Notitie
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen u aan te melden of de directory te wijzigen.
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen de mappen te wijzigen.
Microsoft Fabric is een geïntegreerde analyseservice waarmee u sneller inzicht krijgt in datawarehouses en big data-systemen. Gegevensvisualisatie in notebooks is een belangrijke functie waarmee u eenvoudig inzicht kunt krijgen in uw gegevens, zodat gebruikers patronen, trends en uitbijters kunnen identificeren.
Wanneer u met Apache Spark in Fabric werkt, hebt u ingebouwde opties voor het visualiseren van gegevens, waaronder grafiekfuncties voor fabric-notebooks en toegang tot populaire opensource-bibliotheken.
Met Fabric-notebooks kunt u ook tabellaire resultaten converteren naar aangepaste grafieken zonder code te schrijven, waardoor u een intuïtievere en naadloze ervaring voor gegevensverkenning mogelijk maakt.
Ingebouwde visualisatieopdracht - display() functie
Met de ingebouwde fabricvisualisatiefunctie kunt u Apache Spark DataFrames, Pandas DataFrames en SQL-queryresultaten transformeren in uitgebreide, interactieve gegevensvisualisaties.
Met de weergavefunctie kunt u PySpark en Scala Spark DataFrames of Resilient Distributed Datasets (RDD's) weergeven als dynamische tabellen of grafieken.
U kunt het aantal rijen opgeven van het gegevensframe dat wordt weergegeven. De standaardwaarde is 1000. Notebook uitvoerwidget ondersteunt het weergeven en profileren van maximaal 10000 rijen van een dataframe.

U kunt de filterfunctie op de globale werkbalk gebruiken om aangepaste regels toe te passen op uw gegevens. De filtervoorwaarde wordt toegepast op een opgegeven kolom en de resultaten worden weergegeven in de tabel- en grafiekweergaven.

