Notitie
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen u aan te melden of de directory te wijzigen.
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen de mappen te wijzigen.
Belangrijk
Dit is een patroon om incrementeel gegevens te verzamelen met Dataflow Gen2. Dit is niet hetzelfde als incrementeel vernieuwen. Incrementeel vernieuwen is een functie die momenteel in ontwikkeling is. Deze functie is een van de belangrijkste stemideeën op onze ideeënwebsite. U kunt stemmen op deze functie op de site Fabric Ideas.
Deze zelfstudie duurt 15 minuten en beschrijft hoe u incrementeel gegevens in een lakehouse kunt verzamelen met behulp van Dataflow Gen2.
Incrementeel het verzamelen van gegevens in een gegevensbestemming vereist een techniek om alleen nieuwe of bijgewerkte gegevens in uw gegevensbestemming te laden. Deze techniek kan worden uitgevoerd met behulp van een query om de gegevens te filteren op basis van de gegevensbestemming. Deze zelfstudie laat zien hoe u een gegevensstroom maakt om gegevens uit een OData-bron in een lakehouse te laden en hoe u een query toevoegt aan de gegevensstroom om de gegevens te filteren op basis van de gegevensbestemming.
De overzichtelijke stappen in deze handleiding zijn als volgt:
- Maak een gegevensstroom om gegevens uit een OData-bron in een lakehouse te laden.
- Voeg een query toe aan de gegevensstroom om de gegevens te filteren op basis van de gegevensbestemming.
- (Optioneel) laad gegevens opnieuw met behulp van notebooks en pijplijnen.
Vereisten
U moet een werkruimte met Microsoft Fabric hebben. Als u nog geen werkruimte hebt, raadpleegt u Een werkruimte maken. De handleiding gaat ervan uit dat je de diagramweergave in Gegevensstroom Gen2 gebruikt. Als u wilt controleren of u de diagramweergave gebruikt, gaat u in het bovenste lint naar Weergave en controleert u of Diagramweergave is geselecteerd.
Een gegevensstroom creëren om data uit een OData-bron naar een lakehouse te laden.
In deze sectie maakt u een gegevensstroom om gegevens uit een OData-bron in een lakehouse te laden.
Maak een nieuw lakehouse in uw werkruimte.
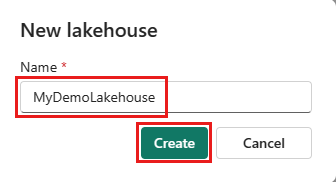
Maak een nieuwe Dataflow Gen2 in uw werkruimte.
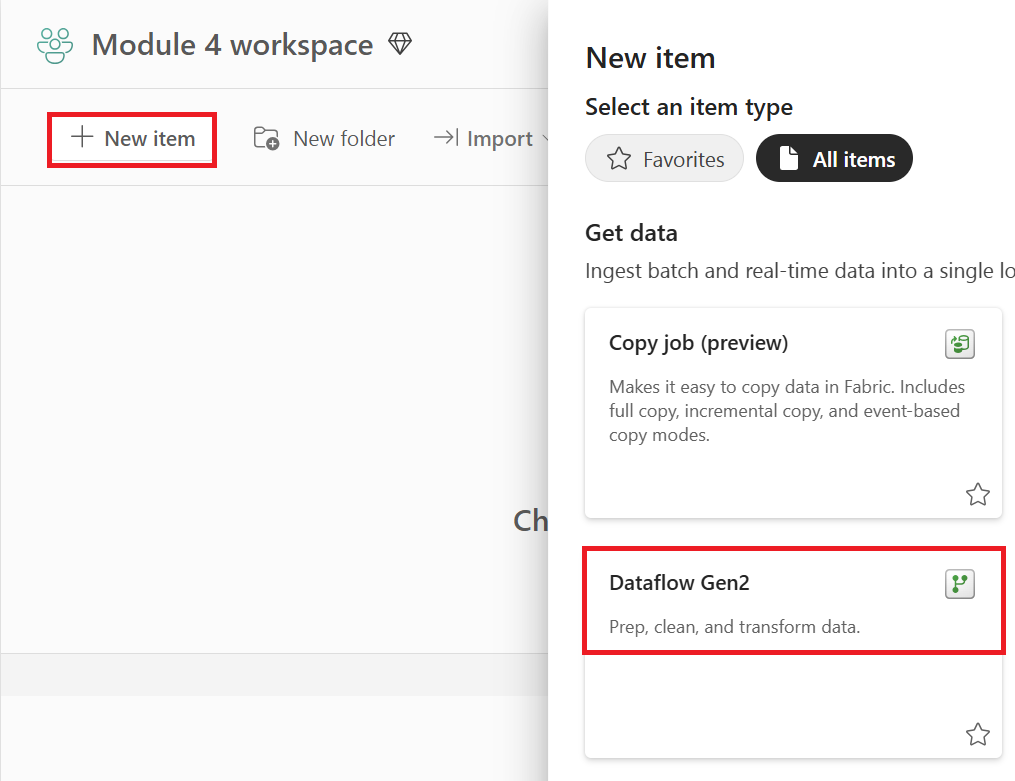
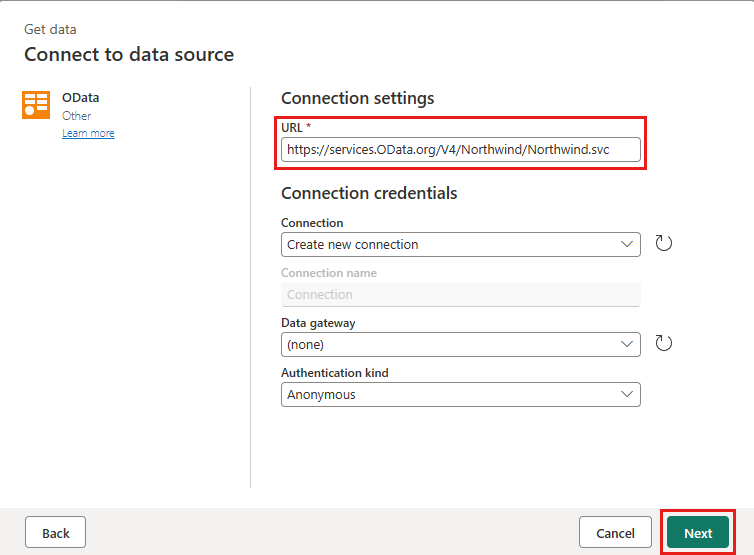
Voeg een nieuwe bron toe aan de gegevensstroom. Selecteer de OData-bron en voer de volgende URL in:
https://services.OData.org/V4/Northwind/Northwind.svc
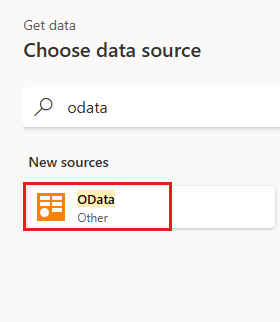
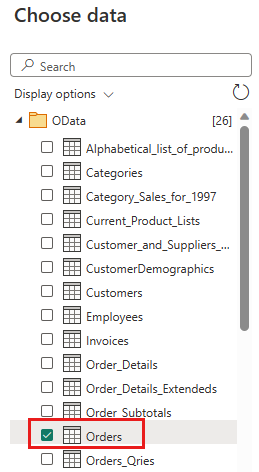
Selecteer de tabel Orders en selecteer Volgende.
