Notitie
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen u aan te melden of de directory te wijzigen.
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen de mappen te wijzigen.
Microsoft Fabric Data Engineering- en Data Science-ervaringen werken op een volledig beheerd Spark-rekenplatform. Standaard delen alle Spark-taken in een werkruimte dezelfde pool- en resource-instellingen, maar verschillende workloads hebben vaak verschillende vereisten. Een lichtgewicht gegevenstransformatie heeft niet hetzelfde stuurprogrammageheugen nodig als een grootschalige machine learning-taak.
Met infrastructuuromgevingen kunt u de Spark-rekenconfiguratie per workload aanpassen, zodat elke notebook- of Spark-taakdefinitie kan worden uitgevoerd met de juiste runtimeversie, pool en stuurprogramma/uitvoerprogramma zonder de standaardinstellingen voor de hele werkruimte te wijzigen.
Rekeninstellingen op werkruimteniveau configureren
Werkruimtebeheerders bepalen of omgevingsitems de standaardconfiguratie voor rekenkracht van de werkruimte kunnen overschrijven. Het uitschakelen van aanpassing op itemniveau zorgt voor consistent resourcegebruik in de werkruimte. Als u dit inschakelt, hebben leden en inzenders de flexibiliteit om de berekening voor afzonderlijke workloads af te stemmen.
Ga in uw browser naar uw Fabric-werkruimte in de Fabric-portal.
Selecteer Werkruimte-instellingen.
Selecteer Data Engineering/Science en selecteer vervolgens Spark-instellingen.
Selecteer het tabblad Pool .
Schakel de rekenconfiguraties aanpassen voor items in op Aan.
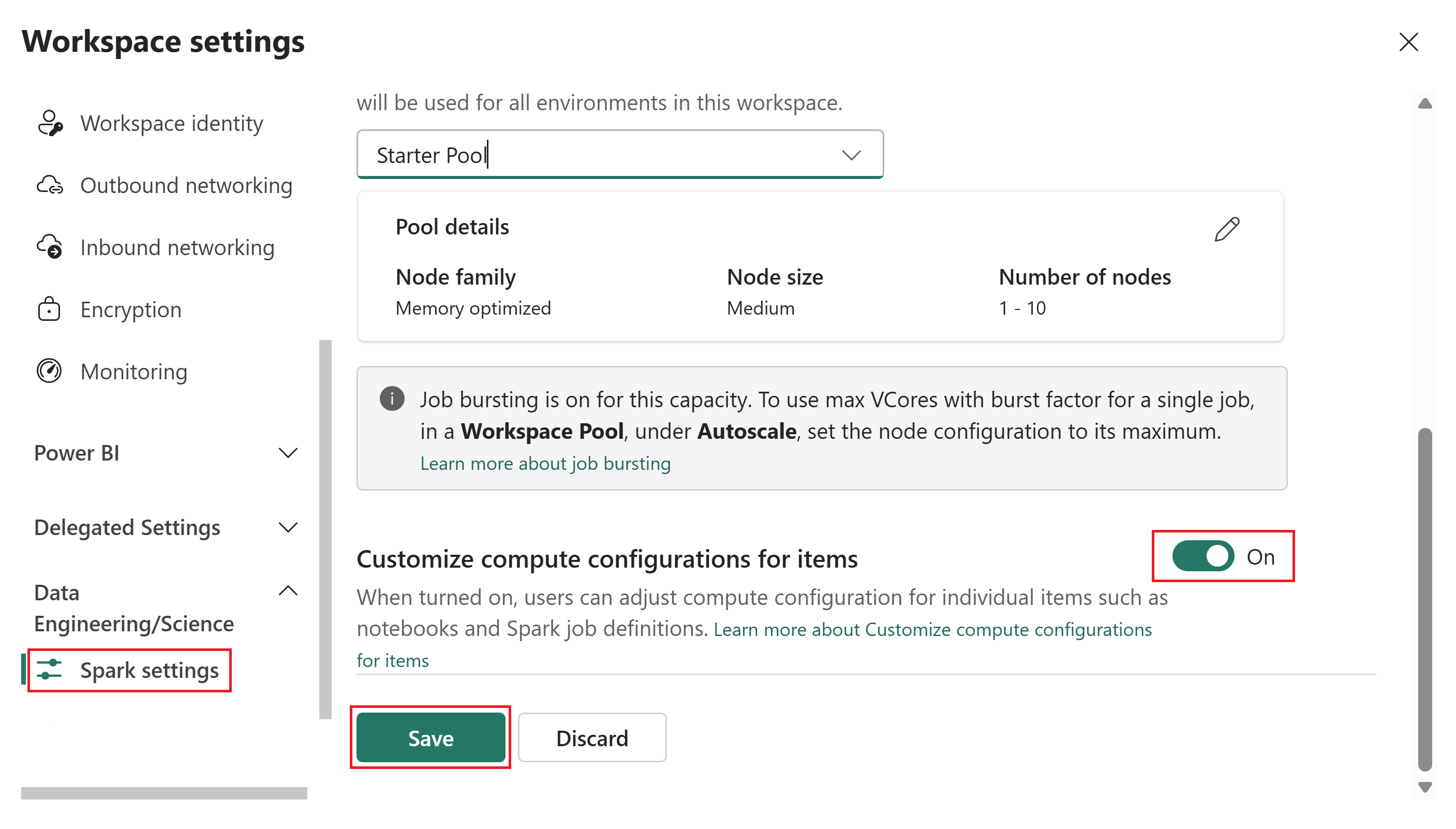
Wanneer deze wisselknop is ingeschakeld, kunnen leden en bijdragers de rekenconfiguraties op sessieniveau wijzigen in een Fabric-omgeving. Wanneer deze functie is uitgeschakeld, wordt de sectie Compute in omgevingsitems uitgeschakeld en maken alle Spark-taken gebruik van de standaardgroep van de werkruimte.
Selecteer Opslaan.

Rekenproces configureren in een omgeving
Nadat een werkruimtebeheerder aanpassing op itemniveau heeft ingeschakeld, kunt u rekeninstellingen in een omgevingsitem configureren. Dit omvat het kiezen van een Spark-runtime, het selecteren van een pool en het afstemmen van stuurprogramma's en uitvoerdersbronnen.
