Notitie
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen u aan te melden of de directory te wijzigen.
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen de mappen te wijzigen.
Meer informatie over het bouwen van een anomaliedetectietoepassing voor productverkoopgegevens. In deze zelfstudie maakt u een .NET-consoletoepassing met C# in Visual Studio.
In deze handleiding leer je hoe je:
- De gegevens laden
- Een transformatie maken voor anomaliedetectie met pieken
- Piekafwijkingen detecteren met de transformatie
- Een transformatie maken voor anomaliedetectie van wijzigingspunten
- Afwijkingen van wijzigingspunten detecteren met de transformatie
U vindt de broncode voor deze zelfstudie in de opslagplaats dotnet/samples .
Vereiste voorwaarden
Visual Studio 2022 of hoger waarop de workload .NET Desktop Development is geïnstalleerd.
Opmerking
De gegevensindeling is product-sales.csv gebaseerd op de gegevensset 'Shampoo Sales Over a Three Year Period' oorspronkelijk afkomstig uit DataMarket en geleverd door Time Series Data Library (TSDL), gemaakt door Rob Hyndman.
"Shampoo Sales over een periode van drie jaar" Gegevensset met licentie onder de DataMarket Default Open License.
Een consoletoepassing maken
Maak een C# -consoletoepassing met de naam ProductSalesAnomalyDetection. Klik op de knop Volgende.
Kies .NET 8 als framework dat u wilt gebruiken. Klik op de knop Maken.
Maak een map met de naam Gegevens in uw project om uw gegevensbestanden op te slaan.
Installeer het Microsoft.ML NuGet-pakket:
Opmerking
In dit voorbeeld wordt de laatste stabiele versie van de vermelde NuGet-pakketten gebruikt, tenzij anders vermeld.
Klik in Solution Explorer met de rechtermuisknop op uw project en selecteer NuGet-pakketten beheren. Kies 'nuget.org' als pakketbron, selecteer het tabblad Bladeren, zoek Microsoft.ML en selecteer Installeren. Selecteer de knop OK in het dialoogvenster Voorbeeld van wijzigingen en selecteer vervolgens de knop Accepteren in het dialoogvenster Acceptatie van licenties als u akkoord gaat met de licentievoorwaarden voor de vermelde pakketten. Herhaal deze stappen voor Microsoft.ML.TimeSeries.
Voeg de volgende
usinginstructies toe boven aan het Program.cs-bestand :using Microsoft.ML; using ProductSalesAnomalyDetection;
Download je gegevens
Download de gegevensset en sla deze op in de map Gegevens die u eerder hebt gemaakt:
Klik met de rechtermuisknop op product-sales.csv en selecteer 'Koppeling opslaan (of doel) als...'
Zorg ervoor dat u het bestand *.csv opslaat in de map Gegevens of nadat u het ergens anders hebt opgeslagen, verplaatst u het bestand *.csv naar de map Gegevens .
Klik in Solution Explorer met de rechtermuisknop op het bestand *.csv en selecteer Eigenschappen. Wijzig onder Geavanceerd de waarde van Kopiëren naar Uitvoermap naar Kopiëren als nieuwer.
De volgende tabel is een voorbeeld van gegevens uit uw *.csv-bestand:
| Maand | ProductVerkoop |
|---|---|
| 1-jan | 271 |
| 2 januari | 150.9 |
| ..... | ..... |
| 1-feb | 199.3 |
| ..... | ..... |
Klassen maken en paden definiëren
Definieer vervolgens de gegevensstructuren van de invoer- en voorspellingsklasse.
Voeg een nieuwe klasse toe aan uw project:
Klik in Solution Explorer met de rechtermuisknop op het project en selecteer Nieuw item toevoegen>.
Selecteer in het dialoogvenster Nieuw item toevoegen de optie Klasse en wijzig het veld Naamin ProductSalesData.cs. Selecteer vervolgens Toevoegen.
Het bestand ProductSalesData.cs wordt geopend in de code-editor.