De uitvoer van de SQL-instructie gebruikt standaard dezelfde uitvoerwidget met display().
Rijke tabelweergave voor dataframes
Ondersteuning voor gratis selectie in de tabelweergave
Standaard wordt de tabelweergave weergegeven wanneer u de opdracht display() gebruikt in een Fabric-notebook. De uitgebreide preview van dataframes biedt een intuïtieve gratis selectiefunctie die is ontworpen om de ervaring voor gegevensanalyse te verbeteren door flexibele, interactieve selectieopties mogelijk te maken. Met deze functie kunnen gebruikers eenvoudig navigeren en dataframes verkennen.
kolomselectie
- enkele kolom: klik op de kolomkop om de hele kolom te selecteren.
- Meerdere kolommen: Nadat u één kolom hebt geselecteerd, houdt u Shift ingedrukt en klikt u vervolgens op een andere kolomkop om meerdere kolommen te selecteren.
Rijselectie
- enkele rij: klik op een rijkop om de hele rij te selecteren.
- Meerdere rijen: Nadat u één rij hebt geselecteerd, houdt u Shift ingedrukt en klikt u vervolgens op een andere rijkop om meerdere rijen te selecteren.
voorbeeld van celinhoud: bekijk een voorbeeld van de inhoud van afzonderlijke cellen om snel en gedetailleerd te kijken naar de gegevens zonder dat u extra code hoeft te schrijven.
kolomoverzicht: Een samenvatting van elke kolom ophalen, inclusief gegevensdistributie en belangrijke statistieken, om snel inzicht te krijgen in de kenmerken van de gegevens.
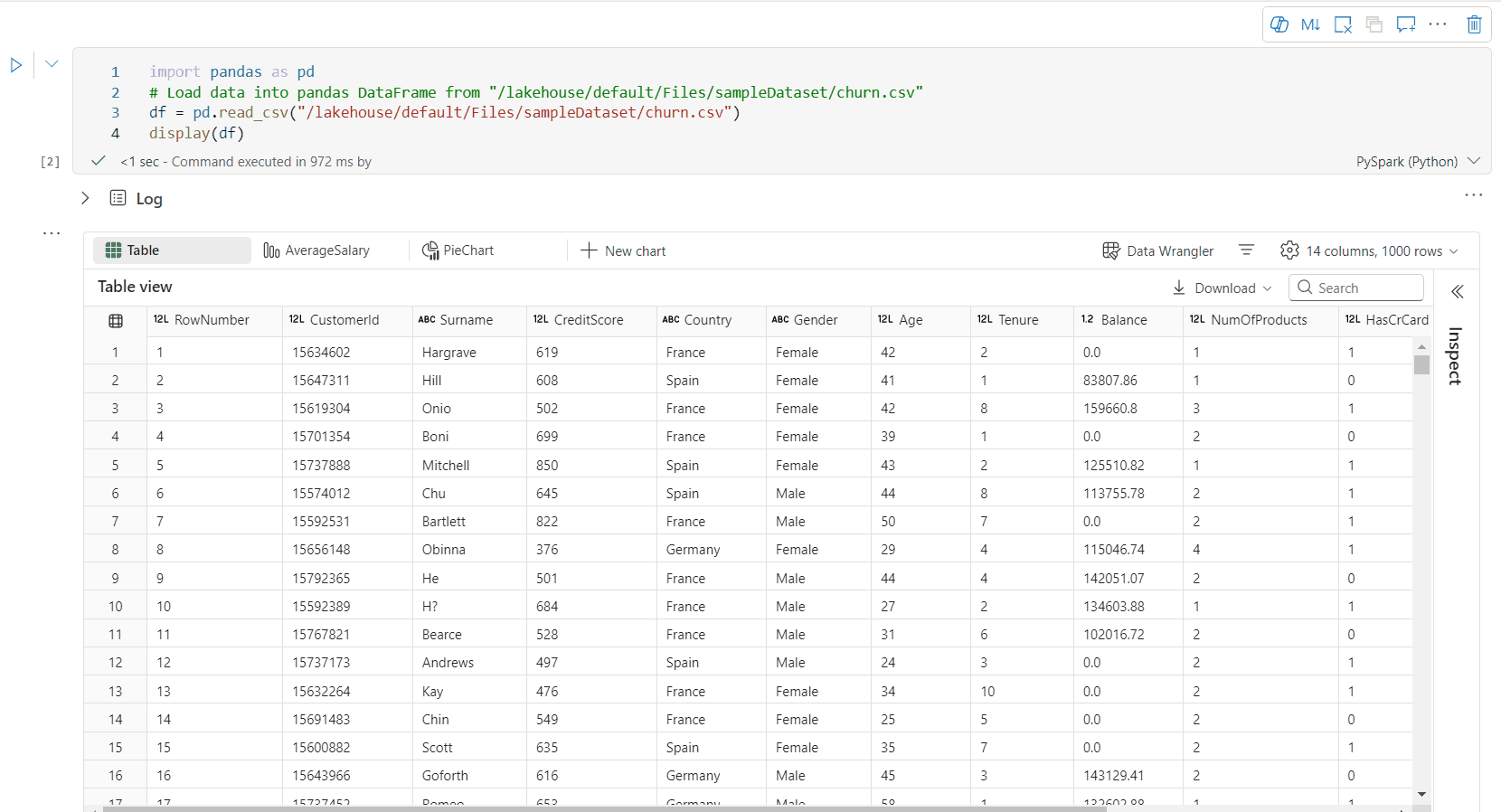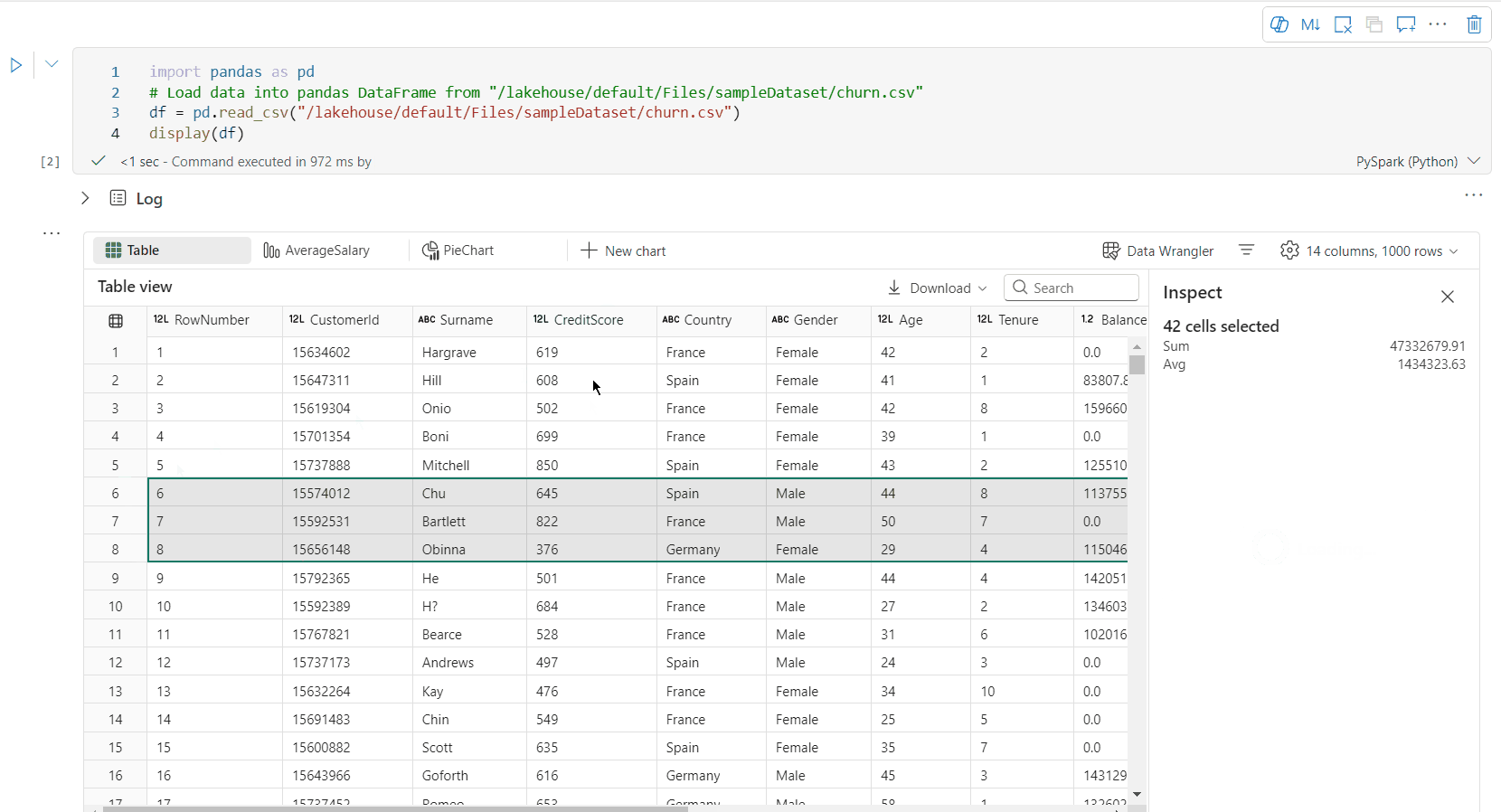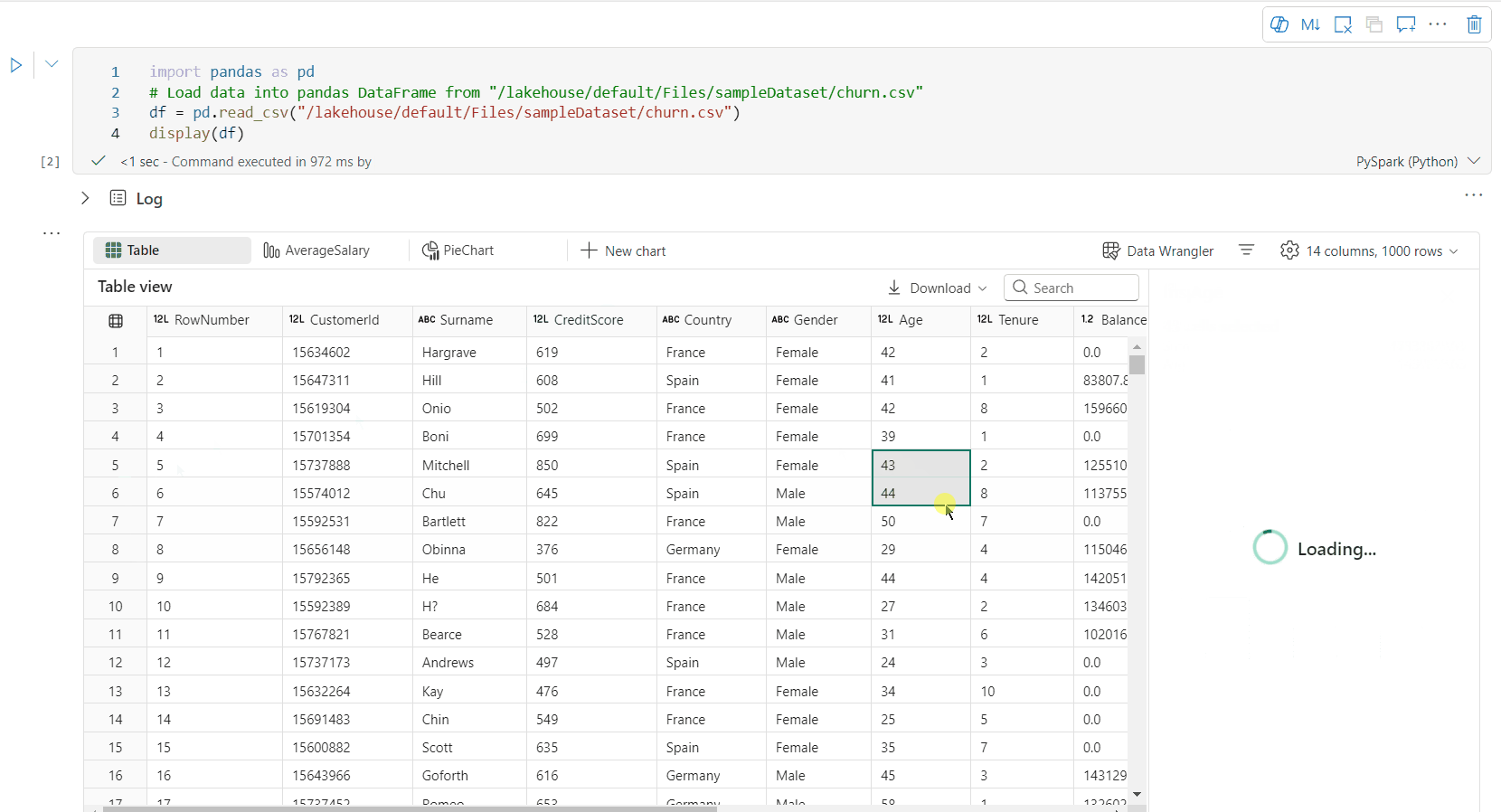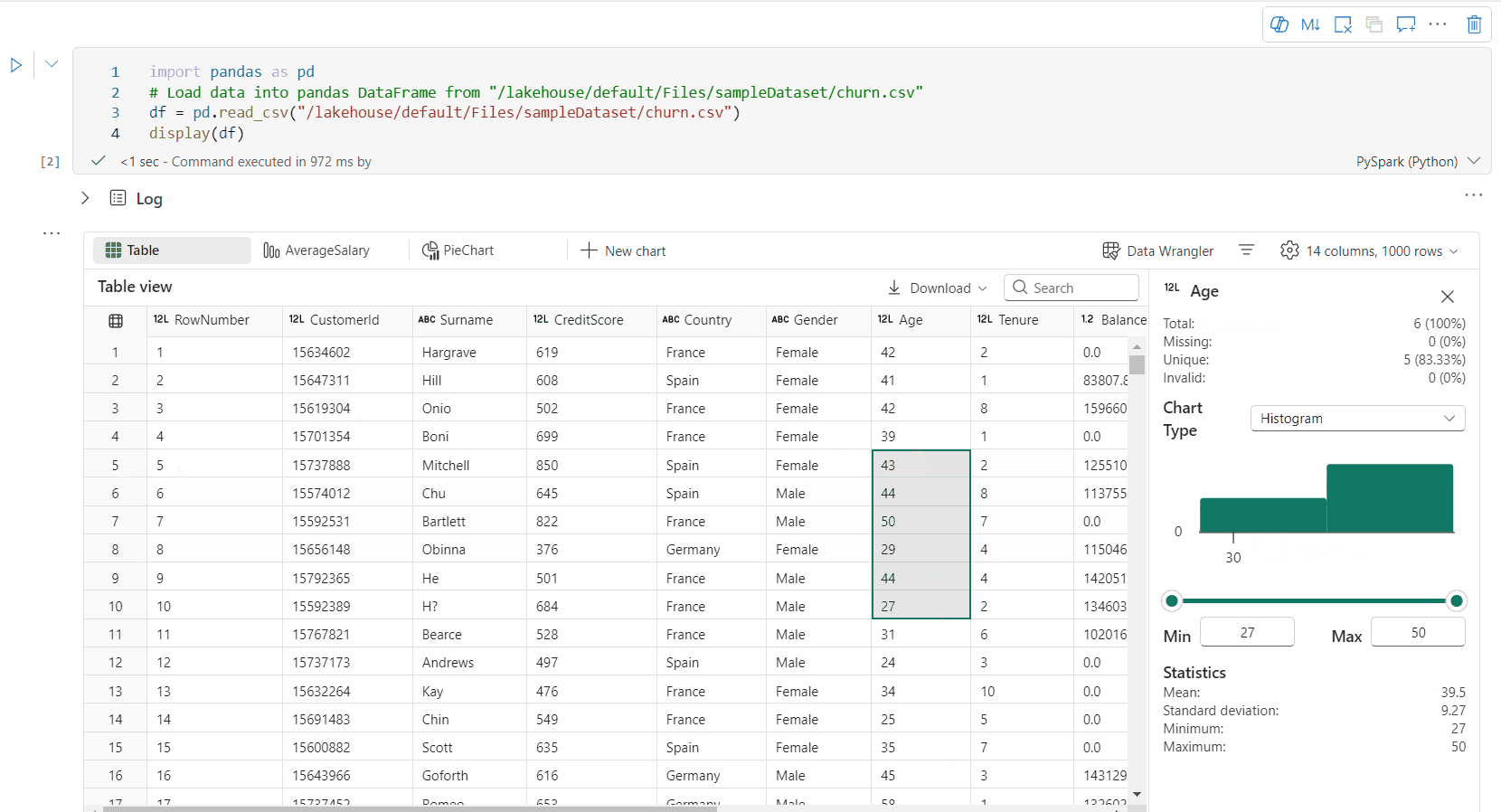
Vrije gebied selecteren: selecteer een doorlopend segment van de tabel om een overzicht te krijgen van het totale aantal geselecteerde cellen en de numerieke waarden in het geselecteerde gebied.
Geselecteerde inhoud kopiëren: in alle selectiegevallen kunt u de geselecteerde inhoud snel kopiëren met de snelkoppeling Ctrl+C. De geselecteerde gegevens worden gekopieerd in CSV-indeling, zodat u deze eenvoudig kunt verwerken in andere toepassingen.

