Notitie
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen u aan te melden of de directory te wijzigen.
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen de mappen te wijzigen.
Gebruik snelkoppelingstransformaties om gestructureerde bestanden te converteren naar doorzoekbare Delta-tabellen. Als uw brongegevens al een tabelindeling hebben, zoals CSV, Parquet of JSON, worden deze gegevens automatisch gekopieerd en geconverteerd naar Delta Lake-indeling, zodat u er query's op kunt uitvoeren met behulp van SQL, Spark of Power BI zonder ETL-pijplijnen te bouwen.
Voor niet-gestructureerde tekstbestanden die AI-processen nodig hebben, zoals samenvatting, vertaling of sentimentanalyse, zie Snelkoppelingstransformaties (AI-powered).
Snelkoppelingstransformaties blijven altijd gesynchroniseerd met de brongegevens. Fabric Spark-berekening voert de transformatie uit en kopieert de gegevens waarnaar wordt verwezen door een OneLake-snelkoppeling naar een beheerde Delta-tabel. Met automatische schemaafhandeling, diepe afvlakkingsmogelijkheden en ondersteuning voor meerdere compressie-indelingen, elimineren snelkoppelingstransformaties de complexiteit van het bouwen en onderhouden van ETL-pijplijnen.
Opmerking
Sneltoets-transformaties zijn momenteel in openbare preview en kunnen in de toekomst worden gewijzigd.
Waarom sneltoetsbewerkingen gebruiken?
- Automatische conversie: Fabric kopieert en converteert bronbestanden naar Delta-indeling zonder handmatige pijplijnorkestratie.
- Frequente synchronisatie : Fabric pollt de snelkoppeling om de twee minuten en synchroniseert wijzigingen.
- Delta Lake-uitvoer : de resulterende tabel is compatibel met elke Apache Spark-engine.
- Geërfde governance – de snelkoppeling neemt OneLake-herkomst, toegangsrechten en Microsoft Purview-beleid over.
Vereiste voorwaarden
| Requirement | Details |
|---|---|
| Microsoft Fabric SKU | Capaciteit of proef die ondersteuning biedt voor Lakehouse-workloads. |
| Brongegevens | Een map met homogene CSV-, Parquet- of JSON-bestanden. |
| Rol binnen werkruimte | Inzender of hoger. |
Ondersteunde bronnen, indelingen en bestemmingen
Alle door OneLake ondersteunde gegevensbronnen worden ondersteund.
| Bronbestandsindeling | Bestemming | Ondersteunde extensies | Ondersteunde compressietypen | Aantekeningen |
|---|---|---|---|---|
| CSV (UTF-8, UTF-16) | Delta Lake-tabel in de map Lakehouse/Tables | .csv, .txt (scheidingsteken), .tsv (door tabs gescheiden), .psv (door pijpen gescheiden) | .csv.gz, .csv.bz2 | .csv.zip en .csv.snappy worden niet ondersteund. |
| Parquet | Delta Lake-tabel in de map Lakehouse/Tables | .parket | .parquet.snappy, .parquet.gzip, .parquet.lz4, .parquet.brotli, .parquet.zstd | |
| JSON | Delta Lake-tabel in de map Lakehouse/Tables | .json, .jsonl, .ndjson | .json.gz, .json.bz2, .jsonl.gz, .ndjson.gz, .jsonl.bz2, .ndjson.bz2 | .json.zip en .json.snappy worden niet ondersteund. |
Een snelkoppelingstransformatie instellen
Selecteer in uw lakehouse in de sectie Tabellen de optie Nieuwe Tabel Snelkoppeling, wat Snelkoppelingstransformatie (preview) is. Kies uw bron (bijvoorbeeld Azure Data Lake, Azure Blob Storage, Dataverse, Amazon S3, GCP, SharePoint, OneDrive en meer).
