Verbinding maken met Common Data Model-tabellen in Azure Data Lake Storage
Opmerking
Azure Active Directory heet nu Microsoft Entra ID. Meer informatie
Neem gegevens op in Dynamics 365 Customer Insights - Data met behulp van uw Azure Data Lake Storage-account met Common Data Model-tabellen. Gegevensopname kan volledig of incrementeel zijn.
Vereisten
Op het Azure Data Lake Storage-account moet hiërarchische naamruimte ingeschakeld zijn. De gegevens moeten worden opgeslagen in een hiërarchische mapindeling die de hoofdmap definieert en submappen heeft voor elke tabel. De submappen kunnen volledige gegevens of incrementele gegevensmappen hebben.
Om te verifiëren met een Microsoft Entra-service-principal, moet u ervoor zorgen dat deze in uw tenant is geconfigureerd. Zie Verbinding met een Azure Data Lake Storage-account maken met een Microsoft Entra-service-principal voor meer informatie.
De Azure Data Lake Storage waarmee u verbinding wilt maken en waaruit u gegevens wilt opnemen, moet zich in dezelfde Azure-regio bevinden als de Dynamics 365 Customer Insights-omgeving en de abonnementen moeten zich in dezelfde tenant bevinden. Verbindingen met een Common Data Model-map vanuit een data lake in een andere Azure-regio worden niet ondersteund. Als u de Azure-regio van de omgeving wilt weten, gaat u naar Instellingen>Systeem>Info in Customer Insights - Data.
Gegevens die zijn opgeslagen in online services, kunnen op een andere locatie worden opgeslagen dan waar gegevens worden verwerkt of opgeslagen. Door het importeren van of verbinden met gegevens die zijn opgeslagen in online services, gaat u ermee akkoord dat gegevens kunnen worden overgedragen. Ga voor meer informatie naar het Microsoft Trust Center.
De Customer Insights - Data-service-principal moet een van de volgende rollen hebben om toegang te krijgen tot het opslagaccount. Voor meer informatie, zie Machtigingen verlenen aan de service-principal voor toegang tot het opslagaccount.
- Opslag-blobgegevens lezer
- Opslag-blobgegevens eigenaar
- Inzender van opslag-blobgegevens
Wanneer u verbinding maakt met uw Azure-opslag met behulp van de optie Azure-abonnement, heeft de gebruiker die de gegevensbronverbinding instelt, minimaal de Bijdrager van Storage Blob-gegevens-machtigingen nodig voor het opslagaccount.
Wanneer u verbinding maakt met uw Azure-opslag met behulp van de optie Azure-resource, heeft de gebruiker die de gegevensbronverbinding instelt, minimaal de machtiging voor de actie Microsoft.Storage/storageAccounts/read nodig voor het opslagaccount. Een ingebouwde Azure-rol die deze actie bevat, is de rol Lezer. U kunt de toegang tot alleen de noodzakelijke actie beperken door een aangepaste Azure-rol te maken die alleen deze actie bevat.
Voor optimale prestaties moet de grootte van een partitie 1 GB of minder zijn en mag het aantal partitiebestanden in een map niet groter zijn dan 1000.
Gegevens in uw Data Lake Storage moeten de Common Data Model-standaard volgen voor de opslag van uw gegevens en het Common Data Model-manifest hebben om het schema van de gegevensbestanden (*.csv of *.parquet) weer te geven. Het manifest moet de details van de tabellen bevatten, zoals tabelkolommen en gegevenstypen, evenals de locatie van het gegevensbestand en het bestandstype. Zie voor meer informatie Het Common Data Model-manifest. Als het manifest niet aanwezig is, kunnen beheerders met Storage Blob Data eigenaar- of Storage Blob Data inzender-toegang het schema definiëren bij het opnemen van de gegevens.
Opmerking
Als een van de velden in de .parquet-bestanden het gegevenstype Int96 heeft, worden de gegevens mogelijk niet weergegeven op de pagina Tabellen. We raden u aan standaardgegevenstypen te gebruiken, zoals de Unix-tijdstempelindeling (die de tijd weergeeft als het aantal seconden sinds 1 januari 1970, om middernacht UTC).
