geen positie innemen. Het komt omdat er niemand echt antwoord heeft op vragen in software. Er is geen absoluut recht en fout, maar eerder een evenwicht tussen tegengestelden.
Neem bijvoorbeeld de twee hoofdscholen voor het ontwikkelen van webtoepassingen: Toepassingen met één pagina (SPA's) versus toepassingen aan de serverzijde. Aan de ene kant is de gebruikerservaring meestal beter met SPA's en kan de hoeveelheid verkeer naar de webserver worden geminimaliseerd, waardoor het mogelijk is om ze te hosten op iets eenvoudigs als statische hosting. Aan de andere kant zijn SPA's meestal langzamer te ontwikkelen en moeilijker te testen. Welke is de juiste keuze? Het hangt af van je situatie.
Cloudeigen toepassingen zijn niet immuun voor dezelfde dichotomie. Ze hebben duidelijke voordelen met betrekking tot de snelheid van ontwikkeling, stabiliteit en schaalbaarheid, maar het beheer ervan kan een stuk moeilijker zijn.
Jaren geleden was het niet ongebruikelijk dat het proces van het verplaatsen van een toepassing van ontwikkeling naar productie een maand duurde, of zelfs nog meer. Bedrijven hebben software uitgebracht op een frequentie van 6 maanden of zelfs elk jaar. U hoeft niet verder te kijken dan Microsoft Windows om een idee te krijgen van de frequentie van releases die acceptabel waren voor de ooit groene dagen van Windows 10. Vijf jaar verstreken tussen Windows XP en Vista, nog eens drie tussen Vista en Windows 7.
Het is nu vrij goed vastgesteld dat het snel vrijgeven van software bedrijven die snel bewegen een enorm marktvoordeel biedt ten opzichte van hun langzamere concurrenten. Daarom zijn belangrijke updates voor Windows 10 nu ongeveer om de zes maanden.
De patronen en procedures die snellere, betrouwbaardere releases mogelijk maken om waarde te leveren aan het bedrijf, worden gezamenlijk DevOps genoemd. Ze bestaan uit een breed scala aan ideeën die betrekking hebben op de hele levenscyclus van softwareontwikkeling, van het opgeven van een toepassing tot het leveren en uitvoeren van die toepassing.
DevOps is ontstaan vóór microservices en het is waarschijnlijk dat de beweging naar kleinere, meer geschikt voor doelservices niet mogelijk zou zijn geweest zonder DevOps om het vrijgeven en gebruiken van niet slechts één, maar veel toepassingen in productie eenvoudiger te maken.
Afbeelding 10-1 : DevOps en microservices.
Door goede DevOps-praktijken is het mogelijk de voordelen van cloud-native toepassingen te realiseren zonder te verzanden onder een berg werk bij het daadwerkelijk bedienen van de toepassingen.
Er is geen gouden hamer als het gaat om DevOps. Niemand kan een complete en allesomvattende oplossing verkopen voor het vrijgeven en gebruiken van hoogwaardige toepassingen. Dit komt doordat elke toepassing heel anders is dan alle andere. Er zijn echter hulpprogramma's die DevOps een veel minder ontmoedigende propositie kunnen maken. Een van deze hulpprogramma's wordt Azure DevOps genoemd.
Azure DevOps
Azure DevOps heeft een lange pedigree. Het kan zijn oorsprong terugvoeren naar de tijd dat Team Foundation Server voor het eerst online ging, en de verschillende naamswijzigingen volgde: Visual Studio Online en Visual Studio Team Services. Door de jaren heen is het echter veel meer geworden dan zijn voorgangers.
Azure DevOps is onderverdeeld in vijf belangrijke onderdelen:

Afbeelding 10-2 - Azure DevOps.
Azure Repos - Broncodebeheer dat ondersteuning biedt voor het gerespecteerde Team Foundation Version Control (TFVC) en de favoriete Git. Pull-aanvragen bieden een manier om sociale codering mogelijk te maken door de discussie over wijzigingen te bevorderen terwijl ze worden aangebracht.
Azure Boards : biedt een hulpprogramma voor het bijhouden van problemen en werkitems waarmee gebruikers de werkstromen kunnen kiezen die het beste voor hen werken. Het wordt geleverd met een aantal vooraf geconfigureerde sjablonen, waaronder sjablonen ter ondersteuning van SCRUM- en Kanban-stijlen voor ontwikkeling.
Azure Pipelines : een build- en releasebeheersysteem dat een nauwe integratie met Azure ondersteunt. Builds kunnen worden uitgevoerd op verschillende platforms van Windows naar Linux naar macOS. Buildagents kunnen worden ingericht in de cloud of op locatie.
Azure-testplannen : er blijft geen QA-persoon achter met het testbeheer en de experimentele ondersteuning voor testen die wordt aangeboden door de functie Testplannen.
Azure Artifacts : een artefactfeed waarmee bedrijven hun eigen, interne versies van NuGet, npm en andere kunnen maken. Het fungeert als dubbel doel om te fungeren als een cache van upstream-pakketten als er een fout optreedt in een gecentraliseerde opslagplaats.
