Notitie
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen u aan te melden of de directory te wijzigen.
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen de mappen te wijzigen.
When you set up rules to unify your data into a customer profile, consider these best practices:
Balance time to unify vs. complete matching. Attempting to capture every possible match leads to many rules and unification taking a long time.
Add rules progressively and track the results. Remove rules that don’t improve the match result.
Deduplicate each table so that every customer is represented in a single row.
Use normalization to standardize variations in how data was entered such as Street vs. St vs. St. vs. st.
Use fuzzy matching strategically to correct typos and errors such as bob@contoso.com and bob@contoso.cm. Fuzzy matches take longer to run than exact matches. Always test to see if the extra time spent on fuzzy matching is worth the extra match rate.
Narrow the scope of matches with exact match. Make sure every rule with fuzzy conditions has at least one exact match condition.
Don’t match columns that contain heavily repeated data. Make sure fuzzy-matched columns don’t have values repeated frequently, such as a form’s default value of "Firstname."
Unification performance
Each rule takes time to run. Patterns such as comparing every table to every other table or trying to capture every possible record match can lead to long unification processing times. It also returns few if any more matches over a plan that compares each table to a base table.
The best approach is to start with a basic set of rules you know are needed, such as comparing each table to your primary table. Your primary table should be the table with the most complete and accurate data. This table should be ordered at the top in the Matching rules unification step.
Progressively add several rules and see how long the changes take to run and if your results improve. Go to Settings > System > Status and select Match to see how long deduplication and matching took for each unification run.
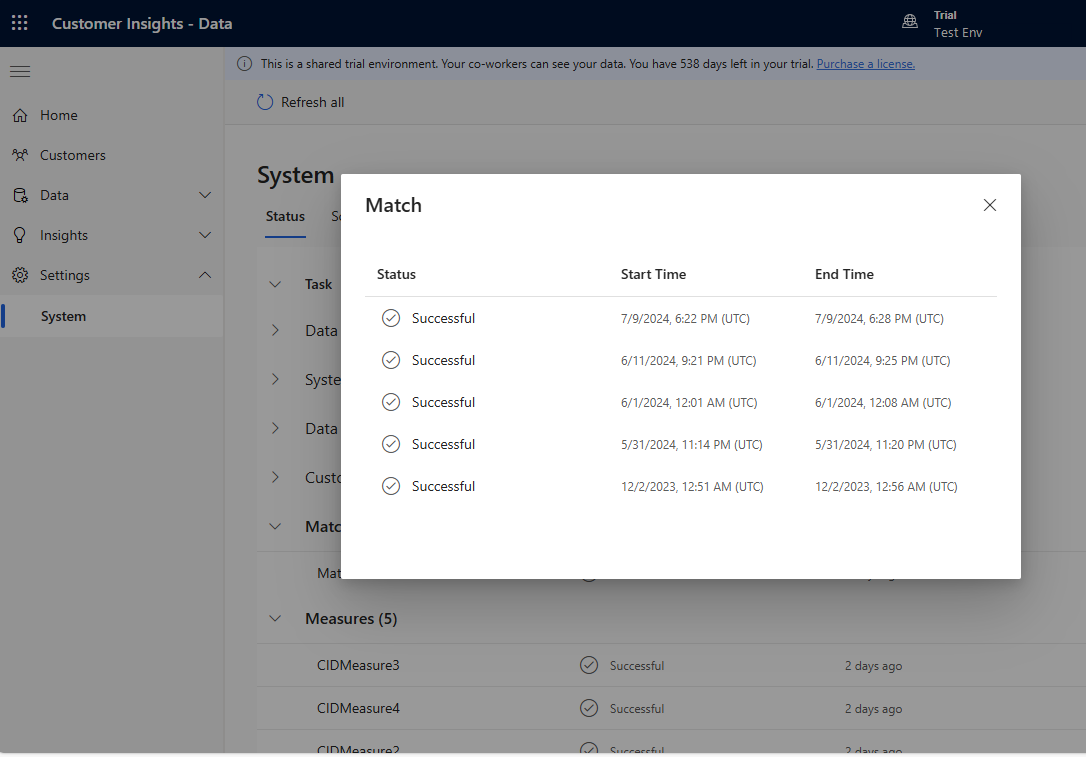
View the rule statistics on the Deduplication rules and Matching rules pages to see if the number of Unique records changes. If a new rule matches some records, and the unique record count doesn't change, then a previous rule identifies those matches.