Beperkingen
- Customer Insights - Data ondersteunt geen kolommen met een decimaal type met een precisie groter dan 16.
Verbinding maken met Azure Data Lake Storage
Ga naar Gegevens>Gegevensbronnen.
Selecteer Een gegevensbron toevoegen.
Selecteer Azure Data Lake Common Data Model-tabellen.

Voer een Naam gegevensbron en een optionele Beschrijving in. Er wordt naar de naam verwezen in downstreamprocessen en deze kan niet worden gewijzigd nadat de gegevensbron is gemaakt.
Kies een van de volgende opties voor Uw opslag verbinden met. Zie Verbinding met een Azure Data Lake Storage-account maken met een Microsoft Entra-service-principal voor meer informatie.
- Azure-resource: Voer de Resource-id in. (private-link.md).
- Azure-abonnement: selecteer het Abonnement en dan de Resourcegroep en het Opslagaccount.
Opmerking
U hebt een van de volgende rollen nodig voor de container om de gegevensbron te maken:
- Storage Blob-gegevenslezer is voldoende om van een opslagaccount te lezen en de gegevens op te nemen in Customer Insights - Data.
- Bijdrager van Storage Blob-gegevens of Eigenaar van Storage Blob-gegevens is vereist als u de manifestbestanden rechtstreeks in Customer Insights - Data wilt bewerken.
Als u de rol voor het opslagaccount hebt, wordt dezelfde rol voor alle containers geboden.
Optioneel, als u gegevens van een opslagaccount wilt opnemen via een Azure Private Link, selecteert u Private Link inschakelen. Zie voor meer informatie Privékoppelingen.
Kies de naam van de Container die de gegevens en het schema bevat (model.json- of manifest.json-bestand) om gegevens uit te importeren, en selecteer Volgende.
Opmerking
Elk model.json- of manifest.json-bestand dat aan een andere gegevensbron in de omgeving is gekoppeld, wordt niet in de lijst weergegeven. Hetzelfde model.json- of manifest.json-bestand kan echter worden gebruikt voor gegevensbronnen in meerdere omgevingen.
Als u een nieuw schema wilt maken, gaat u naar Een nieuw schemabestand maken.
Als u een bestaand schema wilt gebruiken, navigeert u naar de map met het model.json- of manifest.cdm.json-bestand. U kunt in een map zoeken om het bestand te vinden.
Selecteer het json-bestand en selecteer Volgende. Een lijst met beschikbare tabellen wordt weergegeven.
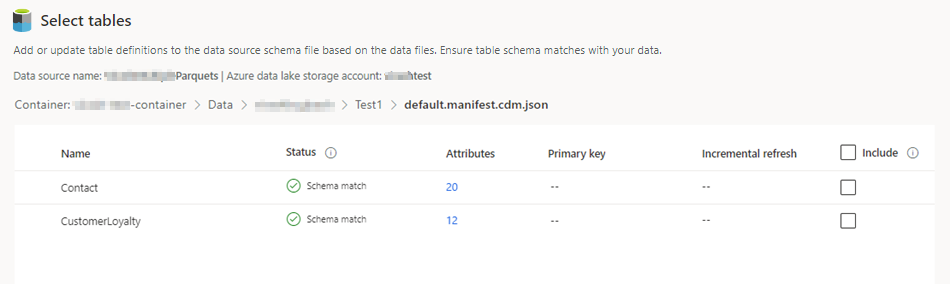
Selecteer de tabellen die u wil opnemen.
Tip
Als u een tabel in een JSON-bewerkingsinterface wilt bewerken, selecteert u de tabel en vervolgens Schemabestand bewerken. Breng uw wijzigingen aan selecteer Opslaan.
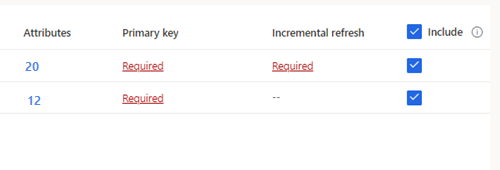
Voor geselecteerde tabellen die incrementele opname vereisen, wordt Vereist weergegeven onder Incrementeel vernieuwen. Voor elk van deze tabellen, zie Een incrementele vernieuwing configureren voor Azure Data Lake-gegevensbronnen.
