Notitie
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen u aan te melden of de directory te wijzigen.
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen de mappen te wijzigen.
Van toepassing op: ✅ SQL Analytics-eindpunt en -magazijn in Microsoft Fabric
Aangepaste SQL-pools geven beheerders meer controle over de manier waarop resources worden toegewezen om aanvragen te verwerken. In deze quickstart configureert u aangepaste SQL-pools en bekijkt u de classificatiewaarden met behulp van de Fabric REST API.
Werkruimtebeheerders kunnen de toepassingsnaam (of programmanaam) uit de verbindingsreeks gebruiken om aanvragen naar verschillende rekengroepen te routeren. Werkruimtebeheerders kunnen ook het percentage resources beheren dat elke reken-SQL-pool kan gebruiken, op basis van de burstbare schaallimiet van de werkruimtecapaciteit.
De Fabric REST API definieert een geïntegreerd eindpunt voor bewerkingen.
Vereiste voorwaarden
- Toegang tot een magazijnitem in een werkruimte. U moet een lid zijn van de rol van beheerder.
De huidige configuratie ophalen
Gebruik de volgende API om de huidige configuratie op te halen.
Voorbeeld van Fabric-notitieblok
U kunt de volgende Python-voorbeeldcode uitvoeren in een Fabric Spark-notebook.
- De code verzendt een
GETaanvraag naar de configuratie-API voor de aangepaste SQL-pool en retourneert de configuratie van de aangepaste SQL-pool voor de werkruimte. - Het
workspace_idveld gebruikt demssparkutils.runtime.contextom de werkruimte-GUID op te halen waarin het notebook wordt uitgevoerd. Als u een aangepaste SQL-pool in een andere werkruimte wilt configureren, werkt u deworkspace_idGUID van de werkruimte bij waar u de aangepaste SQL-pools wilt configureren.
import requests
import json
from notebookutils import mssparkutils
# This will get the workspace_id where this notebook is running.
# Update to the workspace_id (guid) if running this notebook outside of the workspace where the warehouse exists.
workspaceId = mssparkutils.runtime.context.get('currentWorkspaceId')
url = f'https://api.fabric.microsoft.com/v1/workspaces/{workspaceId}/warehouses/sqlPoolsConfiguration?beta=true'
response = requests.request(method='get', url=url, headers={'Authorization': f'Bearer {mssparkutils.credentials.getToken("pbi")}'})
if response.status_code == 200:
print(json.dumps(response.json(), indent=4))
else:
print(response.text)
Aangepaste SQL-pools configureren
In het volgende Python-voorbeeld worden aangepaste SQL-pools ingeschakeld en geconfigureerd. U kunt deze Python-code uitvoeren in een Fabric Spark-notebook.
- De configuratie van aangepaste SQL-pools is alleen actief wanneer
customSQLPoolsEnabledhet kenmerk is ingesteld op true. U kunt een nettolading definiëren in decustomSQLPoolsobjectdefinitie, maar als u customSQLPoolsEnabled niet instelt op true, wordt de nettolading genegeerd en wordt autonoom workloadbeheer gebruikt. - De code configureert twee aangepaste SQL-pools, namelijk de pools
ContosoSQLPoolenAdhocPool.- De
ContosoSQLPoolis ingesteld om 70% van de beschikbare middelen te ontvangen. De classificator Toepassingsnaam heeft de waardeMyContosoApp. - Alle SQL-query's die afkomstig zijn van een verbindingsreeks die de naam van de
MyContosoApptoepassing aangeeft, worden geclassificeerd voor deContosoSQLPoolaangepaste SQL-pool en hebben toegang tot 70% van de totale knooppunten met burstable-capaciteit. - Alle SQL-query's die niet in de toepassingsnaam van de verbindingsreeks staan
MyContosoApp, worden verzonden naar deAdhocaangepaste SQL-pool, die is gedefinieerd als de standaardgroep. Deze verzoeken krijgen toegang tot 30% van de totale nodes met burstbare capaciteit.
- De
- Alle aangepaste SQL-poolconfiguraties moeten één standaard-SQL-pool hebben die wordt geïdentificeerd door het
isDefaultkenmerk in te stellen op true. - De som van alle
maxResourcePercentagewaarden moet kleiner zijn dan of gelijk zijn aan 100%. - Het
workspace_idveld gebruikt demssparkutils.runtime.contextom de werkruimte-GUID op te halen waarin het notebook wordt uitgevoerd. Als u een aangepaste SQL-pool in een andere werkruimte wilt configureren, werkt u deworkspace_idGUID van de werkruimte bij waar u de aangepaste SQL-pools wilt configureren.
