Parquet-indeling in Data Factory in Microsoft Fabric
In dit artikel wordt beschreven hoe u de Parquet-indeling configureert in de gegevenspijplijn van Data Factory in Microsoft Fabric.
Ondersteunde mogelijkheden
Parquet-indeling wordt ondersteund voor de volgende activiteiten en connectors als bron en doel.
| Categorie | Connector/activiteit |
|---|---|
| Ondersteunde connector | Amazon S3 |
| Amazon S3 compatibel | |
| Azure Blob Storage | |
| Azure Data Lake Storage Gen1 | |
| Azure Data Lake Storage Gen2 | |
| Azure Files | |
| Bestandssysteem | |
| FTP | |
| Google Cloud Storage | |
| HTTP | |
| Lakehouse Files | |
| Oracle Cloud Storage | |
| SFTP | |
| Ondersteunde activiteit | Copy-activiteit (bron/doel) |
| Activiteit Lookup | |
| GetMetadata-activiteit | |
| Activiteit verwijderen |
Parquet-indeling in kopieeractiviteit
Als u de Parquet-indeling wilt configureren, kiest u de verbinding in de bron of het doel van de kopieeractiviteit van de gegevenspijplijn en selecteert u Parquet in de vervolgkeuzelijst met de bestandsindeling. Selecteer Instellingen voor verdere configuratie van deze indeling.
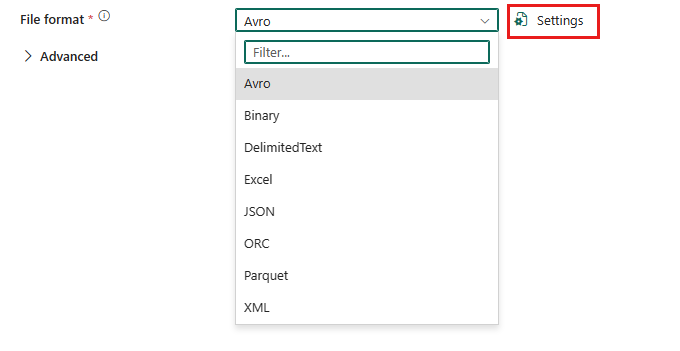
Parquet-indeling als bron
Nadat u Instellingen in de sectie Bestandsindeling hebt geselecteerd, worden de volgende eigenschappen weergegeven in het dialoogvenster Instellingen voor bestandsindeling.
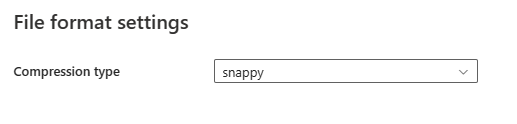
- Compressietype: kies de compressiecodec die wordt gebruikt voor het lezen van Parquet-bestanden in de vervolgkeuzelijst. U kunt kiezen uit None, gzip (.gz), snappy, lzo, Brotli (.br), Zstandard, lz4, lz4frame, bzip2 (.bz2) of lz4hadoop.
Parquet-indeling als doel
Nadat u Instellingen hebt geselecteerd, worden de volgende eigenschappen weergegeven in het dialoogvenster Instellingen voor bestandsindeling.
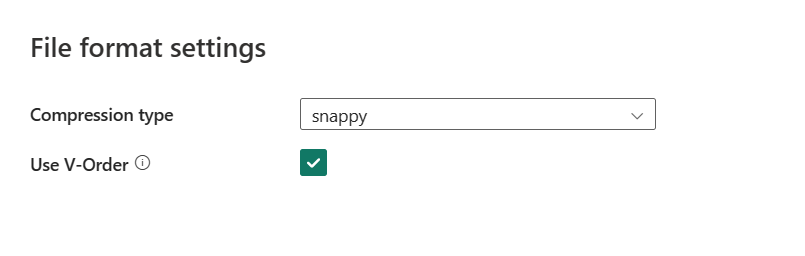
Compressietype: kies de compressiecodec die wordt gebruikt voor het schrijven van Parquet-bestanden in de vervolgkeuzelijst. U kunt kiezen uit None, gzip (.gz), snappy, lzo, Brotli (.br), Zstandard, lz4, lz4frame, bzip2 (.bz2) of lz4hadoop.