Ondersteuning voor gegevensprofilering via het deelvenster Inspecteren

U kunt uw dataframe profileren door op de knop Controleren te klikken. Het biedt de samengevatte gegevensdistributie en geeft statistieken van elke kolom weer.
Elke kaart in het zijvenster Inspecteren wordt toegewezen aan een kolom van het gegevensframe. U kunt meer details bekijken door op de kaart te klikken of een kolom in de tabel te selecteren.
U kunt de celdetails bekijken door op de cel van de tabel te klikken. Deze functie is handig wanneer het gegevensframe lange tekenreekstypen bevat.
Uitgebreide uitgebreide gegevensframegrafiekweergave
De verbeterde grafiekweergave in de opdracht display() biedt een intuïtievere en dynamischere manier om uw gegevens te visualiseren.
Belangrijke verbeteringen:
Ondersteuning voor meerdere grafieken: Voeg maximaal vijf grafieken toe binnen één display() uitvoerwidget door Nieuwe grafiek te selecteren, waardoor eenvoudige vergelijkingen tussen verschillende kolommen mogelijk zijn.
Aanbevelingen voor slimme grafieken: bekijk een lijst met voorgestelde grafieken op basis van uw DataFrame. Kies ervoor om een aanbevolen visualisatie te bewerken of een aangepaste grafiek helemaal opnieuw te maken.