De organisatie-eenheid op het hoogste niveau in Azure DevOps wordt een project genoemd. Binnen elk project kunnen de verschillende onderdelen, zoals Azure Artifacts, worden ingeschakeld en uitgeschakeld. Elk van deze onderdelen biedt verschillende voordelen voor cloudtoepassingen. De drie handigste zijn opslagplaatsen, borden en pijplijnen. Als gebruikers hun broncode willen beheren in een andere opslagplaatsstack, zoals GitHub, maar nog steeds willen profiteren van Azure Pipelines en andere onderdelen, is dat perfect mogelijk.
Gelukkig hebben ontwikkelteams veel opties bij het selecteren van een opslagplaats. Een daarvan is GitHub.
GitHub Actions (GitHub-acties)
GitHub is opgericht in 2009 en is een veelgebruikte webopslagplaats voor het hosten van projecten, documentatie en code. Veel grote techbedrijven, zoals Apple, Amazon, Google en algemene bedrijven, maken gebruik van GitHub. GitHub maakt gebruik van het opensource-, gedistribueerd versiebeheersysteem met de naam Git als basis. Bovendien voegt het een eigen set functies toe, waaronder het bijhouden van defecten, functie- en pull-aanvragen, takenbeheer en wiki's voor elke codebasis.
Naarmate GitHub zich verder ontwikkelt, worden ook DevOps-functies toegevoegd. GitHub heeft bijvoorbeeld een eigen CI/CD-pijplijn (continue integratie/continue levering), genaamd GitHub Actions. GitHub Actions is een door de community aangedreven hulpprogramma voor werkstroomautomatisering. Hiermee kunnen DevOps-teams integreren met hun bestaande hulpprogramma's, nieuwe producten combineren en matchen, en aansluiten op hun softwarelevenscyclus, met inbegrip van bestaande CI/CD-partners.
GitHub heeft meer dan 40 miljoen gebruikers, waardoor het de grootste host van broncode ter wereld is. In oktober 2018 heeft Microsoft GitHub gekocht. Microsoft heeft toegezegd dat GitHub een open platform blijft dat elke ontwikkelaar kan aansluiten en uitbreiden. Het blijft opereren als een onafhankelijk bedrijf. GitHub biedt abonnementen voor enterprise-, team-, professionele en gratis accounts.
Bronbeheer
Het organiseren van de code voor een cloudeigen toepassing kan lastig zijn. In plaats van één gigantische toepassing bestaan de cloudeigen toepassingen meestal uit een web van kleinere toepassingen die met elkaar praten. Net als bij alle dingen in computing blijft de beste rangschikking van code een open vraag. Er zijn voorbeelden van succesvolle toepassingen die verschillende soorten indelingen gebruiken, maar twee varianten lijken de meest populair te zijn.
Voordat u aan de slag gaat met het werkelijke broncodebeheer zelf, is het waarschijnlijk de moeite waard om te bepalen hoeveel projecten geschikt zijn. Binnen één project is er ondersteuning voor meerdere opslagplaatsen en build-pijplijnen. Borden zijn iets ingewikkelder, maar ook daar kunnen de taken eenvoudig worden toegewezen aan meerdere teams binnen één project. Het is mogelijk om honderden, zelfs duizenden ontwikkelaars, uit één Azure DevOps-project te ondersteunen. Dit is waarschijnlijk de beste benadering, omdat het één plek biedt waar alle ontwikkelaars zich kunnen ontwikkelen en de verwarring verminderen bij het vinden van die ene toepassing wanneer ontwikkelaars niet zeker weten in welk project het zich bevindt.
Het splitsen van code voor microservices binnen het Azure DevOps-project kan iets lastiger zijn.
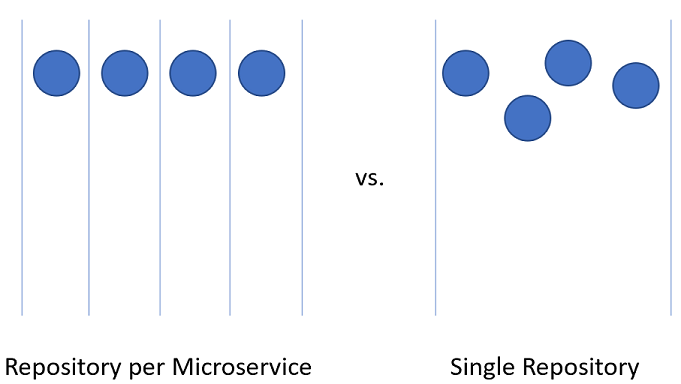
Afbeelding 10-3 - Één versus veel opslagplaatsen.
Opslagplaats per microservice
Op het eerste gezicht lijkt deze benadering de meest logische benadering voor het opsplitsen van de broncode voor microservices. Elke opslagplaats kan de code bevatten die nodig is om de ene microservice te bouwen. De voordelen van deze aanpak zijn direct zichtbaar:
- Instructies voor het bouwen en onderhouden van de toepassing kunnen worden toegevoegd aan een README-bestand in de hoofdmap van elke opslagplaats. Wanneer u door de opslagplaatsen bladert, kunt u deze instructies gemakkelijk vinden, waardoor de spin-uptijd voor ontwikkelaars wordt verminderd.