Gebruik V-Order: Schakel een optimalisatie van schrijftijd in voor de Parquet-bestandsindeling. Zie Optimalisatie van Delta Lake-tabellen en V-Order voor meer informatie. Deze functie is standaard ingeschakeld.
Onder Geavanceerde instellingen op het tabblad Bestemming worden de volgende eigenschappen met betrekking tot parquet-indeling weergegeven.
- Maximum aantal rijen per bestand: bij het schrijven van gegevens in een map kunt u ervoor kiezen om naar meerdere bestanden te schrijven en de maximumrijen per bestand op te geven. Geef de maximumrijen op die u per bestand wilt schrijven.
- Bestandsnaamvoorvoegsel: van toepassing wanneer maximumrijen per bestand is geconfigureerd. Geef het voorvoegsel voor de bestandsnaam op bij het schrijven van gegevens naar meerdere bestanden, wat resulteert in dit patroon:
<fileNamePrefix>_00000.<fileExtension>Als dit niet is opgegeven, wordt het voorvoegsel van de bestandsnaam automatisch gegenereerd. Deze eigenschap is niet van toepassing wanneer de bron een archief is op basis van bestanden of een partitieoptie ingeschakeld gegevensarchief.
Tabelsamenvatting
Parquet als bron
De volgende eigenschappen worden ondersteund in de sectie Bron van kopieeractiviteit wanneer u de Parquet-indeling gebruikt.
| Name | Beschrijving | Waarde | Vereist | JSON-scripteigenschap |
|---|---|---|---|---|
| Bestandsindeling | De bestandsindeling die u wilt gebruiken. | Parquet | Ja | type (onder datasetSettings):Parquet |
| Compressietype | De compressiecodec die wordt gebruikt om Parquet-bestanden te lezen. | Kies uit: Geen gzip (.gz) bits lzo Brotli (.br) Zstandard lz4 lz4frame bzip2 (.bz2) lz4hadoop |
Nee | compressionCodec: gzip bits lzo brotli zstd lz4 lz4frame bz2 lz4hadoop |
Parquet als bestemming
De volgende eigenschappen worden ondersteund in de sectie Doel van de kopieeractiviteit wanneer u de Parquet-indeling gebruikt.
| Name | Beschrijving | Waarde | Vereist | JSON-scripteigenschap |
|---|---|---|---|---|
| Bestandsindeling | De bestandsindeling die u wilt gebruiken. | Parquet | Ja | type (onder datasetSettings):Parquet |
| V-order gebruiken | Een optimalisatie van schrijftijd naar de Parquet-bestandsindeling. | geselecteerd of niet geselecteerd | Nee | enableVertiParquet |
| Compressietype | De compressiecodec die wordt gebruikt voor het schrijven van Parquet-bestanden. | Kies uit: Geen gzip (.gz) bits lzo Brotli (.br) Zstandard lz4 lz4frame bzip2 (.bz2) lz4hadoop |
Nee | compressionCodec: gzip bits lzo brotli zstd lz4 lz4frame bz2 lz4hadoop |
| Maximum aantal rijen per bestand | Wanneer u gegevens in een map schrijft, kunt u ervoor kiezen om naar meerdere bestanden te schrijven en de maximumrijen per bestand op te geven. Geef de maximumrijen op die u per bestand wilt schrijven. | <uw maximum aantal rijen per bestand> | Nee | maxRowsPerFile |
| Bestandsnaamvoorvoegsel | Van toepassing wanneer maximumrijen per bestand zijn geconfigureerd. Geef het voorvoegsel voor de bestandsnaam op bij het schrijven van gegevens naar meerdere bestanden, wat resulteert in dit patroon: <fileNamePrefix>_00000.<fileExtension> Als dit niet is opgegeven, wordt het voorvoegsel van de bestandsnaam automatisch gegenereerd. Deze eigenschap is niet van toepassing wanneer de bron een archief is op basis van bestanden of een partitieoptie ingeschakeld gegevensarchief. |
<uw bestandsnaamvoorvoegsel> | Nee | fileNamePrefix |
Gerelateerde inhoud
Feedback
Binnenkort beschikbaar: In de loop van 2024 zullen we GitHub-problemen geleidelijk uitfaseren als het feedbackmechanisme voor inhoud en deze vervangen door een nieuw feedbacksysteem. Zie voor meer informatie: https://aka.ms/ContentUserFeedback.
Feedback verzenden en weergeven voor