Kies het bestand, configureer transformatie en maak snelkoppelingen : blader naar een bestaande OneLake-snelkoppeling die verwijst naar de map met uw CSV-bestanden, configureer parameters en start het maken.
- Scheidingsteken in CSV-bestanden: selecteer het teken dat wordt gebruikt om kolommen te scheiden (komma, puntkomma, pipe, tab, ampersand, spatie).
- Eerste rij als kopteksten : geef aan of de eerste rij kolomnamen bevat.
- Naam van snelkoppeling naar tabel : geef een beschrijvende naam op; Fabric maakt deze onder /Tables.
Volg vernieuwingen en bekijk logboeken voor transparantie in het Beheercentrum voor snelkoppelingbewaking.

Fabric Spark computing kopieert de gegevens naar een Delta-tabel en toont de voortgang in het deelvenster Snelkoppeling beheren. Snelkoppelingstransformaties zijn beschikbaar in Lakehouse-items. Ze maken Delta Lake-tabellen in de map Lakehouse/Tables .
Hoe synchronisatie werkt
Na de eerste lading wordt de Fabric Spark-berekening uitgevoerd:
- Pollt het doel van de snelkoppeling elke twee minuten.
- Detecteert nieuwe of gewijzigde bestanden en voegt rijen dienovereenkomstig toe of overschrijft.
- Detecteert verwijderde bestanden en verwijdert bijbehorende rijen.