Voor geselecteerde tabellen waarvoor geen primaire sleutel is gedefinieerd, wordt Vereist weergegeven onder Primaire sleutel. Voor elk van deze tabellen:
- Selecteer Vereist. Het deelvenster Tabel bewerken wordt weergegeven.
- Kies de primaire sleutel. De primaire sleutel is een kenmerk dat uniek is voor de tabel. Als een kenmerk een geldige primaire sleutel is, mag het geen dubbele waarden, ontbrekende waarden of null-waarden bevatten. Kenmerken van het gegevenstype string, integer en GUID worden ondersteund als primaire sleutels.
- Wijzig eventueel het partitiepatroon.
- Selecteer Sluiten om het deelvenster op te slaan en te sluiten.
Selecteer het aantal kolommen voor elke opgenomen tabel. De pagina Kernmerken beheren wordt weergegeven.
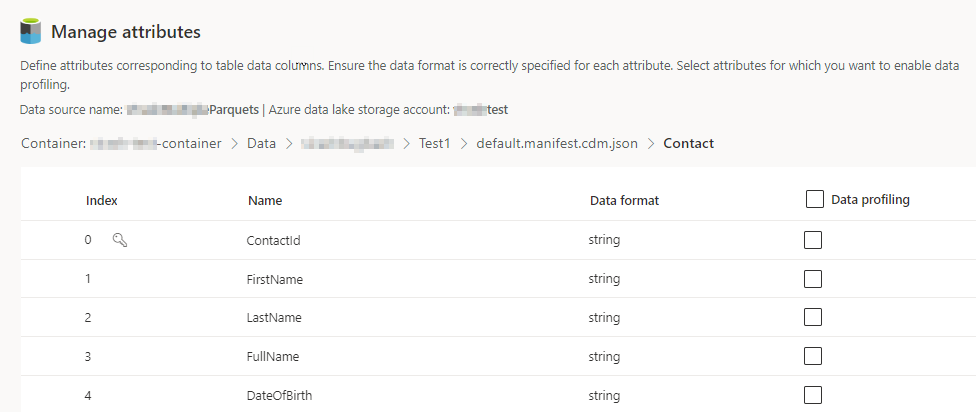
- Maak nieuwe kolommen, bewerk of verwijder bestaande kolommen. U kunt de naam, de gegevensindeling wijzigen of een semantisch type toevoegen.
- Als u analyses en andere mogelijkheden wilt inschakelen, selecteert u Gegevensprofilering voor de hele tabel of voor specifieke kolommen. Standaard is geen tabel ingeschakeld voor gegevensprofilering.
- Selecteer Gereed.
Selecteer Opslaan. De pagina Gegevensbronnen wordt geopend met de nieuwe gegevensbron met de status Vernieuwen.
Tip
Er zijn statussen voor taken en processen. De meeste processen zijn afhankelijk van andere upstreamprocessen, zoals de vernieuwing van gegevensbronnen en gegevensprofilering.
Selecteer de status om het deelvenster Details van voortgang te openen en de voortgang van de taken te bekijken. Als u de taak wilt annuleren, selecteert u Taak annuleren onder aan het deelvenster.
Onder elke taak kunt u Zie details selecteren voor meer voortgangsinformatie, zoals verwerkingstijd, de laatste verwerkingsdatum en eventuele toepasselijke fouten en waarschuwingen die verband houden met de taak of het proces. Selecteer Systeemstatus weergeven onder aan het deelvenster om andere processen in het systeem te zien.

Het laden van gegevens kan enige tijd vergen. Na een succesvolle vernieuwing kunnen de opgenomen gegevens worden bekeken op de pagina Tabellen.
Een nieuw schemabestand maken
Selecteer Schemabestand maken.
Voer een naam in voor het bestand en selecteer Opslaan.
