Notitie
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen u aan te melden of de directory te wijzigen.
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen de mappen te wijzigen.
ML.NET Model Builder is een intuïtieve grafische Visual Studio-extensie voor het bouwen, trainen en implementeren van aangepaste machine learning-modellen. Er wordt gebruikgemaakt van geautomatiseerde machine learning (AutoML) om verschillende machine learning-algoritmen en -instellingen te verkennen om u te helpen de machine te vinden die het beste bij uw scenario past.
U hebt geen machine learning-expertise nodig om Model Builder te kunnen gebruiken. U hebt alleen wat gegevens nodig en een probleem om op te lossen. Model Builder genereert de code om het model toe te voegen aan uw .NET-toepassing.

Een Model Builder-project maken
Wanneer u Model Builder voor het eerst start, wordt u gevraagd het project een naam te geven en vervolgens een mbconfig configuratiebestand in het project te maken. Het mbconfig bestand houdt alles bij wat u in Model Builder doet, zodat u de sessie opnieuw kunt openen.
Na de training worden er drie bestanden gegenereerd onder het *.mbconfig-bestand:
- Model.consumption.cs: dit bestand bevat de
ModelInputen schema's enModelOutputdePredictfunctie die is gegenereerd voor het gebruik van het model. - Model.training.cs: dit bestand bevat de trainingspijplijn (gegevenstransformaties, algoritme, algoritme hyperparameters) die door Model Builder zijn gekozen om het model te trainen. U kunt deze pijplijn gebruiken om uw model opnieuw te trainen.
- Model.zip: dit is een geserialiseerd zip-bestand dat uw getrainde ML.NET model vertegenwoordigt.
Wanneer u uw mbconfig bestand maakt, wordt u gevraagd om een naam. Deze naam wordt toegepast op de verbruiks-, trainings- en modelbestanden. In dit geval is de gebruikte naam Model.
Scenario
U kunt veel verschillende scenario's naar Model Builder brengen om een machine learning-model voor uw toepassing te genereren.
Een scenario is een beschrijving van het type voorspelling dat u wilt doen met behulp van uw gegevens. Voorbeeld:
- Voorspel het verkoopvolume van toekomstige producten op basis van historische verkoopgegevens.
- Sentimenten classificeren als positief of negatief op basis van klantbeoordelingen.
- Detecteren of een banktransactie frauduleus is.
- Feedbackproblemen van klanten doorsturen naar het juiste team in uw bedrijf.
Elk scenario wordt toegewezen aan een andere machine learning-taak, waaronder:
| Opdracht | Scenario |
|---|---|
| Binaire classificatie | Gegevensclassificatie |
| Classificatie met meerdere klassen | Gegevensclassificatie |
| Afbeeldingsclassificatie | Afbeeldingsclassificatie |
| Tekstclassificatie | Tekstclassificatie |
| Regressie | Waardevoorspelling |
| Aanbeveling | Aanbeveling |
| Prognoses opstellen | Prognoses opstellen |
Het scenario voor het classificeren van sentimenten als positief of negatief valt bijvoorbeeld onder de binaire classificatietaak.
Zie Machine Learning-taken in ML.NET voor meer informatie over de verschillende ML-taken die worden ondersteund door ML.NET.
Welk machine learning-scenario is geschikt voor mij?
In Model Builder moet u een scenario selecteren. Het type scenario is afhankelijk van het type voorspelling dat u probeert te maken.
Tabellair
Gegevensclassificatie
Classificatie wordt gebruikt om gegevens in categorieën te categoriseren.
Voorbeeldinvoer
Voorbeelduitvoer
| SepalLength | SepalWidth | Lengte van bloemblaadje | Breedte van bloemblaadje | Soort |
|---|---|---|---|---|
| 5.1 | 3.5 | 1.4 | 0,2 | setosa |
| Voorspelde soorten |
|---|
| setosa |
Waardevoorspelling
Waardevoorspelling, die onder de regressietaak valt, wordt gebruikt om getallen te voorspellen.
