Overzicht van gegevensimport- en exporttaken
Gebruik de werkruimte Gegevensbeheer om taken voor het importeren en exporteren van gegevens te maken en te beheren. Standaard wordt met het proces voor gegevensimport en -export een faseringstabel gemaakt voor elke entiteit in de doeldatabase. Met faseringstabellen kunt u gegevens verifiëren, opschonen of converteren voordat u deze verplaatst.
Notitie
Dit artikel gaat ervanuit dat u vertrouwd bent met gegevensentiteiten.
Proces voor importeren/exporteren van gegevens
Hier vindt u de stappen die u moet uitvoeren om gegevens te importeren of te exporteren.
Maak een import- of exporttaak waarbij u de volgende taken uitvoert:
- Definieer de projectcategorie.
- Identificeer de entiteiten die u wilt importeren of exporteren.
- Stel de gegevensindeling voor de taak in.
- Bepaal de volgorde van de entiteiten, zodat ze in logische groepen en in een logische volgorde worden verwerkt.
- Bepaal of u faseringstabellen wilt gebruiken.
Controleer of de bron- en doelgegevens juist zijn toegewezen.
Controleer de beveiliging voor uw import- of exporttaak.
Voer de import- of exporttaak uit.
Controleer aan de hand van de taakhistorie of de taak naar verwachting is uitgevoerd.
Schoon de faseringstabellen op.
In de overige gedeelten van dit artikel vindt u meer informatie over elke stap van het proces.
Notitie
Gebruik het pictogram voor het vernieuwen van formulieren om het formulier voor gegevensimport/-export te vernieuwen en de meest recente voortgang te bekijken. Vernieuwen op browserniveau wordt niet aanbevolen omdat hiermee import-/exporttaken worden onderbroken die niet in een batch worden uitgevoerd.
Een import- of exporttaak maken
Een taak voor het importeren of exporteren van gegevens kan één keer of meerdere keren worden uitgevoerd.
De projectcategorie definiëren
Het is raadzaam om de tijd te nemen om een juiste projectcategorie voor uw import- of exporttaak te selecteren. Met projectcategorieën kunt u gerelateerde taken beheren.
De entiteiten identificeren die u wilt importeren of exporteren
U kunt specifieke entiteiten toevoegen aan een import- of exporttaak of een sjabloon selecteren om toe te passen. Sjablonen vullen een taak met een lijst met entiteiten. De optie Sjabloon toepassen is beschikbaar als u de taak een naam geeft en opslaat.
De gegevensindeling voor de taak instellen
Wanneer u een entiteit selecteert, moet u de indeling selecteren van de gegevens die worden geëxporteerd of geïmporteerd. U definieert indelingen via de tegel Instelling van gegevensbronnen. Een brongegevensindeling is een combinatie van Type, Vestandsindeling, Scheidingsteken rij en Scheidingsteken voor kolommen. Er zijn andere kenmerken, maar dit zijn de belangrijkste. In de volgende tabel staan de geldige combinaties.
| Bestandsindeling | Scheidingsteken rij/kolom | XML-stijl |
|---|---|---|
| Excel | Excel | -N.v.t.- |
| XML | -N.v.t.- | XML-element XML-kenmerk |
| Gescheiden, vaste breedte | Komma, puntkomma, tab, verticale streep, dubbele punt | -N.v.t.- |
Notitie
Het is belangrijk dat u de juiste waarde selecteert voor Rijscheidingsteken, Kolomscheidingsteken en Tekstkwalificatie als de optie Bestandsindeling is ingesteld op Gescheiden. Zorg ervoor dat uw gegevens niet het teken bevatten dat als scheidingsteken of kwalificatie wordt gebruikt , omdat dit kan leiden tot fouten tijdens het importeren en exporteren.
Notitie
Zorg ervoor dat u alleen wettelijke tekens gebruikt voor bestandsindelingen op basis van XML. Zie Geldige tekens in XML 1.0 voor meer informatie over geldige tekens. In XML 1.0 zijn geen controletekens toegestaan, behalve tabs, regelteruglopen en nieuwe regels. Voorbeelden van ongeldige tekens zijn vierkante haakjes, accolades en backslashes.