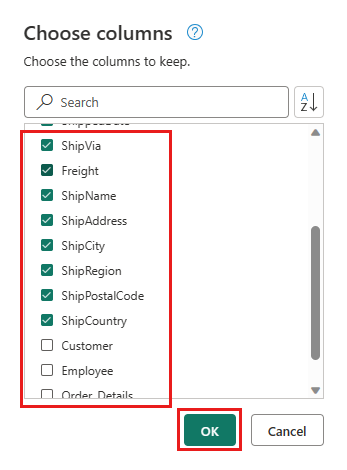
Selecteer de volgende kolommen die u wilt behouden:
OrderIDCustomerIDEmployeeIDOrderDateRequiredDateShippedDateShipViaFreightShipNameShipAddressShipCityShipRegionShipPostalCodeShipCountry
Wijzig het gegevenstype van
OrderDate,RequiredDateenShippedDateindatetime.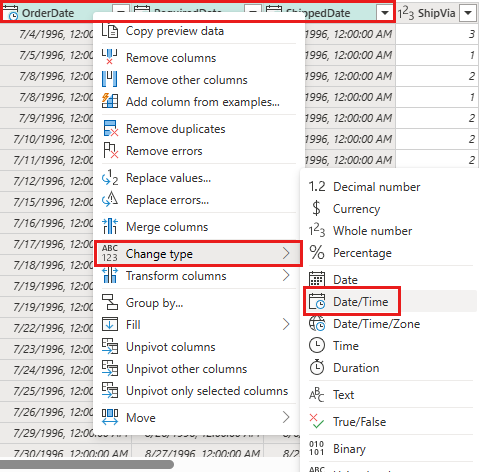
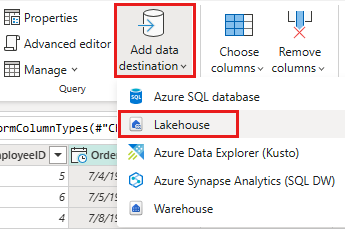
Stel de gegevensbestemming in op uw lakehouse met behulp van de volgende instellingen:
- Gegevensbestemming:
Lakehouse - Lakehouse: Selecteer het lakehouse dat u in stap 1 hebt gemaakt.
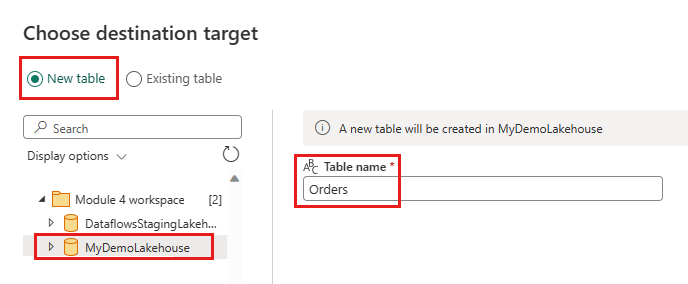
- Nieuwe tabelnaam:
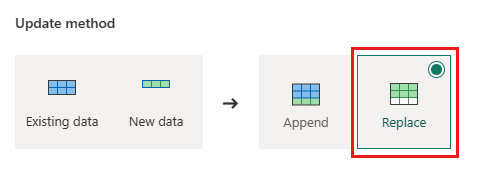
Orders - Updatemethode:
Replace
- Gegevensbestemming:
selecteer Volgende en publiceer de gegevensstroom.



Je hebt nu een dataflow gemaakt om gegevens uit een OData-bron in een lakehouse te laden. Deze gegevensstroom wordt gebruikt in de volgende sectie om een query toe te voegen aan de gegevensstroom om de gegevens te filteren op basis van de gegevensbestemming. Daarna kunt u de gegevensstroom gebruiken om gegevens opnieuw te laden met behulp van notebooks en pijplijnen.
Een query toevoegen aan de gegevensstroom om de gegevens te filteren op basis van de gegevensbestemming
In deze sectie wordt aan de gegevensstroom een query toegevoegd om de gegevens te filteren op basis van de gegevens in het doellakehouse. De query haalt het maximum OrderID op in het lakehouse aan het begin van het verversen van de datastroom en gebruikt de maximale OrderId om alleen de orders met een hogere OrderId van de bron op te halen om toe te voegen aan uw gewenste gegevenslocatie. Hierbij wordt ervan uitgegaan dat orders in een oplopende volgorde van OrderID aan de bron worden toegevoegd. Als dit niet het geval is, kunt u een andere kolom gebruiken om de gegevens te filteren. U kunt bijvoorbeeld de OrderDate kolom gebruiken om de gegevens te filteren.
Notitie
OData-filters worden toegepast in Fabric nadat de gegevens van de gegevensbron zijn ontvangen, maar voor databasebronnen zoals SQL Server wordt het filter toegepast in de query die is verzonden naar de back-endgegevensbron en worden alleen gefilterde rijen geretourneerd naar de service.
Nadat de gegevensstroom is vernieuwd, heropent u de gegevensstroom die u in de vorige sectie hebt gemaakt.