Bewaken en problemen oplossen
Snelkoppelingstransformaties omvatten bewaking en foutafhandeling om de opnamestatus bij te houden en problemen te diagnosticeren.
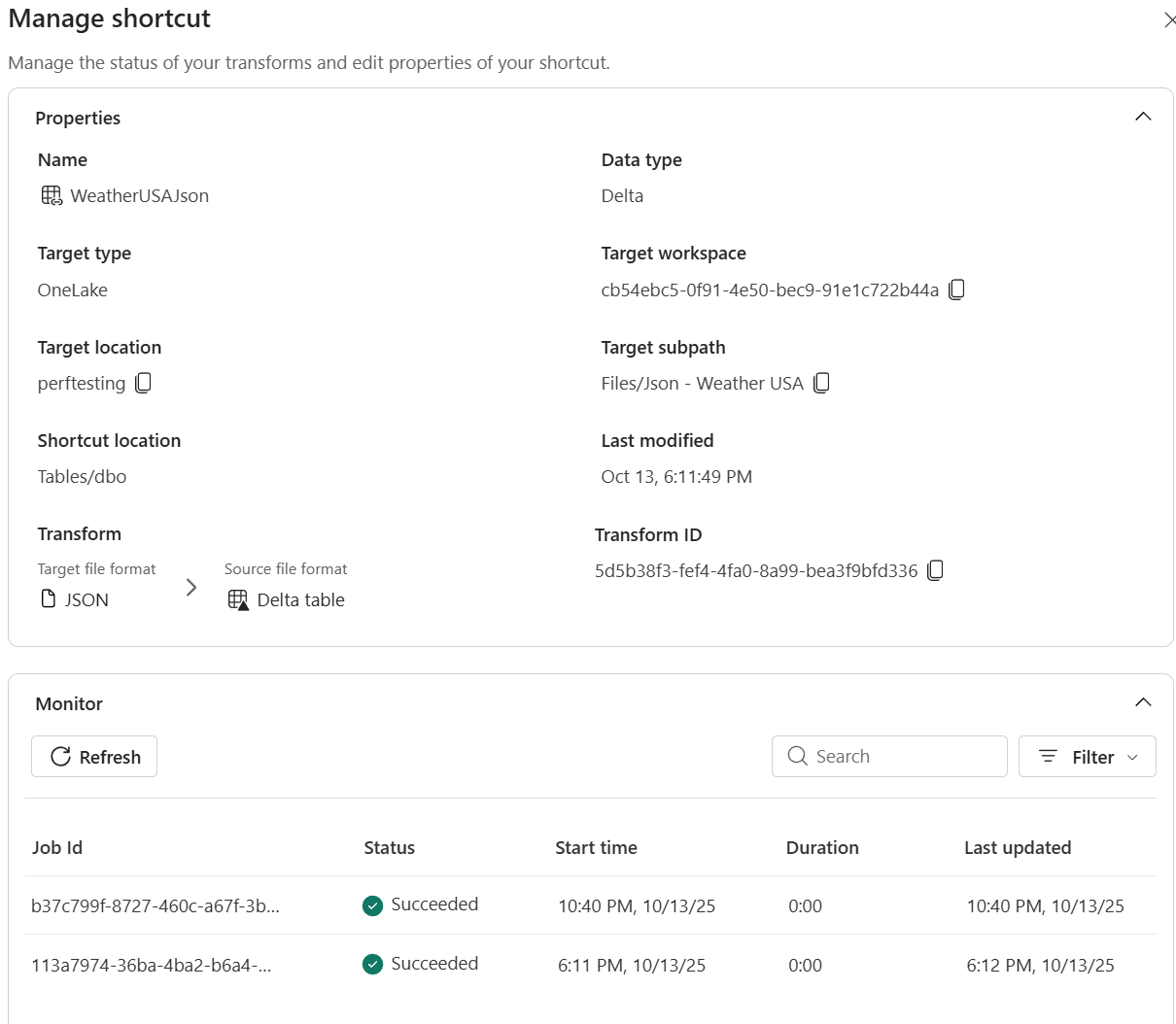
Open de lakehouse en klik met de rechtermuisknop op de snelkoppeling die uw transformatie ondersteunt.
Selecteer Snelkoppeling beheren.
In het detailvenster kunt u het volgende bekijken:
- Status : laatste scanresultaat en huidige synchronisatiestatus.
- Vernieuwingsgeschiedenis : chronologische lijst met synchronisatiebewerkingen met aantal rijen en eventuele foutdetails.
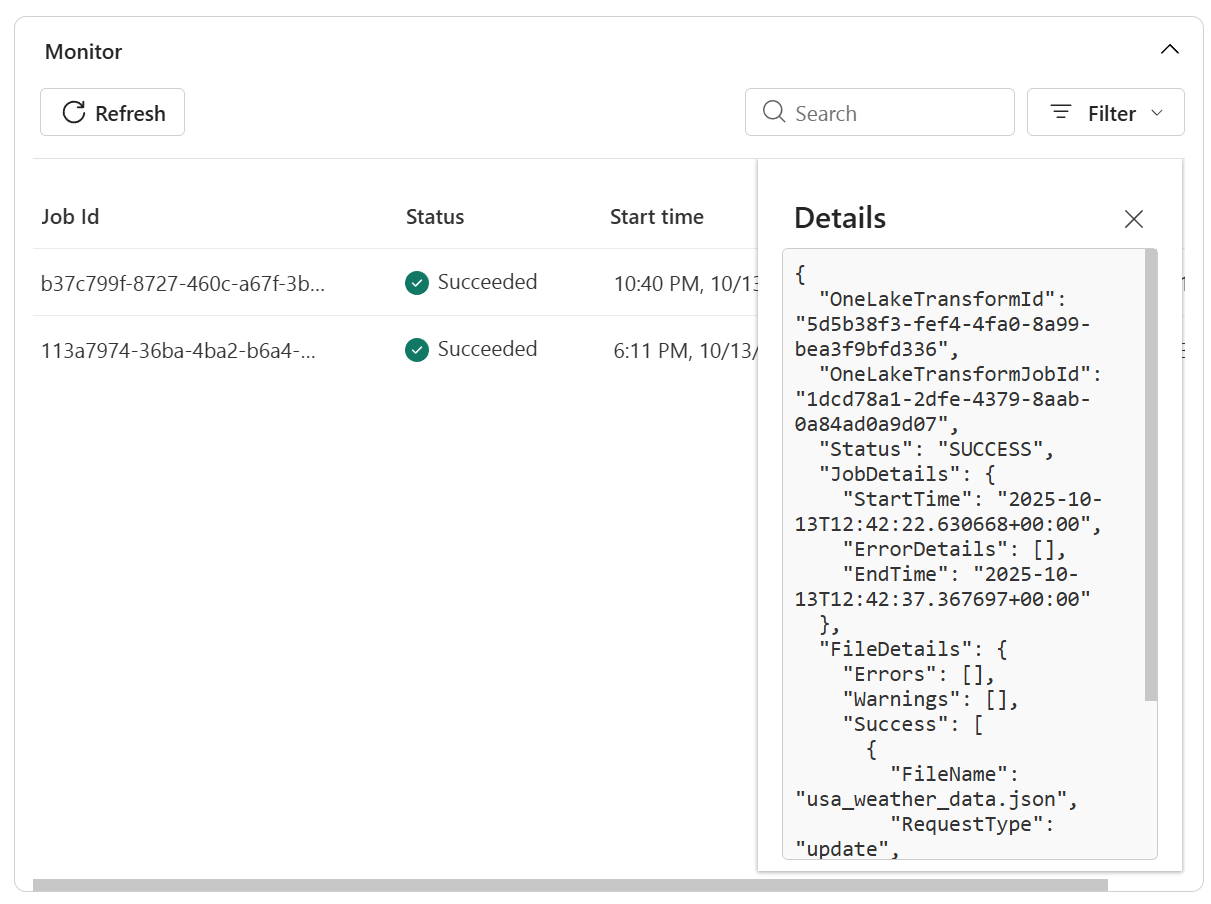
Meer details weergeven in logboeken om problemen op te lossen
Beperkingen
Huidige beperkingen van snelkoppelingstransformaties:
-
Bronindeling: Alleen CSV-, JSON- en Parquet-bestanden worden ondersteund.
- Niet-ondersteunde gegevenstypen voor CSV: Kolommen met gemengde gegevenstypen, Timestamp_Nanos, complexe logische typen - MAP/LIST/STRUCT, Onbewerkt binair bestand
- Niet-ondersteunde gegevenstypen voor Parquet: Timestamp_nanos, decimaal met INT32/INT64, INT96, niet-toegewezen gehele getallen - UINT_8/UINT_16/UINT_64, complexe logische typen - MAP/LIST/STRUCT