Voeg de volgende
usinginstructie toe aan het begin van ProductSalesData.cs:using Microsoft.ML.Data;Verwijder de bestaande klassedefinitie en voeg de volgende code toe, die twee klassen
ProductSalesDataheeft enProductSalesPrediction, aan het ProductSalesData.cs-bestand :public class ProductSalesData { [LoadColumn(0)] public string? Month; [LoadColumn(1)] public float numSales; } public class ProductSalesPrediction { //vector to hold alert,score,p-value values [VectorType(3)] public double[]? Prediction { get; set; } }ProductSalesDatageeft een invoergegevensklasse op. Het kenmerk LoadColumn geeft aan welke kolommen (per kolomindex) in de gegevensset moeten worden geladen.ProductSalesPredictionhiermee geeft u de voorspellingsgegevensklasse op. Voor anomaliedetectie bestaat de voorspelling uit een waarschuwing om aan te geven of er een anomalie, een onbewerkte score en p-waarde is. Hoe dichter de p-waarde is op 0, hoe waarschijnlijker er een anomalie is opgetreden.Maak twee globale velden voor het onlangs gedownloade bestandspad van de gegevensset en het pad naar het opgeslagen modelbestand:
-
_dataPathheeft het pad naar de gegevensset die wordt gebruikt om het model te trainen. -
_docsizebevat het aantal records in het gegevenssetbestand. U gebruikt_docSizeom te berekenenpvalueHistoryLength.
-
Voeg de volgende code toe aan de regel rechts onder de
usinginstructies om deze paden op te geven:string _dataPath = Path.Combine(Environment.CurrentDirectory, "Data", "product-sales.csv"); //assign the Number of records in dataset file to constant variable const int _docsize = 36;
Variabelen initialiseren
Vervang de
Console.WriteLine("Hello World!")regel door de volgende code om demlContextvariabele te declareren en te initialiseren:MLContext mlContext = new MLContext();De MLContext-klasse is startpunt voor alle ML.NET-bewerkingen en initialisatie
mlContextcreëert een nieuwe ML.NET-omgeving die kan worden gedeeld in de werkstromen voor het maken van modellen. Het is vergelijkbaar, conceptueel gezien, metDBContextin Entity Framework.
De gegevens laden
Gegevens in ML.NET worden weergegeven als een IDataView-interface.
IDataView is een flexibele, efficiënte manier om tabelgegevens (numeriek en tekst) te beschrijven. Gegevens kunnen vanuit een tekstbestand of uit andere bronnen (bijvoorbeeld SQL-database of logboekbestanden) naar een IDataView object worden geladen.
Voeg de volgende code toe nadat u de variabele hebt
mlContextgemaakt:IDataView dataView = mlContext.Data.LoadFromTextFile<ProductSalesData>(path: _dataPath, hasHeader: true, separatorChar: ',');De LoadFromTextFile() definieert het gegevensschema en leest in het bestand. Het neemt de gegevenspadvariabelen in en retourneert een
IDataView.
Anomaliedetectie van tijdreeksen
Anomaliedetectie markeert onverwachte of ongebruikelijke gebeurtenissen of gedragingen. Het geeft aanwijzingen waar u naar problemen moet zoeken en helpt u de vraag 'Is dit raar?' te beantwoorden.

Anomaliedetectie is het proces waarbij uitschieters in tijdreeksgegevens worden gedetecteerd; punten op een tijdreeks waar het gedrag niet aan de verwachtingen voldoet of 'afwijkend' is.
Anomaliedetectie kan op veel manieren nuttig zijn. Bijvoorbeeld:
Als je een auto hebt, wil je misschien weten: Is deze oliemeter normaal of heb ik een lek? Als u het energieverbruik bewaakt, wilt u weten: Is er een storing?
Er zijn twee typen tijdreeksafwijkingen die kunnen worden gedetecteerd:
Pieken geven tijdelijke uitbarstingen van afwijkend gedrag in het systeem aan.
Wijzigingspunten geven het begin van permanente wijzigingen in de loop van de tijd in het systeem aan.
In ML.NET zijn de algoritmen IID-piekdetectie of IID-wijzigingspuntdetectie geschikt voor onafhankelijke en identieke gedistribueerde gegevenssets. Ze gaan ervan uit dat uw invoergegevens een reeks gegevenspunten zijn die onafhankelijk worden bemonsterd uit één stationaire distributie.
In tegenstelling tot de modellen in de andere handleidingen, voeren de transformaties van de tijdreeks-anomaliedetector werrkzaamheden rechtstreeks uit op invoergegevens. De IEstimator.Fit() methode heeft geen trainingsgegevens nodig om de transformatie te produceren. Het heeft echter wel het gegevensschema nodig, dat wordt geleverd door een gegevensweergave die is gegenereerd op basis van een lege lijst met ProductSalesData.
U analyseert dezelfde productverkoopgegevens om pieken en wijzigingspunten te detecteren. Het proces voor het bouwen en trainen van modellen is hetzelfde voor piekdetectie en wijzigingspuntdetectie; het belangrijkste verschil is het specifieke detectie-algoritme dat wordt gebruikt.