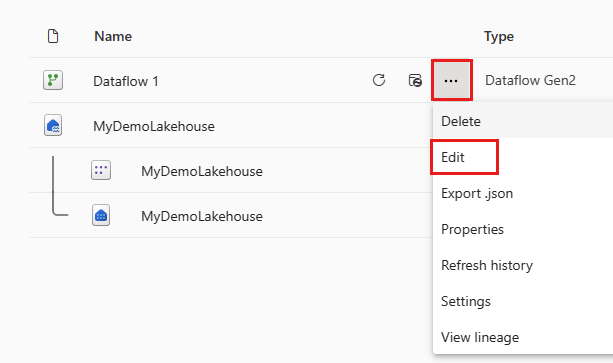
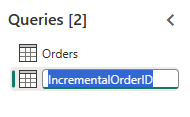
Maak een nieuwe query met de naam
IncrementalOrderIDen haal gegevens op uit de tabel Orders in het lakehouse dat u in de vorige sectie hebt gemaakt.
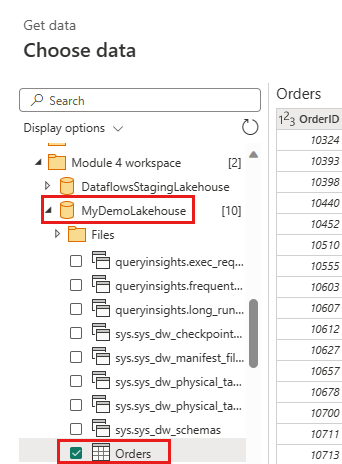
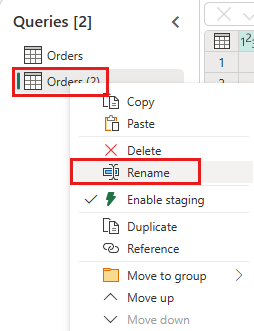
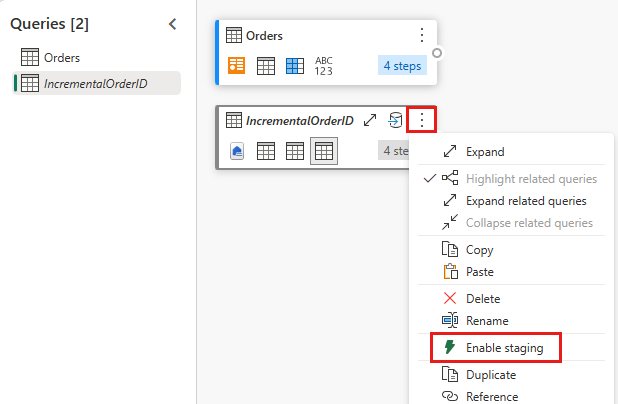
Fasering van deze query uitschakelen.
Klik in het voorbeeld van de gegevens met de rechtermuisknop op de
OrderIDkolom en selecteer Inzoomen.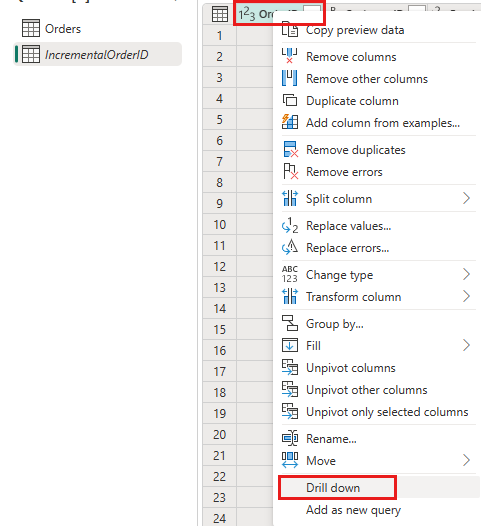
Selecteer van het lint Lijsthulpmiddelen ->Statistieken ->Maximum.
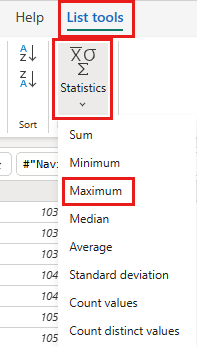
U hebt nu een query die de maximale OrderID in het lakehouse retourneert. Deze query wordt gebruikt om de gegevens uit de OData-bron te filteren. In de volgende sectie wordt een query toegevoegd aan de gegevensstroom om de gegevens uit de OData-bron te filteren op basis van de maximale OrderID in lakehouse.
