Notitie
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen u aan te melden of de directory te wijzigen.
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen de mappen te wijzigen.
Met snelkoppelingstransformaties worden onbewerkte bestanden (CSV, Parquet en JSON) geconverteerd naar Delta-tabellen die altijd gesynchroniseerd blijven met de brongegevens. De transformatie wordt uitgevoerd door Fabric Spark Compute, waarmee de gegevens waarnaar wordt verwezen door een OneLake-snelkoppeling naar een beheerde Delta-tabel worden gekopieerd, zodat u zelf geen traditionele ETL-pijplijnen (extract, transform, load) hoeft te bouwen en organiseren. Met automatische schemaafhandeling, diepe afvlakkingsmogelijkheden en ondersteuning voor meerdere compressie-indelingen, elimineren snelkoppelingstransformaties de complexiteit van het bouwen en onderhouden van ETL-pijplijnen.
Note
Sneltoets-transformaties zijn momenteel in openbare preview en kunnen in de toekomst worden gewijzigd.
Waarom sneltoetsbewerkingen gebruiken?
- Geen handmatige pijplijnen : Fabric kopieert en converteert de bronbestanden automatisch naar Delta-indeling; U hoeft geen incrementele belastingen te organiseren.
- Regelmatig vernieuwen : Fabric controleert de snelkoppeling elke 2 minuten en synchroniseert eventuele wijzigingen bijna onmiddellijk.
- Gereed voor openen en analyseren : uitvoer is een Delta Lake-tabel waarop een apache Spark-compatibele engine query's kan uitvoeren.
- Geïntegreerde governance: de snelkoppeling neemt OneLake-herkomst, machtigingen en Microsoft Purview-beleid over.
- Spark-based – Transformaties gebouwd voor schaal.
Prerequisites
| Requirement | Details |
|---|---|
| Microsoft Fabric-SKU | Capaciteit of proefversie die ondersteuning biedt voor Lakehouse-workloads . |
| Brongegevens | Een map met homogene CSV-, Parquet- of JSON-bestanden. |
| Werkruimterol | Inzender of hoger. |
Ondersteunde bronnen, indelingen en bestemmingen
Alle door OneLake ondersteunde gegevensbronnen worden ondersteund.
| Bronbestandsindeling | Bestemming | Ondersteunde extensies | Ondersteunde compressietypen | Opmerkingen |
|---|---|---|---|---|
| CSV (UTF-8, UTF-16) | Delta Lake-tabel in de map Lakehouse/Tables | .csv,.txt(scheidingsteken),.tsv(door tabs gescheiden), .psv(door pijpen gescheiden), | .csv.gz,.csv.bz2 | .csv.zip en .csv.snappy worden vanaf de datum niet ondersteund. |
| Parquet | Delta Lake-tabel in de map Lakehouse/Tables | .parket | .parquet.snappy,.parquet.gzip,.parquet.lz4,.parquet.brotli,.parquet.zstd | |
| JSON | Delta Lake-tabel in de map Lakehouse/Tables | .json,.jsonl,.ndjson | .json.gz,.json.bz2,.jsonl.gz,.ndjson.gz,.jsonl.bz2,.ndjson.bz2 | .json.zip en .json.snappy worden vanaf nu niet ondersteund |
- Ondersteuning voor Excel-bestanden maakt deel uit van de roadmap
- AI-transformaties die beschikbaar zijn ter ondersteuning van ongestructureerde bestandsindelingen (.txt, .doc, .docx) met Text Analytics-use case live met meer verbeteringen die binnenkort beschikbaar zijn
Een snelkoppelingstransformatie instellen
Selecteer in uw lakehouse Nieuwe tabelsnelkoppeling in de sectie Tabellen, wat snelkoppelingstransformatie (voorbeeld) is en selecteer uw bron (Azure Data Lake, Azure Blob Storage, Dataverse, Amazon S3, GCP, SharePoint, OneDrive, enzovoort).
Kies het bestand, configureer transformatie en maak snelkoppeling : blader naar een bestaande OneLake-snelkoppeling die verwijst naar de map met uw CSV-bestanden, configureer parameters en start het maken.