Gebruik Unicode in plaats van een specifieke codepagina om gegevens te importeren of te exporteren. Dit helpt om de meest consistente resultaten te krijgen en voorkomt dat taken voor gegevensbeheer mislukken omdat ze Unicode-tekens bevatten. De door het systeem gedefinieerde brongegevensindelingen waarin Unicode wordt gebruikt, hebben Unicode in de bronnaam. De Unicode-indeling wordt toegepast door een Unicode-coderende ANSI-codepagina te kiezen als Codepagina op het tabblad Landinstellingen. Selecteer een van de volgende codepagina's voor Unicode:
| Codepagina | Weergavenaam |
|---|---|
| 1200 | Unicode |
| 12000 | Unicode (UTF-32) |
| 12001 | Unicode (UTF-32 Big-Endian) |
| 1201 | Unicode (Big-Endian) |
| 65000 | Unicode (UTF-7) |
| 65001 | Unicode (UTF-8) |
Zie Codepagina-id's voor meer informatie over codepagina's.
De volgorde van de entiteiten bepalen
Entiteiten kunnen worden geordend in een gegevenssjabloon of in import- en exporttaken. Wanneer u een taak met meer dan één gegevensentiteit uitvoert, moet u ervoor zorgen dat de gegevensentiteiten correct zijn geordend. U stelt voornamelijk een volgorde voor entiteiten in als er functionele afhankelijkheden tussen entiteiten bestaan. Als entiteiten geen functionele afhankelijkheden hebben, kunnen ze worden gepland voor parallel importeren of exporteren.
Uitvoeringseenheden, -niveaus en -volgordes
De uitvoeringseenheid, het niveau in de uitvoeringseenheid en de volgorde van entiteiten bepalen in welke volgorde de gegevens worden geëxporteerd of geïmporteerd.
- Entiteiten worden in elke uitvoeringseenheid parallel verwerkt.
- In elke uitvoeringseenheid worden entiteiten parallel verwerkt als ze hetzelfde niveau hebben.
- In elk niveau worden entiteiten verwerkt op basis van hun volgnummer in dat niveau.
- Nadat één niveau is verwerkt, wordt het volgende niveau verwerkt.
Opnieuw sequentiëren
In de volgende situaties kan opnieuw sequentiëren nut hebben:
- Als er slechts één gegevenstaak wordt gebruikt voor al uw wijzigingen, kunt u opties voor opnieuw sequentiëren gebruiken om de uitvoeringstijd voor de volledige taak te optimaliseren. In deze gevallen kunt u de uitvoeringseenheid gebruiken voor de module, het niveau voor het functiegebied in de module en de volgorde voor de entiteit. Met deze benadering kunt u parallel werken in verschillende modules, maar u kunt ook op volgorde in een module werken. Om ervoor te zorgen dat parallelle bewerkingen lukken, moet u rekening houden met alle afhankelijkheden.
- Als er meerdere gegevenstaken worden gebruikt (bijvoorbeeld één taak voor elke module), kunt u de optie voor sequentiëren gebruiken om het niveau en de volgorde van entiteiten te wijzigen voor een optimale uitvoering.
- Als er helemaal geen afhankelijkheden zijn, kunt u entiteiten in verschillende uitvoeringseenheden sequentiëren voor maximale optimalisatie.
Het menu Opnieuw sequentiëren is beschikbaar wanneer er meerdere entiteiten zijn geselecteerd. U kunt opnieuw sequentiëren op basis van het uitvoeringsniveau, het niveau of sequentieopties. U kunt een verhoging instellen voor het opnieuw sequentiëren van de entiteiten die zijn geselecteerd. De eenheid, het niveau en/of het volgnummer dat is geselecteerd voor elke entiteit wordt bijgewerkt op basis van de opgegeven verhoging.
Sorteren
Gebruik de optie Sorteren op om de entiteitslijst op volgorde weer te geven.
Afkappen
Voor importprojecten kunt u ervoor kiezen records in de entiteiten af te kappen voorafgaand aan de import. Afkappen is handig als uw records in een schone set tabellen moeten worden geïmporteerd. Deze instelling is standaard uitgeschakeld.