- Elke service bevindt zich op een logische locatie, gemakkelijk te vinden door de naam van de service te kennen.
- Builds kunnen eenvoudig worden ingesteld zodat ze alleen worden geactiveerd wanneer er een wijziging wordt aangebracht in de opslagplaats van de eigenaar.
- Het aantal wijzigingen dat in een opslagplaats binnenkomt, is beperkt tot het kleine aantal ontwikkelaars dat aan het project werkt.
- Beveiliging is eenvoudig in te stellen door de opslagplaatsen te beperken waartoe ontwikkelaars lees- en schrijfmachtigingen hebben.
- Instellingen op opslagplaatsniveau kunnen worden gewijzigd door het team dat eigenaar is, met een minimum aan discussie met anderen.
Een van de belangrijkste ideeën achter microservices is dat services moeten worden gescheiden van elkaar. Wanneer u Domain Driven Design gebruikt om de grenzen voor services te bepalen, fungeren de services als transactionele grenzen. Database-updates mogen niet meerdere services omvatten. Deze verzameling gerelateerde gegevens wordt een gebonden context genoemd. Dit idee wordt weerspiegeld door de isolatie van microservicegegevens in een database, gescheiden en autonoom van de rest van de services. Het is heel logisch om dit idee helemaal door te voeren naar de broncode.
Deze aanpak is echter niet zonder problemen. Een van de complexere ontwikkelingsproblemen van onze tijd is het beheren van afhankelijkheden. Houd rekening met het aantal bestanden waaruit de gemiddelde node_modules map bestaat. Een nieuwe installatie van iets als create-react-app zal waarschijnlijk duizenden pakketten meebrengen. De vraag hoe u deze afhankelijkheden beheert, is een moeilijke.
Als een afhankelijkheid wordt bijgewerkt, moeten downstreampakketten deze afhankelijkheid ook bijwerken. Helaas vereist dat ontwikkelwerk, waardoor de node_modules map uiteindelijk terechtkomt met meerdere versies van één pakket, waarvan elk een afhankelijkheid is van een ander pakket dat versiebeheer kent met een iets ander tempo. Welke versie van een afhankelijkheid moet worden gebruikt bij het implementeren van een toepassing? De versie die momenteel in productie is? De versie die momenteel in bètaversie is, maar waarschijnlijk beschikbaar is voor de consument tegen de tijd dat deze naar productie gaat. Moeilijke problemen die niet worden opgelost door alleen microservices te gebruiken.
Er zijn bibliotheken die afhankelijk zijn van een groot aantal projecten. Door de microservices te verdelen met één in elke opslagplaats, kunnen de interne afhankelijkheden het beste worden opgelost met behulp van de interne opslagplaats, Azure Artifacts. Builds voor bibliotheken publiceren hun nieuwste versies naar Azure Artifacts voor intern gebruik. Het downstreamproject moet nog steeds handmatig worden bijgewerkt om afhankelijk te zijn van de zojuist bijgewerkte pakketten.
Een ander nadeel vormt zich bij het verplaatsen van code tussen services. Hoewel het leuk zou zijn om te geloven dat de eerste divisie van een toepassing in microservices 100% juist is, is de realiteit dat we zelden zo voorbeschreven zijn dat we geen fouten in de serviceafdeling maken. Daarom moeten functionaliteit en de code die deze aanstuurt van de service naar de service gaan: opslagplaats naar opslagplaats. Wanneer u van de ene opslagplaats naar de andere springt, verliest de code de geschiedenis. Er zijn veel gevallen, met name in het geval van een controle, waarbij een volledige geschiedenis van een stukje code waardevol is.
Het laatste en belangrijkste nadeel is het coördineren van wijzigingen. In een echte microservicestoepassing mogen er geen implementatieafhankelijkheden tussen services zijn. Het moet mogelijk zijn om services A, B en C in elke volgorde te implementeren omdat ze losse koppeling hebben. In werkelijkheid zijn er echter momenten waarop het wenselijk is om een wijziging aan te brengen die meerdere opslagplaatsen tegelijk doorkruist. Enkele voorbeelden zijn het bijwerken van een bibliotheek om een beveiligingsgat te sluiten of een communicatieprotocol te wijzigen dat door alle services wordt gebruikt.
Om een wijziging tussen opslagplaatsen aan te brengen, moet er achtereenvolgens in elke opslagplaats een commit worden gemaakt. Elke wijziging in elke opslagplaats moet afzonderlijk worden aangevraagd en gecontroleerd. Deze activiteit kan moeilijk te coördineren zijn.
Een alternatief voor het gebruik van veel opslagplaatsen is om alle broncode samen te voegen in een gigantische, allemaal wetende, enkele opslagplaats.