import requests
import json
from notebookutils import mssparkutils
body = {
"customSQLPoolsEnabled": True,
"customSQLPools": [
{
"name": "ContosoSQLPool",
"isDefault": False,
"maxResourcePercentage": 70,
"optimizeForReads": False,
"classifier": {
"type": "Application Name",
"value": [
"MyContosoApp"
]
}
},
{
"name": "AdhocPool",
"isDefault": True,
"maxResourcePercentage": 30,
"optimizeForReads": True
}
]
}
# This will get the workspaceId where this notebook is running.
# Update to the workspace_id (guid) if running this notebook outside of the workspace where the warehouse exists.
workspace_id = mssparkutils.runtime.context.get('currentWorkspaceId')
url = f'https://api.fabric.microsoft.com/v1/workspaces/{workspace_id}/warehouses/sqlPoolsConfiguration?beta=true'
response = requests.request(method='patch', url=url, json=body, headers={'Authorization': f'Bearer {mssparkutils.credentials.getToken("pbi")}'})
if response.status_code == 200:
print("SQL Custom Pools configured successfully.")
else:
print(response.text)
Aanbeveling
Gebruik deze nuttige classificatiewaarden voor application name (regex) voor verkeer van Fabric:
- Als u query's van Fabric-pijplijnen wilt classificeren, gebruikt u
^Data Integration-to[0-9a-fA-F]{8}-[0-9a-fA-F]{4}-[1-5][0-9a-fA-F]{3}-[89abAB][0-9a-fA-F]{3}-[0-9a-fA-F]{12}$. - Als u query's uit Power BI wilt classificeren, gebruikt u
^(PowerBIPremium-DirectQuery|Mashup Engine(?: \(PowerBIPremium-Import\))?). - Als u query's wilt classificeren vanuit de SQL-queryeditor van de Fabric-portal, gebruikt u
DMS_user.
De naam van de toepassing instellen in SQL Server Management Studio (SSMS)
De classificatie voor aangepaste SQL-pools maakt gebruik van de parameter toepassingsnaam of programmanaam van algemene verbindingsreeksen.
Geef in SQL Server Management Studio (SSMS) de servernaam voor het magazijn op en geef verificatie op. Microsoft Entra MFA wordt aanbevolen.
Selecteer de knop Geavanceerd .
Wijzig op de pagina Geavanceerde eigenschappen onder Context de waarde van toepassingsnaam in
MyContosoApp.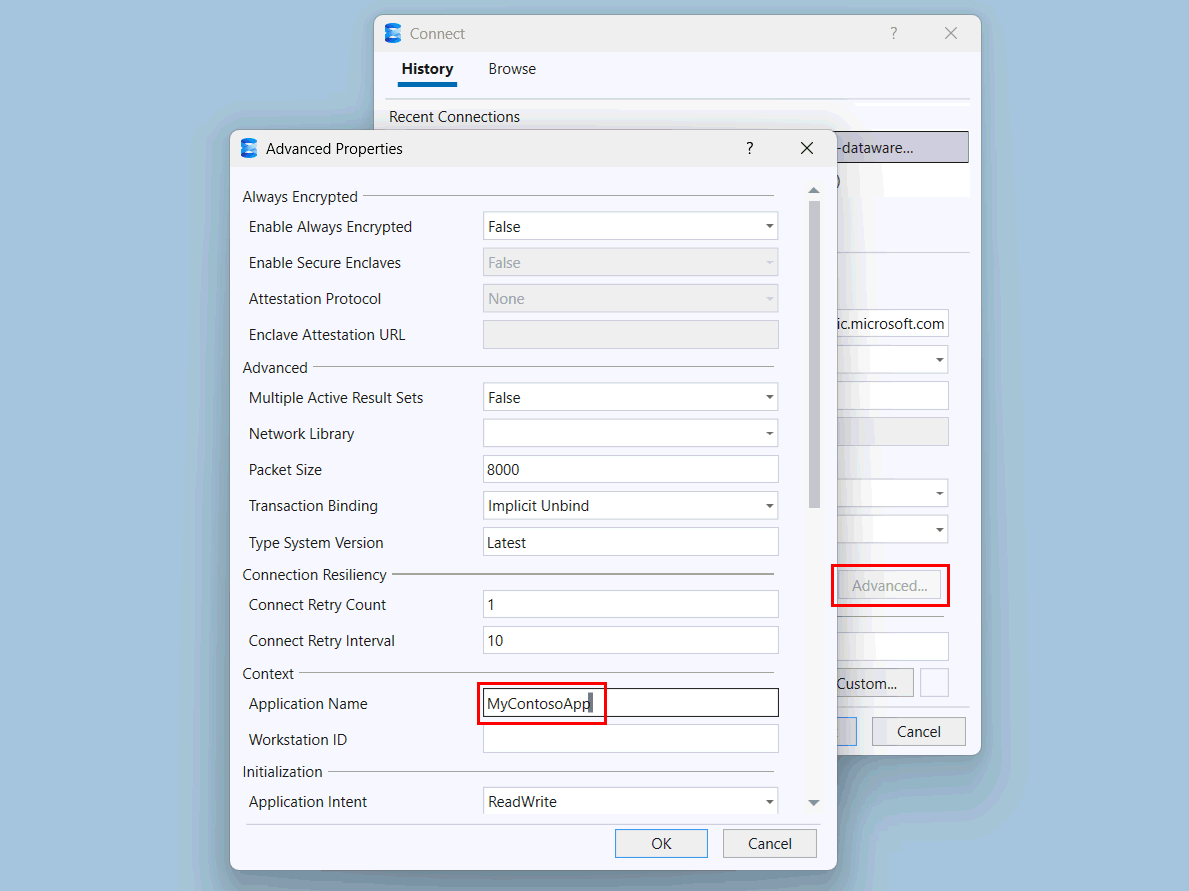
Kies OK.