Controleren of de bron- en doelgegevens juist zijn toegewezen
Toewijzing is een functie die zowel op importtaken als op exporttaken wordt toegepast.
- In de context van een importtaak wordt met toewijzing beschreven welke kolommen in het bronbestand de kolommen in de faseringstabel worden. Op deze manier kan het systeem bepalen welke kolomgegevens in het bronbestand naar welke kolom van de faseringstabel moeten worden gekopieerd.
- In de context van een exporttaak wordt met toewijzing beschreven welke kolommen van de faseringstabel (de bron) de kolommen in het doelbestand worden.
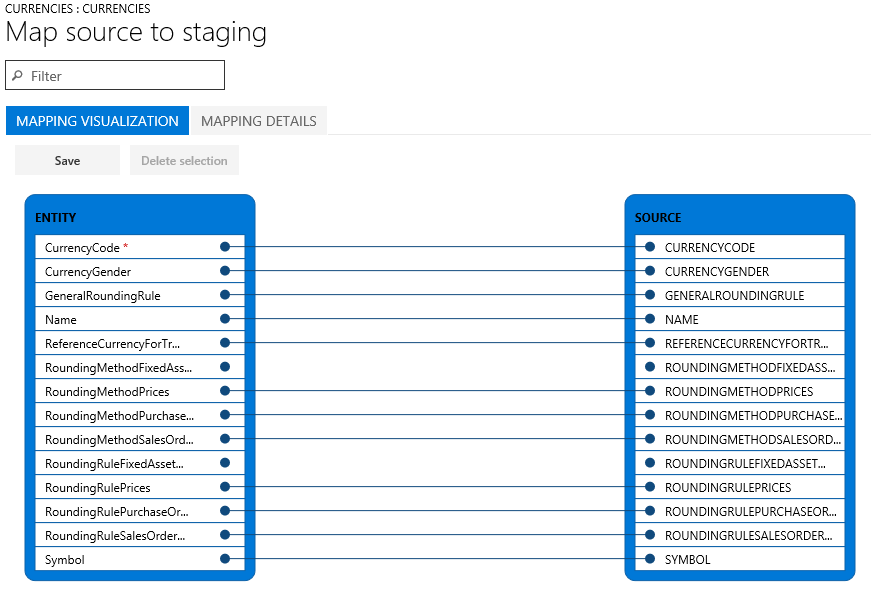
Als de kolomnamen in de faseringstabel en het bestand overeenkomen, wordt de toewijzing automatisch uitgevoerd, op basis van de namen. Als de namen afwijken, worden kolommen echter niet automatisch toegewezen. In deze gevallen moet u de toewijzing voltooien door de optie Kaart weergeven te selecteren voor de entiteit in de gegevenstaak.
Er zijn twee toewijzingsweergaven: Visualisering van toewijzing, de standaardweergave, en Gegevens toewijzen. Met een rood sterretje (*) worden de vereiste velden in de entiteit aangeduid. Deze velden moeten worden toegewezen voordat u met de entiteit kunt werken. U kunt de toewijzing van andere velden desgewenst ongedaan maken wanneer u met de entiteit werkt. Als u de toewijzing van een veld ongedaan wilt maken, selecteert u het veld in de kolom Entiteit of Bron en selecteert u vervolgens Selectie verwijderen. Selecteer Opslaan om uw wijzigingen op te slaan en sluit de pagina om terug te keren naar het project. U kunt hetzelfde proces gebruiken om de veldtoewijzingen van bron naar fasering te bewerken nadat u de import heeft uitgevoerd.
U kunt een toewijzing op de pagina genereren door Brontoewijzing maken te selecteren. Een gegenereerde toewijzing gedraagt zich als een automatische toewijzing. Daarom moet u niet-toegewezen velden handmatig toewijzen.
De beveiliging voor uw import- of exporttaak controleren
De toegang tot de werkruimte Gegevensbeheer kan worden beperkt zodat niet-beheerders alleen toegang tot bepaalde gegevenstaken krijgen. Toegang tot een gegevenstaak houdt volledige toegang tot de uitvoeringshistorie van die taak en de faseringstabellen in. Daarom moet u ervoor zorgen dat passende toegangsbeperkingen zijn ingesteld wanneer u een gegevenstaak maakt.