Eén opslagplaats
In deze benadering, ook wel monorepository genoemd, wordt alle broncode voor elke service in dezelfde opslagplaats geplaatst. In het begin lijkt deze benadering een vreselijk idee dat het omgaan met broncode onhandig maakt. Er zijn echter enkele gemarkeerde voordelen om op deze manier te werken.
Het eerste voordeel is dat het eenvoudiger is om afhankelijkheden tussen projecten te beheren. In plaats van te vertrouwen op een externe artefactfeed, kunnen projecten elkaar rechtstreeks importeren. Dit betekent dat updates direct zijn en conflicterende versies waarschijnlijk worden gevonden tijdens het compileren op het werkstation van de ontwikkelaar. In feite verschuift u enkele van de integratietests naar links.
Bij het verplaatsen van code tussen projecten is het nu eenvoudiger om de geschiedenis te behouden, omdat de bestanden worden gedetecteerd als ze zijn verplaatst in plaats van opnieuw te worden geschreven.
Een ander voordeel is dat ingrijpende wijzigingen, die grensoverschrijdend zijn ten aanzien van diensten, in een enkele commit kunnen worden doorgevoerd. Deze activiteit vermindert de overhead van het afzonderlijk controleren van mogelijk tientallen wijzigingen.
Er zijn veel hulpprogramma's die statische analyse van code kunnen uitvoeren om onveilige programmeerprocedures te detecteren of problematisch gebruik van API's te detecteren. In een wereld met meerdere opslagplaatsen moet elke opslagplaats worden doorlopen om de problemen erin te vinden. Met één opslagplaats kan de analyse op één plaats worden uitgevoerd.
Er zijn ook veel nadelen voor de benadering van één opslagplaats. Een van de meest zorgwekkende is dat het hebben van één opslagplaats zorgt voor beveiligingsproblemen. Als de inhoud van een opslagplaats wordt gelekt in een opslagplaats per servicemodel, is de hoeveelheid code die verloren gaat minimaal. Met één opslagplaats kan alles verloren gaan dat het bedrijf eigenaar is. Er zijn veel voorbeelden in het verleden van dit gebeuren en het ontsporen van hele gameontwikkelingsinspanningen. Als u meerdere opslagplaatsen hebt, wordt er minder oppervlakte weergegeven. Dit is een wenselijk kenmerk in de meeste beveiligingsprocedures.
De grootte van de enkele opslagplaats wordt waarschijnlijk snel onbeheerbaar. Dit geeft een aantal interessante gevolgen voor de prestaties. Het kan nodig zijn om gespecialiseerde hulpprogramma's zoals Virtual File System voor Git te gebruiken, die oorspronkelijk is ontworpen om de ervaring voor ontwikkelaars in het Windows-team te verbeteren.
Het argument voor het gebruik van één opslagplaats komt vaak overeen met een argument dat Facebook of Google deze methode gebruikt voor de rangschikking van broncode. Als de aanpak goed genoeg is voor deze bedrijven, dan is het zeker de juiste aanpak voor alle bedrijven. De waarheid van de zaak is dat weinig bedrijven werken op iets zoals de schaal van Facebook of Google. De problemen die zich op deze schalen voordoen, verschillen van die van de meeste ontwikkelaars. Wat goed is voor de gans is misschien niet goed voor de gander.
Uiteindelijk kan een van beide oplossingen worden gebruikt om de broncode voor microservices te hosten. In de meeste gevallen is het beheer en de technische overhead van het werken in één opslagplaats echter niet de nadelen waard. Het opsplitsen van code over meerdere opslagplaatsen stimuleert een betere scheiding van zorgen en moedigt autonomie aan tussen ontwikkelteams.
Standaardbestandsstructuur
Ongeacht het debat over één versus meerdere opslagplaatsen heeft elke service een eigen map. Een van de beste optimalisaties waarmee ontwikkelaars snel tussen projecten kunnen schakelen, is door een standaardmapstructuur te onderhouden.
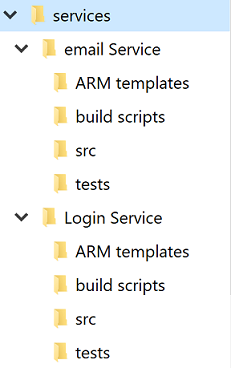
Afbeelding 10-4 - Standaard mapstructuur.
Wanneer een nieuw project wordt gemaakt, moet er een sjabloon worden gebruikt die de juiste structuur plaatst. Deze sjabloon kan ook nuttige items bevatten als een skelet README-bestand en een azure-pipelines.yml. In elke microservicearchitectuur maakt een hoge mate van variantie tussen projecten bulkbewerkingen met de services moeilijker.
Er zijn veel hulpprogramma's die sjablonen kunnen bieden voor een hele map, die verschillende broncodemappen bevatten. Yeoman is populair in de JavaScript-wereld en GitHub heeft onlangs opslagplaatssjablonen uitgebracht, die veel van dezelfde functionaliteit bieden.
Taakbeheer
Het beheren van taken in elk project kan lastig zijn. Vooraf zijn er talloze vragen die moeten worden beantwoord over het soort werkstromen dat moet worden ingesteld om een optimale productiviteit van ontwikkelaars te garanderen.