Selecteer Maak verbinding met.
Als u een voorbeeldactiviteit wilt genereren, gebruikt u deze verbinding in SSMS om een eenvoudige query uit te voeren in uw magazijn, bijvoorbeeld:
SELECT * FROM dbo.DimDate;

Bekijk query-inzichten voor de aangepaste SQL-pool
Controleer de
sys.dm_exec_sessionsdynamische beheerweergave om te zien dat deze wordt herkend als de toepassingsnaam dieMyContosoAppdoor SSMS aan de SQL-engine wordt doorgegeven.SELECT session_id, program_name FROM sys.dm_exec_sessions WHERE program_name = 'MyContosoApp';Voorbeeld:
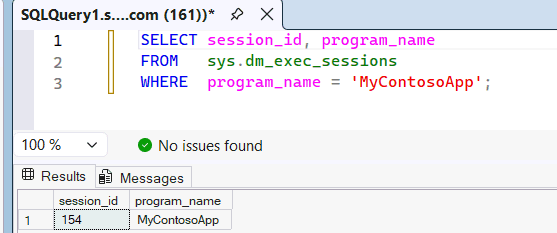
Omdat de
program_namenaam van de toepassing overeenkomt met de naam van de toepassing in deMyContosoAppaangepaste SQL-pool, gebruikt deze query de resources in die pool. Als u wilt bewijzen welke aangepaste SQL-pool de query heeft gebruikt, kunt u een query uitvoeren op de queryinsights.exec_requests_history systeemweergave. Wacht 10-15 minuten tot queryinzichten zijn ingevuld en voer vervolgens de volgende query uit.SELECT distributed_statement_id, submit_time, program_name, sql_pool_name, start_time, end_time FROM queryinsights.exec_requests_history WHERE program_name = 'MyContosoApp';U kunt ook de pool van een query identificeren door de Statement ID. Voer in de SQL-query-editor van de Fabric-portal een query uit op uw warehouse- of SQL-analyse-eindpunt.
SELECT * FROM dbo.DimDate;Selecteer het tabblad Berichten en noteer de Statement ID voor de query-uitvoering. In de SQL-query-editor is
program_namehetDMS_user, die u eerder hebt geconfigureerd om de aangepaste SQL-poolMyContosoAppte gebruiken.Wacht 10-15 minuten totdat de inzichten van de query zijn geladen.
Haal de
sql_pool_nameen andere informatie op om te controleren of de juiste aangepaste SQL-pool is gebruikt.SELECT distributed_statement_id, submit_time, program_name, sql_pool_name, start_time, end_time FROM queryinsights.exec_requests_history WHERE distributed_statement_id = '<Statement ID>';
De configuratie van aangepaste SQL-pools herstellen
Als u de werkruimte wilt terugbrengen naar de oorspronkelijke staat, wijzigt u de customSQLPoolsEnabled eigenschap in False. Als u de configuratie van aangepaste SQL-pools wilt behouden, moet u elke poolnaam doorgeven zoals in de customSQLPools lijst.
Met deze Python-voorbeeldcode worden aangepaste SQL-pools uitgeschakeld en herstelt het naar de autonome workloadbeheerconfiguratie van SELECT en niet-SELECT pools. Een PATCH aanvraag wordt aangeroepen met de customSQLPoolsEnabled eigenschap ingesteld op False.
import requests
import json
from notebookutils import mssparkutils
body = {
"customSQLPoolsEnabled": False,
"customSQLPools": []
}
# This will get the workspaceId where this notebook is running.
# Update to the workspace_id (guid) if running this notebook outside of the workspace where the warehouse exists.
workspace_id = mssparkutils.runtime.context.get('currentWorkspaceId')
url = f'https://api.fabric.microsoft.com/v1/workspaces/{workspace_id}/warehouses/sqlPoolsConfiguration?beta=true'
response = requests.request(method='patch', url=url, json=body, headers={'Authorization': f'Bearer {mssparkutils.credentials.getToken("pbi")}'})
if response.status_code == 200:
print("SQL Custom Pools successfully disabled.")
else:
print(response.text)