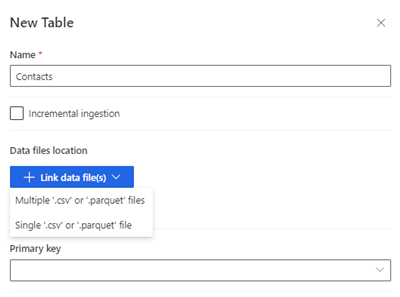
Selecteer Nieuwe tabel. Het deelvenster Nieuwe tabel wordt weergegeven.
Voer de naam van de tabel in en kies de Locatie van gegevensbestanden.
- Meerdere .csv- of .parquet-bestanden: blader naar de hoofdmap, selecteer het patroontype en voer de uitdrukking in.
- Enkele .csv- of .parquet-bestanden: blader naar het .csv- of .parquet-bestand en selecteer het.
Selecteer Opslaan.
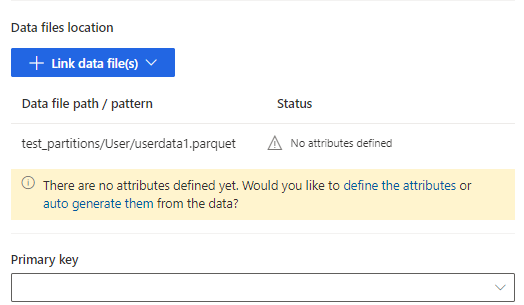
Selecteer de kenmerken definiëren om de kenmerken handmatig toe te voegen, of selecteer automatisch genereren. Als u de kenmerken wilt definiëren, voert u een naam in, selecteert u de gegevensindeling en het optionele semantische type. Voor automatisch gegenereerde kenmerken:
Nadat de kenmerken automatisch zijn gegenereerd, selecteert u Kenmerken beoordelen. De pagina Kernmerken beheren wordt weergegeven.
Zorg ervoor dat de gegevensindeling voor elk kenmerk correct is.
Als u analyses en andere mogelijkheden wilt inschakelen, selecteert u Gegevensprofilering voor de hele tabel of voor specifieke kolommen. Standaard is geen tabel ingeschakeld voor gegevensprofilering.
Selecteer Gereed. De pagina Tabellen selecteren wordt weergegeven.
Ga door met het toevoegen van tabellen en kolommen, indien van toepassing.
Nadat alle tabellen zijn toegevoegd, selecteert u Opnemen om de tabellen op te nemen bij de gegevensbronopname.
Voor geselecteerde tabellen die incrementele opname vereisen, wordt Vereist weergegeven onder Incrementeel vernieuwen. Voor elk van deze tabellen, zie Een incrementele vernieuwing configureren voor Azure Data Lake-gegevensbronnen.
Voor geselecteerde tabellen waarvoor geen primaire sleutel is gedefinieerd, wordt Vereist weergegeven onder Primaire sleutel. Voor elk van deze tabellen:
- Selecteer Vereist. Het deelvenster Tabel bewerken wordt weergegeven.
- Kies de primaire sleutel. De primaire sleutel is een kenmerk dat uniek is voor de tabel. Als een kenmerk een geldige primaire sleutel is, mag het geen dubbele waarden, ontbrekende waarden of null-waarden bevatten. Kenmerken van het gegevenstype string, integer en GUID worden ondersteund als primaire sleutels.
- Wijzig eventueel het partitiepatroon.
- Selecteer Sluiten om het deelvenster op te slaan en te sluiten.
Selecteer Save. De pagina Gegevensbronnen wordt geopend met de nieuwe gegevensbron met de status Vernieuwen.
Tip
Er zijn statussen voor taken en processen. De meeste processen zijn afhankelijk van andere upstreamprocessen, zoals de vernieuwing van gegevensbronnen en gegevensprofilering.
Selecteer de status om het deelvenster Details van voortgang te openen en de voortgang van de taken te bekijken. Als u de taak wilt annuleren, selecteert u Taak annuleren onder aan het deelvenster.
Onder elke taak kunt u Zie details selecteren voor meer voortgangsinformatie, zoals verwerkingstijd, de laatste verwerkingsdatum en eventuele toepasselijke fouten en waarschuwingen die verband houden met de taak of het proces. Selecteer Systeemstatus weergeven onder aan het deelvenster om andere processen in het systeem te zien.