Cloudeigen toepassingen zijn meestal kleiner dan traditionele softwareproducten of in ieder geval zijn ze onderverdeeld in kleinere services. Het bijhouden van problemen of taken met betrekking tot deze services blijft net zo belangrijk als bij elk ander softwareproject. Niemand wil een werkitem uit het oog verliezen of aan een klant moeten uitleggen dat hun probleem niet goed is vastgelegd. Borden worden geconfigureerd op projectniveau, maar binnen elk project kunnen gebieden worden gedefinieerd. Hierdoor kunnen problemen in verschillende onderdelen worden opgesplitst. Het voordeel van het behoud van al het werk voor de hele toepassing op één plek is dat u eenvoudig werkitems van het ene team naar het andere kunt verplaatsen naarmate ze beter worden begrepen.
Azure DevOps wordt geleverd met een aantal populaire sjablonen die vooraf zijn geconfigureerd. In de meest eenvoudige configuratie is alles wat men moet weten wat zich in de werkvoorraad bevindt, waar mensen aan werken en wat is afgerond. Het is belangrijk om deze zichtbaarheid te hebben in het proces van het bouwen van software, zodat werk prioriteit kan krijgen en voltooide taken kunnen worden gerapporteerd aan de klant. Natuurlijk houden weinig softwareprojecten zich aan een proces zo eenvoudig als to do, doingen done. Het duurt niet lang voordat mensen beginnen met het toevoegen van stappen zoals QA of Detailed Specification aan het proces.
Een van de belangrijkste onderdelen van Agile-methodologieën is zelfintrospectie met regelmatige tussenpozen. Deze beoordelingen zijn bedoeld om inzicht te geven in de problemen waarmee het team te maken heeft en hoe ze kunnen worden verbeterd. Dit betekent vaak dat de stroom van problemen en functies via het ontwikkelingsproces wordt gewijzigd. Het is dus perfect gezond om de indelingen van de borden met extra fasen uit te breiden.
De fasen in de borden zijn niet de enige organisatietool. Afhankelijk van de configuratie van het bord is er een hiërarchie van werkitems. Het meest gedetailleerde item dat op een bord kan worden weergegeven, is een taak. Een taak bevat standaard velden voor een titel, beschrijving, een prioriteit, een schatting van de resterende hoeveelheid werk en de mogelijkheid om te koppelen aan andere werkitems of ontwikkelingsitems (branches, commits, pull requests, builds, enzovoort). Werkitems kunnen worden geclassificeerd in verschillende gebieden van de toepassing en verschillende iteraties (sprints) om ze gemakkelijker te vinden.
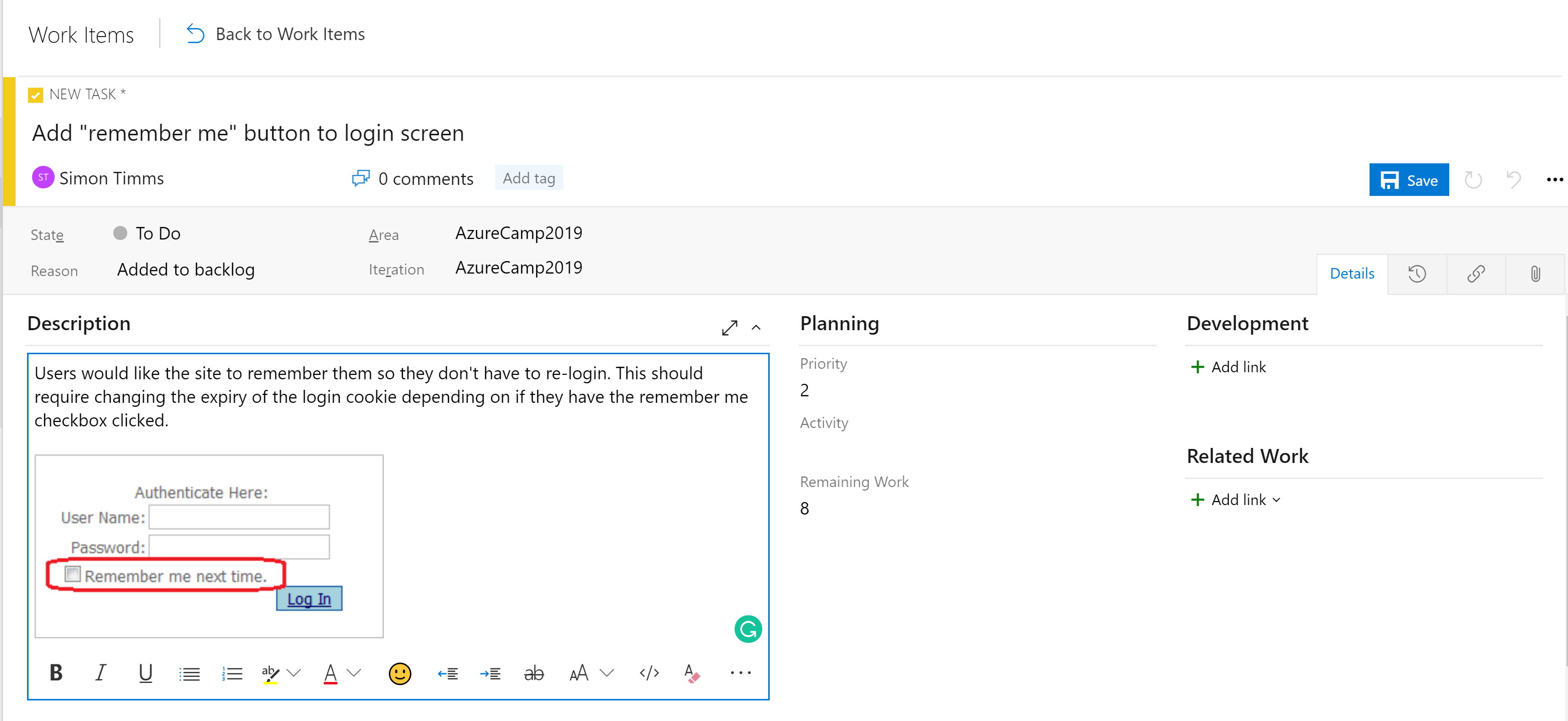
Afbeelding 10-5 - Taak in Azure DevOps.