- Scheidingsteken in CSV-bestanden: selecteer het teken dat wordt gebruikt om kolommen te scheiden (komma, puntkomma, pipe, tab, ampersand, spatie).
- Eerste rij als kopteksten : geef aan of de eerste rij kolomnamen bevat.
- Naam van snelkoppeling naar tabel : geef een beschrijvende naam op; Fabric maakt deze onder /Tables.
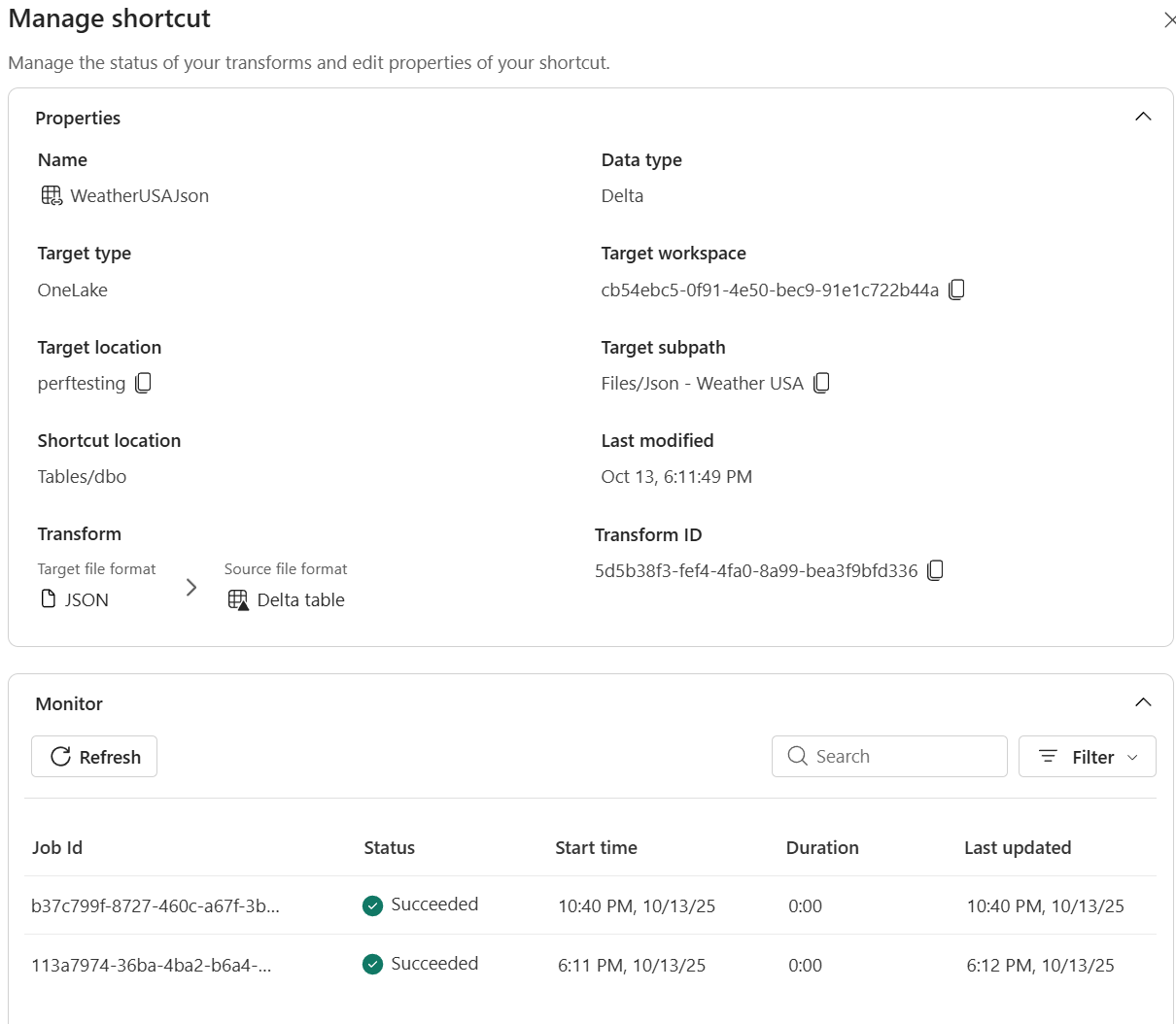
Volg vernieuwingen en bekijk logboeken voor transparantie in het Beheercentrum voor snelkoppelingbewaking.