Flexibele aanpassing: pas uw visualisaties aan met aanpasbare instellingen die worden aangepast op basis van het geselecteerde grafiektype.
Categorie Basisinstellingen Beschrijving Grafiektype De weergavefunctie ondersteunt een breed scala aan grafiektypen, waaronder staafdiagrammen, spreidingsdiagrammen, lijndiagrammen, draaitabel en meer. Titel Titel De titel van de grafiek. Titel Ondertitel De ondertitel van de grafiek met meer beschrijvingen. Gegevens X-axis Geef de sleutel van de grafiek op. Gegevens Y-as Geef de waarden van de grafiek op. Legenda Legenda weergeven Schakel de legenda in of uit. Legenda Positie Pas de positie van de legenda aan. Overige Reeksgroep Gebruik deze configuratie om de groepen voor de aggregatie te bepalen. Overige aggregatie Gebruik deze methode om gegevens in uw visualisatie samen te voegen. Overige Gestapeld Configureer de weergavestijl van het resultaat. Overige Ontbrekende en NULL-waarden Configureren hoe ontbrekende of NULL-grafiekwaarden worden weergegeven. Notitie
Daarnaast kunt u het aantal weergegeven rijen opgeven met een standaardinstelling van 1000. De uitvoerwidget voor notebookweergave ondersteunt het weergeven en profileren van maximaal 10.000 rijen van een DataFrame. Selecteer Aggregatie voor alle resultaten en selecteer Vervolgens Toepassen om de grafiekgeneratie uit het hele dataframe toe te passen. Er wordt een Spark-taak geactiveerd wanneer de grafiekinstelling wordt gewijzigd. Het kan enkele minuten duren voordat de berekening is voltooid en de grafiek wordt weergegeven.