Het beschrijvingsveld ondersteunt de normale stijlen die u zou verwachten (vet, cursief, onderstreept en doorhalen) en de mogelijkheid om afbeeldingen in te voegen. Dit maakt het een krachtige tool om werk of bugs te specificeren.
Taken kunnen worden samengeteld in functies, waarmee een grotere werkeenheid wordt gedefinieerd. Functies kunnen op zijn beurt worden samengeteld in epics. Het classificeren van taken in deze hiërarchie maakt het veel gemakkelijker om te begrijpen hoe dicht een grote functie bij implementatie is.

Afbeelding 10-6 - Werkitem in Azure DevOps.
Er zijn verschillende manieren om naar de taken in Azure Boards te kijken. Items die nog niet zijn gepland, worden weergegeven in de achterstand. Van daaruit kunnen ze worden toegewezen aan een sprint. Een sprint is een tijdvak waarin wordt verwacht dat een hoeveelheid werk wordt voltooid. Dit werk kan taken omvatten, maar ook de oplossing van tickets. Eenmaal daar kan de hele sprint worden beheerd vanuit de sprintbordsectie. In deze weergave ziet u hoe het werk vordert en bevat een burn-down chart om voortdurend te schatten of de sprint succesvol zal zijn.
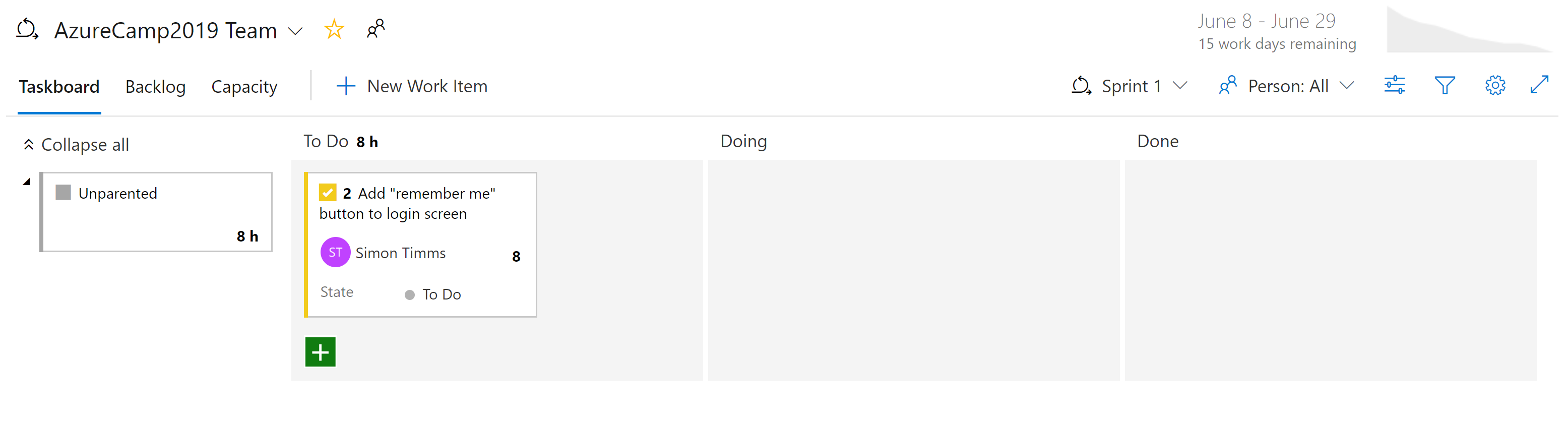
Afbeelding 10-7 - Bord in Azure DevOps.