Fabric Spark computing kopieert de gegevens naar een Delta-tabel en toont de voortgang in het deelvenster Snelkoppeling beheren. Snelkoppelingstransformaties zijn beschikbaar in Lakehouse-items. Ze maken Delta Lake-tabellen in de map Lakehouse/Tables .
Hoe synchronisatie werkt
Na de eerste lading wordt de Fabric Spark-berekening uitgevoerd:
- Pollt het snelkoppelingsdoel elke 2 minuten.
- Detecteert nieuwe of gewijzigde bestanden en voegt rijen dienovereenkomstig toe of overschrijft.
- Detecteert verwijderde bestanden en verwijdert bijbehorende rijen.
Bewaken en problemen oplossen
Snelkoppelingstransformaties omvatten bewaking en foutafhandeling om de opnamestatus bij te houden en problemen te diagnosticeren.
- Open de lakehouse en klik met de rechtermuisknop op de snelkoppeling die uw transformatie ondersteunt.
- Selecteer Snelkoppeling beheren.
- In het detailvenster kunt u het volgende bekijken:
- Status : laatste scanresultaat en huidige synchronisatiestatus.
-
Vernieuwingsgeschiedenis : chronologische lijst met synchronisatiebewerkingen met aantal rijen en eventuele foutdetails.
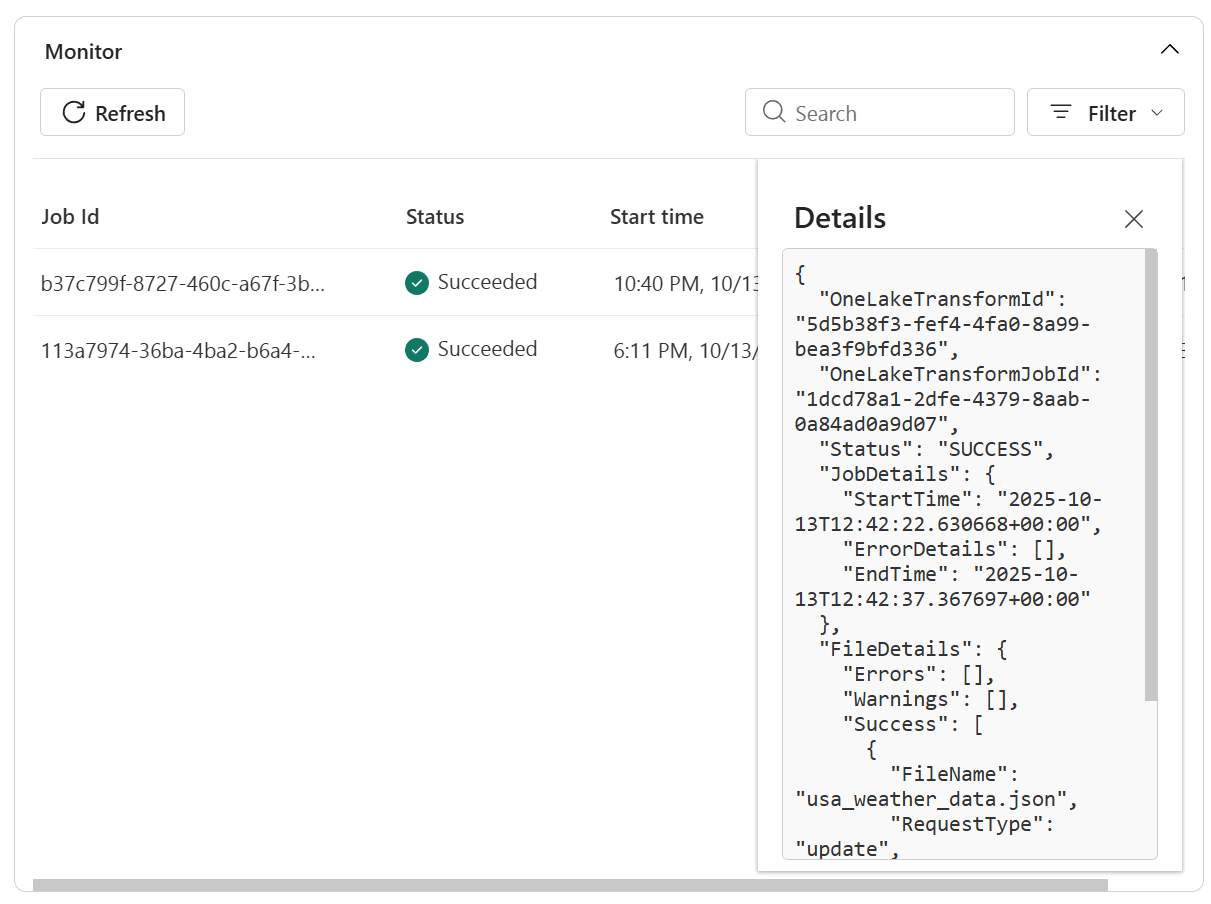
- Bekijk meer informatie in logboeken voor het oplossen van problemen
Note
De mogelijkheid om de transformatie vanuit dit tabblad te pauzeren of te verwijderen is een toekomstige functie die deel uitmaakt van de roadmap.
Beperkingen
Huidige beperkingen van snelkoppelingstransformaties:
- Alleen CSV-, Parquet-, JSON-bestandsindelingen worden ondersteund.
- Bestanden moeten een identiek schema delen; schemadrift wordt nog niet ondersteund.
- Transformaties zijn geoptimaliseerd voor lezen; MERGE INTO-, of DELETE-instructies rechtstreeks op de tabel worden geblokkeerd.
- Alleen beschikbaar in Lakehouse-items (geen magazijnen of KQL-databases).