Een taak beveiligen op rollen en gebruikers
Gebruik het menu Toepasselijke rollen om de taak tot een of meer beveiligingsrollen te beperken. Alleen gebruikers in deze rollen hebben toegang tot de taak.
U kunt een taak ook beperken tot bepaalde gebruikers. Wanneer u een taak op basis van gebruikers beveiligt in plaats van op rollen, is er meer controle wanneer meerdere gebruikers aan een rol zijn toegewezen.
Een taak beveiligen op rechtspersoon
Gegevenstaken zijn algemeen van aard. Daarom is een taak zichtbaar in andere rechtspersonen in het systeem als een gegevenstaak in een rechtspersoon is gemaakt en gebruikt. Dit standaardgedrag kan in sommige toepassingsscenario's de voorkeur genieten. Een organisatie die facturen op basis van gegevensentiteiten importeert, kan bijvoorbeeld een centraal team voor de verwerking van facturen samenstellen dat verantwoordelijk is voor het beheren van factuurfouten voor alle divisies in de organisatie. In dit scenario is het nuttig voor het centrale team voor het verwerken van facturen om vanuit alle rechtspersonen toegang te hebben tot taken voor het importeren van facturen. Daarom voldoet het standaardgedrag aan de vereisten vanuit het perspectief van een rechtspersoon.
Een organisatie kan echter ook de voorkeur geven aan aparte factuurverwerkingsteams per rechtspersoon. In dit geval moet een team in een rechtspersoon alleen toegang hebben tot de taak voor het importeren van facturen binnen de eigen rechtspersoon. Om te voldoen aan deze vereiste, kunt u toegangsbeheer op basis van rechtspersoon voor de gegevenstaken configureren via het menu Toepasselijke rechtspersonen in de gegevenstaak. Na de configuratie krijgen gebruikers alleen taken te zien die beschikbaar zijn in de rechtspersoon waarbij ze momenteel zijn aangemeld. Als een gebruiker taken van een andere rechtspersoon wil weergeven, moet hij of zij overschakelen naar die rechtspersoon.
Een taak kan tegelijkertijd op basis van rollen, gebruikers en rechtspersoon worden beveiligd.
De import- of exporttaak uitvoeren
U kunt één taak tegelijk uitvoeren door de knop Importeren of Exporteren te selecteren nadat u de taak hebt gedefinieerd. Als u een terugkerende taak wilt instellen, selecteert u Terugkerende gegevenstaak maken.
Notitie
Een import- of een exporttaak kan worden uitgevoerd door de knop Importeren of Exporteren te selecteren. Hiermee wordt een batchtaak zo gepland dat deze slechts één keer wordt uitgevoerd. De taak wordt mogelijk niet onmiddellijk uitgevoerd als de batchservice de vertraging veroorzaakt vanwege de belasting van de batchservice. De taken kunnen ook synchroon worden uitgevoerd door Nu importeren of Nu exporteren te selecteren. Hiermee wordt de taak onmiddellijk gestart en dit is handig als de batch niet wordt gestart vanwege beperking. De taken kunnen ook op een later tijdstip worden uitgevoerd. U kunt dit doen door de optie Uitvoeren in batch te kiezen. Batchresources zijn onderworpen aan beperking, waardoor de batchtaak niet onmiddellijk wordt gestart. Het gebruik van een batch is de aanbevolen optie, omdat deze ook helpt bij grote hoeveelheden gegevens die moeten worden geïmporteerd of geëxporteerd. Batchtaken kunnen worden gepland voor uitvoering in een specifieke batchgroep, zodat u meer controle hebt vanuit taakverdelingsperspectief.
Controleren of de taak naar verwachting is uitgevoerd
De taakhistorie is beschikbaar voor het oplossen van problemen bij import- en exporttaken. Historische taakuitvoeringen worden ingedeeld op tijd.
Voor elke taakuitvoering worden de volgende gegevens weergegeven:
- Uitvoeringsdetails
- Uitvoeringslogboek
In uitvoeringsgegevens wordt de status weergegeven van elke gegevensentiteit die door de taak is verwerkt. Op deze manier kunt u snel de volgende informatie vinden:
- De entiteiten die zijn verwerkt.