Voorbeeldinvoer
Voorbeelduitvoer
| vendor_id | rate_code | passenger_count | trip_time_in_secs | trip_distance | payment_type | fare_amount |
|---|---|---|---|---|---|---|
| CMT | 1 | 1 | 1271 | 3.8 | CRD | 17.5 |
| Voorspeld tarief |
|---|
| 4.5 |
Aanbeveling
Het aanbevelingsscenario voorspelt een lijst met voorgestelde items voor een bepaalde gebruiker, op basis van hoe vergelijkbaar hun likes en niet-leuk zijn voor andere gebruikers'.
U kunt het aanbevelingsscenario gebruiken wanneer u een set gebruikers en een set 'producten' hebt, zoals artikelen die moeten worden gekocht, films, boeken of tv-programma's, samen met een set 'beoordelingen' van die producten van gebruikers.
Voorbeeldinvoer
Voorbeelduitvoer
| Gebruikers-id | Product-id | Beoordeling |
|---|---|---|
| 1 | 2 | 4.2 |
| Voorspelde classificatie |
|---|
| 4.5 |
Prognoses opstellen
In het prognosescenario worden historische gegevens gebruikt met een tijdreeks of een seizoensgebonden onderdeel.
U kunt het prognosescenario gebruiken om de vraag of verkoop voor een product te voorspellen.
Voorbeeldinvoer
Voorbeelduitvoer
| Datum | SaleQty |
|---|---|
| 1/1/1970 | 1000 |
| 3-daagse prognose |
|---|
| [1000,1001,1002] |
Computer Vision
Afbeeldingsclassificatie
Afbeeldingsclassificatie wordt gebruikt om afbeeldingen van verschillende categorieën te identificeren. Bijvoorbeeld verschillende soorten terrein of dieren of productiedefecten.
U kunt het scenario voor afbeeldingsclassificatie gebruiken als u een set afbeeldingen hebt en u de afbeeldingen in verschillende categorieën wilt classificeren.
Voorbeeldinvoer
Voorbeelduitvoer

| Voorspeld label |
|---|
| Hond |
Objectdetectie
Objectdetectie wordt gebruikt om entiteiten in afbeeldingen te zoeken en te categoriseren. Bijvoorbeeld het zoeken en identificeren van auto's en personen in een afbeelding.
U kunt objectdetectie gebruiken wanneer afbeeldingen meerdere objecten van verschillende typen bevatten.
Voorbeeldinvoer
Voorbeelduitvoer

Natuurlijke taalverwerking
Tekstclassificatie
Tekstclassificatie categoriseert onbewerkte tekstinvoer.
U kunt het scenario voor tekstclassificatie gebruiken als u een set documenten of opmerkingen hebt en u deze in verschillende categorieën wilt classificeren.
Voorbeeldinvoer
Voorbeelduitvoer
| Beoordelen |
|---|
| Ik vind deze biefstuk echt leuk! |
| Gevoel |
|---|
| Positief |
Omgeving
U kunt uw machine learning-model lokaal trainen op uw computer of in de cloud op Azure, afhankelijk van het scenario.
Wanneer u lokaal traint, werkt u binnen de beperkingen van uw computerbronnen (CPU, geheugen en schijf). Wanneer u in de cloud traint, kunt u uw resources omhoog schalen om te voldoen aan de vereisten van uw scenario, met name voor grote gegevenssets.
| Scenario | Lokale CPU | Lokale GPU | Azure |
|---|---|---|---|
| Gegevensclassificatie | ✔️ | ❌ | ❌ |
| Waardevoorspelling | ✔️ | ❌ | ❌ |
| Aanbeveling | ✔️ | ❌ | ❌ |
| Prognoses opstellen | ✔️ | ❌ | ❌ |
| Afbeeldingsclassificatie | ✔️ | ✔️ | ✔️ |
| Objectdetectie | ❌ | ❌ | ✔️ |
| Tekstclassificatie | ✔️ | ✔️ | ❌ |
Gegevens
Zodra u uw scenario hebt gekozen, wordt u door Model Builder gevraagd om een gegevensset op te geven. De gegevens worden gebruikt voor het trainen, evalueren en kiezen van het beste model voor uw scenario.
Model Builder ondersteunt gegevenssets in .tsv-, .csv-, .txt- en SQL-databaseindelingen. Als u een .txt bestand hebt, moeten kolommen worden gescheiden door ,, ;of \t.
Als de gegevensset bestaat uit afbeeldingen, zijn .jpg de ondersteunde bestandstypen en .png.