Het laden van gegevens kan enige tijd vergen. Na een succesvolle vernieuwing kunnen de opgenomen gegevens worden bekeken vanaf de pagina Gegevens>Tabellen.
Een Azure Data Lake Storage-gegevensbron bewerken
U kunt de optie Verbinding maken met een opslagaccount met bijwerken. Zie Verbinding met een Azure Data Lake Storage-account maken met een Microsoft Entra-service-principal voor meer informatie. Als u verbinding wilt maken met een andere container dan uw opslagaccount, of de accountnaam wilt wijzigen, moet u een nieuwe gegevensbronverbinding maken.
Ga naar Gegevens>Gegevensbronnen. Selecteer Bewerken naast de gegevensbron die u wilt bijwerken.
Wijzig (een van) de volgende gegevens:
Omschrijving
Uw opslag verbinden met en verbindingsgegevens. U kunt geen informatie over Container wijzigen bij het bijwerken van de verbinding.
Opmerking
Een van de volgende rollen moet worden toegewezen aan het opslagaccount of de container:
- Opslag-blobgegevens lezer
- Opslag-blobgegevens eigenaar
- Inzender van opslag-blobgegevens
Beheerde identiteiten gebruiken voor Azure met uw Azure Data Lake Storage ???
Private Link inschakelen als u gegevens van een opslagaccount wilt opnemen via een Azure Private Link. Zie voor meer informatie Privékoppelingen.
Selecteer Volgende.
Wijzig (een van) de volgende:
Navigeer naar een ander model.json- of manifest.json-bestand met een andere set tabellen uit de container.
Als u extra tabellen wilt toevoegen om op te nemen, selecteert u Nieuwe tabel.
Als u reeds geselecteerde tabellen wilt verwijderen als er geen afhankelijkheden zijn, selecteert u de tabel en Verwijderen.
Belangrijk
Als er afhankelijkheden zijn in het bestaande model.json- of manifest.json-bestand en de set tabellen, ziet u een foutbericht en kunt u geen ander model.json- of manifest.json-bestand selecteren. Verwijder die afhankelijkheden voordat u het model.json- of manifest.json-bestand wijzigt, of maak een nieuw gegevensbron met model.json of manifest.json dat u wilt gebruiken om te voorkomen dat u de afhankelijkheden verwijdert.
Als u de locatie van het gegevensbestand of de primaire sleutel wilt wijzigen, selecteert u Bewerken.
Zie Een incrementele vernieuwing configureren voor Azure Data Lake-gegevensbronnen als u de incrementele opnamegegevens wilt wijzigen.
Wijzig alleen de tabelnaam zodat deze overeenkomt met de tabelnaam in het .json-bestand.
Opmerking
Zorg ervoor dat de tabelnaam na opname altijd hetzelfde is als de tabelnaam in het bestand model.json of manifest.json. Customer Insights - Data valideert alle tabelnamen met model.json of manifest.json tijdens elke systeemvernieuwing. Als een tabelnaam verandert, treedt er een fout op omdat Customer Insights - Data de nieuwe tabelnaam niet kan vinden in het .json-bestand. Als een opgenomen tabelnaam per ongeluk is gewijzigd, bewerkt u de tabelnaam zodat deze overeenkomt met de naam in het .json-bestand.
Selecteer Kolommen om deze toe te voegen of te wijzigen, of om gegevensprofilering in te schakelen. Selecteer Gereed.
Selecteer Opslaan om uw wijzigingen toe te passen en terug te keren naar de pagina Gegevensbronnen.
Tip
Er zijn statussen voor taken en processen. De meeste processen zijn afhankelijk van andere upstreamprocessen, zoals de vernieuwing van gegevensbronnen en gegevensprofilering.
Selecteer de status om het deelvenster Details van voortgang te openen en de voortgang van de taken te bekijken. Als u de taak wilt annuleren, selecteert u Taak annuleren onder aan het deelvenster.
Onder elke taak kunt u Zie details selecteren voor meer voortgangsinformatie, zoals verwerkingstijd, de laatste verwerkingsdatum en eventuele toepasselijke fouten en waarschuwingen die verband houden met de taak of het proces. Selecteer Systeemstatus weergeven onder aan het deelvenster om andere processen in het systeem te zien.