Notitie
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen u aan te melden of de directory te wijzigen.
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen de mappen te wijzigen.
De systeemeigen uitvoeringsengine is een baanbrekende verbetering voor uitvoeringen van Apache Spark-taken in Microsoft Fabric. Deze vectorized engine optimaliseert de prestaties en efficiëntie van uw Spark-query's door ze rechtstreeks op uw Lakehouse-infrastructuur uit te voeren. De naadloze integratie van de engine betekent dat er geen codewijzigingen nodig zijn en leveranciersafhankelijkheid wordt vermeden. Het ondersteunt Apache Spark-API's en is compatibel met Runtime 1.3 (Apache Spark 3.5) en Runtime 2.0 (Apache Spark 4.1) en werkt met Parquet-, Delta- en CSV-indelingen. Ongeacht de locatie van uw gegevens in OneLake of als u toegang hebt tot gegevens via snelkoppelingen, maximaliseert de systeemeigen uitvoeringsengine de efficiëntie en prestaties.
De systeemeigen uitvoeringsengine verhoogt de queryprestaties aanzienlijk en minimaliseert de operationele kosten. De werkelijke resultaten variëren per workloadkenmerken en configuratie. De engine is geschikt voor het beheren van een breed scala aan scenario's voor gegevensverwerking, variërend van routinegegevensopname, batchtaken en ETL-taken (extraheren, transformeren, laden) tot complexe analyse van gegevenswetenschap en responsieve interactieve query's. Gebruikers profiteren van versnelde verwerkingstijden, verhoogde doorvoer en geoptimaliseerd resourcegebruik.
De systeemeigen uitvoeringsengine is gebaseerd op twee belangrijke OSS-onderdelen: Velox, een C++ databaseversnellingsbibliotheek die is geïntroduceerd door Meta en Apache Gluten (incubating), een middelste laag die verantwoordelijk is voor het offloaden van op JVM gebaseerde SQL-engines voor de uitvoering van systeemeigen engines die door Intel zijn geïntroduceerd.
Ondersteunde operators worden verplaatst van JVM-gebaseerde Spark naar een gevectoriseerde C++-uitvoeringsroute, waardoor kolomgebaseerde, SIMD-versnelde verwerking wordt geboden met natuurlijke ondersteuning voor Parquet- en Delta-indelingen. De systeemeigen engine behoudt belangrijke Fabric Spark-queryoptimalisaties, waaronder adaptieve queryuitvoering (AQE), kosten-gebaseerd herschrijven, kolomsnoeien en predicaatpushdown, zodat dit optimalisatiegedrag volledig actief blijft wanneer operators worden uitbesteed. De engine biedt ook ondersteuning voor parallelle laadbewerkingen van Delta-momentopnamen en versnelt bewerkingen die profiteren van Z-ordering en Liquid Clustering op Delta-tabellen, waardoor er betere prestaties worden behaald voor georganiseerde gegevensindelingen.
Wanneer moet u de systeemeigen uitvoeringsengine gebruiken
De systeemeigen uitvoeringsengine biedt een oplossing voor het uitvoeren van query's op grootschalige gegevenssets; het optimaliseert de prestaties door gebruik te maken van de systeemeigen mogelijkheden van onderliggende gegevensbronnen en de overhead te minimaliseren die doorgaans samenhangt met gegevensverplaatsing en serialisatie in traditionele Spark-omgevingen. De motor ondersteunt verschillende operators en gegevenstypen, waaronder rollup hashaggregatie, uitzending geneste-lus-koppeling (BNLJ) en precieze tijdstempelformaten. Als u echter volledig wilt profiteren van de mogelijkheden van de engine, moet u rekening houden met de optimale gebruiksvoorbeelden:
- De engine is effectief bij het werken met gegevens in Parquet- en Delta-indelingen, die systeemeigen en efficiënt kunnen worden verwerkt.
- Query's die complexe transformaties en aggregaties omvatten, profiteren aanzienlijk van de mogelijkheden voor kolomverwerking en vectorisatie van de engine.
- Prestatieverbeteringen zijn het belangrijkst in scenario's waarin de query's het terugvalmechanisme niet activeren door niet-ondersteunde functies of expressies te voorkomen.