Zie Trainingsgegevens laden in Model Builder voor meer informatie.
Kies de uitvoer die u wilt voorspellen (label)
Een gegevensset is een tabel met rijen met trainingsvoorbeelden en kolommen met kenmerken. Elke rij heeft:
- een label (het kenmerk dat u wilt voorspellen)
- kenmerken (kenmerken die worden gebruikt als invoer om het label te voorspellen)
Voor het scenario voor het voorspellen van huizenprijzen kunnen de volgende functies zijn:
- De vierkante beelden van het huis.
- Het aantal slaapkamers en badkamers.
- De postcode.
Het label is de historische woningprijs voor die rij met vierkante beelden, slaapkamer en badkamerwaarden en postcode.
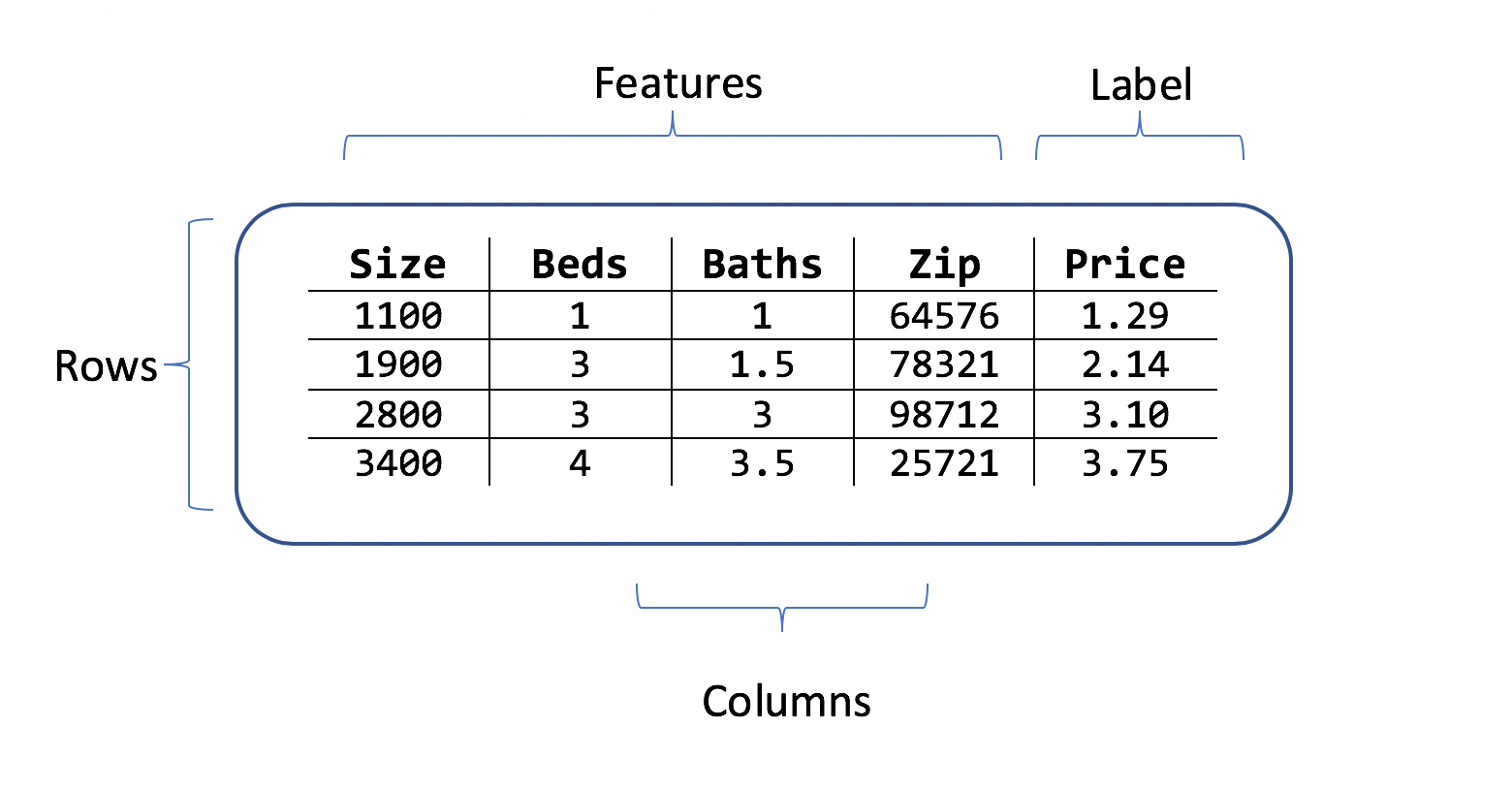
Voorbeeldgegevenssets
Als u nog geen eigen gegevens hebt, kunt u een van deze gegevenssets uitproberen:
| Scenario | Opmerking | Gegevens | Label | Functies |
|---|---|---|---|---|
| Classificatie | Verkoopafwijkingen voorspellen | productverkoopgegevens | Productverkopen | Month |
| Sentiment van websiteopmerkingen voorspellen | opmerkingsgegevens van website | Label (1 wanneer negatief gevoel, 0 wanneer positief) | Opmerking, jaar | |
| Frauduleuze creditcardtransacties voorspellen | creditcardgegevens | Klasse (1 wanneer frauduleus, anders 0) | Bedrag, V1-V28 (geanonimiseerde functies) | |
| Het type probleem in een GitHub-opslagplaats voorspellen | GitHub-probleemgegevens | Gebied | Titel, beschrijving | |
| Waardevoorspelling | Tariefprijs voor taxi voorspellen | taxiritgegevens | Veergeld | Reistijd, afstand |
| Afbeeldingsclassificatie | De categorie van een bloem voorspellen | bloemafbeeldingen | Het type bloem: daisy, paardenbloem, rozen, zonnebloemen, tulpen | De afbeeldingsgegevens zelf |
| Aanbeveling | Films voorspellen die iemand leuk vindt | filmbeoordelingen | Gebruikers, films | Classificeringen |
Trainen
Zodra u uw scenario, omgeving, gegevens en label hebt geselecteerd, traint Model Builder het model.
Wat is training?