- Hoeveel records voor een entiteit zijn verwerkt en hoeveel er zijn mislukt.
- De gefaseerde records voor elke entiteit.
U kunt de faseringsgegevens in een bestand voor exporttaken downloaden of u kunt de gegevens downloaden als een pakket voor import- en exporttaken.
Vanuit de uitvoeringsgegevens kunt u ook het uitvoeringslogboek openen.
Parallelle invoer
Voor een snellere import van gegevens kan een parallelle verwerking van een bestand worden ingeschakeld als de entiteit parallelle invoer ondersteunt. Als u de parallelle import voor een entiteit wilt configureren, moet u de volgende stappen volgen.
Ga naar Systeembeheer > Werkruimten > Gegevensbeheer.
Selecteer in de sectie Importeren/exporteren de tegel Raamwerkparameters om de pagina Raamwerkparameters voor het importeren/exporteren van gegevens te openen.
Selecteer op het tabblad Entiteitsinstellingen de optie Uitvoeringsparameters voor entiteit configureren om de pagina Uitvoeringsparameters voor entiteit importeren te openen.
Stel de volgende velden in om parallelle import voor een entiteit te configureren:
- Selecteer de entiteit in het veld Entiteit. Als het entiteitsveld leeg is, wordt de lege waarde gebruikt als standaardinstelling voor alle volgende importen, als de entiteit parallelle import ondersteunt.
- Voer in het veld Drempel voor records importeren het drempelaantal in voor records importeren. Hiermee wordt het aantal records bepaald dat door een thread moet worden verwerkt. Als een bestand 10.000 records bevat, wordt met een recordaantal van 2500 met het taakaantal van 4 bedoeld dat elke thread 2500 records verwerkt.
- Voer in het veld Taakaantal importeren het aantal importtaken in. Het aantal mag niet hoger zijn dan het maximum aantal batchthreads dat is toegewezen voor batchverwerking in Systeembeheer >Serverconfiguratie.
Opmerking
Als u te veel parallelle taken toevoegt, gebruikt de onderliggende infrastructuur de resourcecapaciteit van 100% en heeft deze gevolgen voor de prestaties van de omgeving en andere bewerkingen. Er wordt voorgesteld dat u de resourcecapaciteit van de omgeving en het verbruik begrijpt op basis van de parallelle importtaken die zijn geconfigureerd en het aantal taken beperken.
Taakgeschiedenis opschonen
Standaard worden taakgeschiedenisitems en gerelateerde faseringstabelgegevens die ouder zijn dan 90 dagen automatisch verwijderd. De functie voor het opschonen van taakgeschiedenis in gegevensbeheer kan worden gebruikt om periodieke opschoning van de uitvoeringsgeschiedenis te configureren met een lagere bewaarperiode dan deze standaard. Deze functionaliteit vervangt de vorige functie voor het opschonen van faseringstabellen, die nu is afgeschaft. De volgende tabellen worden door het opschoningsproces opgeschoond.
Alle faseringstabellen
DMFSTAGINGVALIDATIONLOG
DMFSTAGINGEXECUTIONERRORS
DMFSTAGINGLOGDETAIL
DMFSTAGINGLOG
DMFDEFINITIONGROUPEXECUTIONHISTORY
DMFEXECUTION
DMFDEFINITIONGROUPEXECUTION
De functie Opschoning van uitvoeringsgeschiedenis is toegankelijk via Gegevensbeheer > Opschoning van taakgeschiedenis.
Planningsparameters
Als u het opschoningsproces plant, moeten de volgende parameters worden opgegeven om de opschoningscriteria te definiëren.
Aantal dagen om historie te behouden - Deze instelling wordt gebruikt om te beheren hoeveel uitvoeringshistorie moet worden bewaard. Geschiedenis wordt in aantal dagen opgegeven. Wanneer de opschoningstaak is gepland als een terugkerende batchtaak, fungeert deze instelling als een continu bewegend venster, waarbij de geschiedenis gedurende het opgegeven aantal dagen intact blijft terwijl de rest wordt verwijderd. De standaardwaarde is zeven dagen.