- De engine is zeer geschikt voor query's die rekenintensief zijn, in plaats van eenvoudig of I/O-gebonden.
Zie de Apache Gluten-documentatie voor informatie over de operators en functies die worden ondersteund door de systeemeigen uitvoeringsengine.
De systeemeigen uitvoeringsengine inschakelen
Voor het gebruik van de volledige mogelijkheden van de systeemeigen uitvoeringsengine tijdens de preview-fase zijn specifieke configuraties nodig. In de volgende procedures ziet u hoe u deze functie activeert voor notebooks, Spark-taakdefinities en volledige omgevingen.
Belangrijk
De systeemeigen uitvoeringsengine ondersteunt Runtime 1.3 (Apache Spark 3.5, Delta Lake 3.2) en Runtime 2.0 (Apache Spark 4.1, Delta Lake 4.1).
Inschakelen op omgevingsniveau
Om een uniforme prestatieverbetering te garanderen, schakelt u de systeemeigen uitvoeringsengine in voor alle taken en notebooks die aan uw omgeving zijn gekoppeld:
Navigeer naar de werkruimte met uw omgeving en selecteer de omgeving. Als u geen omgeving hebt gemaakt, raadpleegt u Een omgeving maken, configureren en gebruiken in Fabric.
Selecteer Acceleratie onder Spark-berekening.
Schakel het selectievakje in met het label Systeemeigen uitvoeringsengine inschakelen.
Sla de wijzigingen op en publiceer deze.
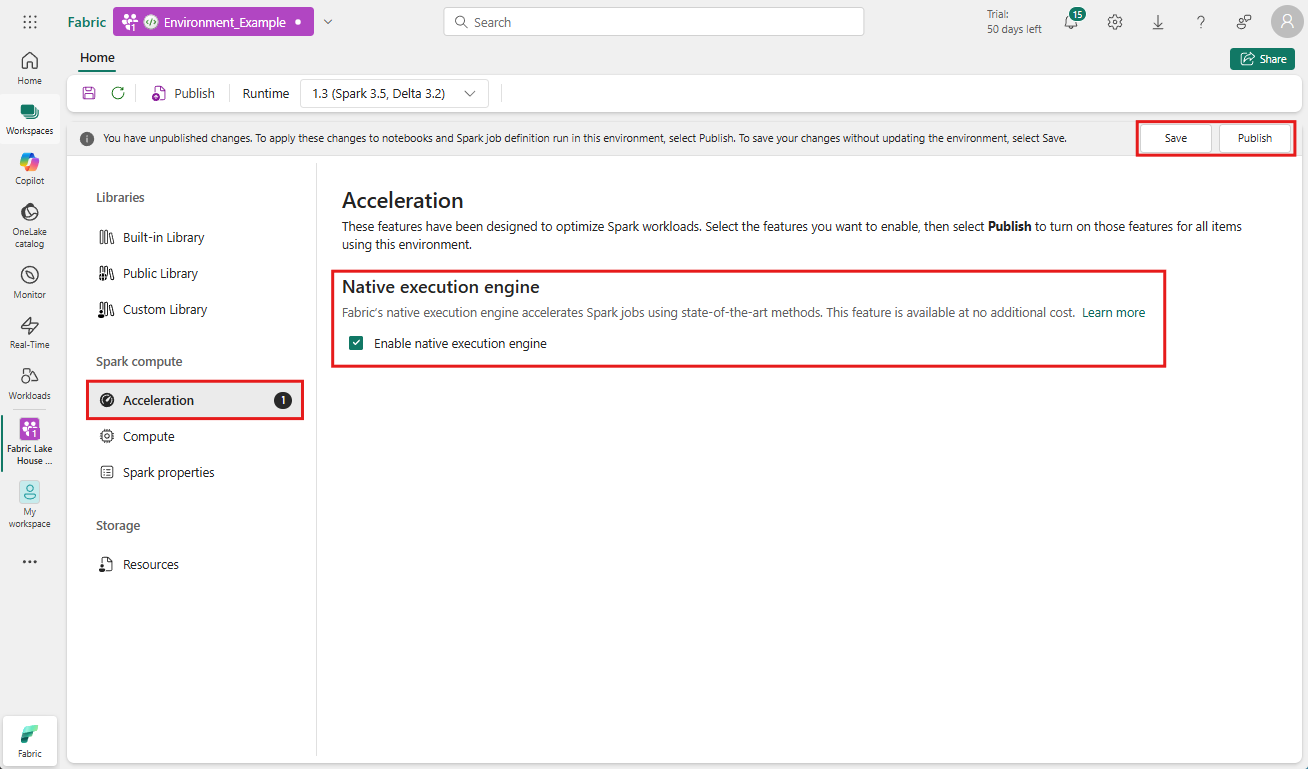

Wanneer deze optie is ingeschakeld op omgevingsniveau, nemen alle volgende taken en notebooks de instelling over. Deze overname zorgt ervoor dat nieuwe sessies of resources die in de omgeving zijn gemaakt, automatisch profiteren van de verbeterde uitvoeringsmogelijkheden.