Het zou nu duidelijk moeten zijn dat er veel kracht is in de boards in Azure DevOps. Voor ontwikkelaars zijn er eenvoudige weergaven van waaraan wordt gewerkt. Projectmanagers hebben inzichten in het komende werk evenals een overzicht van bestaand werk. Voor managers zijn er tal van rapporten over bronnen en capaciteit. Helaas is er niets magisch aan cloudtoepassingen die de noodzaak om werk bij te houden elimineren. Maar als u werk moet bijhouden, zijn er een paar plaatsen waar de ervaring beter is dan in Azure DevOps.
CI/CD-pijplijnen
Bijna geen verandering in de levenscyclus van softwareontwikkeling is zo revolutionaire geweest als de komst van continue integratie (CI) en continue levering (CD). Het bouwen en uitvoeren van geautomatiseerde tests op de broncode van een project, zodra een wijziging is ingecheckt, spoort fouten vroegtijdig op. Vóór de komst van continue integratie-builds zou het niet ongebruikelijk zijn om code op te halen uit de opslagplaats en te ontdekken dat deze geen tests heeft doorstaan of zelfs niet kon worden gebouwd. Dit heeft geresulteerd in het opsporen van de oorzaak van de breuk.
Traditioneel vereiste het verzenden van software naar de productieomgeving uitgebreide documentatie en een lijst met stappen. Elk van deze stappen moet handmatig worden voltooid in een zeer foutgevoelig proces.

Afbeelding 10-8 - Controlelijst.
De zus van continue integratie is continue levering waarin de nieuw gebouwde pakketten in een omgeving worden geïmplementeerd. Het handmatige proces kan niet worden aangepast aan de snelheid van ontwikkeling, zodat automatisering belangrijker wordt. Controlelijsten worden vervangen door scripts die dezelfde taken sneller en nauwkeuriger kunnen uitvoeren dan elke mens.
De omgeving waar continue levering aan levert, kan een testomgeving zijn of, zoals wordt gedaan door veel grote technologiebedrijven, het kan de productieomgeving zijn. Deze laatste vereist een investering in hoogwaardige tests die erop kunnen vertrouwen dat een verandering niet voor gebruikers productie zal breken. Net zoals continue integratie vroegtijdig problemen in de code opspoort, worden problemen in het implementatieproces vroegtijdig opgemerkt door continue levering.
Het belang van het automatiseren van het build- en leveringsproces wordt benadrukt door cloudtoepassingen. Deployments komen vaker voor en in meer omgevingen, waardoor handmatige implementatie vrijwel onmogelijk is.
Azure-builds
Azure DevOps biedt een set hulpprogramma's om continue integratie en implementatie eenvoudiger te maken dan ooit. Deze hulpprogramma's bevinden zich onder Azure Pipelines. De eerste daarvan is Azure Builds, een hulpprogramma voor het uitvoeren van op YAML gebaseerde builddefinities op schaal. Gebruikers kunnen hun eigen buildmachines meenemen (ideaal als de build een zorgvuldig ingestelde omgeving vereist) of een machine gebruiken uit een voortdurend vernieuwde pool van door Azure gehoste virtuele machines. Deze gehoste buildagents worden vooraf geïnstalleerd met een breed scala aan ontwikkelhulpprogramma's voor niet alleen .NET-ontwikkeling, maar voor alles, van Java tot Python tot iPhone-ontwikkeling.
DevOps bevat een breed scala aan kant-en-klare builddefinities die kunnen worden aangepast voor elke build. De builddefinities worden gedefinieerd in een bestand met de naam azure-pipelines.yml en ingecheckt in de repository, zodat ze samen met de broncode kunnen worden geversioneerd. Hierdoor is het veel eenvoudiger om wijzigingen aan te brengen in de build-pijplijn in een vertakking, omdat de wijzigingen alleen in die vertakking kunnen worden ingecheckt. Een voorbeeld azure-pipelines.yml voor het bouwen van een ASP.NET-webtoepassing in volledig framework wordt weergegeven in afbeelding 10-9.
name: $(rev:r)
variables:
version: 9.2.0.$(Build.BuildNumber)
solution: Portals.sln
artifactName: drop
buildPlatform: any cpu
buildConfiguration: release
pool:
name: Hosted VisualStudio
demands:
- msbuild
- visualstudio
- vstest
steps:
- task: NuGetToolInstaller@0
displayName: 'Use NuGet 4.4.1'
inputs:
versionSpec: 4.4.1
- task: NuGetCommand@2
displayName: 'NuGet restore'
inputs:
restoreSolution: '$(solution)'
- task: VSBuild@1
displayName: 'Build solution'
inputs:
solution: '$(solution)'
msbuildArgs: '-p:DeployOnBuild=true -p:WebPublishMethod=Package -p:PackageAsSingleFile=true -p:SkipInvalidConfigurations=true -p:PackageLocation="$(build.artifactstagingdirectory)\\"'
platform: '$(buildPlatform)'
configuration: '$(buildConfiguration)'
- task: VSTest@2
displayName: 'Test Assemblies'
inputs:
testAssemblyVer2: |
**\$(buildConfiguration)\**\*test*.dll
!**\obj\**
!**\*testadapter.dll
platform: '$(buildPlatform)'
configuration: '$(buildConfiguration)'
- task: CopyFiles@2
displayName: 'Copy UI Test Files to: $(build.artifactstagingdirectory)'
inputs:
SourceFolder: UITests
TargetFolder: '$(build.artifactstagingdirectory)/uitests'
- task: PublishBuildArtifacts@1
displayName: 'Publish Artifact'
inputs:
PathtoPublish: '$(build.artifactstagingdirectory)'
ArtifactName: '$(artifactName)'
condition: succeededOrFailed()
Afbeelding 10-9 - Een voorbeeld azure-pipelines.yml
Deze builddefinitie maakt gebruik van een aantal ingebouwde taken die het maken van builds zo eenvoudig maken als het bouwen van een Lego-set (eenvoudiger dan de gigantische Millennium Falcon). Met de NuGet-taak worden bijvoorbeeld NuGet-pakketten hersteld, terwijl de VSBuild-taak de Visual Studio-buildhulpprogramma's aanroept om de daadwerkelijke compilatie uit te voeren. Er zijn honderden verschillende taken beschikbaar in Azure DevOps, met duizenden die door de community worden onderhouden. Het is waarschijnlijk dat iemand er al een heeft gemaakt, ongeacht welke buildtaken u wilt uitvoeren.