Categorie Geavanceerde instellingen Beschrijving Kleur Thema Definieer de themakleurset van de grafiek. X-axis Etiket Geef een label op de X-as op. X-axis Schaal Geef de schaalfunctie van de X-as op. X-axis Bereik Geef het waardebereik X-as op. Y-as Etiket Geef een label op de Y-as op. Y-as Schaal Geef de schaalfunctie van de Y-as op. Y-as Bereik Geef het waardebereik Y-as op. Beeldscherm Labels weergeven De resultaatlabels in de grafiek weergeven/verbergen. De wijzigingen van configuraties worden onmiddellijk van kracht en alle configuraties worden automatisch opgeslagen in notebookinhoud.
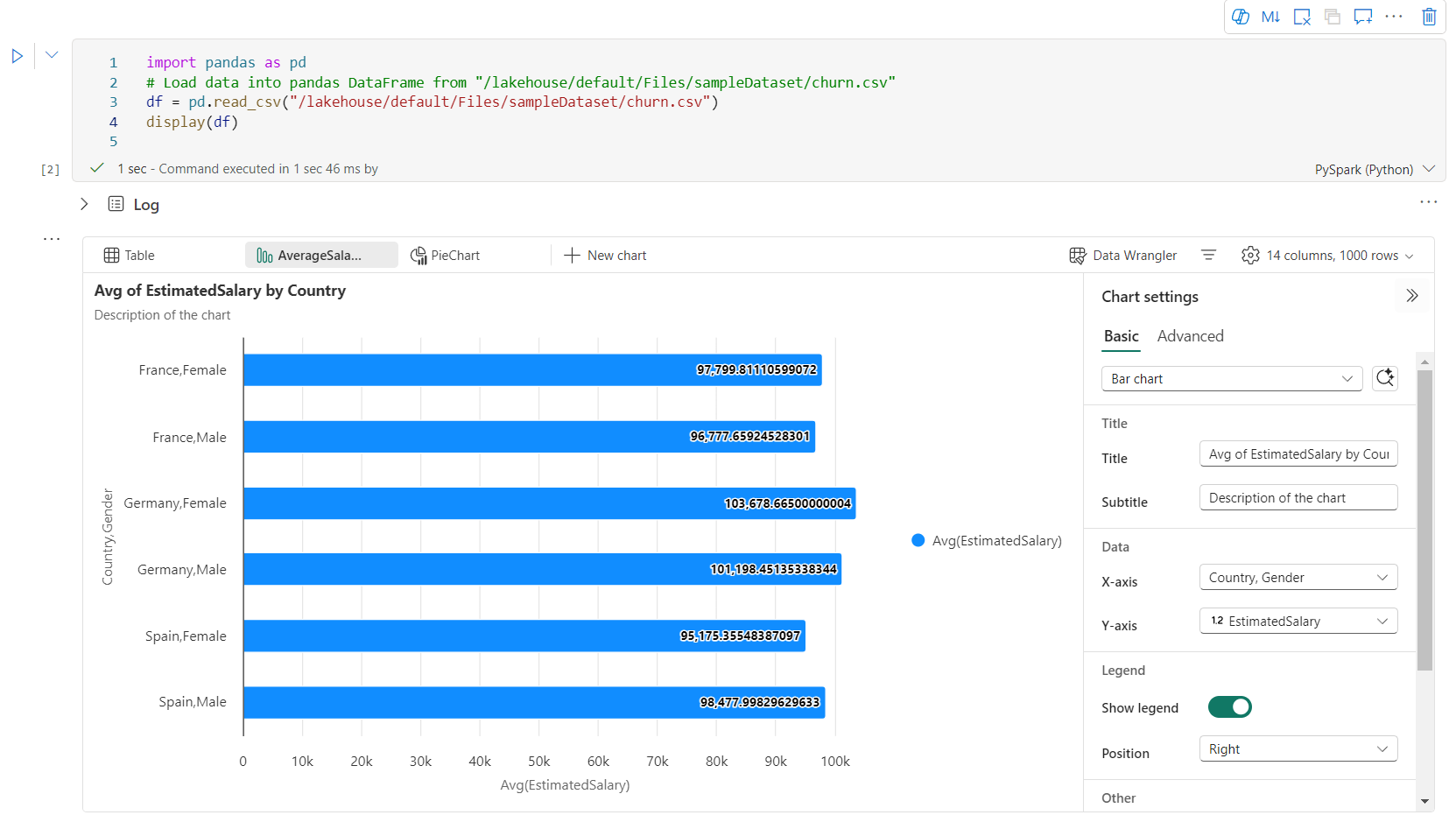
U kunt grafieken eenvoudig wijzigen, dupliceren, verwijderen of verplaatsen in het menu met grafiektabbladen. U kunt ook tabbladen slepen en neerzetten om ze opnieuw te ordenen. Het eerste tabblad wordt weergegeven als de standaardwaarde wanneer het notitieblok wordt geopend.
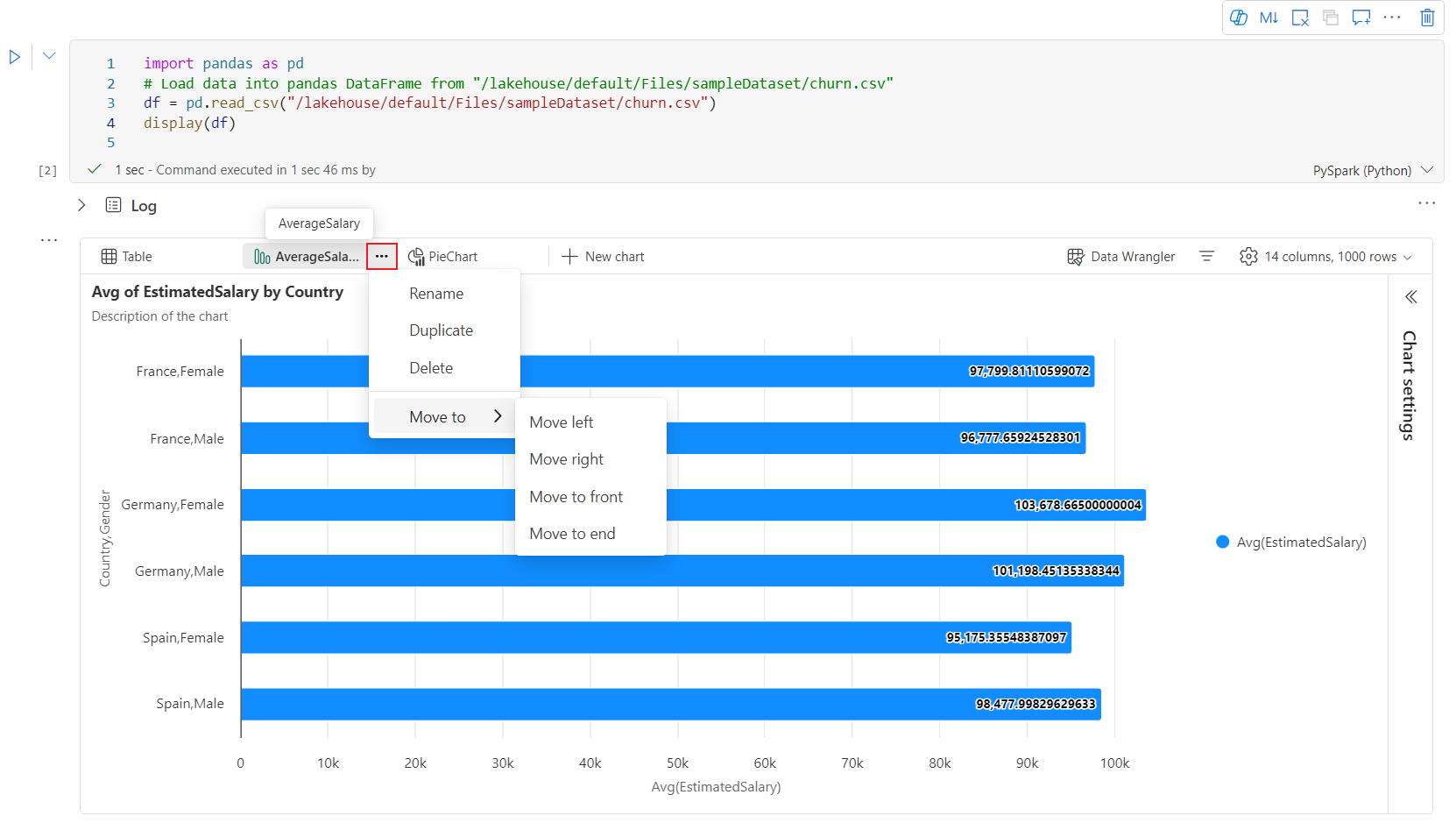
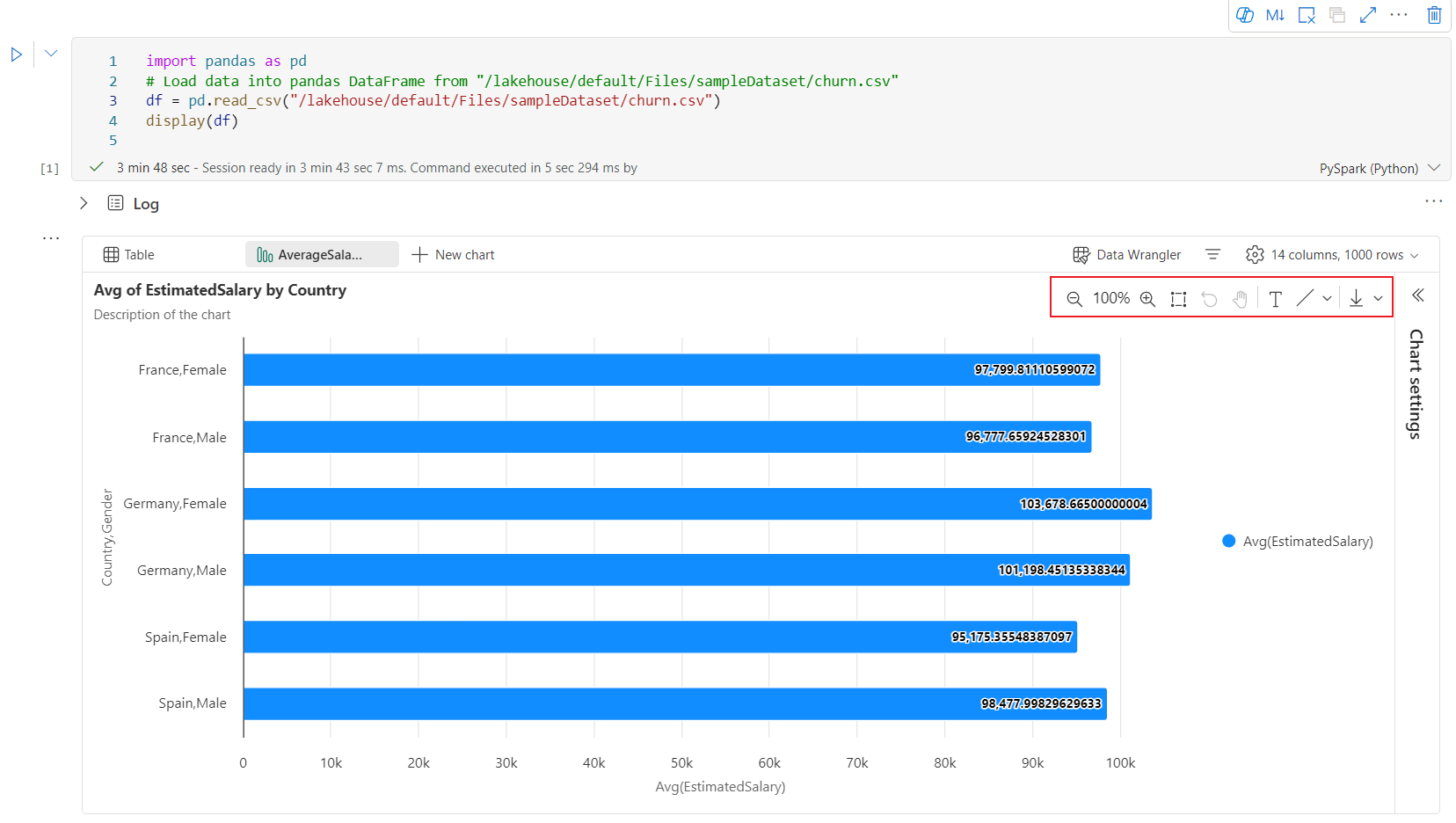
Een interactieve werkbalk is beschikbaar in de nieuwe grafiekervaring wanneer de gebruiker de muisaanwijzer op een grafiek plaatst. Ondersteuningsbewerkingen zoals inzoomen, uitzoomen, uitzoomen, in- en uitzoomen selecteren, opnieuw instellen, pannen, aantekeningen bewerken, enzovoort.
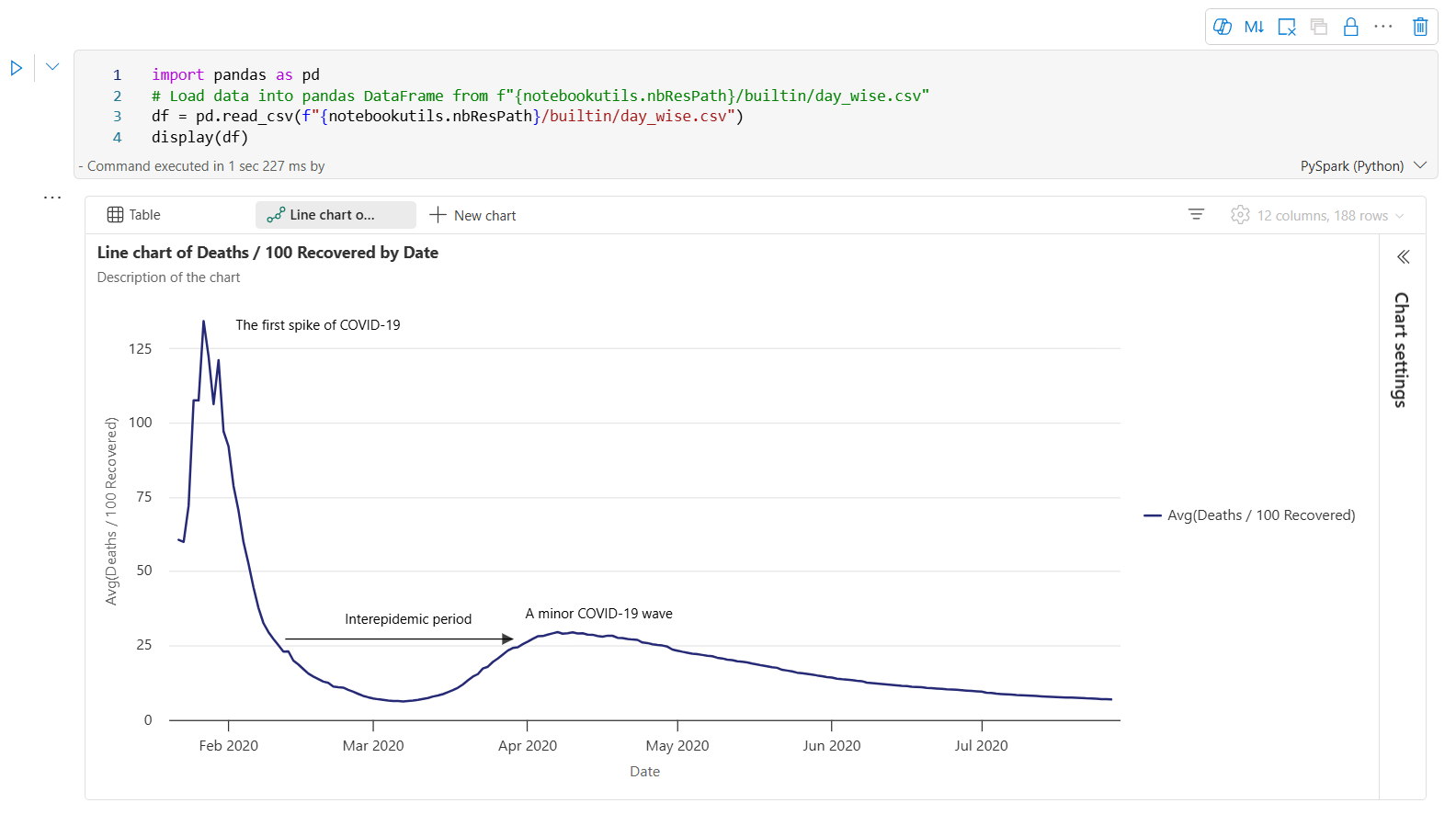
Hier volgt een voorbeeld van een grafiekaantekening.