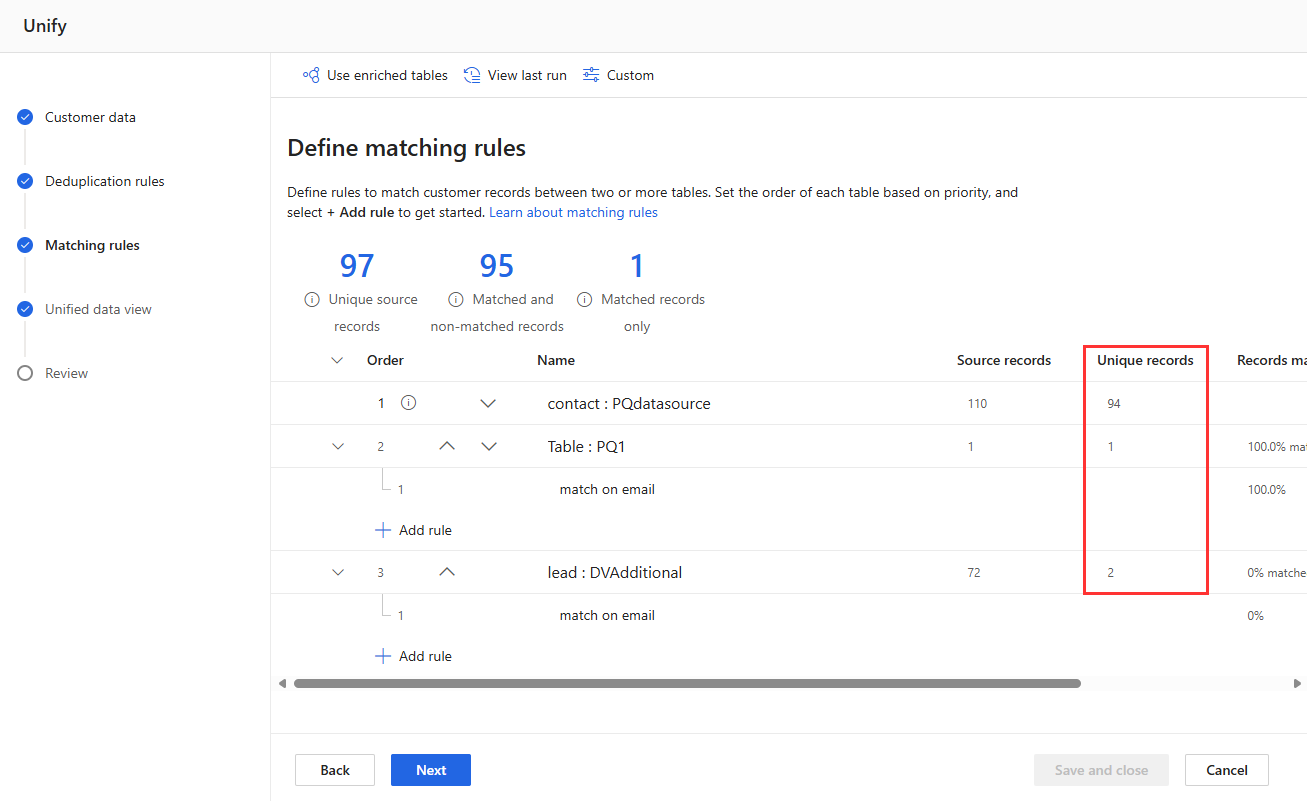
Customer data
In the Customer data step:
Exclude columns that aren't needed for matching rules or that you don't want included in the final customer profile.