Builds kunnen handmatig worden geactiveerd door een check-in, volgens een schema of door het voltooien van een andere build. In de meeste gevallen is het bouwen van elke check-in wenselijk. Builds kunnen worden gefilterd zodat verschillende builds worden uitgevoerd op verschillende onderdelen van de opslagplaats of op verschillende vertakkingen. Dit maakt scenario's mogelijk, zoals het uitvoeren van snelle builds met beperkte tests op pull-aanvragen en het uitvoeren van een volledige regressiesuite tegen de trunk op nachtbasis.
Het eindresultaat van een build is een verzameling bestanden die bekend staat als buildartefacten. Deze artefacten kunnen worden doorgegeven aan de volgende stap in het buildproces of worden toegevoegd aan een Azure Artifacts-feed, zodat ze kunnen worden gebruikt door andere builds.
Azure DevOps-releases
Builds zorgen voor de compilatie van de software tot een releasepakket, maar de artefacten moeten nog naar een testomgeving worden overgebracht om voor continuïteit van levering te zorgen. Hiervoor gebruikt Azure DevOps een afzonderlijk hulpprogramma met de naam Releases. Het hulpprogramma Releases maakt gebruik van dezelfde takenbibliotheek die beschikbaar was voor de build, maar introduceert een concept van 'fasen'. Een fase is een geïsoleerde omgeving waarin het pakket wordt geïnstalleerd. Een product kan bijvoorbeeld gebruikmaken van een ontwikkeling, een QA en een productieomgeving. Code wordt continu geleverd in de ontwikkelomgeving waar geautomatiseerde tests erop kunnen worden uitgevoerd. Zodra deze tests zijn geslaagd, wordt de release verplaatst naar de QA-omgeving voor handmatig testen. Ten slotte wordt de code naar productie gepusht, waar deze zichtbaar is voor iedereen.

Afbeelding 10-10 - Release-pijplijn
Elke fase in de build kan automatisch worden geactiveerd door de voltooiing van de vorige fase. In veel gevallen is dit echter niet wenselijk. Voor het verplaatsen van code naar productie is mogelijk goedkeuring van iemand vereist. Het hulpprogramma Releases ondersteunt dit door goedkeurders toe te staan bij elke stap van de release-pijplijn. Regels kunnen zodanig worden ingesteld dat een specifieke persoon of groep personen zich moet afmelden bij een release voordat deze in productie wordt genomen. Deze poorten zorgen voor handmatige kwaliteitscontroles en ook voor naleving van wettelijke vereisten met betrekking tot het beheren van wat er in productie gaat.
Iedereen krijgt een build-pijplijn
Er zijn geen kosten verbonden aan het configureren van veel build-pijplijnen, dus het is voordelig om ten minste één build-pijplijn per microservice te hebben. In het ideale geval zijn microservices onafhankelijk implementeerbaar in elke omgeving, zodat elke service via een eigen pipeline kan worden vrijgegeven zonder dat er een massa niet-gerelateerde code mee wordt vrijgegeven. Elke pijplijn kan een eigen set goedkeuringen hebben die variaties in het buildproces voor elke service mogelijk maakt.
Versiebeheer van releases
Een nadeel van het gebruik van de functionaliteit Releases is dat deze niet kan worden gedefinieerd in een ingecheckt azure-pipelines.yml bestand. Er zijn veel redenen waarom u dit wilt doen, van het gebruik van releasedefinities per branch tot het inclusief maken van een releaseskelet in uw projecttemplate. Gelukkig is het werk gaande om de ondersteuning van enkele fasen naar het bouwcomponent te verplaatsen. Dit wordt build met meerdere fasen genoemd en de eerste versie is nu beschikbaar.
Met ons samenwerken op GitHub
De bron voor deze inhoud vindt u op GitHub, waar u ook problemen en pull-aanvragen kunt maken en controleren. Bekijk onze gids voor inzenders voor meer informatie.