overzicht() in samenvatting weergeven
Gebruik display(df, summary = true) om de statistiekensamenvatting van een gegeven Apache Spark DataFrame te controleren. De samenvatting bevat de kolomnaam, het kolomtype, de unieke waarden en ontbrekende waarden voor elke kolom. U kunt ook een specifieke kolom selecteren om de minimumwaarde, maximumwaarde, gemiddelde waarde en standaarddeviatie te bekijken.

Optie displayHTML()
Fabric-notebooks ondersteunen HTML-afbeeldingen met behulp van de displayHTML-functie .
De volgende afbeelding is een voorbeeld van het maken van visualisaties met behulp van D3.js.

Voer de volgende code uit om deze visualisatie te maken.
displayHTML("""<!DOCTYPE html>
<meta charset="utf-8">
<!-- Load d3.js -->
<script src="https://d3js.org/d3.v4.js"></script>
<!-- Create a div where the graph will take place -->
<div id="my_dataviz"></div>
<script>
// set the dimensions and margins of the graph
var margin = {top: 10, right: 30, bottom: 30, left: 40},
width = 400 - margin.left - margin.right,
height = 400 - margin.top - margin.bottom;
// append the svg object to the body of the page
var svg = d3.select("#my_dataviz")
.append("svg")
.attr("width", width + margin.left + margin.right)
.attr("height", height + margin.top + margin.bottom)
.append("g")
.attr("transform",
"translate(" + margin.left + "," + margin.top + ")");
// Create Data
var data = [12,19,11,13,12,22,13,4,15,16,18,19,20,12,11,9]
// Compute summary statistics used for the box:
var data_sorted = data.sort(d3.ascending)
var q1 = d3.quantile(data_sorted, .25)
var median = d3.quantile(data_sorted, .5)
var q3 = d3.quantile(data_sorted, .75)
var interQuantileRange = q3 - q1
var min = q1 - 1.5 * interQuantileRange
var max = q1 + 1.5 * interQuantileRange
// Show the Y scale
var y = d3.scaleLinear()
.domain([0,24])
.range([height, 0]);
svg.call(d3.axisLeft(y))
// a few features for the box
var center = 200
var width = 100
// Show the main vertical line
svg
.append("line")
.attr("x1", center)
.attr("x2", center)
.attr("y1", y(min) )
.attr("y2", y(max) )
.attr("stroke", "black")
// Show the box
svg
.append("rect")
.attr("x", center - width/2)
.attr("y", y(q3) )
.attr("height", (y(q1)-y(q3)) )
.attr("width", width )
.attr("stroke", "black")
.style("fill", "#69b3a2")
// show median, min and max horizontal lines
svg
.selectAll("toto")
.data([min, median, max])
.enter()
.append("line")
.attr("x1", center-width/2)
.attr("x2", center+width/2)
.attr("y1", function(d){ return(y(d))} )
.attr("y2", function(d){ return(y(d))} )
.attr("stroke", "black")
</script>
"""
)
Een Power BI-rapport insluiten in een notebook
Belangrijk
Deze functie is beschikbaar als preview-versie.
Het Python-pakket powerbiclient wordt nu systeemeigen ondersteund in Fabric-notebooks. U hoeft geen extra instellingen (zoals verificatieproces) uit te voeren in De Spark Runtime 3.4 van het Fabric-notebook. Importeer powerbiclient en ga vervolgens verder met uw verkenning. Zie de powerbiclient-documentatie voor meer informatie over het gebruik van het powerbiclient-pakket.
Powerbiclient ondersteunt de volgende belangrijke functies.
Een bestaand Power BI-rapport weergeven
U kunt eenvoudig Power BI-rapporten insluiten en ermee werken in uw notebooks met slechts een paar regels code.
De volgende afbeelding is een voorbeeld van het weergeven van een bestaand Power BI-rapport.