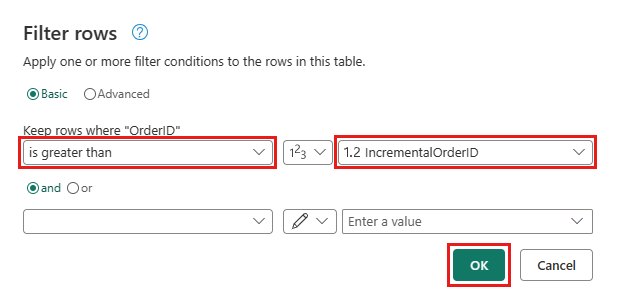
Ga terug naar de query Orders en voeg een nieuwe stap toe om de gegevens te filteren. Gebruik de volgende instellingen:
- Kolom:
OrderID - Operatie:
Greater than - Waarde: parameter
IncrementalOrderID

- Kolom:
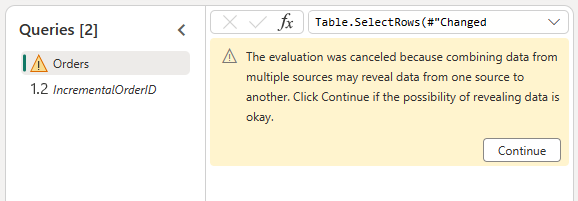
Sta het combineren van de gegevens uit de OData-bron en het lakehouse toe door het bevestigen van de volgende dialoog:
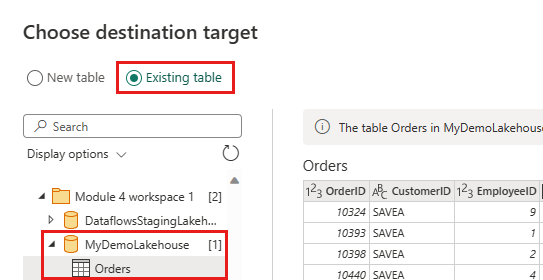
Werk de gegevensbestemming bij om de volgende instellingen te gebruiken:
- Updatemethode:
Append

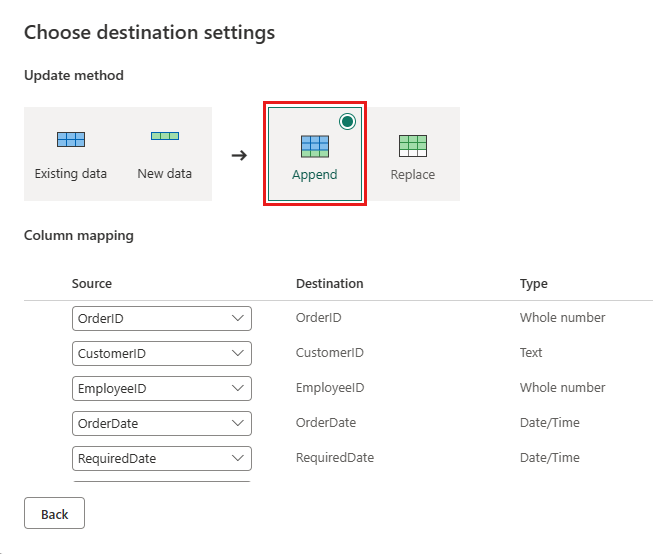
- Updatemethode:
Publiceer de gegevensstroom.
Uw gegevensstroom bevat nu een query waarmee de gegevens uit de OData-bron worden gefilterd op basis van de maximale OrderID in lakehouse. Dit betekent dat alleen nieuwe of bijgewerkte gegevens in het lakehouse worden geladen. In de volgende sectie wordt de gegevensstroom gebruikt om gegevens opnieuw te laden met behulp van notebooks en pijplijnen.
(Optioneel) gegevens opnieuw laden met behulp van notebooks en pijplijnen
U kunt desgewenst specifieke gegevens opnieuw laden met behulp van notebooks en pijplijnen. Met aangepaste Python-code in het notebook verwijdert u de oude gegevens uit lakehouse. Door vervolgens een pijplijn te maken waarin u het notebook voor het eerst uitvoert en de gegevensstroom opeenvolgend uitvoert, laadt u de gegevens uit de OData-bron opnieuw in het lakehouse. Notebooks ondersteunen meerdere talen, maar in deze zelfstudie wordt PySpark gebruikt. Pyspark is een Python-API voor Spark en wordt in deze zelfstudie gebruikt om Spark SQL-query's uit te voeren.