Aantal uren om de taak uit te voeren: afhankelijk van de hoeveelheid geschiedenis die moet worden opgeschoond, kan de totale uitvoeringstijd voor de opschoningstaak variëren van enkele minuten tot enkele uren. Deze parameter moet worden ingesteld op het aantal uren dat de taak wordt uitgevoerd. Nadat de opschoningstaak gedurende het opgegeven aantal uren is uitgevoerd, wordt de taak afgesloten en wordt de opschoning hervat de volgende keer wanneer de taak wordt uitgevoerd op basis van het terugkeerschema.
Een maximale uitvoeringstijd kan worden opgegeven door een maximum in te stellen voor het aantal uren dat de taak met deze instelling moet worden uitgevoerd. De opschoningslogica doorloopt één taakuitvoering-id tegelijk in een chronologische volgorde, waarbij de oudste het eerst wordt opgeschoond. Er worden geen nieuwe uitvoerings-id's voor opschonen meer opgehaald wanneer de resterende uitvoeringsduur binnen de laatste 10% van de opgegeven duur is. In sommige gevallen duurt de opschoningstaak langer dan de opgegeven maximale tijd. Deze duur is grotendeels afhankelijk van het aantal records dat moet worden verwijderd voor de huidige uitvoerings-id die is gestart voordat de drempel van 10% is bereikt. De opschoning die is gestart, moet worden voltooid om de gegevensintegriteit te waarborgen, wat betekent dat opschonen ondanks overschrijding van de opgegeven limiet wordt voortgezet. Wanneer dit voltooid is, worden geen nieuwe uitvoerings-id's opgehaald en wordt de opschoningstaak voltooid. De resterende uitvoeringsgeschiedenis die door gebrek aan uitvoeringstijd niet is opgeschoond, wordt voor de volgende ingeplande opschoning opgehaald. De standaard- en minimumwaarde voor deze instelling is 2 uur.
Terugkerende batch: de opschoningstaak kan worden uitgevoerd als een eenmalige, handmatige uitvoering, of kan worden gepland voor terugkerende batchuitvoering. De batch kan worden gepland met de instellingen bij Op de achtergrond uitvoeren, de standaardinstelling voor batchuitvoering.
Notitie
Als de functie voor het opschonen van taakgeschiedenis niet wordt gebruikt, wordt de uitvoeringsgeschiedenis ouder dan 90 dagen nog steeds automatisch verwijderd. Naast deze automatische verwijdering kan het opschonen van de taakgeschiedenis worden uitgevoerd. Zorg ervoor dat de opschoningstaak herhaaldelijk wordt uitgevoerd. Zoals hierboven uitgelegd, worden bij een opschoningsuitvoering slechts zoveel uitvoerings-id's opgeschoond als mogelijk is binnen het opgegeven maximale aantal uren.
Taakgeschiedenis opschonen en archiveren
De functie voor het opschonen en archiveren van de taakgeschiedenis vervangt de vorige versies van de functionaliteit voor opschonen. In dit gedeelte worden deze nieuwe mogelijkheden uitgelegd.
Een van de belangrijkste wijzigingen in de functionaliteit voor opschonen is het gebruik van de systeembatchtaak voor het opschonen van de geschiedenis. Met het gebruik van de systeembatchtaak kunnen apps voor financiën en bedrijfsactiviteiten de batchtaak voor opschonen automatisch plannen en uitvoeren zodra het systeem gereed is. Het is niet meer nodig om de batchtaak handmatig te plannen. In deze standaarduitvoeringsmodus wordt de batchtaak elk uur uitgevoerd vanaf middernacht en wordt de uitvoeringsgeschiedenis voor de meest recente zeven dagen bewaard. De verwijderde geschiedenis wordt gearchiveerd voor toekomstige ophaalacties. Vanaf versie 10.0.20 is deze functie altijd beschikbaar.
De tweede wijziging in het opschoningsproces is het archiveren van de verwijderde uitvoeringsgeschiedenis. Met de opschoningstaak worden de verwijderde records gearchiveerd naar de blob-opslag die DIXF gebruikt voor normale integraties. Het gearchiveerde bestand heeft de DIXF-pakketindeling en is zeven dagen beschikbaar in de blob. Gedurende deze tijd kan het worden gedownload. De standaardduur van zeven dagen voor het gearchiveerde bestand kan worden ingesteld op maximaal 90 dagen in de parameters.