Voer de volgende code uit om een bestaand Power BI-rapport weer te geven.
from powerbiclient import Report
report_id="Your report id"
report = Report(group_id=None, report_id=report_id)
report
Rapportvisuals maken vanuit een Spark DataFrame
U kunt een Spark DataFrame in uw notebook gebruiken om snel inzichtelijke visualisaties te genereren. U kunt ook Opslaan selecteren in het ingesloten rapport om een rapportitem te maken in een doelwerkruimte.
De volgende afbeelding is een voorbeeld van een QuickVisualize() uit een Spark DataFrame.

Voer de volgende code uit om een rapport weer te geven vanuit een Spark DataFrame.
# Create a spark dataframe from a Lakehouse parquet table
sdf = spark.sql("SELECT * FROM testlakehouse.table LIMIT 1000")
# Create a Power BI report object from spark data frame
from powerbiclient import QuickVisualize, get_dataset_config
PBI_visualize = QuickVisualize(get_dataset_config(sdf))
# Render new report
PBI_visualize
Rapportvisuals maken op basis van een Pandas DataFrame
U kunt ook rapporten maken op basis van een Pandas DataFrame in notebook.
De volgende afbeelding is een voorbeeld van een QuickVisualize() uit een pandas DataFrame.

Voer de volgende code uit om een rapport weer te geven vanuit een Spark DataFrame.
import pandas as pd
# Create a pandas dataframe from a URL
df = pd.read_csv("https://raw.githubusercontent.com/plotly/datasets/master/fips-unemp-16.csv")
# Create a pandas dataframe from a Lakehouse csv file
from powerbiclient import QuickVisualize, get_dataset_config
# Create a Power BI report object from your data
PBI_visualize = QuickVisualize(get_dataset_config(df))
# Render new report
PBI_visualize
Populaire bibliotheken
Als het gaat om gegevensvisualisatie, biedt Python meerdere grafiekbibliotheken die zijn voorzien van veel verschillende functies. Standaard bevat elke Apache Spark-pool in Fabric een set gecureerde en populaire opensource-bibliotheken.
Matplotlib
U kunt standaardplotbibliotheken, zoals Matplotlib, weergeven met behulp van de ingebouwde renderingfuncties voor elke bibliotheek.
De volgende afbeelding is een voorbeeld van het maken van een staafdiagram met matplotlib.


Voer de volgende voorbeeldcode uit om dit staafdiagram te tekenen.
# Bar chart
import matplotlib.pyplot as plt
x1 = [1, 3, 4, 5, 6, 7, 9]
y1 = [4, 7, 2, 4, 7, 8, 3]
x2 = [2, 4, 6, 8, 10]
y2 = [5, 6, 2, 6, 2]
plt.bar(x1, y1, label="Blue Bar", color='b')
plt.bar(x2, y2, label="Green Bar", color='g')
plt.plot()
plt.xlabel("bar number")
plt.ylabel("bar height")
plt.title("Bar Chart Example")
plt.legend()
plt.show()
Bokeh
U kunt HTML- of interactieve bibliotheken, zoals bokeh, weergeven met behulp van de displayHTML(df).
De volgende afbeelding is een voorbeeld van het plotten van glyphs over een kaart met behulp van bokeh.

Voer de volgende voorbeeldcode uit om deze afbeelding te tekenen.
from bokeh.plotting import figure, output_file
from bokeh.tile_providers import get_provider, Vendors
from bokeh.embed import file_html
from bokeh.resources import CDN
from bokeh.models import ColumnDataSource
tile_provider = get_provider(Vendors.CARTODBPOSITRON)
# range bounds supplied in web mercator coordinates
p = figure(x_range=(-9000000,-8000000), y_range=(4000000,5000000),
x_axis_type="mercator", y_axis_type="mercator")
p.add_tile(tile_provider)
# plot datapoints on the map
source = ColumnDataSource(
data=dict(x=[ -8800000, -8500000 , -8800000],
y=[4200000, 4500000, 4900000])
)
p.circle(x="x", y="y", size=15, fill_color="blue", fill_alpha=0.8, source=source)
# create an html document that embeds the Bokeh plot
html = file_html(p, CDN, "my plot1")
# display this html
displayHTML(html)
Plotly
U kunt HTML- of interactieve bibliotheken, zoals Plotly, weergeven met behulp van de displayHTML().
Voer de volgende voorbeeldcode uit om deze afbeelding te tekenen.

from urllib.request import urlopen
import json
with urlopen('https://raw.githubusercontent.com/plotly/datasets/master/geojson-counties-fips.json') as response:
counties = json.load(response)
import pandas as pd
df = pd.read_csv("https://raw.githubusercontent.com/plotly/datasets/master/fips-unemp-16.csv",
dtype={"fips": str})
import plotly
import plotly.express as px
fig = px.choropleth(df, geojson=counties, locations='fips', color='unemp',
color_continuous_scale="Viridis",
range_color=(0, 12),
scope="usa",
labels={'unemp':'unemployment rate'}
)
fig.update_layout(margin={"r":0,"t":0,"l":0,"b":0})
# create an html document that embeds the Plotly plot
h = plotly.offline.plot(fig, output_type='div')
# display this html
displayHTML(h)
Pandas
U kunt HTML-uitvoer van pandas DataFrames weergeven als de standaarduitvoer. In fabric-notitieblokken wordt automatisch de vormgegeven HTML-inhoud weergegeven.

import pandas as pd
import numpy as np
df = pd.DataFrame([[38.0, 2.0, 18.0, 22.0, 21, np.nan],[19, 439, 6, 452, 226,232]],
index=pd.Index(['Tumour (Positive)', 'Non-Tumour (Negative)'], name='Actual Label:'),
columns=pd.MultiIndex.from_product([['Decision Tree', 'Regression', 'Random'],['Tumour', 'Non-Tumour']], names=['Model:', 'Predicted:']))
df