- Niet-ondersteunde gegevenstypen voor JSON: Gemengde gegevenstypen in een matrix, onbewerkte binaire blobs in JSON, Timestamp_Nanos
- Consistentie van bestandsschema: Bestanden moeten een identiek schema delen.
- Beschikbaarheid van werkruimten: Alleen beschikbaar in Lakehouse-items (niet datawarehouses of KQL-databases).
- Schrijfbewerkingen: Transformaties zijn geoptimaliseerd voor lezen; directe MERGE INTO of DELETE-instructies op de transformatie-doeltabel worden niet ondersteund.
- Afvlakken van matrixgegevenstype in JSON: Matrixgegevenstype wordt bewaard in deltatabel en gegevens die toegankelijk zijn met Spark SQL en Pyspark. Voor verdere transformaties kan Fabric Materialized Lake Views worden gebruikt voor zilveren laag.
- Vereenvoudigen van diepte in JSON: Geneste structuren worden vereenvoudigd tot vijf niveaus diep. Voor dieper nesten is voorverwerking vereist.
Gebruik het blog Fabric Roadmap en Fabric Updates voor meer informatie over nieuwe functies en releases.
Schoonmaken
Als u de synchronisatie wilt stoppen, verwijdert u de koppelingstransformatie uit Lakehouse Explorer.
Als u de transformatie verwijdert, worden de onderliggende bestanden niet verwijderd.