Piekdetectie
Het doel van piekdetectie is het identificeren van plotselinge maar tijdelijke bursts die aanzienlijk verschillen van het merendeel van de tijdreeksgegevenswaarden. Het is belangrijk om deze verdachte zeldzame items, gebeurtenissen of waarnemingen tijdig te detecteren, zodat ze geminimaliseerd kunnen worden. De volgende benadering kan worden gebruikt om verschillende afwijkingen te detecteren, zoals storingen, cyberaanvallen of virale webinhoud. De volgende afbeelding is een voorbeeld van pieken in een tijdreeksgegevensset:
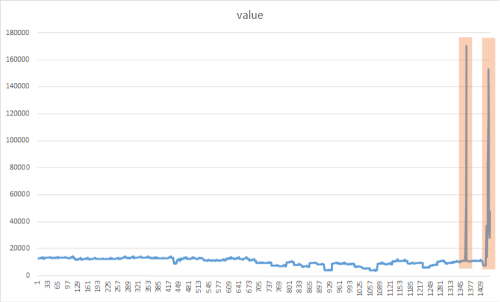
De methode CreateEmptyDataView() toevoegen
Voeg de volgende methode toe aan Program.cs:
IDataView CreateEmptyDataView(MLContext mlContext) {
// Create empty DataView. We just need the schema to call Fit() for the time series transforms
IEnumerable<ProductSalesData> enumerableData = new List<ProductSalesData>();
return mlContext.Data.LoadFromEnumerable(enumerableData);
}
Het CreateEmptyDataView() produceert een leeg gegevensweergaveobject met het juiste schema dat moet worden gebruikt als invoer voor de IEstimator.Fit() methode.
De methode DetectSpike() maken
De methode DetectSpike():
- Maakt de transformatie van de estimator.
- Detecteert pieken op basis van historische verkoopgegevens.
- Geeft de resultaten weer.
Maak de
DetectSpike()methode onder aan het Program.cs-bestand met behulp van de volgende code:DetectSpike(MLContext mlContext, int docSize, IDataView productSales) { }Gebruik de IidSpikeEstimator om het model te trainen voor piekdetectie. Voeg deze toe aan de
DetectSpike()methode met de volgende code:var iidSpikeEstimator = mlContext.Transforms.DetectIidSpike(outputColumnName: nameof(ProductSalesPrediction.Prediction), inputColumnName: nameof(ProductSalesData.numSales), confidence: 95d, pvalueHistoryLength: docSize / 4);Maak de transformatie voor piekdetectie door het volgende toe te voegen als de volgende coderegel in de
DetectSpike()methode:Aanbeveling
De
confidenceenpvalueHistoryLengthparameters zijn van invloed op de wijze waarop pieken worden gedetecteerd.confidencebepaalt hoe gevoelig uw model is voor pieken. Hoe lager het vertrouwen, hoe waarschijnlijker het algoritme is om 'kleinere' pieken te detecteren. DepvalueHistoryLengthparameter definieert het aantal gegevenspunten in een schuifvenster. De waarde van deze parameter is meestal een percentage van de gehele gegevensset. Hoe lager depvalueHistoryLength, hoe sneller het model de vorige grote pieken vergeet.ITransformer iidSpikeTransform = iidSpikeEstimator.Fit(CreateEmptyDataView(mlContext));Voeg de volgende coderegel toe om de
productSalesgegevens te transformeren als de volgende regel in deDetectSpike()methode:IDataView transformedData = iidSpikeTransform.Transform(productSales);De vorige code maakt gebruik van de methode Transform() om voorspellingen te doen voor meerdere invoerrijen van een gegevensset.
Converteer uw
transformedDatagegevens naar een sterk getyptIEnumerablevoor eenvoudigere weergave met behulp van de methode CreateEnumerable() met de volgende code:var predictions = mlContext.Data.CreateEnumerable<ProductSalesPrediction>(transformedData, reuseRowObject: false);Maak een weergaveheaderregel met behulp van de volgende Console.WriteLine() code:
Console.WriteLine("Alert\tScore\tP-Value");U geeft de volgende informatie weer in de resultaten van de detectie van pieken:
-
Alertgeeft een piekwaarschuwing aan voor een bepaald gegevenspunt. -
Scoreis deProductSaleswaarde voor een bepaald gegevenspunt in de gegevensset. -
P-ValueDe "P" staat voor waarschijnlijkheid. Hoe dichter de p-waarde is op 0, hoe waarschijnlijker het gegevenspunt een anomalie is.