De standaardinstellingen wijzigen
Deze functionaliteit is momenteel in preview en moet expliciet worden ingeschakeld door de flight DMFEnableExecutionHistoryCleanupSystemJob in te schakelen. De functie voor gefaseerd opschonen moet eveneens worden ingeschakeld in functiebeheer.
Als u de standaardinstelling voor de levensduur van het gearchiveerde bestand wilt wijzigen, gaat u naar de werkruimte voor gegevensbeheer en selecteert u Taakgeschiedenis opschonen. Stel Aantal dagen om pakket te bewaren in blob in op een waarde tussen 7 en 90 (inclusief). Deze wijziging wordt toegepast op de archieven die zijn gemaakt nadat deze wijziging is aangebracht.
Het gearchiveerde pakket downloaden
Deze functionaliteit is momenteel in preview en moet expliciet worden ingeschakeld door de flight DMFEnableExecutionHistoryCleanupSystemJob in te schakelen. De functie voor gefaseerd opschonen moet eveneens worden ingeschakeld in functiebeheer.
Als u de gearchiveerde uitvoeringsgeschiedenis wilt downloaden, gaat u naar de werkruimte voor gegevensbeheer en selecteert u Taakgeschiedenis opschonen. Selecteer Back-upgeschiedenis pakket om het geschiedenisformulier te openen. Op dit formulier wordt de lijst met alle gearchiveerde pakketten weergegeven. U kunt een archief selecteren en downloaden door Pakket downloaden te selecteren. Het gedownloade pakket heeft de DIXF-pakketindeling en bevat de volgende bestanden:
- Het bestand met faseringstabellen voor entiteiten
- DMFDEFINITIONGROUPEXECUTION
- DMFDEFINITIONGROUPEXECUTIONHISTORY
- DMFEXECUTION
- DMFSTAGINGEXECUTIONERRORS
- DMFSTAGINGLOG
- DMFSTAGINGLOGDETAILS
- DMFSTAGINGVALIDATIONLOG
Gegevens van samengestelde entiteiten sorteren met behulp van xslt
Met deze functionaliteit kunt u een samengestelde entiteit exporteren en xslt-bestand toepassen op het sorteren van de gegevens in het XML-bestand.
Als u gegevens van samengestelde entiteiten wilt sorteren met xslt, volgen u deze stappen.
- Maak een xslt-bestand om de gegevens in XML-indeling te sorteren. Als u bijvoorbeeld een XSLT-bestand hebt voor de kant en klare samengestelde entiteit Inkooporders V3, kunt u de gegevens voor de XML-kenmerkindeling in volgorde sorteren op INVOICEVENDORACCOUNTNUMBER voor PURCHPURCHASEORDERHEADERV2ENTITY en order op LINENUMBER voor PURCHPURCHASEORDERLINEV2ENTITY.
<xsl:stylesheet version='1.0' xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
<xsl:template match="/*">
<xsl:copy>
<xsl:apply-templates select="@*" />
<xsl:apply-templates>
<xsl:sort select="@INVOICEVENDORACCOUNTNUMBER" data-type="text" order="ascending" />
</xsl:apply-templates>
</xsl:copy>
</xsl:template>
<xsl:template match="PURCHPURCHASEORDERHEADERV2ENTITY">
<xsl:copy>
<xsl:apply-templates select="@*"/>
<xsl:apply-templates select="*">
<xsl:sort select="@LINENUMBER" data-type="number" order="descending"/>
</xsl:apply-templates>
</xsl:copy>
</xsl:template>
<xsl:template match="@*|node()">
<xsl:copy>
<xsl:apply-templates select="@*|node()"/>
</xsl:copy>
</xsl:template>
</xsl:stylesheet>
- Ga naar het werkgebied Gegevensbeheer.
- Selecteer in de lijst Gegevensexportprojecten een project met XML-gegevensbron en selecteer Kaart weergeven.
- Selecteer Kaart weergeven voor elke entiteit.
- Ga naar het tabblad Transformaties
- Selecteer Nieuw en upload het xslt-bestand dat in stap 1 is gemaakt.