Maak een nieuw notitieblok in uw werkruimte.
Voeg de volgende PySpark-code toe aan uw notebook:
### Variables LakehouseName = "YOURLAKEHOUSE" TableName = "Orders" ColName = "OrderID" NumberOfOrdersToRemove = "10" ### Remove Old Orders Reload = spark.sql("SELECT Max({0})-{1} as ReLoadValue FROM {2}.{3}".format(ColName,NumberOfOrdersToRemove,LakehouseName,TableName)).collect() Reload = Reload[0].ReLoadValue spark.sql("Delete from {0}.{1} where {2} > {3}".format(LakehouseName, TableName, ColName, Reload))Voer het notebook uit om te controleren of de gegevens zijn verwijderd uit lakehouse.
Maak een nieuwe pijplijn in uw werkruimte.
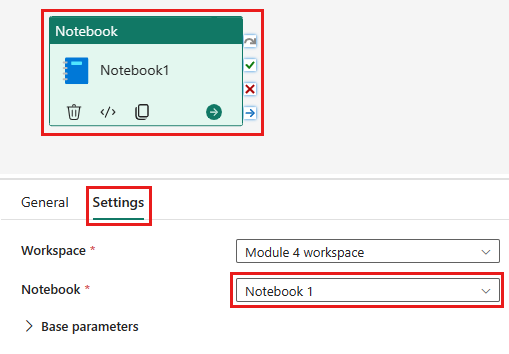
Voeg een nieuwe notebookactiviteit toe aan de pijplijn en selecteer het notebook dat u in de vorige stap hebt gemaakt.
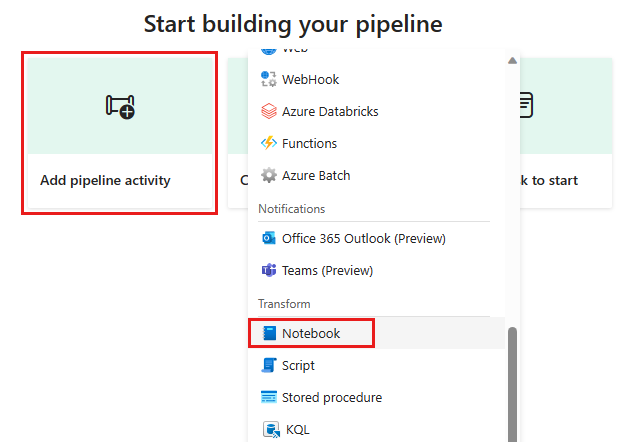
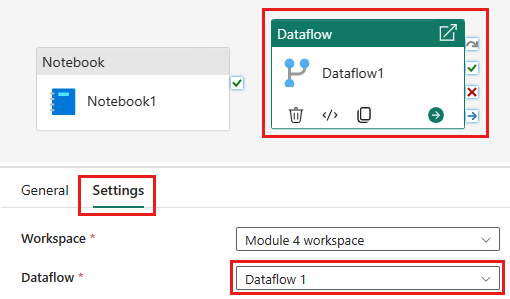
Voeg een nieuwe gegevensstroomactiviteit toe aan de pijplijn en selecteer de gegevensstroom die u in de vorige sectie hebt gemaakt.
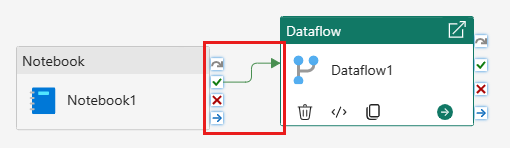
Koppel de notebookactiviteit aan de gegevensstroomactiviteit met een succesvolle trigger.
Sla de pijplijn op en voer deze uit.


U hebt nu een pijplijn waarmee oude gegevens uit het lakehouse worden verwijderd en de gegevens uit de OData-bron opnieuw worden geladen in het lakehouse. Met deze installatie kunt u de gegevens van de OData-bron regelmatig opnieuw laden in het lakehouse.