Review column descriptions selected by intelligent mapping.
Not all columns need to be mapped. Mapping common columns such as email and address fields allows Customer Insights to make downstream processes easier, but columns with a unique ID or purpose to your business can be left unmapped.
Deduplication
Use deduplication rules to remove duplicate customer records within a table so that a single row in each table represents each customer. A good rule identifies a unique customer.
In this simple example, records 1, 2, and 3 share either an email or phone number, and represent the same person.
| ID | Name | Phone | |
|---|---|---|---|
| 1 | Person 1 | (425) 555-1111 | AAA@A.com |
| 2 | Person 1 | (425) 555-1111 | BBB@B.com |
| 3 | Person 1 | (425) 555-2222 | BBB@B.com |
| 4 | Person 2 | (206) 555-9999 | Person2@contoso.com |
We don’t want to match on just name as that would match different people with the same name.
Create Rule 1 using Name and Phone, which matches records 1 and 2.
Create Rule 2 using Name and Email, which matches records 2 and 3.
The combination of Rule 1 and Rule 2 creates a single match group because they share record 2.
You decide the number of rules and conditions that uniquely identify your customers. The exact rules depend on the data you have available to match, the quality of your data, and how exhaustive you want the deduplication process to be.
Normalization
Use normalization to standardize data for better matching. Normalization performs well on large sets of data.
The normalized data is only used for comparison purposes to match customer records more effectively. It doesn't change the data in the final unified customer profile output.
Exact match
Use precision to determine how close two strings should be to be considered a match. The default precision setting requires an exact match. Any other value enables fuzzy matching for that condition.
Precision can be set to low (30% match), medium (60% match), and high (80% match). Or you can customize and set the precision in 1% increments.
Exact match conditions
The exact match conditions are run first to obtain a smaller set of values for fuzzy matches. To be effective, the exact matching conditions should have a reasonable degree of uniqueness. For example, if all your customers live in the same country/region, then having an exact match on the country/region wouldn't help narrow the scope.
Columns like full name, email, phone, or address fields have good uniqueness and are great columns to use as an exact match.
Ensure the column you use for an exact match condition doesn’t have any values that are repeated frequently, such as a default value of "Firstname" captured by a form. Customer insights can profile data columns to provide insight into top repeating values. You can enable data profiling on Azure Data Lake (using Common Data Model or Delta format) connections and Synapse. The data profile is run when the data source is next refreshed. For more information, go to Data profiling.
Fuzzy matching
Use fuzzy matching to match strings that are close but aren’t exact because of typos or other small variations. Use fuzzy matching strategically as it's slower than exact matches. Make sure at least one exact match condition in any rule that has fuzzy conditions.
Fuzzy matching isn't intended to capture name variations like Suzzie and Suzanne. These variations are better captured with the Normalization pattern Type: Name or the custom Alias matching where customers can enter their list of name variations they want to consider as matches.
You can add conditions to a rule, such as matching FirstName and Phone. Conditions within a given rule are "AND" conditions. Every condition must match for the rows to match. Separate rules are "OR" conditions. If Rule 1 doesn't match the rows, then the rows are compared to Rule 2.
Note
Only string data type columns can use fuzzy matching. For columns with other data types such as integer, double, or datetime, the precision field is read-only and set to the exact match.
Fuzzy matching calculations
Fuzzy matches are determined by computing the edit distance score between two strings. If the score meets or exceeds the precision threshold, the strings are considered a match.
The edit distance is the number of edits required to turn one string into another, by adding, deleting, or changing a character.
For example, the strings "robert2020@hotmail.com" and "robrt2020@hotmail.cm" have an edit distance of two when we remove the e and o characters. To calculate the edit distance score, use this formula: (Base string length – Edit Distance) / Base string length.
| Base string | Comparison string | Score |
|---|---|---|
| robert2020@hotmail.com | robrt2020@hotmail.cm | (20 - 2)/20 = 0.9 |