Belangrijk
Voorheen werd de systeemeigen uitvoeringsengine ingeschakeld via Spark-instellingen binnen de omgevingsconfiguratie. De systeemeigen uitvoeringsengine kan nu eenvoudiger worden ingeschakeld met behulp van een wisselknop op het tabblad Versnelling van de omgevingsinstellingen. Als u wilt doorgaan met het gebruik, gaat u naar het tabblad Versnelling en schakelt u de wisselknop in. U kunt deze ook inschakelen via Spark-eigenschappen, indien gewenst.
Inschakelen voor een notebook- of Spark-taakdefinitie
U kunt ook de systeemeigen uitvoeringsengine inschakelen voor één notebook- of Spark-taakdefinitie. U moet de benodigde configuraties aan het begin van uw uitvoeringsscript opnemen:
%%configure
{
"conf": {
"spark.native.enabled": "true",
}
}
Voeg voor notebooks de vereiste configuratieopdrachten in de eerste cel in. Neem voor Spark-taakdefinities de configuraties op in de frontlijn van uw Spark-taakdefinitie. De systeemeigen uitvoeringsengine is geïntegreerd met livepools, dus zodra u de functie inschakelt, wordt deze onmiddellijk van kracht zonder dat u een nieuwe sessie hoeft te starten.
Controle op het queryniveau
De mechanismen voor het inschakelen van de systeemeigen uitvoeringsengine op tenant-, werkruimte- en omgevingsniveaus, naadloos geïntegreerd met de gebruikersinterface, zijn in actieve ontwikkeling. In de tussentijd kunt u de systeemeigen uitvoeringsengine uitschakelen voor specifieke query's, met name als deze operators omvatten die momenteel niet worden ondersteund (zie beperkingen). Als u dit wilt uitschakelen, stelt u de Spark-configuratie spark.native.enabled in op false voor de specifieke cel met uw query.
%%sql
SET spark.native.enabled=FALSE;

Nadat u de query hebt uitgevoerd waarin de systeemeigen uitvoeringsengine is uitgeschakeld, moet u deze opnieuw inschakelen voor volgende cellen door spark.native.enabled in te stellen op true. Deze stap is nodig omdat Spark codecellen opeenvolgend uitvoert.
%%sql
SET spark.native.enabled=TRUE;
Bewerkingen identificeren die door de engine worden uitgevoerd
Er zijn verschillende methoden om te bepalen of een operator in uw Apache Spark-taak is verwerkt met behulp van de systeemeigen uitvoeringsengine.
Spark-gebruikersinterface en Spark-geschiedenisserver
Gebruik de Spark-gebruikersinterface of de Spark-geschiedenisserver om de query te vinden die u moet inspecteren. Als u toegang wilt krijgen tot de Spark-webgebruikersinterface, gaat u naar uw Spark-taakdefinitie en voert u deze uit. Selecteer op het tabblad Uitvoeringen de ... naast de applicatienaam en selecteer Open Spark-webgebruikersinterface. U hebt ook toegang tot de Spark-gebruikersinterface via het tabblad Bewaken in de werkruimte. Selecteer het notebook of de pijplijn. Op de bewakingspagina is er een directe koppeling naar de Spark-gebruikersinterface voor actieve taken.