Training is een automatisch proces waarmee Model Builder uw model leert hoe u vragen voor uw scenario kunt beantwoorden. Zodra het model is getraind, kan het voorspellingen doen met invoergegevens die het nog niet eerder heeft gezien. Als u bijvoorbeeld huizenprijzen voorspelt en er een nieuw huis op de markt komt, kunt u de verkoopprijs voorspellen.
Omdat Model Builder gebruikmaakt van geautomatiseerde machine learning (AutoML), is er tijdens de training geen invoer of afstemming van u vereist.
Hoe lang moet ik trainen?
Model Builder gebruikt AutoML om meerdere modellen te verkennen om u het best presterende model te vinden.
Met langere trainingsperioden kan AutoML meer modellen verkennen met een breder scala aan instellingen.
De onderstaande tabel bevat een overzicht van de gemiddelde tijd die nodig is om goede prestaties te verkrijgen voor een suite voorbeeldgegevenssets, op een lokale computer.
| Grootte van gegevensset | Gemiddelde tijd om te trainen |
|---|---|
| 0 - 10 MB | 10 sec. |
| 10 - 100 MB | 10 min. |
| 100 - 500 MB | 30 min |
| 500 - 1 GB | 60 min. |
| 1 GB+ | 3+ uur |
Deze nummers zijn alleen een handleiding. De exacte lengte van de training is afhankelijk van:
- Het aantal functies (kolommen) dat wordt gebruikt als invoer voor het model.
- Het type kolommen.
- De ML-taak.
- De CPU-, schijf- en geheugenprestaties van de machine die wordt gebruikt voor training.
Het wordt over het algemeen aangeraden om meer dan 100 rijen te gebruiken als gegevenssets met minder dan die mogelijk geen resultaten opleveren.
Evalueren
Evaluatie is het proces van het meten van hoe goed uw model is. Model Builder gebruikt het getrainde model om voorspellingen te doen met nieuwe testgegevens en meet vervolgens hoe goed de voorspellingen zijn.
Model Builder splitst de trainingsgegevens op in een trainingsset en een testset. De trainingsgegevens (80%) worden gebruikt om uw model te trainen en de testgegevens (20%) worden teruggestuurd om uw model te evalueren.
Hoe kan ik inzicht in de prestaties van mijn model?
Een scenario wordt toegewezen aan een machine learning-taak. Elke ML-taak heeft een eigen set metrische evaluatiegegevens.