- Niet-ondersteunde gegevenstypen voor CSV: Kolommen met gemengde gegevenstypen, Timestamp_Nanos, complexe logische typen - MAP/LIST/STRUCT, Onbewerkt binair bestand
- Niet-ondersteund gegevenstype voor Parquet: Timestamp_nanos, Decimaal met INT32/INT64, INT96, niet-gealloceerde gehele typen - UINT_8/UINT_16/UINT_64, Complexe logische typen - MAP/LIST/STRUCT)
- Niet-ondersteunde gegevenstypen voor JSON: Gemengde gegevenstypen in een matrix, onbewerkte binaire blobs in JSON, Timestamp_Nanos
Afvlakken van array-gegevens in JSON: Het array-gegevenstype moet worden behouden in de deltatabel en gegevens moeten toegankelijk zijn met Spark SQL & Pyspark, waarbij voor verdere transformaties Fabric Materialized Lake Views kunnen worden gebruikt voor de zilveren laag.- Bronindeling: Vanaf de aangegeven datum worden alleen CSV-, JSON- en Parquet-bestanden ondersteund.
- Afvlakkende diepte in JSON: Geneste structuren worden platgemaakt tot vijf niveaus diep. Voor dieper nesten is voorverwerking vereist.
- Schrijfbewerkingen: transformaties zijn geoptimaliseerd voor lezen; directe MERGE INTO of DELETE-instructies in de transformatie-doeltabel worden niet ondersteund.
- Beschikbaarheid van werkruimte: is alleen beschikbaar in Lakehouse-items (niet in data-warehouses of KQL-databases).
- Consistentie van bestandsschema's: bestanden moeten een identiek schema delen.
Note
Het toevoegen van ondersteuning voor een aantal van de bovenstaande en het verminderen van beperkingen maakt deel uit van onze roadmap. Volg onze releaseberichten voor verdere updates.
Schoonmaken
Om de synchronisatie te stoppen, verwijdert u de koppelingstransformatie uit de Lakehouse-gebruikersinterface.
Als u de transformatie verwijdert, worden de onderliggende bestanden niet verwijderd.