-
Gebruik de volgende code om de
predictionsIEnumerableresultaten te doorlopen en weer te geven:foreach (var p in predictions) { if (p.Prediction is not null) { var results = $"{p.Prediction[0]}\t{p.Prediction[1]:f2}\t{p.Prediction[2]:F2}"; if (p.Prediction[0] == 1) { results += " <-- Spike detected"; } Console.WriteLine(results); } } Console.WriteLine("");Voeg de aanroep toe aan de
DetectSpike()methode onder de aanroep naar deLoadFromTextFile()methode:DetectSpike(mlContext, _docsize, dataView);
Resultaten van piekdetectie
Uw resultaten moeten er ongeveer als volgt uitzien. Tijdens de verwerking worden berichten weergegeven. U ziet mogelijk waarschuwingen of verwerkingsberichten. Sommige berichten zijn verwijderd uit de volgende resultaten voor duidelijkheid.
Detect temporary changes in pattern
=============== Training the model ===============
=============== End of training process ===============
Alert Score P-Value
0 271.00 0.50
0 150.90 0.00
0 188.10 0.41
0 124.30 0.13
0 185.30 0.47
0 173.50 0.47
0 236.80 0.19
0 229.50 0.27
0 197.80 0.48
0 127.90 0.13
1 341.50 0.00 <-- Spike detected
0 190.90 0.48
0 199.30 0.48
0 154.50 0.24
0 215.10 0.42
0 278.30 0.19
0 196.40 0.43
0 292.00 0.17
0 231.00 0.45
0 308.60 0.18
0 294.90 0.19
1 426.60 0.00 <-- Spike detected
0 269.50 0.47
0 347.30 0.21
0 344.70 0.27
0 445.40 0.06
0 320.90 0.49
0 444.30 0.12
0 406.30 0.29
0 442.40 0.21
1 580.50 0.00 <-- Spike detected
0 412.60 0.45
1 687.00 0.01 <-- Spike detected
0 480.30 0.40
0 586.30 0.20
0 651.90 0.14
Detectie van wijzigingspunten
Change points zijn permanente wijzigingen in de distributie van waarden in een tijdreeksgegevenstroom, zoals niveauwijzigingen en trends. Deze permanente wijzigingen duren veel langer dan spikes en kunnen duiden op catastrofale gebeurtenissen.
Change points zijn meestal niet zichtbaar voor het naakte oog, maar kunnen worden gedetecteerd in uw gegevens met behulp van benaderingen zoals in de volgende methode. De volgende afbeelding is een voorbeeld van een wijzigingspuntdetectie:
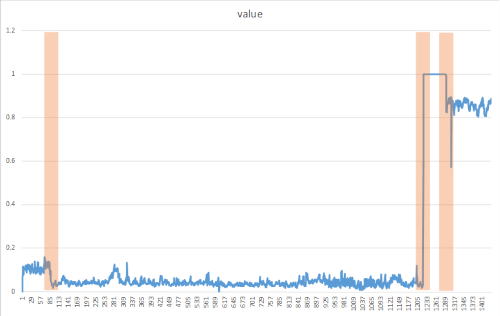
De methode DetectChangepoint() maken
De DetectChangepoint() methode voert de volgende taken uit:
- Maakt de transformatie van de estimator.
- Detecteert wijzigingspunten op basis van historische verkoopgegevens.
- Geeft de resultaten weer.
Maak de
DetectChangepoint()methode, net na de declaratie van deDetectSpike()methode, met behulp van de volgende code:void DetectChangepoint(MLContext mlContext, int docSize, IDataView productSales) { }Maak de iidChangePointEstimator in de
DetectChangepoint()methode met de volgende code:var iidChangePointEstimator = mlContext.Transforms.DetectIidChangePoint(outputColumnName: nameof(ProductSalesPrediction.Prediction), inputColumnName: nameof(ProductSalesData.numSales), confidence: 95d, changeHistoryLength: docSize / 4);Zoals u eerder hebt gedaan, maakt u de transformatie vanuit de estimator door de volgende coderegel toe te voegen in de
DetectChangePoint()methode:Aanbeveling
De detectie van wijzigingspunten gebeurt met een lichte vertraging, omdat het model ervoor moet zorgen dat de huidige afwijking een permanente wijziging is en niet alleen enkele willekeurige pieken voordat er een waarschuwing wordt gemaakt. De hoeveelheid van deze vertraging is gelijk aan de
changeHistoryLengthparameter. Door de waarde van deze parameter te verhogen, worden er waarschuwingen voor wijzigingsdetectie op permanentere wijzigingen weergegeven, maar de afweging zou een langere vertraging zijn.var iidChangePointTransform = iidChangePointEstimator.Fit(CreateEmptyDataView(mlContext));Gebruik de
Transform()methode om de gegevens te transformeren door de volgende code toe te voegen aanDetectChangePoint():IDataView transformedData = iidChangePointTransform.Transform(productSales);Zoals u eerder hebt gedaan, converteert u uw
transformedDatanaar een sterk getypteIEnumerablemethode voor eenvoudigere weergave met behulp van deCreateEnumerable()methode met de volgende code:var predictions = mlContext.Data.CreateEnumerable<ProductSalesPrediction>(transformedData, reuseRowObject: false);Maak een weergaveheader met de volgende code als de volgende regel in de
DetectChangePoint()methode:Console.WriteLine("Alert\tScore\tP-Value\tMartingale value");U geeft de volgende informatie weer in de resultaten van de detectie van wijzigingenpunten:
-
Alertgeeft een waarschuwing voor een wijzigingspunt aan voor een bepaald gegevenspunt. -
Scoreis deProductSaleswaarde voor een bepaald gegevenspunt in de gegevensset. -
P-ValueDe "P" staat voor waarschijnlijkheid. Hoe dichter de P-waarde is op 0, hoe waarschijnlijker het gegevenspunt een anomalie is. -
Martingale valuewordt gebruikt om te bepalen hoe 'vreemd' een gegevenspunt is, op basis van de reeks P-waarden.