Waardevoorspelling
De standaardwaarde voor voorspellingsproblemen met waarden is RSquared, de waarde van RSquared-bereiken tussen 0 en 1. 1 is de best mogelijke waarde of met andere woorden hoe dichter de waarde van RSquared bij 1 ligt, hoe beter uw model presteert.
Andere metrische gegevens die worden gerapporteerd, zoals absoluut verlies, kwadratenverlies en RMS-verlies, zijn aanvullende metrische gegevens, die kunnen worden gebruikt om te begrijpen hoe uw model presteert en vergelijkt met andere waardevoorspellingsmodellen.
Classificatie (2 categorieën)
De standaardwaarde voor classificatieproblemen is nauwkeurigheid. Nauwkeurigheid definieert het aandeel van de juiste voorspellingen die uw model maakt via de testgegevensset. Hoe dichter bij 100% of 1,0 hoe beter het is.
Andere metrische gegevens, zoals AUC (Gebied onder de curve), waarmee het werkelijke positieve percentage versus het fout-positieve percentage wordt berekend, moet groter zijn dan 0,50 om modellen acceptabel te maken.
Aanvullende metrische gegevens, zoals F1-score, kunnen worden gebruikt om de balans tussen Precisie en Relevante overeenkomsten te bepalen.
Classificatie (3+ categorieën)
De standaardwaarde voor classificatie van meerdere klassen is Micronauwkeurigheid. Hoe dichter de micronauwkeurigheid bij 100% of 1,0 is.
Een andere belangrijke metriek voor classificatie met meerdere klassen is macronauwkeurigheid, vergelijkbaar met micronauwkeurigheid, hoe dichter bij 1,0 het beter is. Een goede manier om na te denken over deze twee soorten nauwkeurigheid is:
- Micronauwkeurigheid: Hoe vaak wordt een binnenkomende ticket geclassificeerd aan het juiste team?
- Macronauwkeurigheid: Hoe vaak is een binnenkomend ticket correct voor een team voor een gemiddeld team?
Meer informatie over metrische evaluatiegegevens
Zie metrische gegevens voor modelevaluatie voor meer informatie.
Verbeteren
Als de prestatiescore van uw model niet zo goed is als u wilt, kunt u het volgende doen:
Trainen voor een langere periode. Met meer tijd experimenteren de geautomatiseerde machine learning-engine met meer algoritmen en instellingen.
Voeg meer gegevens toe. Soms is de hoeveelheid gegevens niet voldoende om een machine learning-model van hoge kwaliteit te trainen. Dit geldt met name voor gegevenssets met een klein aantal voorbeelden.
Uw gegevens verdelen. Voor classificatietaken moet u ervoor zorgen dat de trainingsset verdeeld is over de categorieën. Als u bijvoorbeeld vier klassen voor 100 trainingsvoorbeelden hebt en de twee eerste klassen (tag1 en tag2) worden gebruikt voor 90 records, maar de andere twee (tag3 en tag4) worden alleen gebruikt voor de resterende 10 records, kan het gebrek aan evenwichtige gegevens ertoe leiden dat uw model moeite heeft om tag3 of tag4 correct te voorspellen.
Verbruiken
Na de evaluatiefase voert Model Builder een modelbestand en code uit die u kunt gebruiken om het model toe te voegen aan uw toepassing. ML.NET modellen worden opgeslagen als een zip-bestand. De code voor het laden en gebruiken van uw model wordt toegevoegd als een nieuw project in uw oplossing. Model Builder voegt ook een voorbeeldconsole-app toe die u kunt uitvoeren om uw model in actie te zien.
Daarnaast biedt Model Builder u de mogelijkheid om projecten te maken die uw model gebruiken. Op dit moment maakt Model Builder de volgende projecten:
- Console-app: Hiermee maakt u een .NET-consoletoepassing om voorspellingen te doen op basis van uw model.
- Web-API: hiermee maakt u een ASP.NET Core Web-API waarmee u uw model via internet kunt gebruiken.
Wat is de volgende stap?
Installeer de Visual Studio-extensie van Model Builder.
Met ons samenwerken op GitHub
De bron voor deze inhoud vindt u op GitHub, waar u ook problemen en pull-aanvragen kunt maken en controleren. Bekijk onze gids voor inzenders voor meer informatie.