Zoek in het queryplan dat wordt weergegeven in de Spark UI-interface naar knooppuntnamen die eindigen op het achtervoegsel Transformer, *NativeFileScan of VeloxColumnarToRowExec. Het achtervoegsel geeft aan dat de systeemeigen uitvoeringsengine de bewerking heeft uitgevoerd. Knooppunten kunnen bijvoorbeeld worden gelabeld als RollUpHashAggregateTransformer, ProjectExecTransformer, BroadcastHashJoinExecTransformer, ShuffledHashJoinExecTransformer, of BroadcastNestedLoopJoinExecTransformer. Voor CSV-gegevensbronnen kunnen systeemeigen scans worden weergegeven als systeemeigen bestandsscan- of transformatieknooppunten in de Spark-gebruikersinterface, vergelijkbaar met Parquet- en Delta-scanknooppunten.

Uitleg van DataFrame
U kunt de df.explain() opdracht ook uitvoeren in uw notebook om het uitvoeringsplan weer te geven. Zoek in de uitvoer naar dezelfde Transformer, *NativeFileScan, of VeloxColumnarToRowExec achtervoegsels. Deze methode biedt een snelle manier om te controleren of specifieke bewerkingen worden verwerkt door de systeemeigen uitvoeringsengine.

Fabric Spark Advisor-waarschuwingen
Fabric Spark Advisor biedt realtime zichtbaarheid van de terugvaloptie tijdens het uitvoeren van notebookcellen. Wanneer een operator of plansegment terugvalt op Spark op basis van JVM in plaats van het systeemeigen pad, wordt er door Advisor rechtstreeks in de uitvoer van de notebookcel een waarschuwing weergegeven, zodat u snel niet-ondersteunde operators of configuraties kunt identificeren zonder het notebook te verlaten. U kunt deze waarschuwingen gebruiken om vast te stellen wanneer systeemeigen offload niet wordt toegepast en om te bepalen of u uw query of configuratie moet aanpassen.
Terugvalmechanisme
In sommige gevallen kan de systeemeigen uitvoeringsengine mogelijk geen query uitvoeren vanwege redenen zoals niet-ondersteunde functies. In deze gevallen valt de bewerking terug op de traditionele Spark-engine. Dit automatische terugvalmechanisme zorgt ervoor dat uw werkstroom niet wordt onderbroken.


Query's en DataFrames bewaken die door de engine worden uitgevoerd
Als u beter wilt weten hoe de engine voor systeemeigen uitvoering wordt toegepast op SQL-query's en DataFrame-bewerkingen en inzoomt op de fase- en operatorniveaus, kunt u verwijzen naar de Spark-gebruikersinterface en Spark History Server voor gedetailleerdere informatie over de uitvoering van de systeemeigen engine.
Tabblad Systeemeigen uitvoeringsengine
U kunt naar het nieuwe tabblad Gluten SQL/DataFrame navigeren om de informatie over de glutenbuild weer te geven en details over de uitvoering van query's weer te geven. De tabel Query's biedt inzicht in het aantal knooppunten dat wordt uitgevoerd op de systeemeigen engine en de knooppunten die voor elke query terugvallen op de JVM.

Queryuitvoeringsgrafiek
U kunt ook de querybeschrijving selecteren voor de visualisatie van het Apache Spark-queryuitvoeringsplan. De uitvoeringsgrafiek biedt systeemeigen uitvoeringsdetails in fasen en hun respectieve bewerkingen. Achtergrondkleuren onderscheiden de uitvoeringsengines: groen vertegenwoordigt de systeemeigen uitvoeringsengine, terwijl lichtblauw aangeeft dat de bewerking wordt uitgevoerd op de standaard-JVM-engine.

Beperkingen
Hoewel de systeemeigen uitvoeringsengine (NEE) in Microsoft Fabric de prestaties voor Apache Spark-taken aanzienlijk verbetert, heeft het momenteel de volgende beperkingen:
Bestaande beperkingen
Incompatibele Spark-functies: de systeemeigen uitvoeringsengine biedt momenteel geen ondersteuning voor gestructureerd streamen. Als niet-ondersteunde functies rechtstreeks of via geïmporteerde bibliotheken worden gebruikt, wordt de standaardengine van Spark hersteld. Python UDF's, Scala UDF's en complexe gegevenstypen (matrices, kaarten, structs) worden nu ondersteund. Zie Python UDF's, Scala UDF's en complexe gegevenstypen in de systeemeigen uitvoeringsengine voor meer informatie.