Een Spark-runtime selecteren
Open uw item in de omgeving.
Selecteer op het tabblad Start de vervolgkeuzelijst Runtime en kies een runtimeversie.
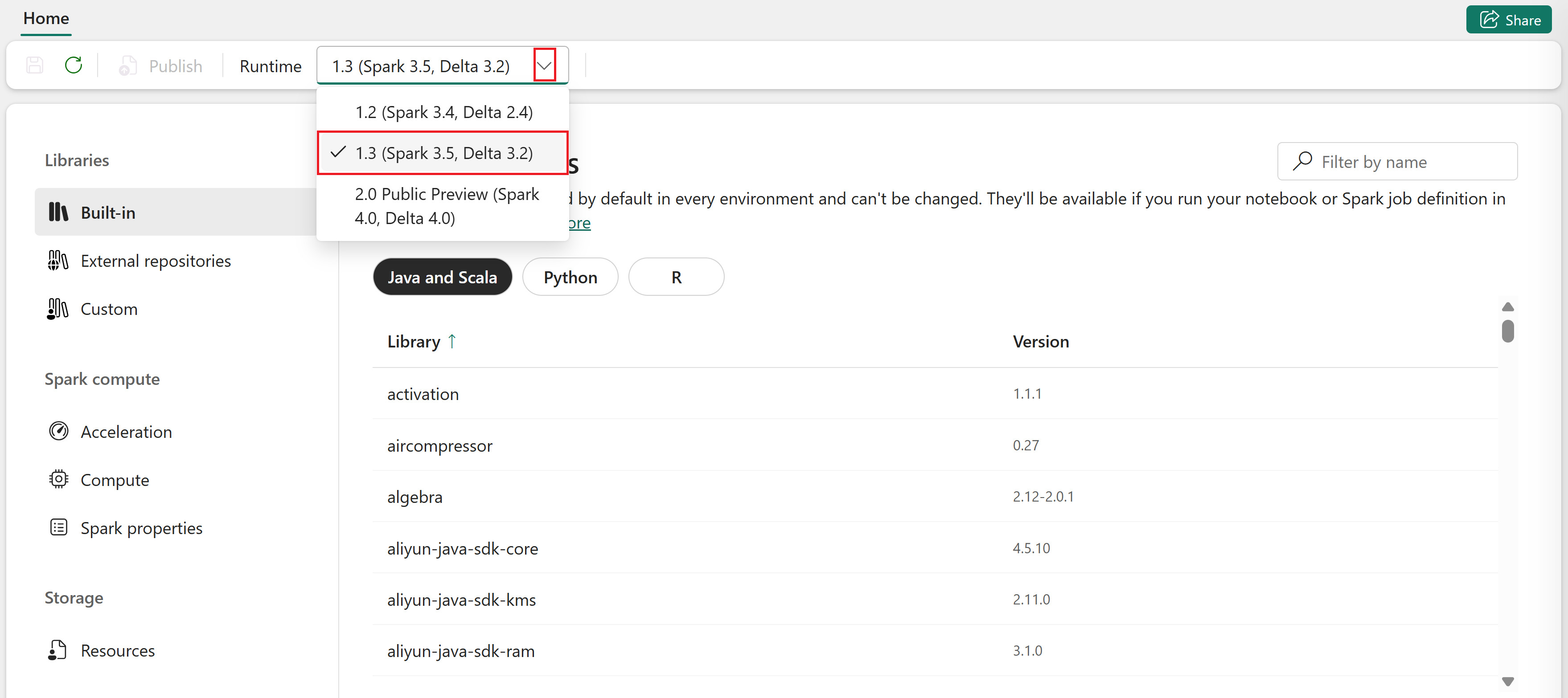

Elke Spark-runtime heeft zijn eigen standaardinstellingen en vooraf geïnstalleerde pakketten.
Belangrijk
- Runtimewijzigingen worden pas van kracht nadat u de omgeving hebt opgeslagen en gepubliceerd.
- Als bestaande bibliotheken of rekeninstellingen niet compatibel zijn met de geselecteerde runtime, mislukt het publiceren. Verwijder of werk de incompatibele instellingen bij en publiceer deze opnieuw.
- Zie Wijzigingen opslaan en publiceren voor stapsgewijze instructies.
Een pool selecteren en rekeneigenschappen afstemmen
Open de omgeving en ga naar de sectie Compute .
Selecteer onder Omgevingspool de starterspool of een aangepaste pool die is gemaakt door uw werkruimtebeheerder.

Gebruik de vervolgkeuzelijsten op de pagina Compute om Spark-eigenschappen op sessieniveau voor de geselecteerde pool te configureren. De beschikbare waarden zijn afhankelijk van de knooppuntgrootte van de pool.