-
Doorloop de
predictionsIEnumerableresultaten en geef de resultaten weer met de volgende code:foreach (var p in predictions) { if (p.Prediction is not null) { var results = $"{p.Prediction[0]}\t{p.Prediction[1]:f2}\t{p.Prediction[2]:F2}\t{p.Prediction[3]:F2}"; if (p.Prediction[0] == 1) { results += " <-- alert is on, predicted changepoint"; } Console.WriteLine(results); } } Console.WriteLine("");Voeg de volgende aanroep toe aan de
DetectChangepoint()methode na de aanroep naar deDetectSpike()methode:DetectChangepoint(mlContext, _docsize, dataView);
Resultaten van wijzigingspuntdetectie
Uw resultaten moeten er ongeveer als volgt uitzien. Tijdens de verwerking worden berichten weergegeven. U ziet mogelijk waarschuwingen of verwerkingsberichten. Sommige berichten zijn verwijderd uit de volgende resultaten voor duidelijkheid.
Detect Persistent changes in pattern
=============== Training the model Using Change Point Detection Algorithm===============
=============== End of training process ===============
Alert Score P-Value Martingale value
0 271.00 0.50 0.00
0 150.90 0.00 2.33
0 188.10 0.41 2.80
0 124.30 0.13 9.16
0 185.30 0.47 9.77
0 173.50 0.47 10.41
0 236.80 0.19 24.46
0 229.50 0.27 42.38
1 197.80 0.48 44.23 <-- alert is on, predicted changepoint
0 127.90 0.13 145.25
0 341.50 0.00 0.01
0 190.90 0.48 0.01
0 199.30 0.48 0.00
0 154.50 0.24 0.00
0 215.10 0.42 0.00
0 278.30 0.19 0.00
0 196.40 0.43 0.00
0 292.00 0.17 0.01
0 231.00 0.45 0.00
0 308.60 0.18 0.00
0 294.90 0.19 0.00
0 426.60 0.00 0.00
0 269.50 0.47 0.00
0 347.30 0.21 0.00
0 344.70 0.27 0.00
0 445.40 0.06 0.02
0 320.90 0.49 0.01
0 444.30 0.12 0.02
0 406.30 0.29 0.01
0 442.40 0.21 0.01
0 580.50 0.00 0.01
0 412.60 0.45 0.01
0 687.00 0.01 0.12
0 480.30 0.40 0.08
0 586.30 0.20 0.03
0 651.90 0.14 0.09
Gefeliciteerd! U hebt nu machine learning-modellen gebouwd voor het detecteren van pieken en wijzigingspuntafwijkingen in verkoopgegevens.
U vindt de broncode voor deze zelfstudie in de opslagplaats dotnet/samples .
In deze tutorial leerde je hoe je:
- De gegevens laden
- Het model trainen voor anomaliedetectie van pieken
- Piekafwijkingen detecteren met het getrainde model
- Het model trainen voor anomaliedetectie van wijzigingspunten
- Afwijkingen van wijzigingspunten detecteren met de getrainde modus
Volgende stappen
Bekijk de GitHub-opslagplaats met Machine Learning-voorbeelden om een voorbeeld van anomaliedetectie van seizoensgebonden gegevens te verkennen.
Met ons samenwerken op GitHub
De bron voor deze inhoud vindt u op GitHub, waar u ook problemen en pull-aanvragen kunt maken en controleren. Bekijk onze gids voor inzenders voor meer informatie.