Niet-ondersteunde bestandsindelingen: query's op
JSONenXMLindelingen worden niet versneld door de systeemeigen uitvoeringsengine. Deze worden standaard teruggezet naar de reguliere Spark JVM-engine voor uitvoering. CSV wordt nu ondersteund via de gevectoriseerde CSV-parser.ANSI-modus wordt niet ondersteund: de systeemeigen uitvoeringsengine biedt geen ondersteuning voor de ANSI SQL-modus. Indien ingeschakeld, valt de uitvoering terug op de standaard Spark-engine.
Het type datumfilter komt niet overeen: als u wilt profiteren van de versnelling van de systeemeigen uitvoeringsengine, moet u ervoor zorgen dat beide zijden van een datumvergelijking overeenkomen in het gegevenstype. Neem in plaats daarvan bijvoorbeeld een
DATETIMEkolom en vergelijk deze niet met een letterlijke tekenreeks, maar zet deze expliciet om zoals weergegeven:CAST(order_date AS DATE) = '2024-05-20'
Andere overwegingen en beperkingen
Decimaal naar float-cast komt niet overeen: Bij het gieten van
DECIMALnaarFLOAT, behoudt Spark precisie door deze te converteren naar een tekenreeks en deze te parseren. NEE (via Velox) voert een directe cast uit van de interneint128_trepresentatie, wat kan leiden tot afronding van discrepanties.Timezone-configuratiefouten : het instellen van een niet-herkende tijdzone in Spark zorgt ervoor dat de taak mislukt onder NEE, terwijl Spark JVM deze correct verwerkt. Voorbeeld:
"spark.sql.session.timeZone": "-08:00" // May cause failure under NEEInconsistent afrondingsgedrag: de
round()functie gedraagt zich anders in NEE vanwege afhankelijkheidstd::roundvan, waardoor de afrondingslogica van Spark niet wordt gerepliceerd. Dit kan leiden tot numerieke inconsistenties bij het afronden van resultaten.Ontbrekende functie voor dubbele sleutelcontrole
map(): Wanneerspark.sql.mapKeyDedupPolicydeze is ingesteld op UITZONDERING, genereert Spark een fout voor dubbele sleutels. NEE slaat deze controle momenteel over en staat toe dat de query onjuist kan slagen.
Voorbeeld:SELECT map(1, 'a', 1, 'b'); -- Should fail, but returns {1: 'b'}Afwijking van volgorde in
collect_list()met sorteren: Bij gebruikDISTRIBUTE BYenSORT BY, behoudt Spark de elementvolgorde incollect_list(). NEE kan waarden in een andere volgorde retourneren als gevolg van willekeurige verschillen, wat kan leiden tot niet-overeenkomende verwachtingen voor volgordegevoelige logica.Tussenliggende typen komen niet overeen voor
collect_list()/collect_set(): Spark gebruiktBINARYals het tussenliggende type voor deze aggregaties, terwijl NEE gebruikmaakt van .ARRAYDeze inconsistentie kan leiden tot incompatibiliteitsproblemen tijdens het plannen of uitvoeren van query's.Beheerde privé-eindpunten die vereist zijn voor opslagtoegang: wanneer systeemeigen uitvoeringsengine (NEE) is ingeschakeld en als Spark-taken toegang proberen te krijgen tot een opslagaccount met behulp van een beheerd privé-eindpunt, moeten gebruikers afzonderlijke beheerde privé-eindpunten configureren voor zowel de Blob-eindpunten (blob.core.windows.net) als dfs-/bestandssysteemeindpunten (dfs.core.windows.net), zelfs als ze verwijzen naar hetzelfde opslagaccount. Eén eindpunt kan niet opnieuw worden gebruikt voor beide. Dit is een huidige beperking en vereist mogelijk extra netwerkconfiguratie bij het inschakelen van een systeemeigen uitvoeringsengine in een werkruimte met beheerde privé-eindpunten voor opslagaccounts.