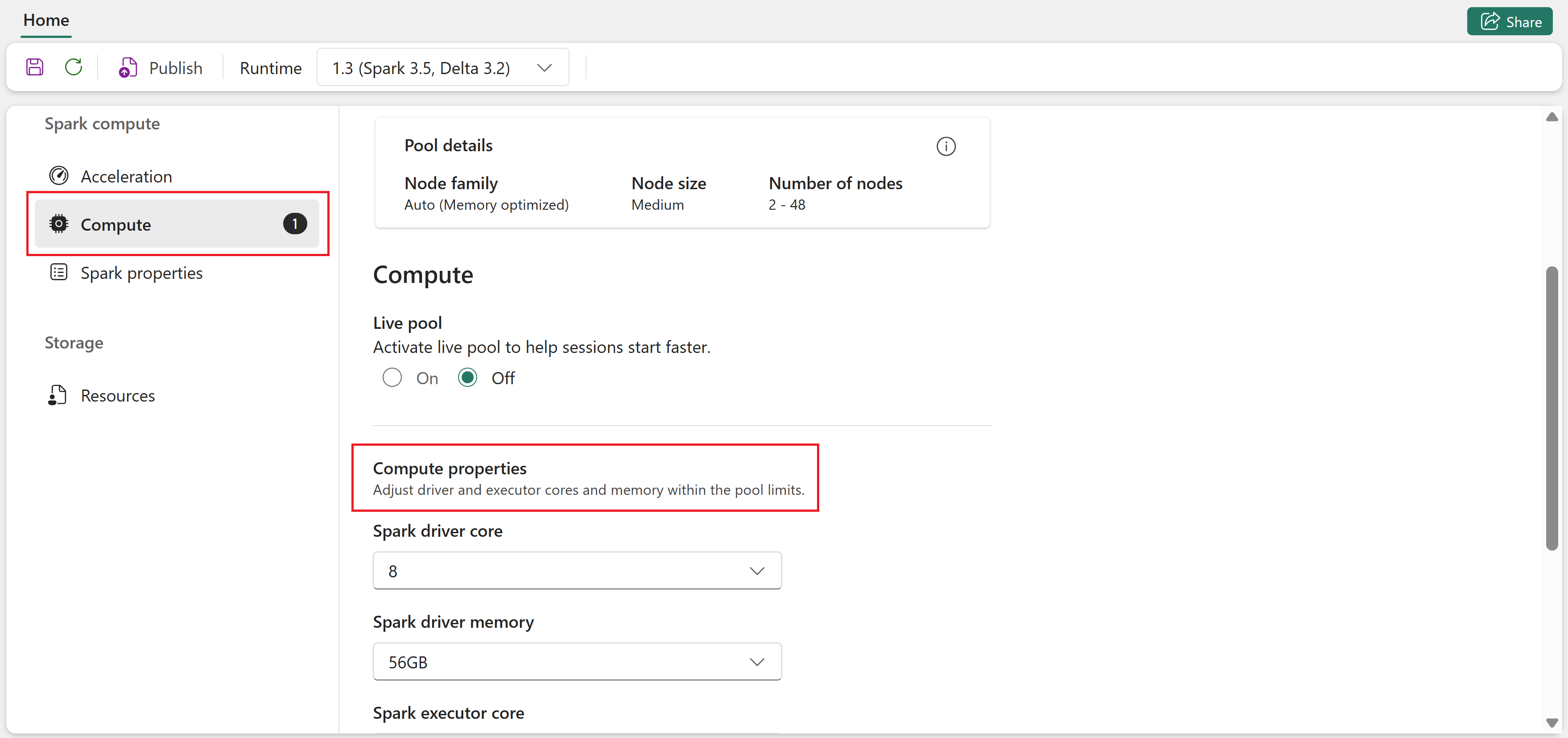
Eigenschappen zijn onder andere:
- Spark-stuurprogrammakernen : het aantal kernen dat is toegewezen aan het Spark-stuurprogramma.
- Geheugen van Spark-stuurprogramma : hoeveelheid geheugen toegewezen aan het Spark-stuurprogramma.
- Spark-uitvoerkernen : het aantal kernen dat aan elke uitvoerder is toegewezen.
- Spark-uitvoerprogramma: hoeveelheid geheugen toegewezen aan elke uitvoerder.


Zie Spark-rekenkracht in Fabric voor meer informatie over de beschikbare poolgrootten en resourcelimieten.
Opmerking
Spark-eigenschappen die zijn ingesteld via spark.conf.set parameters op toepassingsniveau en zijn niet gerelateerd aan de omgevingsrekeninstellingen die hier worden beschreven.